Command Palette
Search for a command to run...
GrepSeek: 直接コーパス相互作用のための検索Agentsの訓練
GrepSeek: 直接コーパス相互作用のための検索Agentsの訓練
Alireza Salemi Chang Zeng Atharva Nijasure Jui-Hui Chung Razieh Rahimi Fernando Diaz Hamed Zamani
概要
大規模言語モデル(LLM)検索agentsは、複数回の推論と情報検索を通じて、知識集約型言語タスクにおいて強い可能性を示している。既存のシステムの多くは、キーワードまたは自然言語クエリを入力として受け取り、事前計算された文書表現のインデックスを用いて文書のランク付けリストを返すretrieverを用いて情報にアクセスする。本研究では、検索agentがコーパス自体を検索環境として扱い、実行可能なシェルコマンドを発行することで証拠を検出する補完的な視点を探求する。本研究では、大規模テキストコーパスから証拠を検出し、フィルタリングし、構成するコンパクトな検索agentを訓練する最適化された直接コーパス相互作用(DCI)検索agentであるGrepSeekを紹介する。大規模コーパス上で強化学習を用いて行動を直接学習することに伴う不安定性に対処するため、本研究では二段階の訓練パイプラインを提案する。第一に、検証済みで因果的に根拠のある検索軌道を生成するために、回答参照型Tutorと回答非参照型Plannerを用いてコールドスタートデータセットを構築する。第二に、初期化された方策をGroup Relative Policy Optimization(GRPO)で精緻化し、agentがコーパスとの直接相互作用を通じてタスク指向の検索行動を改善できるようにする。DCIをスケーラブルに実用的なものとするため、さらに、シェルベースの検索を最大7.6imes加速しつつ、シェルコマンドの逐次実行とのバイトレベルの完全な一致を維持する意味保存型シャーデッド並列実行エンジンを使用する。7つのオープンドメイン質問応答ベンチマークにわたる実験により、GrepSeekが最も強力な全体としてのtokenレベルのF1およびExact Matchを達成することが示された。本研究の分析は、表記の変動が大きいクエリに対する純粋な語彙的相互作用の限界も浮き彫りにしており、現実世界において既存の検索パラダイムを補完しうる実用的かつ競争力のあるsearch agentsのための手法としてDCIを提案する。
One-sentence Summary
GrepSeek is a direct corpus interaction search agent that replaces traditional index-based retrieval with executable shell commands, employing a two-stage training pipeline that first generates verified trajectories using an answer-aware Tutor and answer-blind Planner and then refines the policy via Group Relative Policy Optimization, all accelerated by a semantics-preserving sharded-parallel execution engine for scalable evidence retrieval.
Key Contributions
- This work introduces GrepSeek, a direct corpus interaction search agent that replaces conventional embedding-based retrievers with executable shell commands to locate, filter, and synthesize evidence from raw text corpora.
- A two-stage training pipeline stabilizes reinforcement learning on large corpora by generating verified search trajectories via an answer-aware Tutor and answer-blind Planner, followed by policy refinement through Group Relative Policy Optimization.
- A semantics-preserving sharded-parallel execution engine accelerates shell-based retrieval by up to sevenfold, and empirical evaluations on single-hop and multi-hop question-answering benchmarks demonstrate enhanced task-oriented reasoning and evidence composition.
Introduction
Large language model search agents are increasingly deployed for complex, knowledge-intensive tasks that require multi-step reasoning and evidence synthesis across vast text collections. Traditional retrieval-augmented systems rely on pre-computed document indices, which frequently introduce semantic conflation and rigid chunking boundaries that undermine exact entity matching and fine-grained lexical filtering. Although recent Direct Corpus Interaction approaches bypass these indices by executing shell commands on raw data, they depend heavily on prompting large proprietary models at inference time, leading to prohibitive computational costs, slow response times, and unstable reinforcement learning trajectories for compact agents. To overcome these barriers, the authors introduce GrepSeek, a trained open-weight search agent that learns to interact directly with unstructured corpora through deterministic shell operations. They stabilize policy development using a backward-chaining Tutor and forward-Planner framework, refine search behavior with Group Relative Policy Optimization, and implement a semantics-preserving sharded-parallel execution engine that cuts retrieval latency by up to 7.6 times. This integrated approach transforms direct corpus interaction into a scalable, low-latency alternative to index-based retrieval, delivering statistically significant gains on multi-hop reasoning benchmarks while maintaining byte-exact lexical precision.
