HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

ディープリサーチ Agents はどこで誤るのか?Agent 軌跡におけるスパンレベルのエラー局所化

音声相互作用モデル







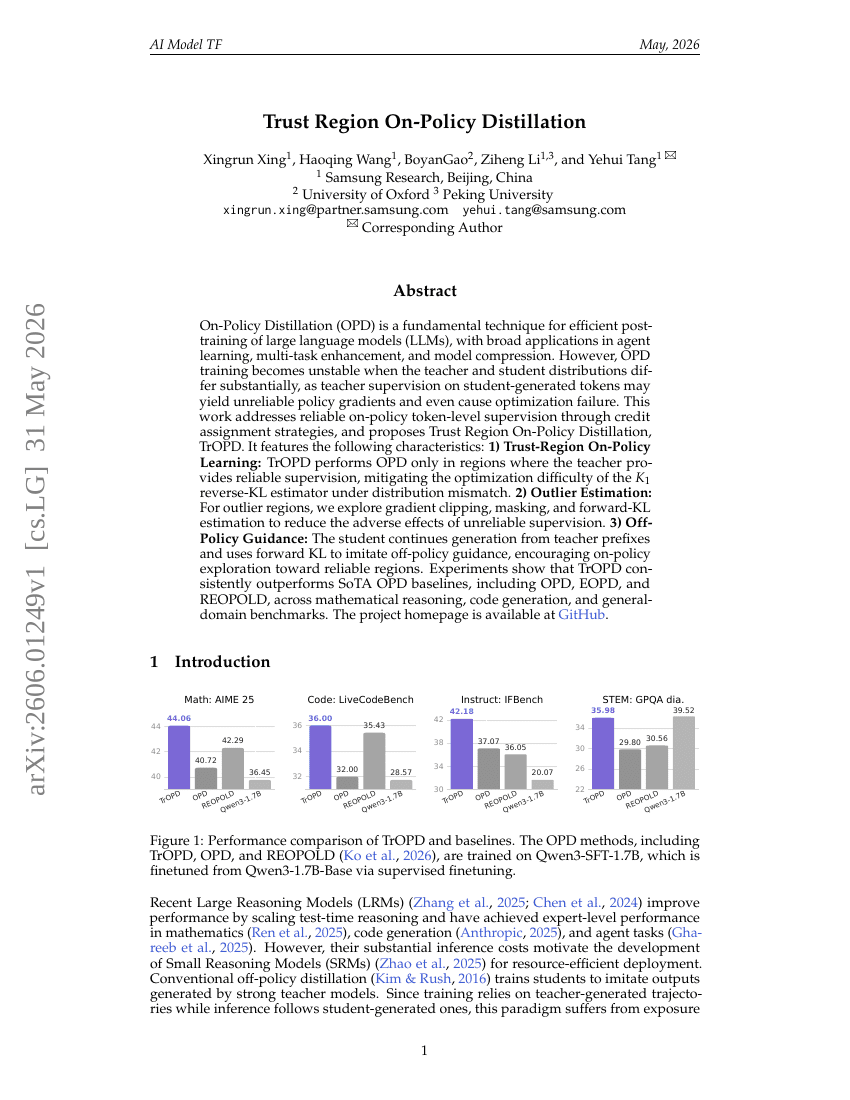

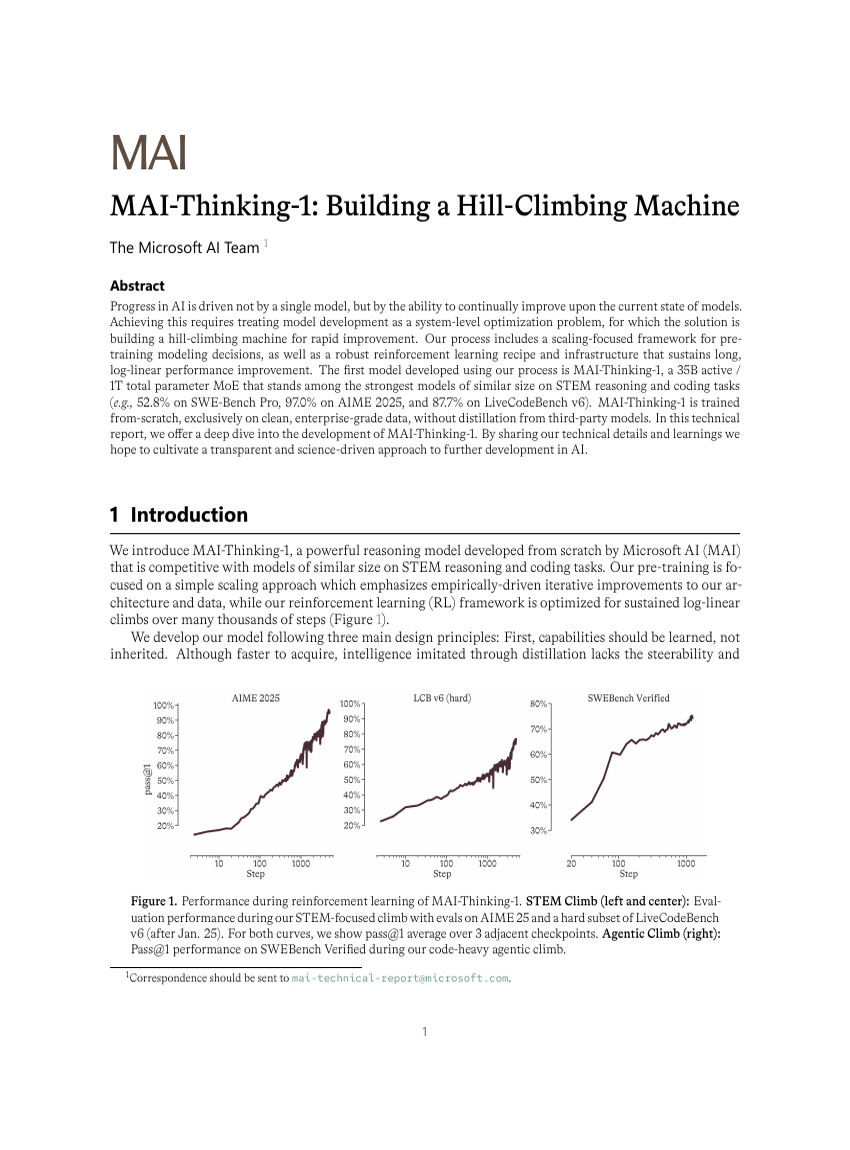

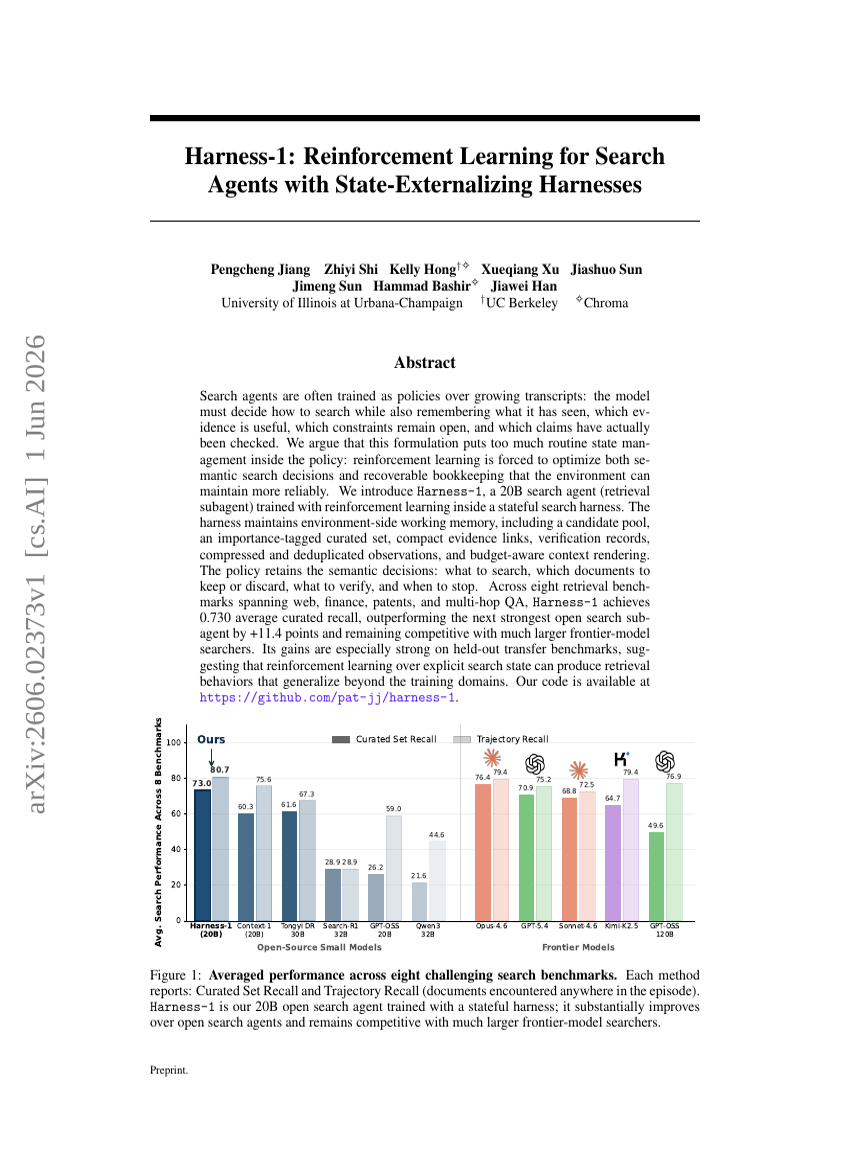



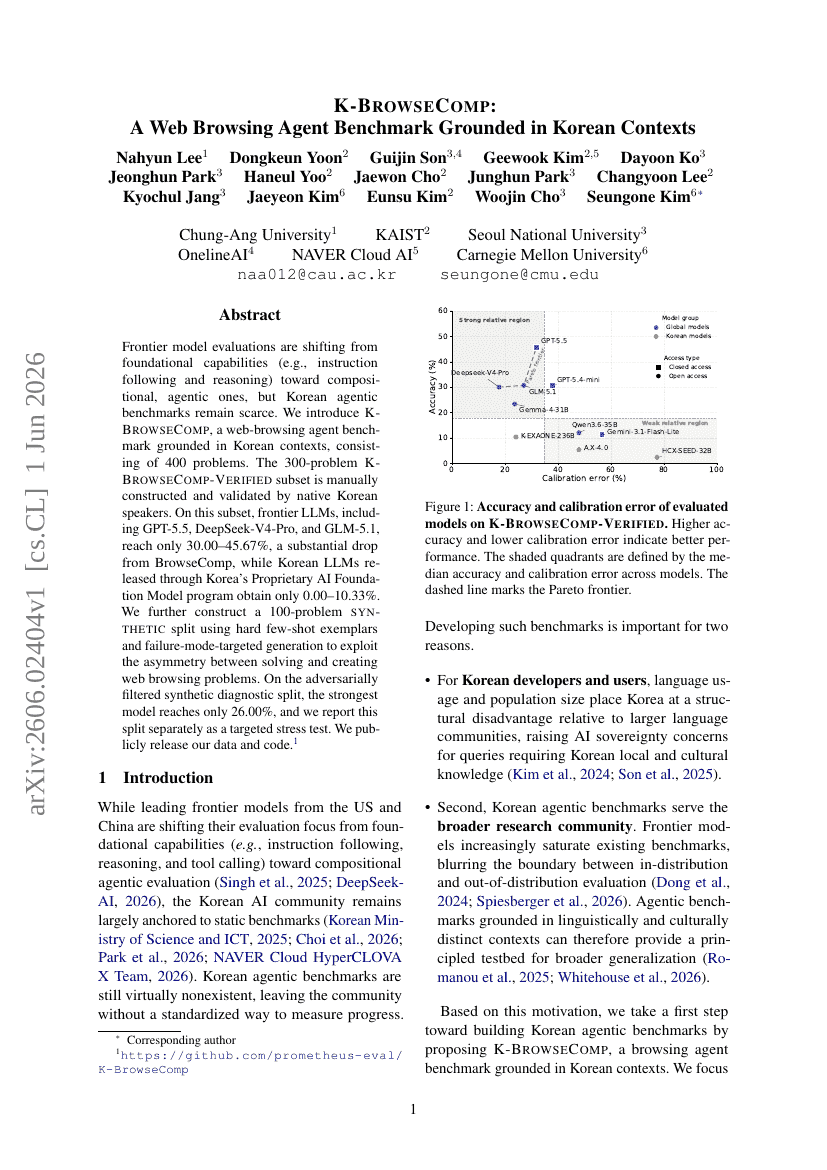














ディープリサーチ Agents はどこで誤るのか?Agent 軌跡におけるスパンレベルのエラー局所化
音声相互作用モデル
コスモス3: 物理AI向けのオムニモーダル・ワールドモデル
速習と遅習:継続的に適応する大規模言語モデルへ向けて
LEAP: エージェントフレームワークを用いたLLMの形式数学への最適化
ワールドモデルと言語モデル:具体的推論と抽象的推論の補完性について
活性化から因果性へ:人間脳における因果的視覚表現の発見
複数ドメイン強化学習におけるドメイン間干渉と回復のための局所摂動理論
Humanoid-GPT: ゼロショットモーショントラッキングのためのデータと構造のスケーリング
信頼域オンポリシー蒸留
OCC-RAG: 忠実な質問応答のための最適な認知コア
