Command Palette
Search for a command to run...
PEFTのスケーリングについて:トリリオンパラメータの百万パーソナルモデルへ向けて
PEFTのスケーリングについて:トリリオンパラメータの百万パーソナルモデルへ向けて
概要
パラメータ効率的ファインチューニング(PEFT)は、通常、フルファインチューニングに対する低コストな代替手法として扱われている。本研究では、より広範な役割、すなわち強力な共有基盤モデルの上に永続的なローカル状態として機能する小型の学習可能アダプタについて考察する。この枠組みにおいて、ベースモデルは共有された能力を提供し、アダプタは嗜好、スキル、ツールの使用習慣、記憶のような更新など、インスタンス固有の動作を担う。本研究では、この問題を3つのスケーリング軸を中心に整理する。Scale Up軸では、より強力な共有事前知識が小さなローカル更新をより有用にする。Scale Down軸では、信頼性を維持しつつアダプタをいかに小型化できるかを検討する。Scale Out軸では、多数の永続的な適応インスタンスが共存する。MinTは、アダプタの識別情報、改訂履歴、出所、評価、およびサービング時の常驻を管理するインフラストラクチャの一例を提供する。これらの結果を総合すると、PEFTはフルファインチューニングに対する単なる予算上の代替手段であるだけでなく、永続的なパーソナルモデルのためのコンパクトな基盤となり得ることが示唆される。
One-sentence Summary
Framing small trainable adapters as persistent local state on strong shared foundation models, this study addresses three coupled scaling problems to support millions of personal models of trillion parameters through large-prior LoRA reinforcement learning, δ-mem designs, and the MinT infrastructure, demonstrating that parameter-efficient fine-tuning preserves continuity across interactions and enables diversity-based aggregation.
Key Contributions
- This work reframes parameter-efficient fine-tuning as persistent local state on shared foundation models and defines three coupled scaling problems to guide adaptation research. The framework examines Scale Up via large-prior LoRA reinforcement learning, Scale Down through memory-oriented adapter designs, and Scale Out using diversity-based aggregation.
- MinT is presented as a concrete infrastructure example that supports adapter identity, policy revision, and serving residency for large adapter populations. This system enables mechanisms allowing strong foundation models to support millions of persistent personal assistants.
- Experiments from a trillion-parameter LoRA RL study show that larger base models adapted with LoRA achieve larger headroom-normalized gains than smaller models trained with full-parameter RL. These results indicate that prior strength matters more than trainable surface size when learning budgets are fixed.
Introduction
Current frontier models lack the ability to maintain persistent personal state despite advances in reasoning and tool use. Prior work treats parameter-efficient fine-tuning primarily as a cost-saving measure and relies on external retrieval for memory, which fails to capture learned behavioral habits efficiently. The authors reframe adapters as compact units of adaptive state on top of strong shared foundation models to enable persistent personal instances. They introduce a three-axis framework addressing base model strength, adapter stability, and population scaling. The team demonstrates trillion-scale LoRA reinforcement learning on a trillion-parameter Mixture of Experts model and shows that diverse adapter populations achieve collective intelligence through aggregation.
Method
The proposed architecture for persistent personal models relies on three coordinated scaling axes: Scale Up, Scale Down, and Scale Out. The authors leverage a biological analogy to illustrate how model scaling mirrors human development.