Dataset

-
Dataset composition and sources: The authors evaluate their approach on a standardized suite of seven knowledge-intensive question answering benchmarks sourced from the FlashRAG repository. The collection is divided into single-hop tasks for targeted fact retrieval and multi-hop tasks for iterative corpus exploration. All evaluations operate on a 2018 Wikipedia dump containing 21 million documents formatted as a single JSONL file.
-
Key details for each subset:
- Natural Questions (NQ): Open-domain split featuring real user queries that require matching Wikipedia passages to answer questions without prior context.
- TriviaQA: Curated trivia questions where answers are typically contained within a single retrieved document.
- PopQA: Entity-centric dataset built from Wikidata triples, specifically targeting rare entities to test long-tail knowledge retrieval.
- HotpotQA: Multi-hop questions designed to force reasoning across at least two distinct Wikipedia articles.
- 2WikiMultihopQA: Constructed using Wikidata properties to enforce explicit logical chains and strict reasoning steps across multiple documents.
- MuSiQue: Rigorously filtered multi-hop dataset that chains single-hop questions to eliminate shortcut reasoning and lexical overlap.
- Bamboogle: Manually crafted questions engineered to defeat standard search engines, demanding deep multi-step evidence gathering. Exact dataset sizes for training and evaluation splits are documented in the appendix table.
-
How the paper uses the data: The authors restrict training to the official training sets of NQ and HotpotQA while treating the remaining five datasets as out-of-distribution evaluation sets. For supervised fine-tuning, they construct a 10,000-sample cold-start dataset using a balanced mixture of HotpotQA and NQ examples, trained for one epoch. This policy is subsequently optimized via GRPO reinforcement learning for 200 steps across the full HotpotQA and NQ training splits. During evaluation, they report token-level F1 scores on official test splits, falling back to development sets only when test labels are unavailable, and provide exact match scores in the appendix.
-
Processing details: Rather than traditional cropping or metadata extraction, the pipeline treats the entire Wikipedia corpus as a flat text file where each line represents one passage. The system prompt enforces a shell-based interaction strategy, instructing the model to pipe search results through commands like
head -n 3orhead -n 8to cap output volume and prevent context overflow. The authors generate synthetic multi-turn trajectories during data construction to teach the model how to alternate between plain-text reasoning steps and single-pipeline shell commands. All benchmarks are standardized through FlashRAG to ensure consistent formatting and evaluation protocols.
Method
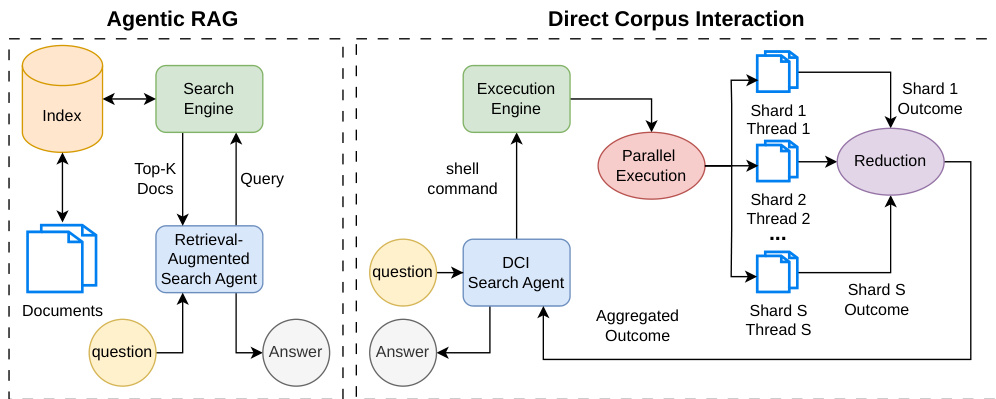
The authors leverage a two-stage training framework to develop GrepSeek, a direct corpus interaction (DCI) search agent that operates within the ReAct framework, enabling it to perform multi-hop reasoning and information retrieval by issuing executable shell commands directly against a raw text corpus. The overall architecture, illustrated in the framework diagram, contrasts with traditional Retrieval-Augmented Generation (RAG) systems that rely on pre-computed indices. Instead, the DCI agent interacts with the corpus through a series of shell commands, such as grep and rg, to find, filter, and compose evidence. The agent's policy, denoted as πθ, generates a trajectory consisting of reasoning traces and actions based on the question and the history of previous interactions. Actions are either shell commands or a termination that outputs the final answer, with the execution engine returning observations that inform subsequent steps.
