Command Palette
Search for a command to run...
VideoMLA: 分スケールの自己回帰的動画拡散のための低ランク潜在KVキャッシュ
VideoMLA: 分スケールの自己回帰的動画拡散のための低ランク潜在KVキャッシュ
Hidir Yesiltepe Jiazhen Hu Tuna Han Salih Meral Adil Kaan Akan Kaan Oktay Hoda Eldardiry Pinar Yanardag
概要
長期ロールアウトの因果的ビデオ拡散は、固定サイズのスライディングウィンドウKVキャッシュに収束しており、最近の進展は、ウィンドウに配置されるtokensやその位置の符号化方法を変更することで、この構成内での革新を図っている。ストリーミング時のメモリ使用量とレイテンシに支配的な影響を与えるper-head KVレイアウト自体は、ほとんど変更されていない。本論文では、ビデオ拡散におけるMulti-Head Latent Attention (MLA) の初の研究事例を提示する。VideoMLAは、per-headのキーと値を、共有される低ランクのコンテンツ潜在変数と共有される分離型3D-RoPE位置キーに置き換えることで、各キャッシュ層におけるtokenあたりのKVメモリ使用量を92.7%削減する。言語モデルにおいてMLAの適用を正当化する際にしばしば用いられるスペクトル仮定が成立しないにもかかわらず、MLAがビデオ拡散タスクで成功する理由をさらに調査する。事前学習済みビデオ注意機構は低ランクではなく、99%エネルギー有効ランクは実用的な潜在次元のいずれよりもはるかに高い値を示す。VideoMLAは、直接スペクトル近似であれば大きな再構成誤差が生じると予測される圧縮率においても、品質を維持している。有効ランクを決定するのは事前学習済みスペクトルではなくMLAのボトルネックであることを示す。スペクトル初期化とランダム初期化のいずれも、初期化段階からほぼ最大のランク予算を占有しており、学習プロセスはこの予算を維持しつつ、その範囲内で適応を行う。VBenchにおいて、VideoMLAは短時間スケールのストリーミングビデオ拡散ベースラインと同等の性能を示し、評価された手法の中で長時間スケールにおいて最高の総合スコアを達成するとともに、単一のB200上でスループットを1.23倍向上させる。
One-sentence Summary
VideoMLA integrates Multi-Head Latent Attention into autoregressive video diffusion by replacing per-head key-value caches with a shared low-rank content latent and a decoupled 3D-RoPE positional key, reducing per-token KV memory by 92.7% at every cached layer while preserving generation quality despite the pretrained attention spectrum exceeding practical latent dimensions.
Key Contributions
- The paper introduces VideoMLA, the first adaptation of Multi-Head Latent Attention to long-rollout causal video diffusion, which replaces dense per-head keys and values with a shared low-rank content latent and a decoupled 3D-RoPE positional key.
- Theoretical analysis demonstrates that the MLA bottleneck, rather than the pretrained attention spectrum, determines the effective rank and enables the model to preserve generation quality at high compression ratios despite the pretrained video attention exceeding practical latent dimensions.
- Empirical evaluations show that VideoMLA reduces per-token key-value memory by 92.7% across every cached layer while maintaining generation fidelity at compression levels where direct spectral approximation would predict significant reconstruction error.
Introduction
Autoregressive video diffusion models convert bidirectional teachers into streaming students that generate frames sequentially using a rolling key-value cache, enabling efficient long-horizon video synthesis. Prior methods improve generation stability or reduce compute by optimizing cache windows or replacing attention mechanisms, yet they either preserve dense per-head key-value layouts or skip token-level compression across cached layers. The authors leverage Multi-Head Latent Attention to bridge this gap, adapting the architecture to video diffusion where memory profiles and attention spectra differ significantly from language models. By replacing traditional caches with a shared low-rank latent representation, they substantially reduce memory overhead without sacrificing streaming generation quality.
Dataset

- Dataset composition and sources: The authors do not provide dataset composition or source information in the submitted excerpt.
- Key details for each subset: No subset sizes, origins, or filtering criteria are detailed in the text.
- How the paper uses the data: The authors do not specify training splits, mixture ratios, or how the data integrates into the model.
