HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

SwanVoice: 独白と対話の両方に対応する表現力のある長尺ゼロショット音声合成

ボトルネックフリー統合マルチモーダルモデルのための表現強制


























SwanVoice: 独白と対話の両方に対応する表現力のある長尺ゼロショット音声合成
ボトルネックフリー統合マルチモーダルモデルのための表現強制
GrepSeek: 直接コーパス相互作用のための検索Agentsの訓練
COLLEAGUE.SKILL:専門知識蒸留による自動AIスキル生成
エージェント型システムによる弱い推論モデルの強化
YoCausal: ビデオ生成はワールドモデルからどれくらい離れているのか? 因果性の視点から
minWM: リアルタイムインタラクティブビデオワールドモデルのためのフルスタックオープンソースフレームワーク
CollectionLoRA: マルチティーチャー・オンポリシー蒸留により1つのLoRAに50の効果を収集する
OmniRetrieval: 異種知識源を横断する統一検索
Qwen-VLA: タスク、環境、およびロボット具現化にわたる視覚・言語・行動モデリングの統合
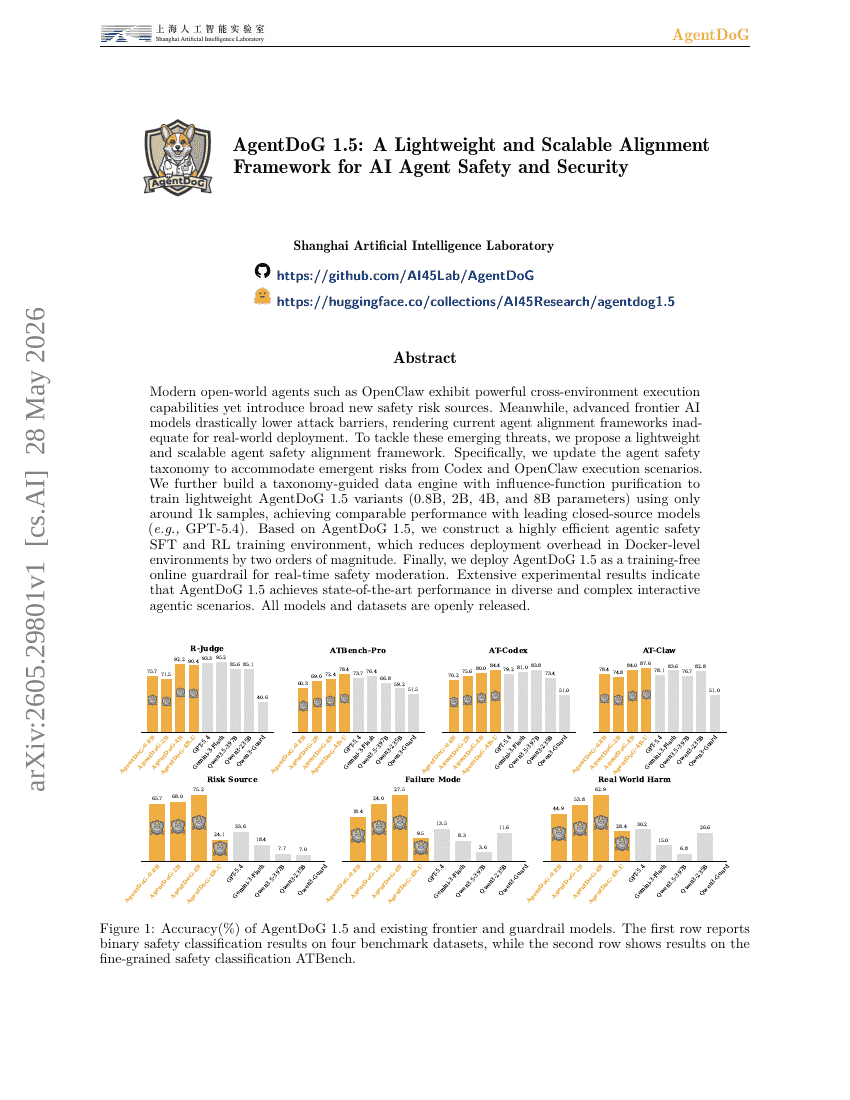
AgentDoG 1.5: AI Agentの安全性とセキュリティのための軽量かつスケーラブルなアライメントフレームワーク
ワールドアクションモデル:具現化AIの新たなフロンティア
