Command Palette
Search for a command to run...
TASTEの問題:agentベンチマークのカバレッジと難易度の向上
TASTEの問題:agentベンチマークのカバレッジと難易度の向上
Tomer Keren Nitay Calderon Asaf Yehudai Yotam Perlitz Michal Shmueli-Scheuer Roi Reichert
概要
agentの能力が向上するにつれ、τ2-Benchなどの既存ベンチマークは次第に飽和状態に近づいている。しかし、新たなベンチマークタスクの構築は依然として複雑であり、多大なコストと人的労力を要する。さらに、標準的なアプローチでは、シナリオを自然言語で記述した後にツールシーケンスにマッピングするため、agentsが実際に実行するツール使用パターンの限られた部分しか捉えられていない。本論文では、タスク構築プロセスを逆転させることで、これらの課題に対処する。本稿では、より広範なツール使用の網羅性を持つ難易度の高いタスクを生成する自動手法であるTASTE(Task Synthesis from Tool Sequence Evolution)を提案する。TASTEは、LLMによる妥当性判定信号を用いて訓練されたAdaptive Contrastive n-gramモデルを活用する。これにより、広範なツール組み合わせをカバーする有効なツールシーケンスのサンプリングが可能となる。TASTEはその後、クラスタリングにより候補群から代表シーケンスを選択し、それらを完全なベンチマークタスクとして具現化するとともに、反復的な難易度進化プロセスを通じて精緻化する。TASTEを用いて、τ2-Benchの3つのドメインを難易度高く拡張したτc-Benchを構築する。11組のagent/user LLMペアについて評価を行った結果、τ2-Benchにおいてほぼ飽和状態にあるモデルが、本手法のタスクにおいて著しい性能低下を示すことを確認した(例:Gemini-3-Flashは0.82!−!0.94から0.28!−!0.61へ低下)。難易度の向上に加え、本手法で生成されたタスクは、agentsが実行しなければならない一意のツール組み合わせの数を2倍以上に増加させている。本研究の結果は、既存ベンチマークにおける高スコアが、必ずしも堅牢なタスク解決能力を反映しているわけではなく、むしろベンチマークの飽和状態を示していることが多いことを示唆している。難易度が高く網羅性の高いベンチマークの生成を自動化することにより、TASTEは将来のagentsに対する継続的かつスケーラブルな評価を可能にする。
One-sentence Summary
The authors introduce TASTE, an automatic framework that reverses traditional benchmark construction by generating tasks directly from tool sequences, utilizing an Adaptive Contrastive n-gram model to sample valid combinations, cluster them, and iteratively evolve difficulty for au^c-Bench, which reveals severe performance drops across 11 evaluated agent/user LLM pairs, including a decline for Gemini-3-Flash from 0.82-0.94 to 0.28-0.61.
Key Contributions
- This paper introduces TASTE, an automatic task synthesis framework that reverses traditional benchmark construction to generate challenging tasks with broader tool-use coverage. The method employs an Adaptive Contrastive n-gram model trained on LLM-judged validity signals to sample diverse tool sequences, selects representative candidates via clustering, instantiates them into complete tasks, and refines them through iterative difficulty evolution.
- The framework constructs au^c-Bench, a challenging extension of the three domains in au^2-Bench that addresses the high cost and limited diversity of manual benchmark creation.
- Evaluations across 11 agent and user LLM pairs demonstrate that models approaching saturation on prior benchmarks experience severe performance degradation on the new tasks, such as Gemini-3-Flash dropping from 0.82-0.94 to 0.28-0.61. These results confirm the benchmark's capacity to expose current tool-use limitations and accurately measure agent capability advances.
Introduction
Tool-using agents require robust benchmarks to evaluate their ability to navigate multi-turn interactions within mutable environments, yet current evaluation frameworks face significant scalability and coverage challenges. Prior work depends on costly manual task authoring or synthetic generation via reverse synthesis from trajectories, which often lacks systematic exploration of tool combinations and fails to assess diversity through sequence-level procedural patterns. The authors leverage TASTE, a pipeline that constructs benchmarks by deriving tasks from representative tool sequences and evolving them through adversarial rewriting and rigorous validation, enabling precise measurement of agent behavior coverage and difficulty progression.