- Processing details: The excerpt omits any cropping strategies, metadata construction, or additional preprocessing steps.
Method
The authors present VideoMLA, a novel approach to reducing the per-token key-value (KV) cache memory in causal video diffusion models by rethinking the per-head KV layout. The framework replaces dense, per-head keys and values with a shared low-rank content latent and a head-shared decoupled 3D-RoPE positional key, significantly reducing memory footprint. The core of the design is a two-part decomposition of the attention mechanism. Each video latent token xt is first compressed into a shared content latent ctKV∈Rdc via a joint down-projection W↓KV, which is written to the compressed KV cache. This latent represents the content of the token. Positional information is decoupled and stored separately. For each head h, the per-head key kt,hnope and value vt,h are reconstructed from ctKV using head-specific up-projections W↑,hK and W↑,hV. This shared latent structure means a single cache read produces all per-head keys and values, eliminating the need to store dense per-head states for each token. The positional information is handled by a separate RoPE branch. A single, head-shared positional key ktR is computed from xt via WRK and stored in the cache. At attention time, this unrotated key is rotated by 3D-RoPE to produce ktrope, which is used in the attention score calculation. The query path follows a similar structure, with a query latent ctQ derived from xt, and a head-specific positional query qt,hR computed from ctQ and rotated. The attention score for head h combines the content-based score from the inner product of qt,hnope and kt,hnope with the positional score from qt,hrope and ktrope. This design reduces the per-token cache size from 2nhdh scalars to dc+dhrope. As shown in the figure below, this results in a significant reduction in memory and a more efficient inference process, as the cache stores a compressed content latent and a shared positional key, with the per-head components reconstructed only when needed for attention computation.

Experiment
The evaluation combines fixed-memory batch scaling tests with a human perceptual study to assess prompt adherence, temporal coherence, and motion consistency in generated videos. Ablation experiments validate that VideoMLA effectively converts cache compression into substantial serving headroom while establishing a clear quality-efficiency trade-off in latent dimension selection. The findings demonstrate that moderate compression preserves essential visual details and that balancing cached content with positional encoding channels optimally supports streaming video generation. These results confirm the method's practical deployment potential, with future work targeting extended horizons and higher resolutions.
The authors analyze the memory and computational complexity of different attention mechanisms, showing that MLA Local reduces memory and computation compared to causal full and causal linear variants by leveraging a compressed latent representation and a split attention design. Results indicate that the proposed approach achieves significant reductions in both metrics while maintaining efficiency and performance. MLA Local reduces memory and computational complexity compared to causal full and causal linear attention mechanisms. The approach achieves lower memory and computation by using a compressed latent representation and a split attention design. The design allows for efficient scaling while maintaining performance through optimized resource allocation.
The authors conduct ablation studies to analyze the impact of key hyperparameters on VideoMLA's performance, focusing on memory efficiency and quality trade-offs. Results show that reducing the KV cache dimension significantly improves memory scalability while maintaining acceptable quality, with optimal performance achieved through a balanced allocation of channels between cached content and positional encoding. The model is trained in three stages using a combination of teacher forcing, consistency distillation, and distribution matching distillation. Reducing the KV cache dimension leads to substantial memory savings and enables larger batch sizes without exceeding memory limits. A balanced allocation of channels between cached content and positional encoding yields the best performance, with a dedicated RoPE subspace improving temporal and spatial coherence. The training pipeline involves multiple stages, including teacher forcing, consistency distillation, and distribution matching distillation, to optimize the model for efficient inference.