The training process begins with the construction of a high-quality, cold-start dataset to stabilize the initial policy. This is achieved through a two-phase pipeline that uses an answer-aware Tutor LLM and an answer-blind Planner LLM to generate verified, causally grounded search trajectories. In the backward phase, the Tutor decomposes the query and gold answer into a sequence of sub-queries and then works backward to generate a shell command for each sub-query, ensuring the command does not leak the answer by masking it and its aliases. The Tutor iteratively refines the command and verifies the retrieved document supports the target answer, constructing a multi-hop evidence chain. This chain is then reversed into chronological order for the forward phase. In the forward phase, the answer-blind Planner generates a reasoning trace and action proposal based solely on the causal history, which the Tutor then aligns with the verified command, ensuring the reasoning is grounded in observable evidence. This process produces trajectories that are both realistic and reliable.
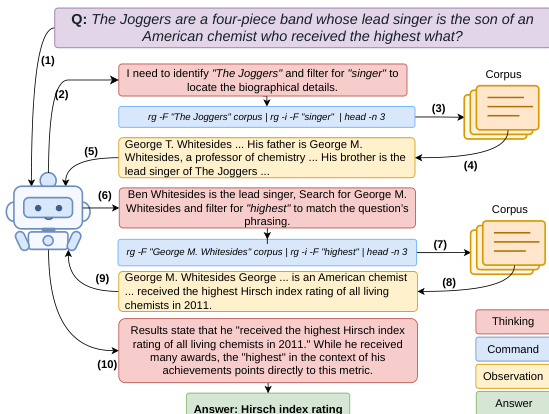
After generating the cold-start data, the policy is first supervised fine-tuned (SFT) on these synthetic trajectories to initialize it with stable and causally grounded retrieval behavior. The SFT stage teaches the agent to produce concise commands and avoid excessive context retrieval. Following SFT, the policy is further optimized using Group Relative Policy Optimization (GRPO). For each query, the policy samples a group of five trajectories, and each trajectory receives a reward based on the token-level F1 score between the predicted answer and the gold answer, combined with a binary format indicator that verifies the structural validity of the trajectory. The GRPO algorithm computes a relative advantage within each group, which encourages trajectories that outperform others for the same query while reducing sensitivity to reward scale. This two-stage approach, combining synthetic data generation with GRPO, addresses the instability of learning directly with reinforcement learning on large corpora.

To make DCI practical at scale, the system employs a sharded-parallel execution engine that accelerates shell-based retrieval by up to 7.6× while preserving byte-exact equivalence with sequential execution. This engine performs a one-time, line-aligned sharding of the corpus into S disjoint partitions. At inference time, compatible shell pipelines are executed in parallel across the S shards using a thread pool. The engine dynamically classifies each pipeline to determine if it can be safely parallelized. Pipelines composed entirely of stateless transformations (e.g., cut, tr, line-wise sed) are evaluated independently on each shard. The final output is reconstructed using a strategy-specific reduction rule, such as deterministic concatenation for purely stateless pipelines or a k-way merge for top-K retrieval pipelines. This approach substantially improves retrieval throughput while ensuring behavioral equivalence to sequential execution. The system further reduces latency by using a persistent search daemon that keeps the corpus in memory and avoids repeated process startup and corpus loading across successive tool calls.
Experiment
Evaluated across seven open-domain question-answering benchmarks using a strict in-distribution and out-of-distribution split, the experiments assess GrepSeek against dense and sparse retrieval baselines through performance comparisons, efficiency analyses, ablation studies, and qualitative case reviews. These evaluations validate that direct corpus interaction via shell commands excels at precise lexical matching and iterative evidence filtering, substantially improving multi-hop reasoning and entity disambiguation while drastically reducing memory and indexing overhead. However, the approach inherently lacks semantic ranking and remains vulnerable to surface-form variations, which occasionally limits its effectiveness on broadly paraphrased queries. Ultimately, the findings confirm that structured, interpretable shell-based retrieval serves as a highly precise and resource-efficient alternative to embedding-driven systems for complex reasoning tasks.
The ablation study evaluates the impact of different training stages on GrepSeek's performance across single-hop and multi-hop benchmarks. Results show that both the supervised fine-tuning (SFT) and reinforcement learning (GRPO) stages are crucial, as removing either leads to significant performance drops. The model without GRPO performs worse than the full model on all datasets, while the variant without SFT shows the most severe degradation, particularly on multi-hop tasks. The full model achieves the highest average score, demonstrating the importance of both stages for effective retrieval and reasoning. Removing either the supervised fine-tuning or reinforcement learning stage leads to significant performance drops across all benchmarks. The model without reinforcement learning performs worse than the full model on every dataset, indicating the importance of policy optimization. The variant without supervised fine-tuning shows the largest overall performance drop, highlighting the necessity of structured trajectory initialization before reinforcement learning.