Dataset

The authors present τc-Bench, an automatically generated benchmark extension designed to improve coverage and difficulty for customer-support agent evaluations. The dataset is built using the TASTE method and extends three domains from the τ2-Bench framework: Airline, Retail, and Telecom. These domains rely on the τ-Bench-Verified corrected task sets and model interactions where simulated users request assistance while agents execute domain-specific tools under strict policies.
-
Dataset Composition and Subsets
- The dataset comprises three subsets generated using the original task counts from the base domains:
- Airline: 50 tasks.
- Retail: 114 tasks.
- Telecom: 114 tasks.
- The authors apply TASTE to each domain to create the extended set. For the Telecom domain, filtering rules restrict gold tool sequences to write-type actions only, as the gold sequences encode only write actions.
- The dataset comprises three subsets generated using the original task counts from the base domains:
-
Data Usage and Processing
- The authors use τc-Bench for model evaluation rather than training. They report pass@1 scores based on final-state reward across all domains and additionally report pass@3 scores for the Airline domain.
- Task generation involves training a trigram model for 3,000 iterations. The pipeline samples unique tool sequences with lengths drawn from a skew-normal distribution with parameters μ=7, σ=5, and α=2, clipped at a maximum length of 15.
- Different LLMs handle specific generation stages. Gemini-3-Flash acts as the plausibility validator and task instantiator, while Gemini-3-Pro is used for task evolution.
-
Metadata Construction and Validation
- Each task includes structured metadata such as
reason_for_call,known_info, andevaluation_criteria. Theknown_infofield provides minimal user context like names and lookup IDs, whileevaluation_criterialists complete action arguments and IDs. - The pipeline generates a database initialization JSON that enforces referential integrity, economic consistency, and state compatibility with action preconditions. Dynamic entities are excluded from the initialization and created at runtime.
- A coherence review process filters generated tasks by checking for fatal defects. This validation ensures no precondition violations, dependency-flow errors, database state impossibilities, or contradictions between user instructions and database states exist in the final dataset.
- Each task includes structured metadata such as
Method
The authors propose TASTE, a three-stage framework for the automatic synthesis of challenging benchmark tasks for tool-using agents, designed to address the limitations of manual benchmark construction and the saturation of existing benchmarks. The overall method operates by first generating a diverse pool of valid tool sequences, then selecting structurally distinct representatives, and finally instantiating and evolving these into complete, difficult tasks. The framework is illustrated in the figure below.
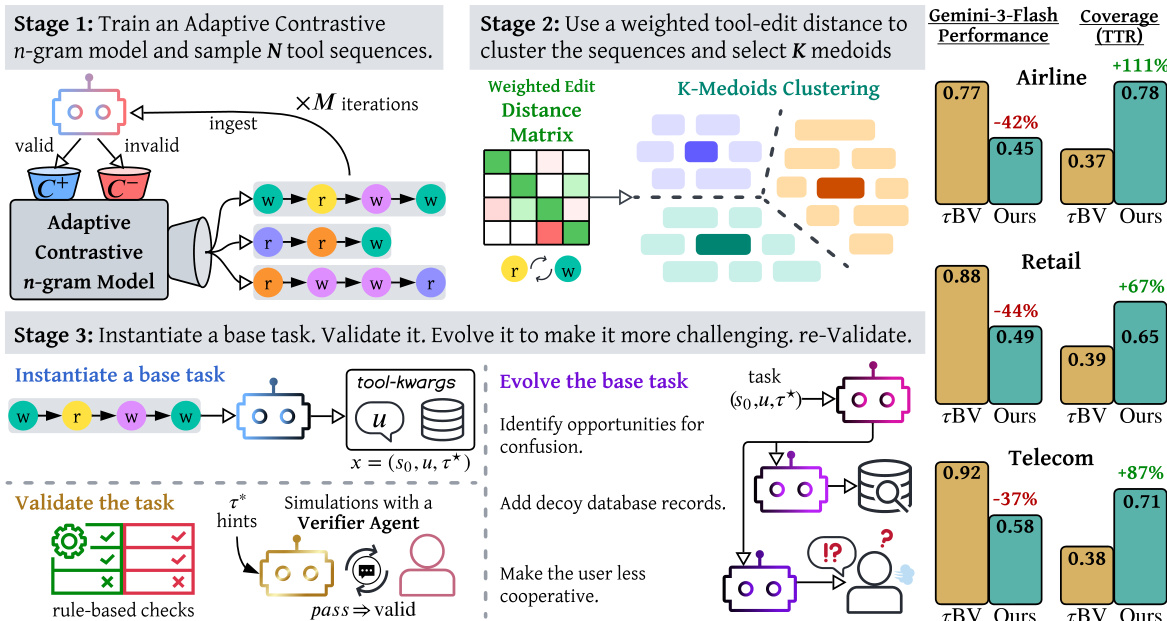
In the first stage, an Adaptive Contrastive n-gram model is trained to sample diverse and valid tool sequences. This model maintains two separate count tables, C+ and C−, for n-grams observed in sequences deemed plausible and implausible, respectively. The sampling probability for the next tool is determined by a contrastive ratio derived from these tables, which is updated online through an iterative generate-and-validate loop. Each candidate sequence is evaluated by an LLM to assign a binary plausibility label, which serves as a learning signal to refine the model's distribution. This adaptive process enables the exploration of a vast tool-combination space while concentrating probability mass on sequences that are likely to be valid and correct.