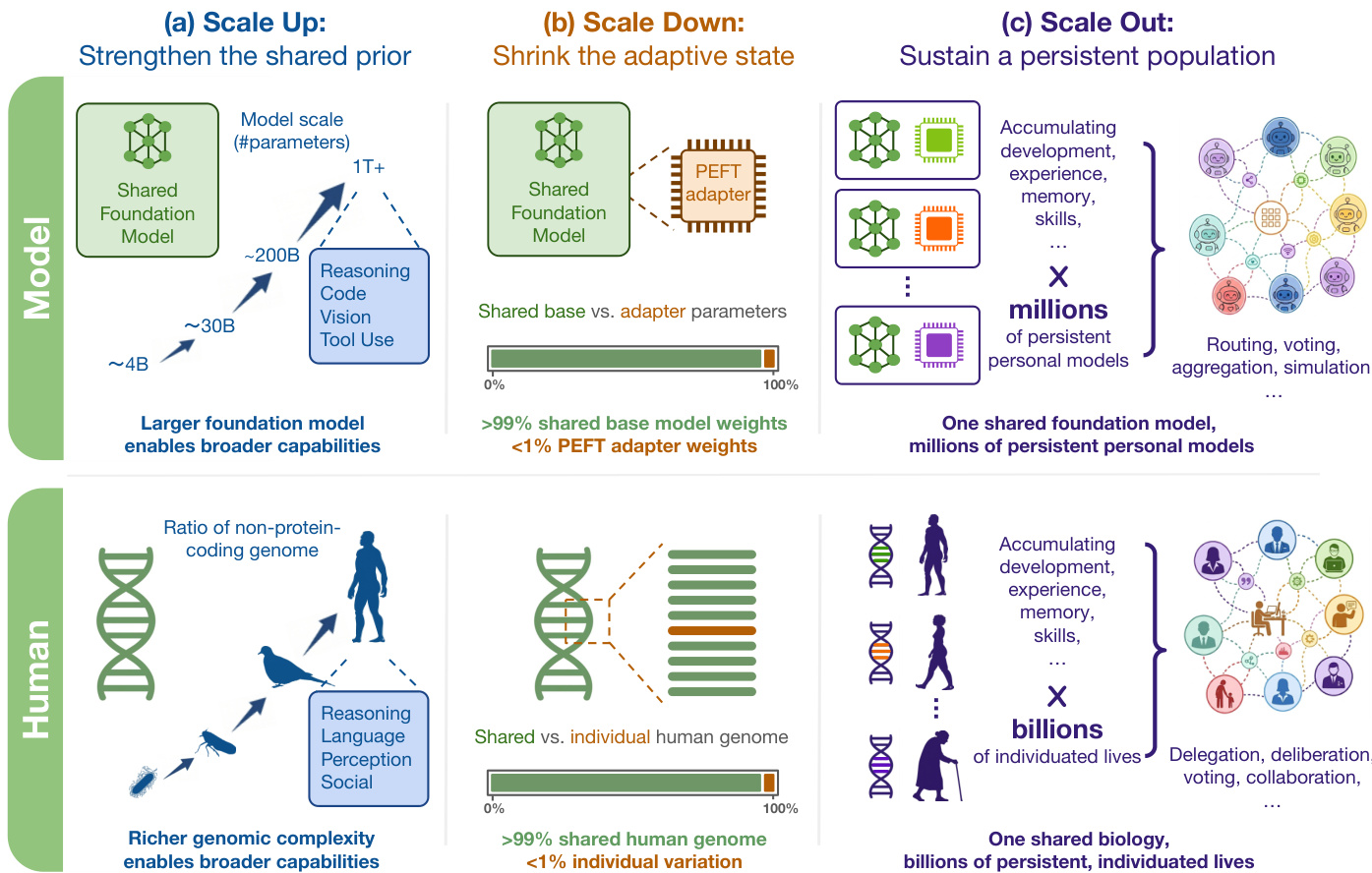
This framework separates the shared foundation model from the individual adaptive state. Scale Up strengthens the shared prior using trillion-scale parameters. Scale Down shrinks the adaptive state to ensure efficiency and stability. Scale Out sustains a persistent population of these models. The breakdown of these axes highlights the transition from individual adaptation to population-scale personalization.