MAI-Thinking-1: 標高上昇機の構築
VLM3:ビジョン言語モデルはネイティブな3D学習者である
Harness-1:状態外部化ハarnessを用いた探索エージェントのための強化学習
DeepCrack: 割れ目のセグメンテーションのための深層階層特徴学習アーキテクチャ
VideoMLA: 分スケールの自己回帰的動画拡散のための低ランク潜在KVキャッシュ
Draft-OPD: 推測的ドラフトモデルのためのオンポリシー蒸留
K-BrowseComp: 韓国語の文脈に基づいたウェブブラウジングAgentベンチマーク
TASTEの問題:agentベンチマークのカバレッジと難易度の向上
PEFTのスケーリングについて:トリリオンパラメータの百万パーソナルモデルへ向けて
Crafter: 多様な入力からの編集可能な科学図の生成のためのMulti-Agent Harness
TACK: 新規TArgeting Chimeras知識データセットにおける劣化活動の統計的評価
ナラティブ・ウィーバー:マルチモーダル条件付けによる制御可能な長距離ビジュアル一貫性に向けて
ハネス更新はハネス利益ではない:自己進化型LLMエージェントにおける進化能力の解離
LongTraceRL: ルーブリック報酬を用いた検索Agent軌跡からの長文脈推論学習
信頼域行動混合によるオンポリシー蒸留
SwanVoice: 独白と対話の両方に対応する表現力のある長尺ゼロショット音声合成