The second stage selects a representative subset of K tool sequences from the sampled pool. This is achieved using K-medoids clustering, where sequences are grouped based on a semantically weighted Levenshtein distance. This distance metric assigns lower costs to substitutions between tools with similar functions (e.g., different types of search tools) and higher costs for substitutions across different tool types or for insertions and deletions, ensuring that clusters are coherent in their functional structure. Medoids, representing the central sequence of each cluster, are selected as the representatives. Each medoid is validated by the same LLM validator; if a medoid is deemed invalid, it is replaced by the next-closest valid member of its cluster, or the cluster is removed and the process is re-run.
In the third stage, each selected medoid is instantiated into a complete benchmark task and refined through an evolution process. A base task is generated by creating a natural-language user instruction and initial database state that are consistent with the gold tool sequence. This task undergoes a multi-step validity pipeline, including rule-based checks and a simulation-based verification using a hint-assisted verifier agent. The agent is provided with a corrupted version of the gold tool-call sequence (shuffled and with masked arguments) to ensure it must engage with the scenario to solve it. Following validation, the task is evolved to increase difficulty. This evolution involves a strategy analysis phase where adversarial patterns are designed to make the user actively try to trick the agent into incorrect actions or arguments. These patterns are then implemented through environment perturbation (adding decoy records) and scenario rewriting, which alters the user instructions to deploy the adversarial techniques. The evolved task is then re-validated, with a graduated fallback mechanism to ensure all final tasks are complete and solvable, even if full adversarial evolution fails.
