HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

BrainG3N: 制御可能な3D脳MRI生成のための二重目的トークナイザー

GateMem: 複数主体共有メモリAgentsにおけるメモリガバナンスのベンチマーク




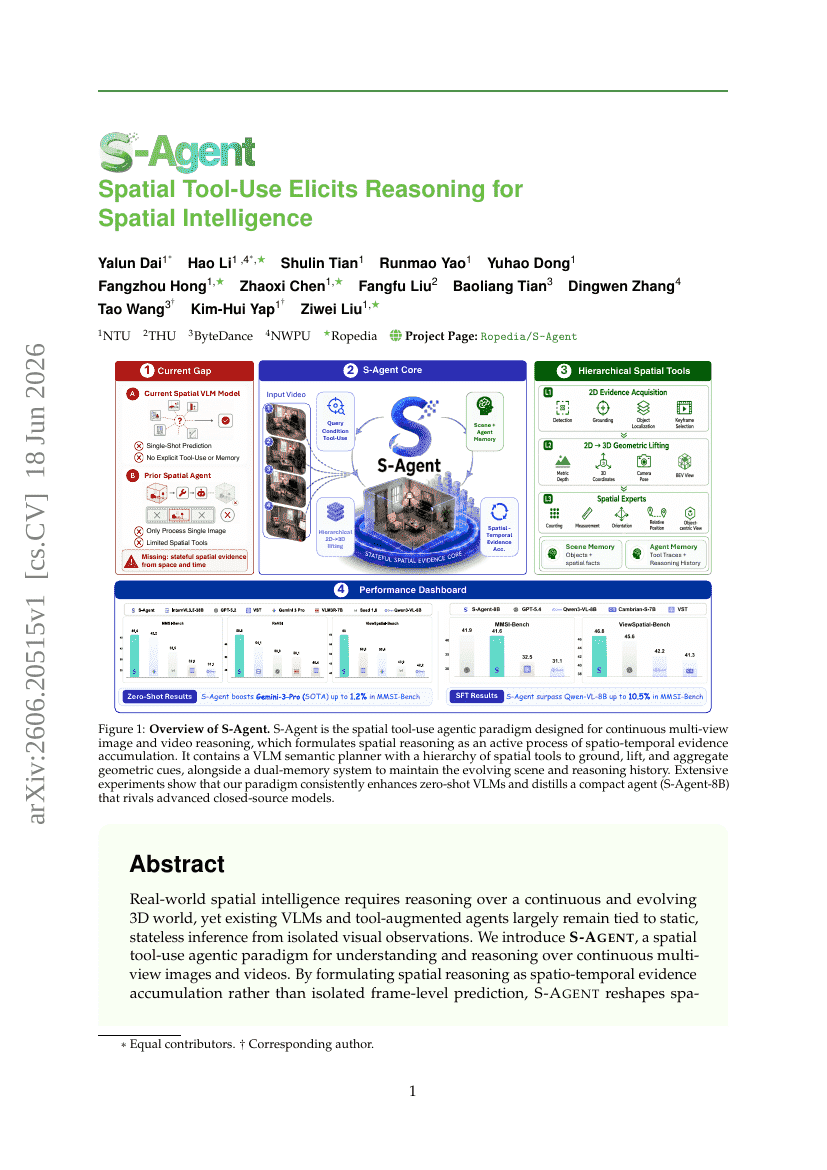






















BrainG3N: 制御可能な3D脳MRI生成のための二重目的トークナイザー
GateMem: 複数主体共有メモリAgentsにおけるメモリガバナンスのベンチマーク
MemSlides:マルチターンローカル修正を用いたパーソナライズされたスライド生成のための階層型メモリ駆動型Agentフレームワーク
PerceptionDLM: マルチモーダル拡散言語モデルを用いた並列領域知覚