ボトルネックフリー統合マルチモーダルモデルのための表現強制
GrepSeek: 直接コーパス相互作用のための検索Agentsの訓練
COLLEAGUE.SKILL:専門知識蒸留による自動AIスキル生成
エージェント型システムによる弱い推論モデルの強化
YoCausal: ビデオ生成はワールドモデルからどれくらい離れているのか? 因果性の視点から
コスモス3: 物理AI向けのオムニモーダル・ワールドモデル
速習と遅習:継続的に適応する大規模言語モデルへ向けて
LEAP: エージェントフレームワークを用いたLLMの形式数学への最適化
ワールドモデルと言語モデル:具体的推論と抽象的推論の補完性について
活性化から因果性へ:人間脳における因果的視覚表現の発見
複数ドメイン強化学習におけるドメイン間干渉と回復のための局所摂動理論
Humanoid-GPT: ゼロショットモーショントラッキングのためのデータと構造のスケーリング
信頼域オンポリシー蒸留
OCC-RAG: 忠実な質問応答のための最適な認知コア
MAI-Thinking-1: 標高上昇機の構築
VLM3:ビジョン言語モデルはネイティブな3D学習者である
Harness-1:状態外部化ハarnessを用いた探索エージェントのための強化学習
DeepCrack: 割れ目のセグメンテーションのための深層階層特徴学習アーキテクチャ
VideoMLA: 分スケールの自己回帰的動画拡散のための低ランク潜在KVキャッシュ