Experiment
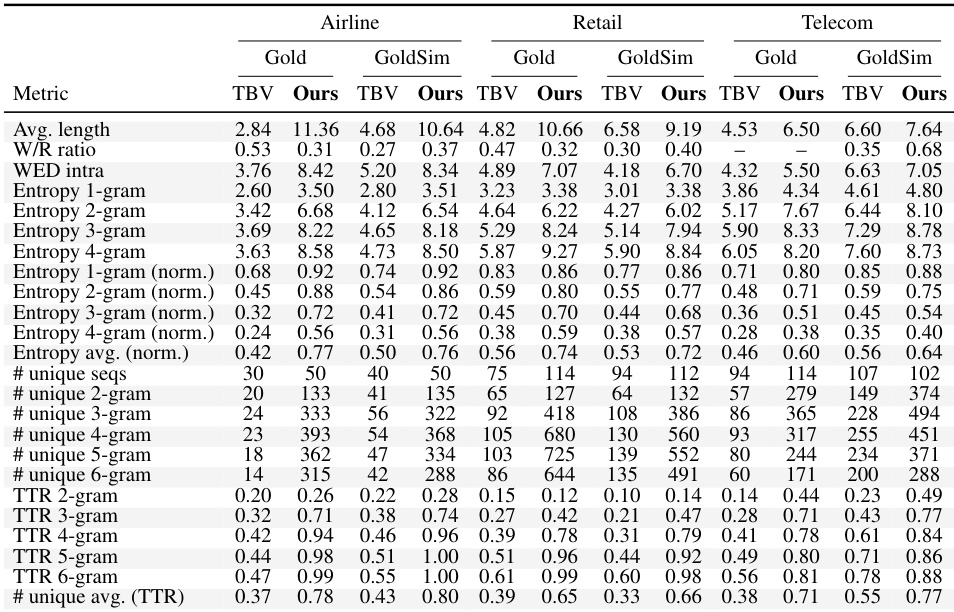
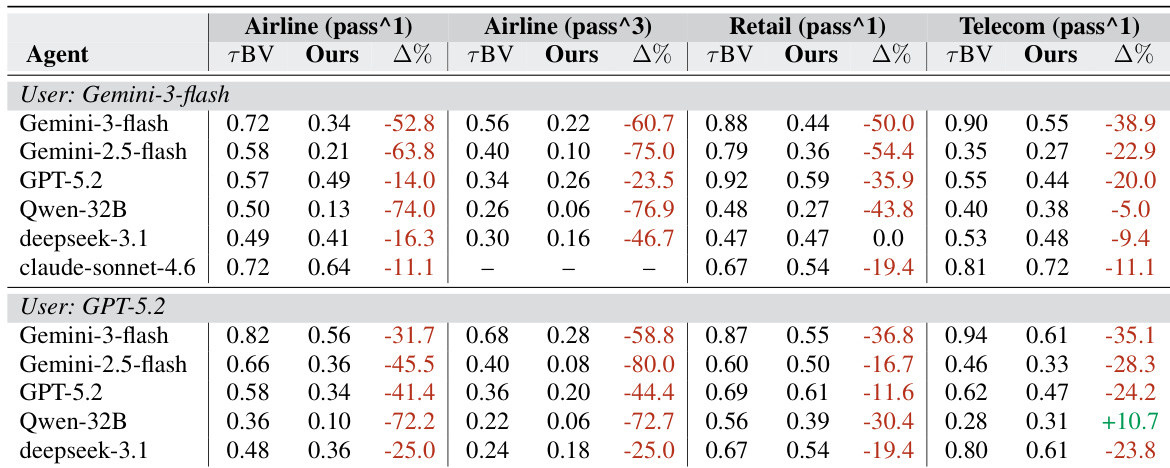
The evaluation tested eleven agent-user pairs across airline, retail, and telecom domains to compare performance on the newly generated τc-Bench against the original τBV benchmark. These experiments validate that the TASTE pipeline successfully produces more diverse and structurally complex tasks, as evidenced by substantially lower success rates that expose benchmark saturation and reveal genuine gaps in model robustness. Supplementary analyses further confirm that the adaptive contrastive sampling method and verification process reliably generate valid tasks while enabling precise difficulty control through sequence length and tool composition. Ultimately, the findings demonstrate that the new benchmark provides a scalable and rigorous framework for continuously differentiating state-of-the-art language models.
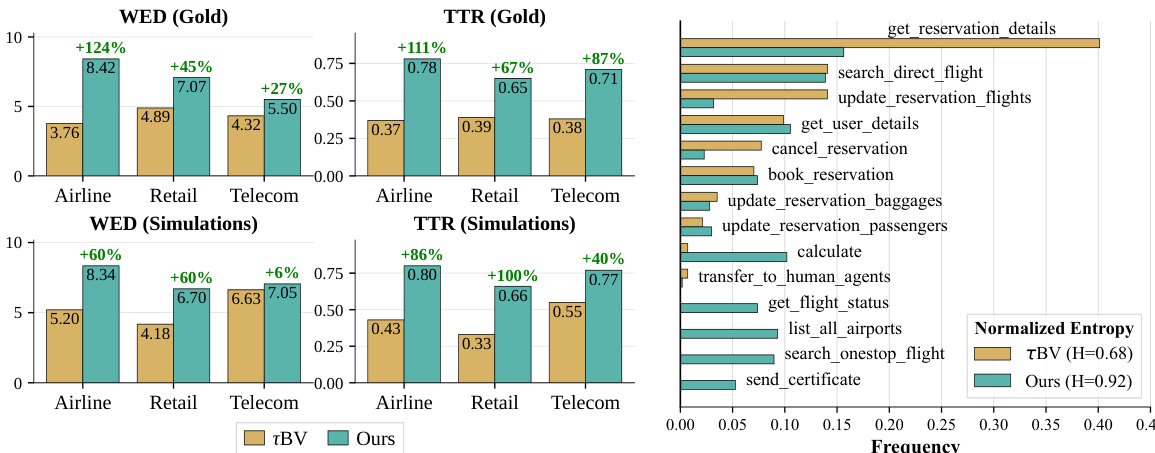
The authors compare two benchmark sets, one derived from a verified version and another generated by their method, across retail and telecom domains. Results show that the generated benchmark exhibits higher diversity in tool usage and sequence structure, with more balanced tool frequency distributions and greater compositional richness. The generated tasks also demonstrate increased difficulty, as evidenced by lower success rates on evolved versions compared to base tasks. The generated benchmark shows higher diversity in tool usage and sequence structure compared to the verified benchmark. Tool frequency distributions are more balanced in the generated benchmark, with increased normalized entropy. Success rates decrease significantly on evolved tasks, indicating increased difficulty in the generated benchmark.