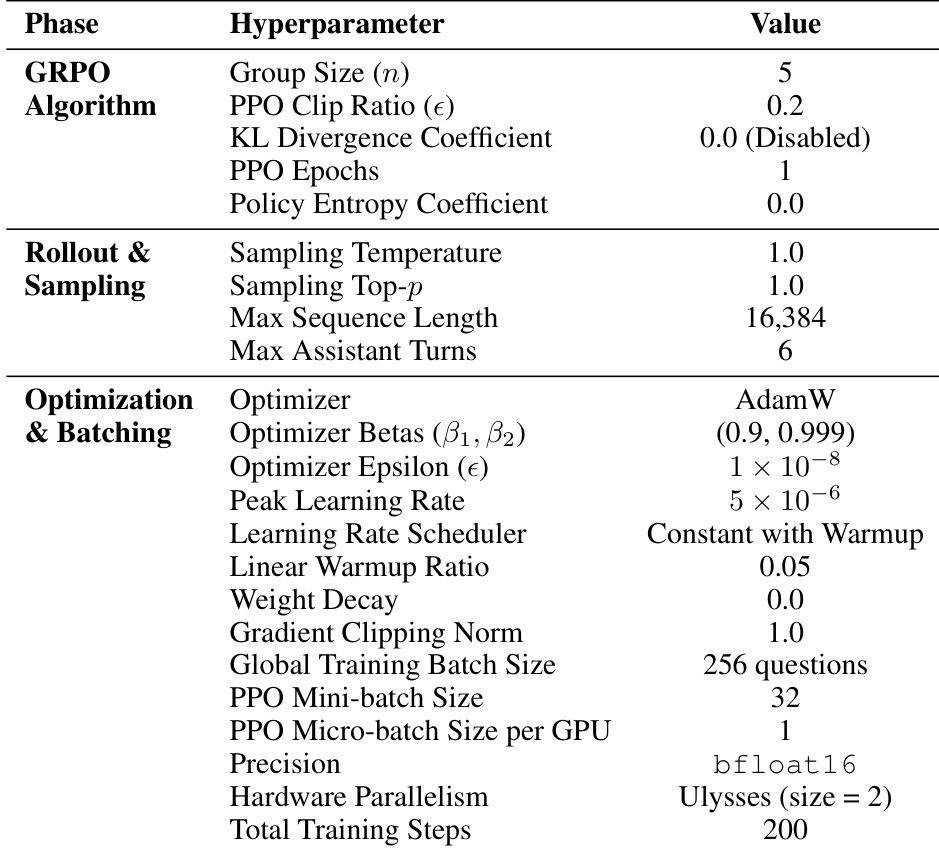
The authors analyze the reinforcement learning configuration for GrepSeek, focusing on the GRPO training phase. The setup uses a group size of five trajectories per query, a PPO clip ratio of 0.2, and disables KL divergence and policy entropy penalties. During rollout, the system employs a sampling temperature of 1.0 and a top-p of 1.0, with a maximum sequence length of 16,384 tokens and up to six assistant turns. Training is conducted using AdamW with a peak learning rate of 5e-6, a linear warmup, and a constant schedule over 200 steps, utilizing bfloat16 precision and Ulysses sequence parallelism. GRPO uses a group size of five trajectories and a PPO clip ratio of 0.2, with no KL divergence or policy entropy penalties. Rollout settings include a sampling temperature of 1.0 and a top-p of 1.0, with a maximum sequence length of 16,384 tokens and six assistant turns. Training uses AdamW with a peak learning rate of 5e-6, a constant schedule after linear warmup, and runs for 200 steps with bfloat16 precision and Ulysses parallelism.
{"summary": "The ablation study compares GrepSeek with variants lacking reinforcement learning optimization or supervised fine-tuning, showing that both training stages are critical for performance. Removing either component leads to significant drops across all datasets, with the absence of supervised fine-tuning causing the most severe degradation. GrepSeek consistently outperforms both ablated variants on multi-hop benchmarks, indicating that structured trajectory initialization and policy optimization are essential for effective retrieval and reasoning.", "highlights": ["GrepSeek significantly outperforms variants without reinforcement learning or supervised fine-tuning across all datasets.", "The absence of supervised fine-tuning causes the largest performance drop, highlighting its importance for stable policy training.", "GrepSeek maintains a clear advantage over ablated variants on multi-hop benchmarks, indicating the value of both training stages for complex reasoning tasks."]