一般ゲームプレイのためのコード世界モデル
静的リーダーボードを超えて:LLM agentsの評価における予測妥当性
S-Agent: 空間的ツール使用が空間知能のための推論を引き出す
Multi-LCB: LiveCodeBenchを複数のプログラミング言語に拡張する
プレイフルなエージェント型ロボット学習
DragMesh-2: 関節付き物体との物理的に妥当な器用な手と物体の相互作用
モエビウス: 10Bレベルの性能を備えた0.2B軽量画像インペインティングフレームワーク
EfficientRollout:RLロールアウトのためのシステム認識型自己推測デコーディング
正しい教師を信頼する:GUIグラウンディングのための品質認識型自己蒸留
空間視覚言語モデルにおける双経路推論の強化
SAE介入は信頼できない:介入後の抑制された行動の回復
Kairos:物理AIのためのネイティブ世界モデルスタック
グアバ:具身操作のための効果的かつ汎用的なハネス
LifeSciBench: 現実的で専門家が扱うレベルのタスクにおいて Language Models を評価する
TRIAGE: 不規則サンプリングされた医療時系列におけるLLMを用いた説明可能なリスク予測のための弁証法的推論
LectūraAgents: 適応的パーソナライズドAI支援学習および具身化教育のためのMulti-Agentフレームワーク
GameCraft-Bench: Agentsは実際のゲームエンジンでプレイ可能なゲームをエンドツーエンドで構築できるか?
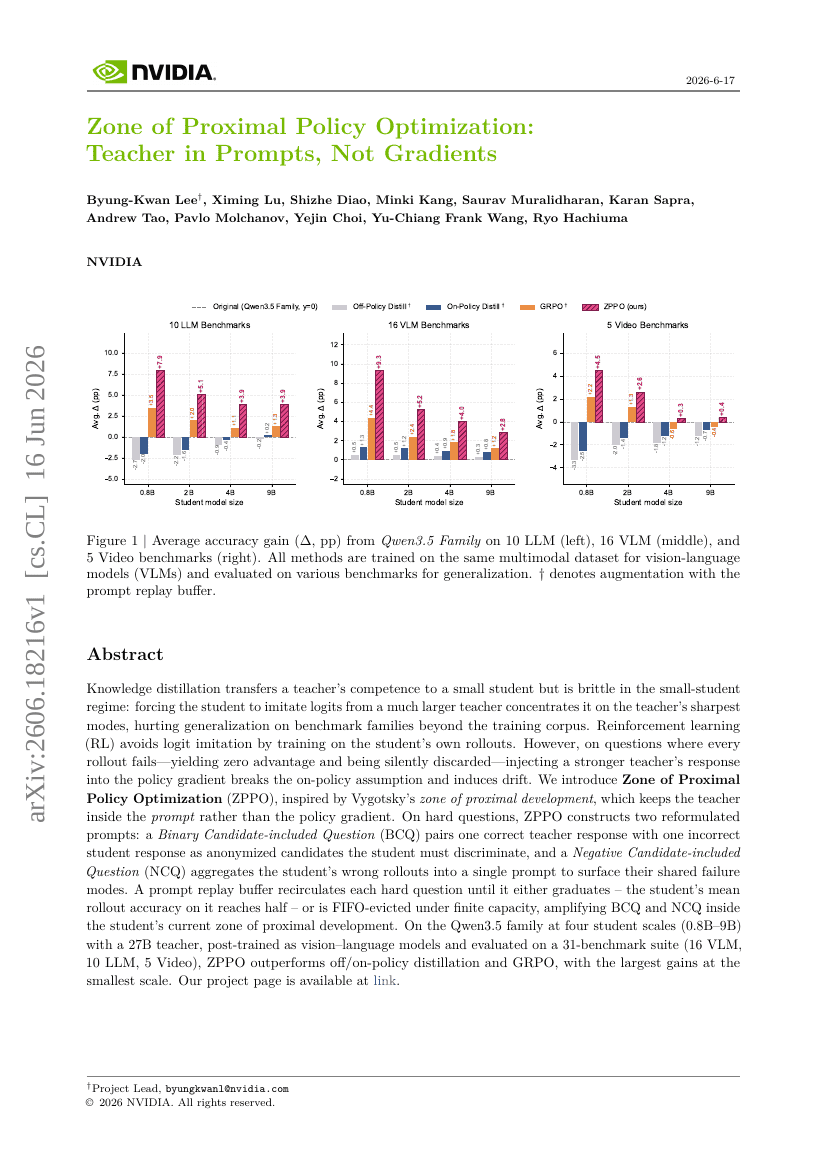
近接政策最適化の領域:プロンプトに教師を、勾配にはない
ACE-Ego-0: VLA事前学習のための自己中心の人間およびロボットのデータの統合