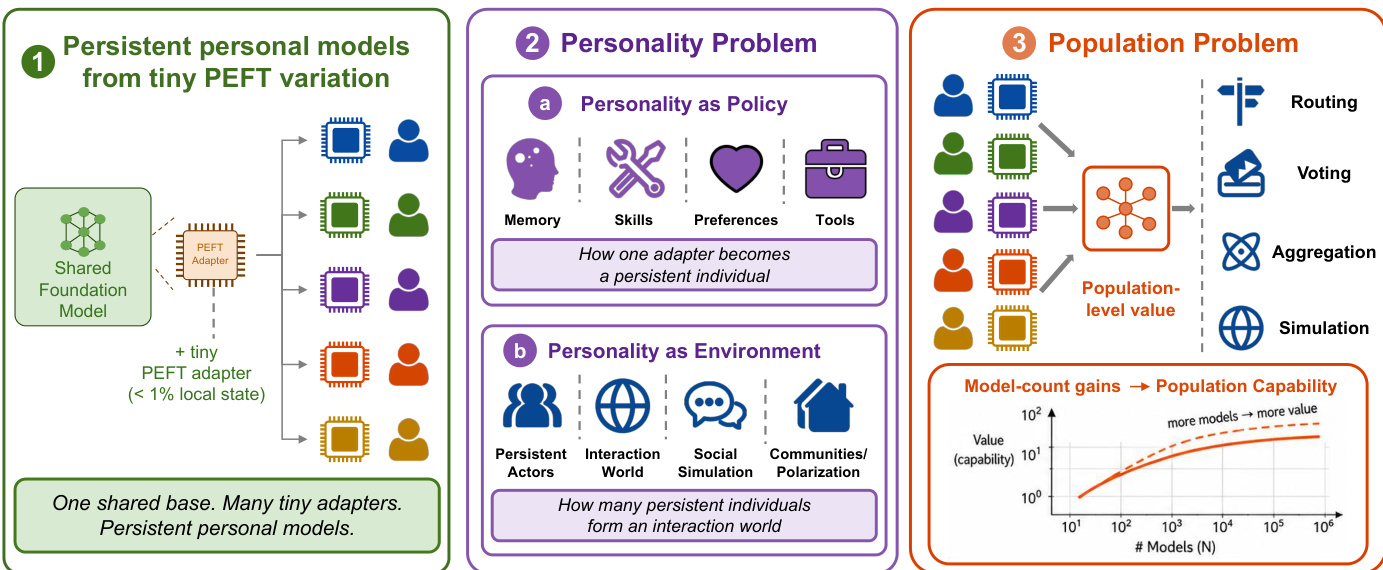
To achieve Scale Down, the system employs advanced adapter designs beyond static Low-Rank Adaptation. A key module is the δ-mem stateful adapter, which maintains a compact online associative memory state.
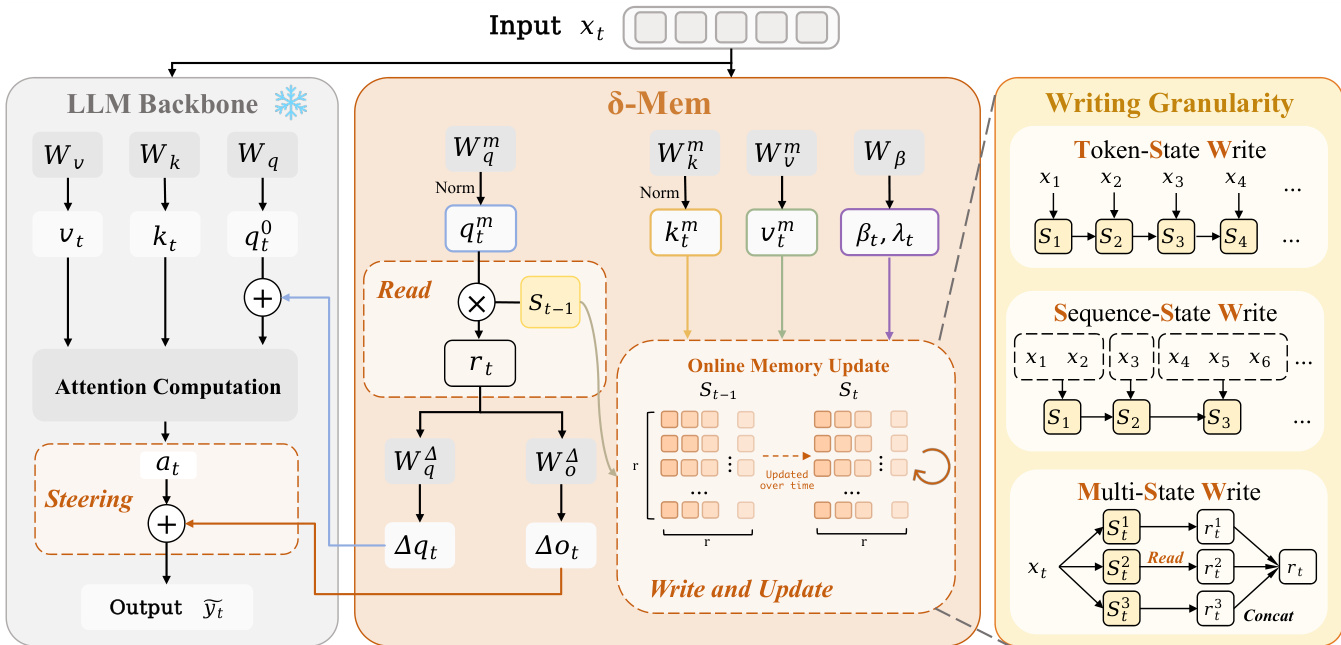
This architecture augments a frozen backbone with a low-dimensional state St. The module reads from previous memory, generates corrections, and writes updated information using a delta-rule update. This allows the adapter to accumulate interaction history without increasing the parameter count significantly.