The authors evaluate GrepSeek, a system that uses direct corpus interaction through shell commands for retrieval-augmented reasoning. Results show that GrepSeek achieves superior performance on multi-hop reasoning tasks compared to dense and sparse retrieval baselines, particularly due to its precise lexical filtering and iterative evidence aggregation. However, it exhibits limitations in handling semantic variations and surface-form differences, where dense retrieval methods perform better. The system's efficiency is characterized by low memory footprint and no offline indexing cost, though it incurs higher inference latency due to longer reasoning trajectories. GrepSeek outperforms retrieval baselines on multi-hop reasoning tasks by leveraging precise lexical filtering and iterative evidence aggregation. The system's reliance on exact string matching makes it sensitive to surface-form variations, leading to performance drops on datasets with semantic ambiguity. GrepSeek achieves high efficiency with minimal memory usage and no offline indexing cost, but has higher inference latency due to extended reasoning processes.

The authors compare GrepSeek against various retrieval-augmented baselines, showing that GrepSeek outperforms non-agenetic and trained agentic methods across multiple benchmarks, particularly on multi-hop reasoning tasks. While GrepSeek achieves the highest overall average performance, it shows mixed results on specific datasets, with notable improvements on some and slight declines on others, especially where lexical variations or semantic ambiguity are present. The results indicate that direct corpus interaction through shell-based retrieval provides high precision for complex reasoning but can be brittle under surface-form variations. GrepSeek achieves the best performance on multiple benchmarks, especially in multi-hop reasoning tasks, outperforming both non-agenetic and trained agentic baselines. GrepSeek shows significant improvements on datasets requiring precise lexical matching and iterative evidence aggregation, but experiences performance trade-offs on datasets with semantic ambiguity or surface-form variations. The method's reliance on exact string matching makes it sensitive to spelling differences and diacritics, leading to failures where dense retrievers can generalize through semantic similarity.
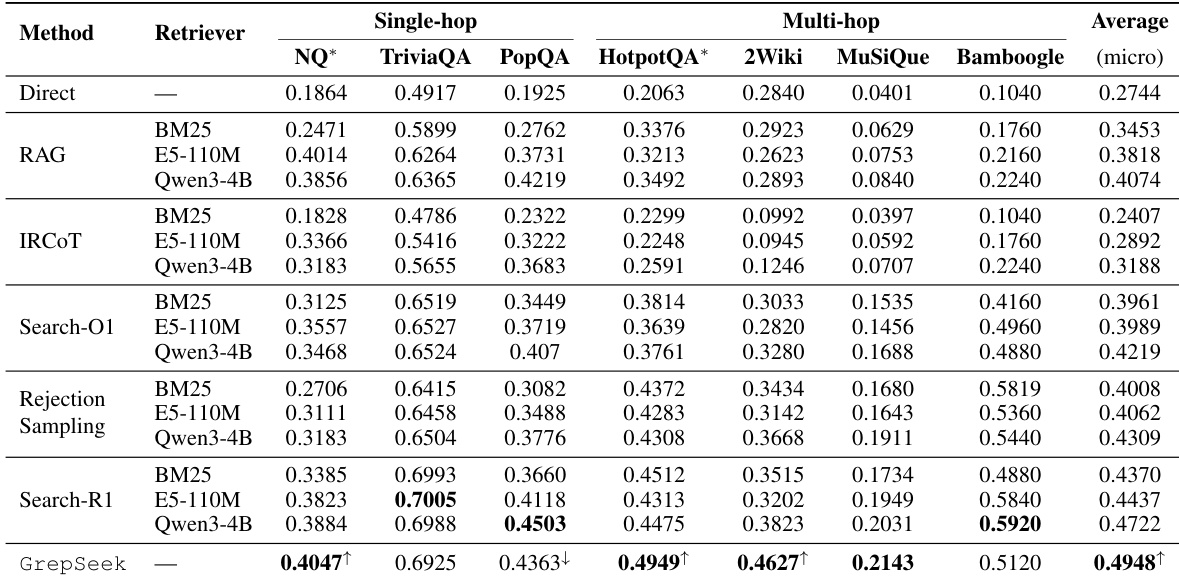
The evaluation setup comprises an ablation study on training stages and a comparative benchmark against retrieval baselines to validate GrepSeek's direct shell-based corpus interaction approach. The ablation confirms that both supervised fine-tuning and reinforcement learning are essential, as removing either causes significant performance degradation, particularly on multi-hop reasoning tasks. Comparative results show that GrepSeek excels in complex multi-hop scenarios by leveraging precise lexical filtering and iterative evidence aggregation, though its reliance on exact string matching makes it sensitive to semantic variations and surface-form differences. Overall, the experiments demonstrate that direct corpus interaction enables high-precision reasoning but requires structured initialization and policy optimization to maintain robustness across diverse linguistic contexts.