ワールドアクションモデルはゼロショットポリシーである
ResearchMath-14K: Agentsによる研究レベルの数学のスケーリング
双方向進化的探索を用いた自己改善型言語モデル
ピクセルから単語へ -- 大規模なネイティブワンビジョンモデルに向けて
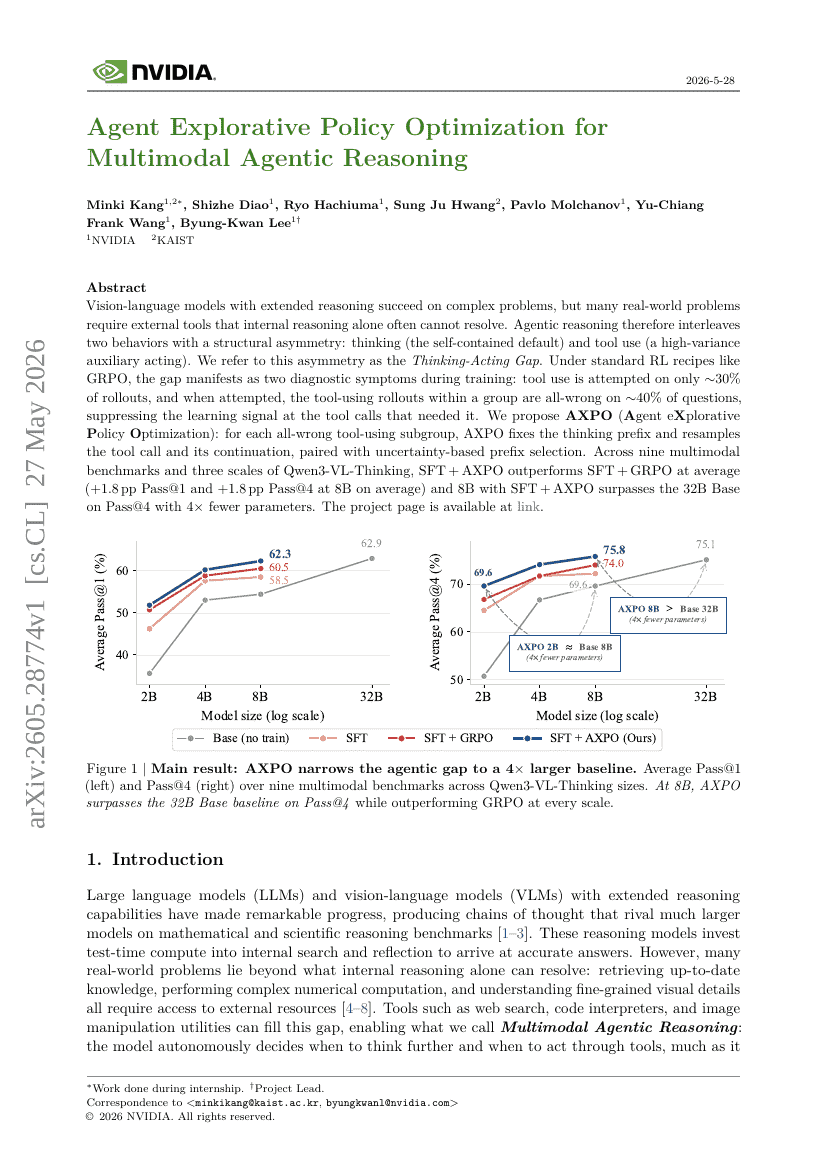
Agent探索的方策最適化のためのマルチモーダルエージェント推論
ProRL: 補正ポリシー勾配推定による能動的推薦のための効果的な強化学習
ガンマ・ワールド:2人プレイヤーを超えた生成型Multi-Agent世界モデル構築
AutoFigure: 出版準備が整った科学的図像の生成と精緻化
AutoResearch AI: 科学発見のためのAI主導型研究自動化に向けて
エージェント・ハーネス工学:調査
D^2-Monitor:Diffusion LLMs に対する動的安全性監視 ~躊躇認識型ルーティングによる~
堅牢なマルチビュー3D再構成のための幾何構造を考慮した表現のノイズ除去
EvalVerse: プロフェッショナルシネマティック動画生成のためのパイプライン対応型および専門家較正型ベンチマーク
MobileGym: モバイルGUI Agent研究のための検証可能かつ高並列シミュレーションプラットフォーム
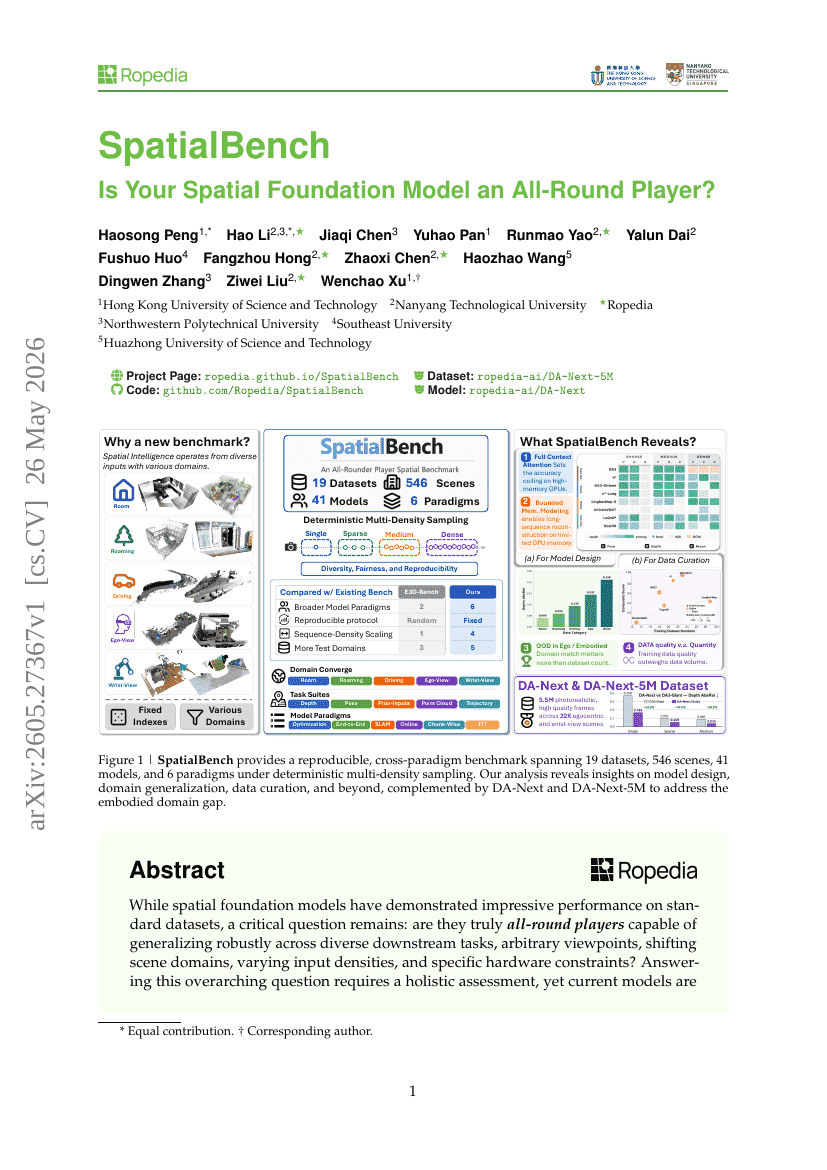
SpatialBench: あなたの空間基盤モデルは万能選手ですか?
LocateAnything: 並列ボックスデコーディングによる高速かつ高品質な視覚言語グラウンディング