The training process utilizes Context Distillation to convert context-time improvements into durable parameter updates. This method operates in three distinct steps.
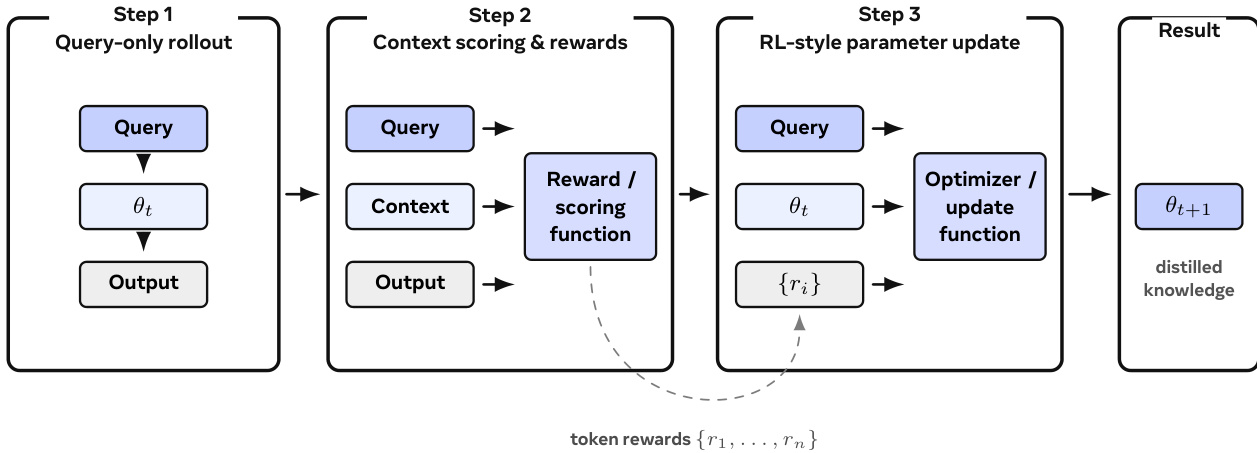
First, the model performs a query-only rollout. Second, a stronger system scores the output using retrieved evidence or tools. Third, an RL-style update adjusts the parameters based on this signal. This ensures the model learns to perform better without requiring privileged context during inference.
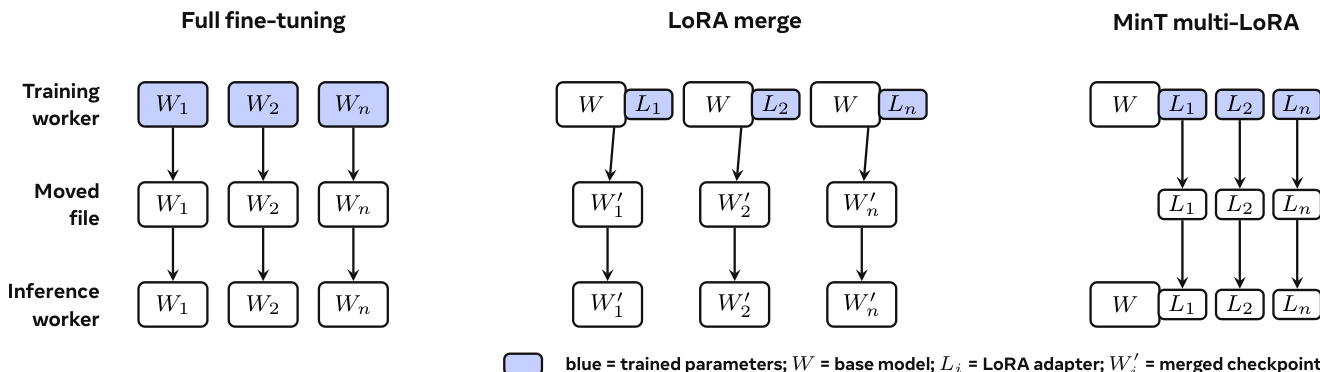
Managing this population requires a robust systems layer like MinT. The infrastructure separates training and rollout workers to handle different computational profiles.