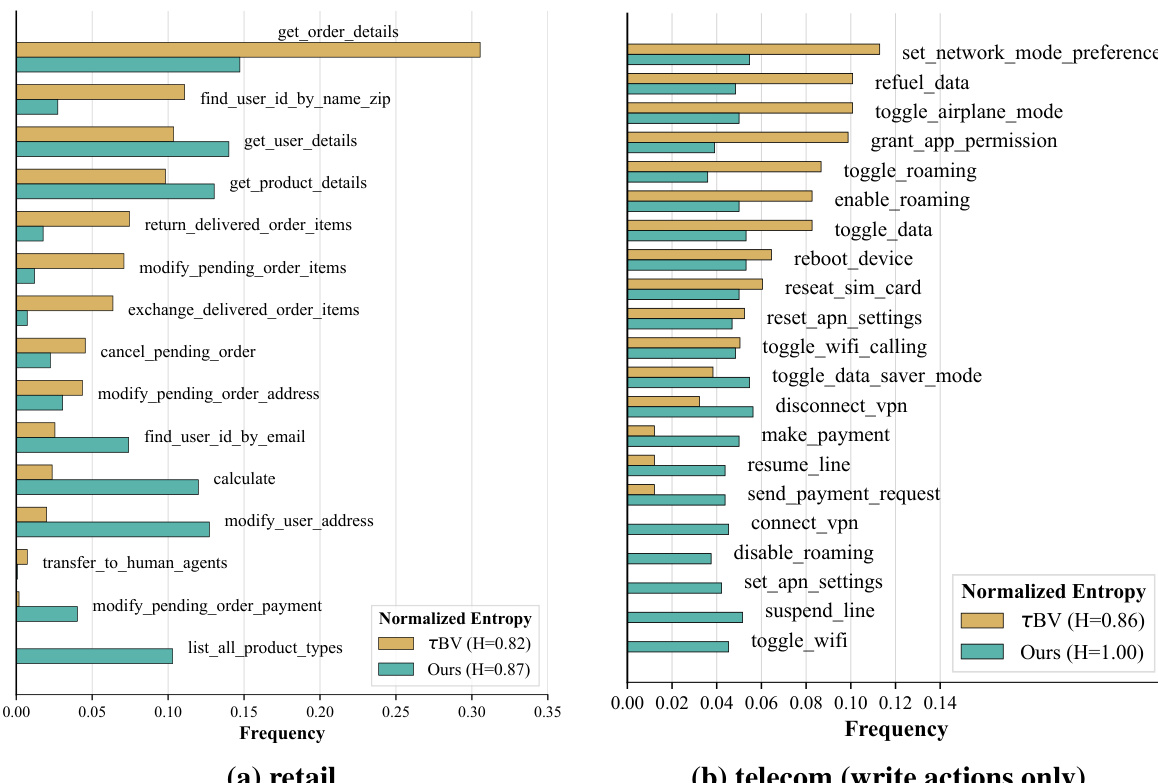
The authors compare two benchmark versions, τ2-Bench and τc-Bench, across three domains, showing that the latter introduces greater diversity and complexity in task sequences. Results indicate that tasks generated by τc-Bench exhibit higher structural variation and broader tool usage patterns, leading to lower performance across various agent-user pairs. The analysis demonstrates that the new benchmark better differentiates agent capabilities by requiring more diverse and challenging execution paths. τc-Bench tasks show significantly higher diversity in tool sequences and execution paths compared to τ2-Bench, as measured by metrics like WED and TTR. Agent performance is consistently lower on τc-Bench tasks, indicating increased difficulty and reduced saturation of state-of-the-art models. The distribution of tool usage is more balanced in τc-Bench, with entropy and unique n-gram counts showing broader coverage across domains.