Gemini Embedding 2: ジェミニ由来のネイティブマルチモーダル埋め込みモデル
言語モデルは睡眠を必要とする
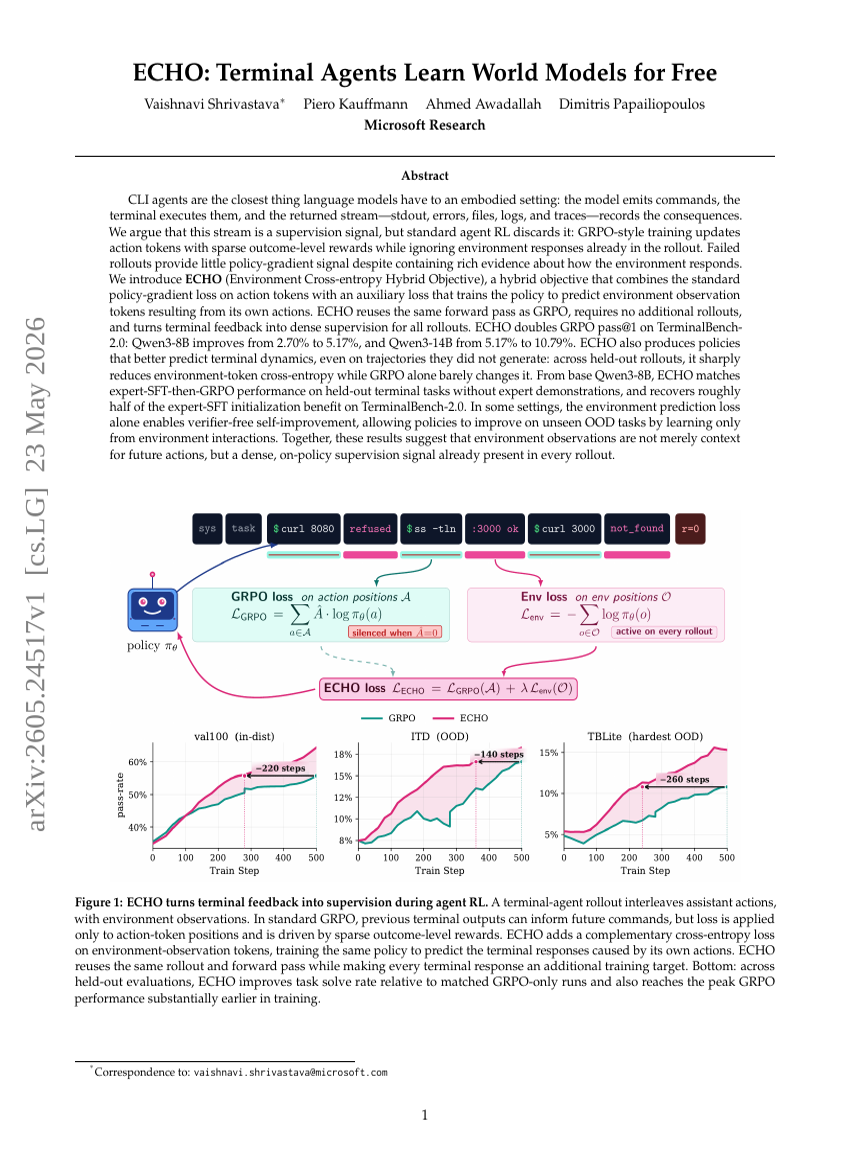
ECHO: ターミナルエージェントが無償でワールドモデルを学習する
ParaVT: エージェント型動画強化学習における並列ツール使用のためのツール事前知識のパラドックスを制御する
GrepSeek: 直接コーパス相互作用のための検索Agentsの訓練
COLLEAGUE.SKILL:専門知識蒸留による自動AIスキル生成
エージェント型システムによる弱い推論モデルの強化
YoCausal: ビデオ生成はワールドモデルからどれくらい離れているのか? 因果性の視点から
minWM: リアルタイムインタラクティブビデオワールドモデルのためのフルスタックオープンソースフレームワーク
CollectionLoRA: マルチティーチャー・オンポリシー蒸留により1つのLoRAに50の効果を収集する
OmniRetrieval: 異種知識源を横断する統一検索
Qwen-VLA: タスク、環境、およびロボット具現化にわたる視覚・言語・行動モデリングの統合
AgentDoG 1.5: AI Agentの安全性とセキュリティのための軽量かつスケーラブルなアライメントフレームワーク
ワールドアクションモデル:具現化AIの新たなフロンティア
ワールドアクションモデルはゼロショットポリシーである
ResearchMath-14K: Agentsによる研究レベルの数学のスケーリング