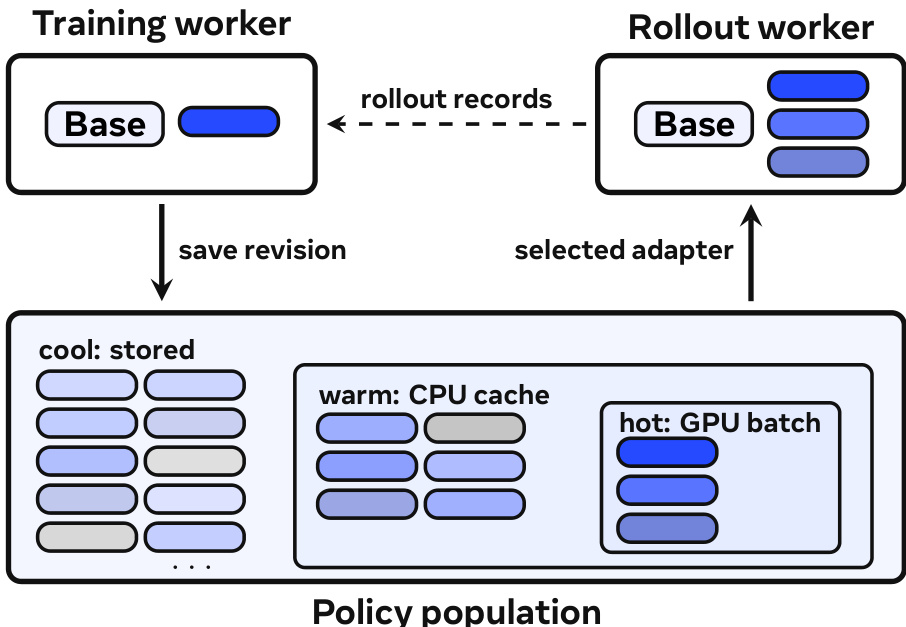
The policy population is organized into hot, warm, and cool storage tiers to optimize residency. This design supports the lifecycle of a personal model, where training updates adapter state and export saves fixed revisions for serving.
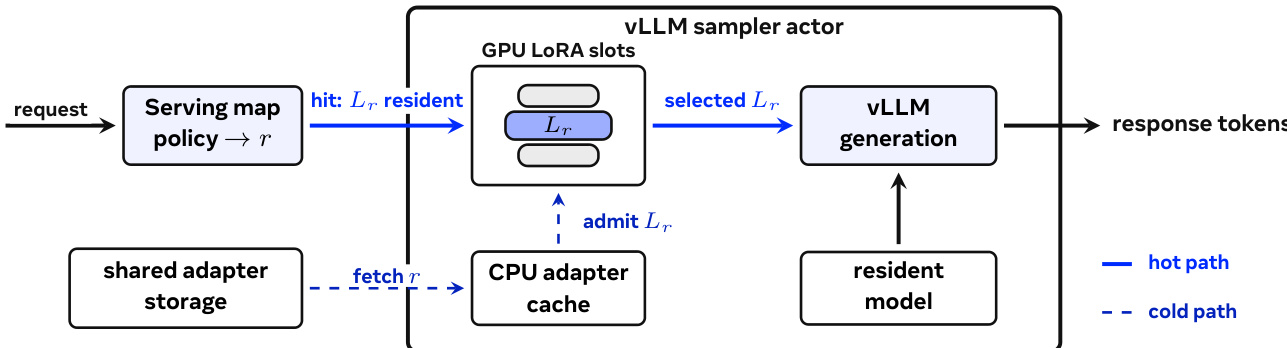
Finally, the system demonstrates that population capability grows with model count. The scaling law indicates that diversity among adapted models becomes a source of collective performance.
Experiment
Experiments evaluating rank reduction, initialization, and hyperparameter transfer reveal that low-rank adapters retain high potential but require specific optimization strategies to ensure reliability across seeds. In agent simulations and collective intelligence tasks, per-user adapters sustain behavioral diversity and performance better than shared-base models, preventing the collapse of heterogeneous populations into uniform policies. Finally, infrastructure tests demonstrate that scaling to millions of instances requires separating policy addressability from active residency to manage serving costs and latency effectively.