The authors analyze the effectiveness of their adaptive contrastive n-gram model in improving the validity rate of sampled tool sequences, showing significant gains through iterative training and the use of negative evidence. They also evaluate task difficulty by comparing base tasks with evolved versions, demonstrating that evolved tasks are substantially harder for agents to solve across different domains. The validity rate of sampled tool sequences improves substantially with adaptive training and negative evidence, increasing from a baseline of 6.7% to 86.7%. Evolved tasks are significantly more difficult than base tasks, with success rates dropping by 16-55% depending on the agent and domain. The model's design choices lead to a large increase in the diversity and complexity of generated tasks, as evidenced by higher coverage metrics and more varied execution paths.
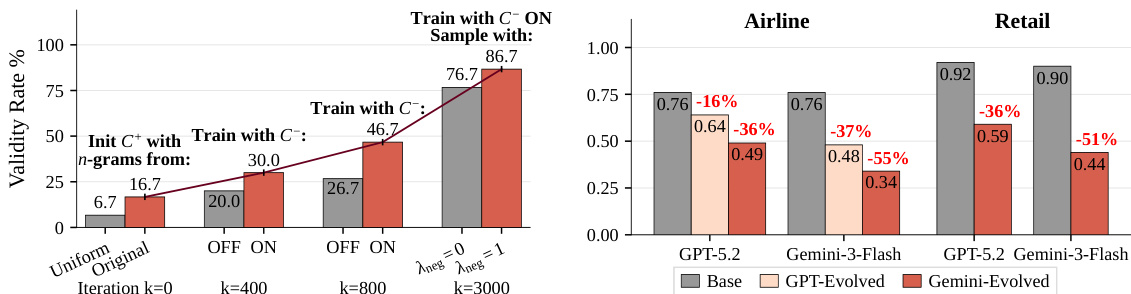
The authors compare the performance of various agent-user pairs on two benchmark versions, showing that the new benchmark consistently results in lower performance across all agents and domains. The degradation is particularly pronounced for agents that previously achieved high scores on the original benchmark, suggesting the new benchmark exposes previously hidden limitations and enables better differentiation among state-of-the-art models. The results indicate that the new benchmark tasks are more diverse and challenging, requiring more varied and complex execution paths. Performance drops substantially on the new benchmark compared to the original, with the most significant declines observed for agents that had high scores on the original benchmark. The new benchmark tasks require more diverse and complex execution paths, as evidenced by increased coverage and diversity metrics across all domains. The performance degradation is consistent across different agent-user pairs and domains, indicating that the new benchmark effectively exposes limitations in current models.
The authors compare their generated tasks against the original benchmark, showing that their tasks exhibit higher diversity and complexity across multiple domains. Results indicate that the new tasks lead to substantially lower performance across various agents, suggesting that the original benchmark may have been saturated. The tasks are more challenging due to increased structural variation, greater tool usage diversity, and longer execution paths, which are supported by metrics such as weighted edit distance and type-token ratio. The distribution of tool usage is more balanced in the new tasks, indicating a broader exploration of the task space. The new tasks show substantially lower performance across agents, indicating higher difficulty compared to the original benchmark. Metrics such as weighted edit distance and type-token ratio reveal greater diversity and complexity in the new tasks. Tool usage is more evenly distributed in the new tasks, reducing skewness and increasing coverage of the tool space.
The experiments compare a newly generated benchmark against an original verified version across multiple domains to evaluate task diversity, generation validity, and model performance. The evolved tasks consistently demonstrate greater structural complexity, more balanced tool usage, and broader execution paths, which substantially lower agent success rates. This performance decline, especially among previously high-scoring models, confirms that the original benchmark was saturated and validates the new approach as a more rigorous standard for differentiating current AI capabilities.