Draft-OPD: 推測的ドラフトモデルのためのオンポリシー蒸留
K-BrowseComp: 韓国語の文脈に基づいたウェブブラウジングAgentベンチマーク
TASTEの問題:agentベンチマークのカバレッジと難易度の向上
PEFTのスケーリングについて:トリリオンパラメータの百万パーソナルモデルへ向けて
Crafter: 多様な入力からの編集可能な科学図の生成のためのMulti-Agent Harness
TACK: 新規TArgeting Chimeras知識データセットにおける劣化活動の統計的評価
ナラティブ・ウィーバー:マルチモーダル条件付けによる制御可能な長距離ビジュアル一貫性に向けて
ハネス更新はハネス利益ではない:自己進化型LLMエージェントにおける進化能力の解離
LongTraceRL: ルーブリック報酬を用いた検索Agent軌跡からの長文脈推論学習
信頼域行動混合によるオンポリシー蒸留
SwanVoice: 独白と対話の両方に対応する表現力のある長尺ゼロショット音声合成
ボトルネックフリー統合マルチモーダルモデルのための表現強制
GrepSeek: 直接コーパス相互作用のための検索Agentsの訓練
COLLEAGUE.SKILL:専門知識蒸留による自動AIスキル生成
エージェント型システムによる弱い推論モデルの強化
YoCausal: ビデオ生成はワールドモデルからどれくらい離れているのか? 因果性の視点から