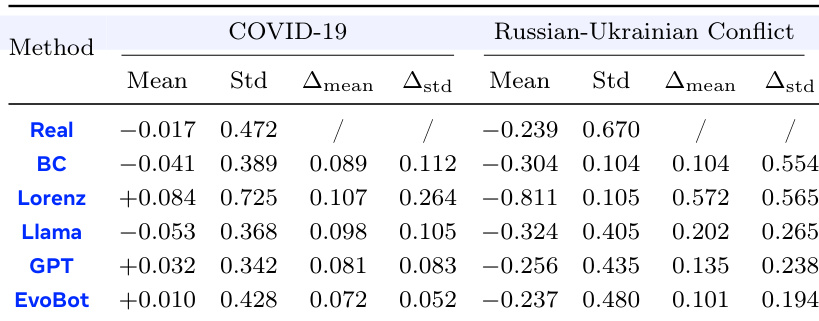
The experiment evaluates the ability of different methods to simulate real-world social dynamics during the COVID-19 pandemic and the Russian-Ukrainian Conflict. EvoBot demonstrates superior statistical alignment with real data, showing significantly lower deviation in mean and standard deviation compared to baselines like Lorenz, Llama, GPT, and Behavior Cloning. EvoBot achieves the closest match to real-world statistics across both the pandemic and conflict datasets. The Lorenz method exhibits the highest divergence from ground truth data, particularly in the Russian-Ukrainian Conflict scenario. Standard LLMs and Behavior Cloning show moderate performance but fail to match the fidelity of the EvoBot approach.
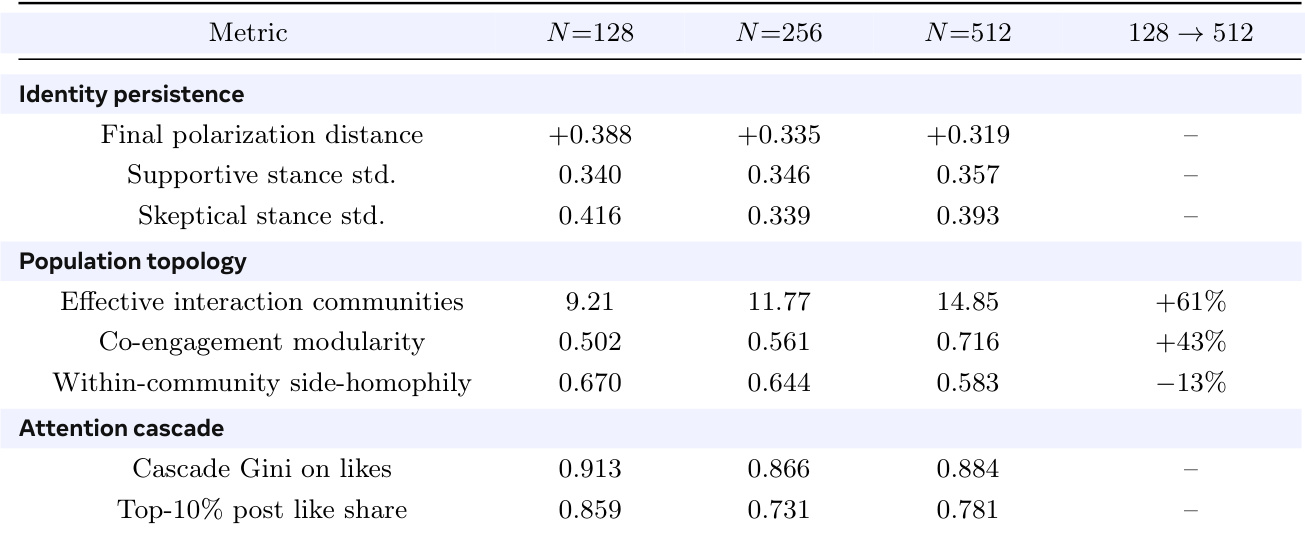
The experiment compares per-user LoRA adapters against a shared-base model in a social simulation environment with varying population sizes. The data indicates that the LoRA configuration consistently yields higher activity volumes and greater diversity in user stances. Furthermore, the LoRA population demonstrates more effective community structures with reduced homophily compared to the shared-base control. LoRA agents generate significantly more comments and original posts than the shared-base model across all tested population sizes. Stance dispersion is markedly higher in the LoRA condition, with standard deviations for supportive and skeptical users reaching roughly double the base model values. The LoRA population forms more effective interaction communities while exhibiting lower within-community side-homophily compared to the base condition.