双方向進化的探索を用いた自己改善型言語モデル
ピクセルから単語へ -- 大規模なネイティブワンビジョンモデルに向けて
Agent探索的方策最適化のためのマルチモーダルエージェント推論
ProRL: 補正ポリシー勾配推定による能動的推薦のための効果的な強化学習
ガンマ・ワールド:2人プレイヤーを超えた生成型Multi-Agent世界モデル構築
AutoFigure: 出版準備が整った科学的図像の生成と精緻化
AutoResearch AI: 科学発見のためのAI主導型研究自動化に向けて
エージェント・ハーネス工学:調査
D^2-Monitor:Diffusion LLMs に対する動的安全性監視 ~躊躇認識型ルーティングによる~
堅牢なマルチビュー3D再構成のための幾何構造を考慮した表現のノイズ除去
EvalVerse: プロフェッショナルシネマティック動画生成のためのパイプライン対応型および専門家較正型ベンチマーク
MobileGym: モバイルGUI Agent研究のための検証可能かつ高並列シミュレーションプラットフォーム
SpatialBench: あなたの空間基盤モデルは万能選手ですか?
LocateAnything: 並列ボックスデコーディングによる高速かつ高品質な視覚言語グラウンディング
Gemini Embedding 2: ジェミニ由来のネイティブマルチモーダル埋め込みモデル
言語モデルは睡眠を必要とする
ECHO: ターミナルエージェントが無償でワールドモデルを学習する
ParaVT: エージェント型動画強化学習における並列ツール使用のためのツール事前知識のパラドックスを制御する