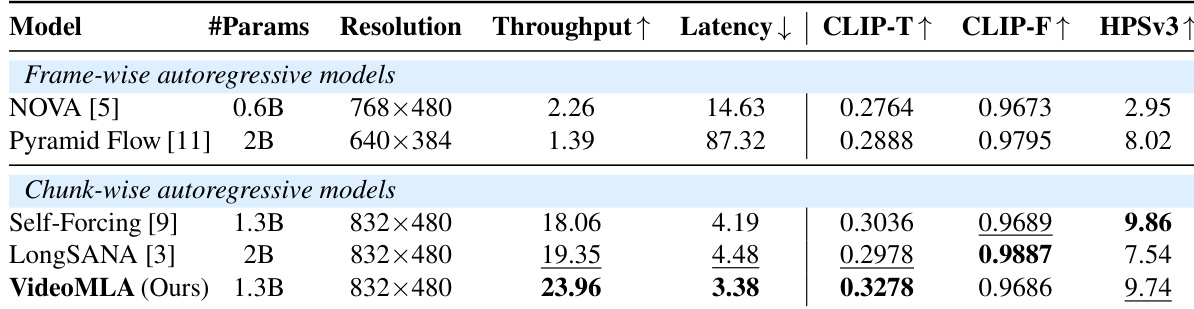
The authors compare VideoMLA against other autoregressive models in terms of parameters, resolution, throughput, latency, and performance on CLIP and HPSv3 metrics. Results show that VideoMLA achieves higher throughput and lower latency compared to frame-wise models, while maintaining competitive or superior performance on quality metrics. VideoMLA achieves higher throughput and lower latency than frame-wise autoregressive models. VideoMLA outperforms other chunk-wise autoregressive models in CLIP-T and HPSv3 scores. VideoMLA demonstrates a balance between efficiency and quality, achieving competitive performance with reduced latency.
The authors conduct ablation studies to evaluate the impact of latent dimension and positional encoding configurations on model performance. Results show that increasing the latent dimension improves quality but reduces memory efficiency, while the balance between positional and content channels significantly affects both semantic fidelity and temporal coherence. The optimal configuration achieves a trade-off between memory savings and video quality. Increasing the latent dimension improves quality but reduces memory efficiency, with diminishing returns at higher values. The split between positional and content channels affects semantic fidelity and temporal coherence, with an optimal balance favoring content channels. The best-performing configuration achieves a balance between memory savings and video quality by optimizing both latent dimension and channel split.

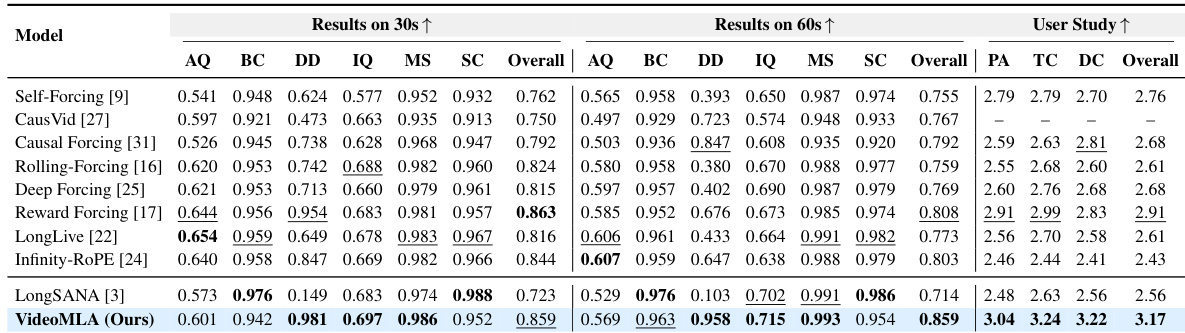
The authors compare their VideoMLA model against several baselines across multiple metrics, including quality and consistency scores. Results show that VideoMLA achieves competitive or superior performance on most evaluation criteria, particularly in long-horizon generation and perceptual quality, while maintaining efficient memory usage through latent compression. VideoMLA outperforms or matches existing methods on key quality and consistency metrics across different generation lengths. The model achieves high perceptual quality in user studies, with strong ratings in prompt adherence and motion consistency. VideoMLA maintains strong performance while significantly reducing memory requirements through efficient latent compression.
The experimental evaluation assesses the memory efficiency, computational complexity, and generation quality of VideoMLA through ablation studies and comparative benchmarks against existing autoregressive models. Results validate that compressed latent representations and split attention designs substantially reduce resource consumption while preserving core model capabilities. Hyperparameter analyses further demonstrate that balancing cached content with positional encoding and optimizing latent dimensions achieves an ideal trade-off between memory savings and video fidelity. Ultimately, the approach delivers competitive generation quality and temporal consistency alongside significantly reduced latency compared to conventional frame-wise baselines.