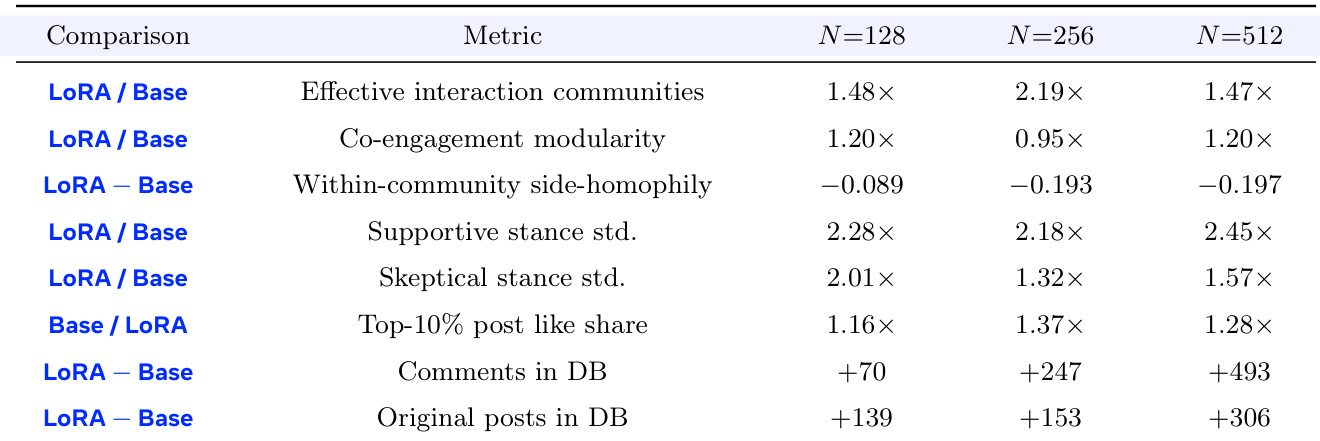
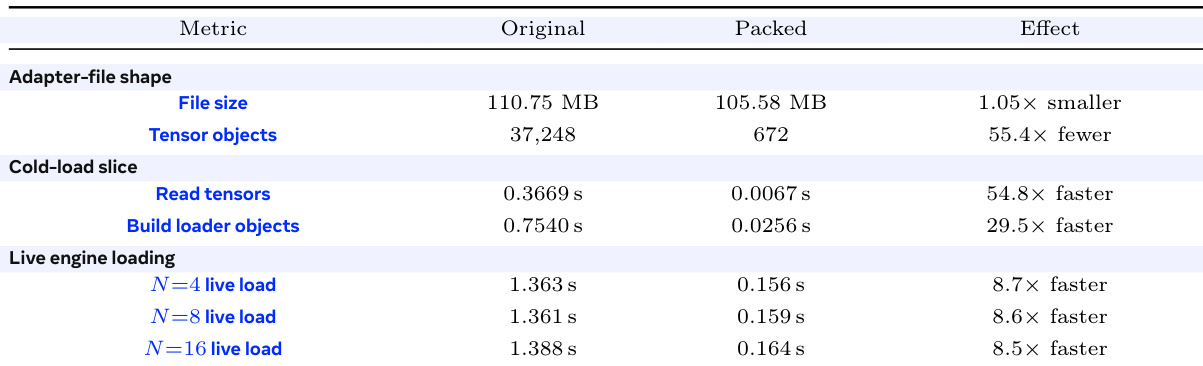
The authors evaluate a packed adapter format to optimize serving efficiency in large-scale deployments, focusing on reducing cold-load overhead. The results demonstrate that while the file size remains similar, the packed format drastically reduces the number of tensor objects, leading to substantial speedups in loading and initialization processes. Packing reduces the number of tensor objects by over 50 times while maintaining a similar file size. Cold-load operations, such as reading tensors and building loader objects, become roughly 30 to 55 times faster. Live engine loading times improve by approximately 8.5 times across different batch sizes.
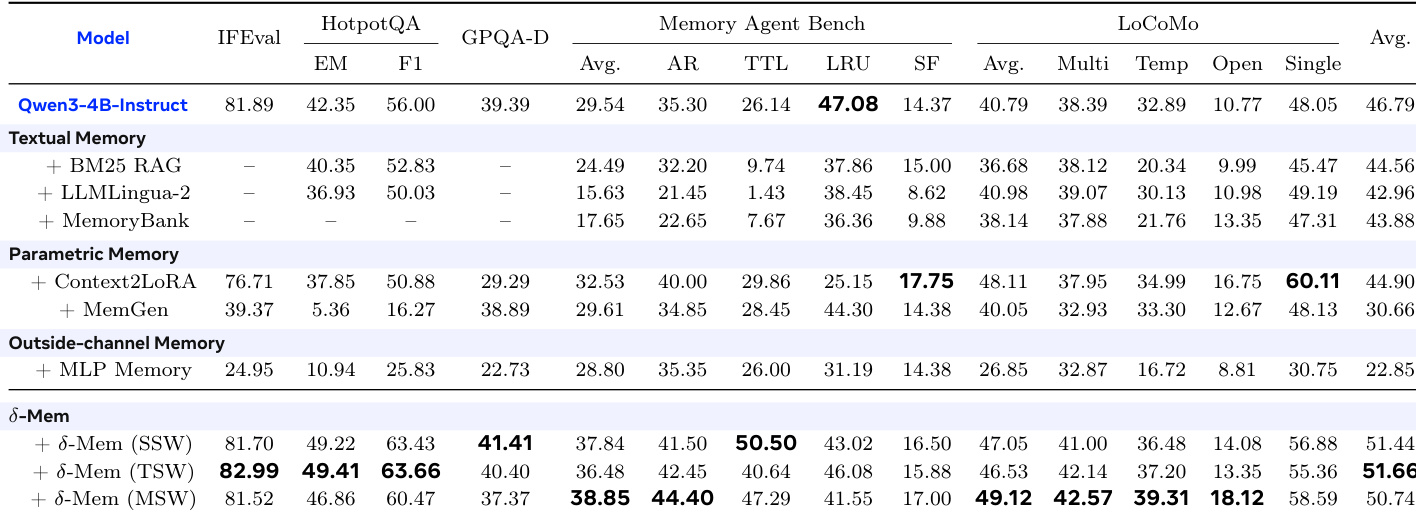
The experiment evaluates various memory mechanisms on a base model, comparing textual retrieval, parametric updates, and outside-channel methods against the proposed delta-Mem variants. Results indicate that while traditional memory augmentation often degrades performance relative to the base model, the delta-Mem configurations consistently outperform both the baseline and other memory strategies. The different delta-Mem variants demonstrate robust improvements across reasoning, memory, and instruction-following tasks. delta-Mem variants consistently achieve superior overall performance compared to the base model and alternative memory methods. Textual memory and outside-channel memory approaches generally underperform relative to the base model across the evaluated benchmarks. Specific delta-Mem configurations show distinct strengths, with different variants leading in specific categories like long-context memory or reasoning accuracy.
The authors evaluate the structural scaling of a simulated social environment using per-user LoRA adapters as the population size increases. Results demonstrate that larger populations form more distinct interaction communities with higher modularity and reduced within-group homophily. Identity metrics such as stance standard deviation remain consistent across population sizes, indicating that individual behavioral diversity is preserved during scale-out. Effective interaction communities and co-engagement modularity increase substantially as population size grows. Within-community side-homophily decreases with larger populations, fostering more diverse cross-group interactions. Stance standard deviations for supportive and skeptical users remain stable across different population scales.
The experiments validate EvoBot's superior ability to simulate real-world social dynamics across pandemic and conflict datasets compared to baseline methods, while demonstrating that per-user LoRA adapters generate more diverse activity and effective community structures than shared-base models. Efficiency evaluations confirm that a packed adapter format significantly reduces loading overhead, and memory mechanism tests show that delta-Mem variants consistently outperform traditional augmentation strategies across reasoning and instruction tasks. Additionally, structural scaling analysis reveals that increasing population size fosters distinct interaction communities and reduces homophily without compromising individual behavioral diversity.