LoopCoder-v2: 効率的なテスト時計算スケーリングのために一度だけループする
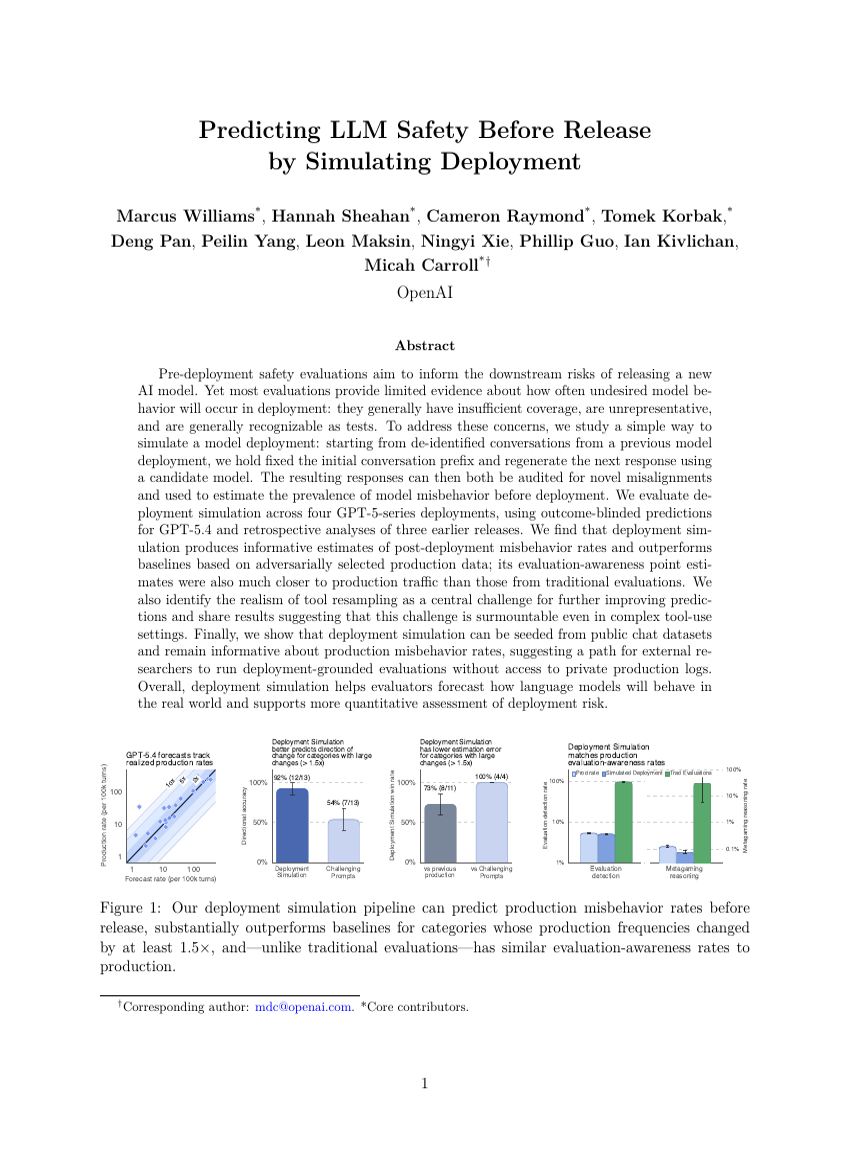
展開をシミュレートすることによるLLMのリリース前の安全性予測
FastContext: コーディングAgentsのための効率的なリポジトリエクスプローラの訓練
VibeThinker-3B: 小規模言語モデルにおける検証可能な推論の最前線を探索する
DreamX-World 1.0: 汎用インタラクティブ・ワールドモデル
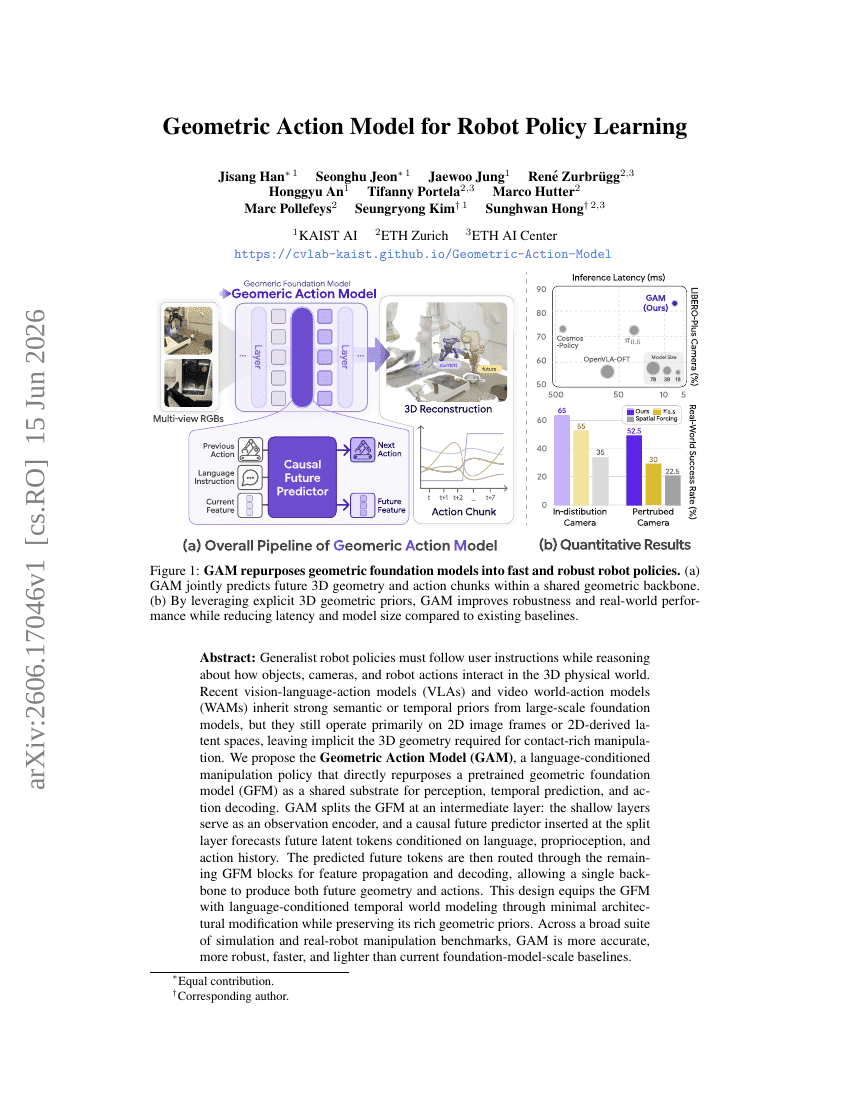
ロボット方策学習のための幾何学的行動モデル
データジャーナリストAgent: データを検証可能なマルチモーダルストーリーに変換する
JoyAI-VL-Interaction: リアルタイム視覚・言語インタラクションインテリジェンス
dots.tts 技術報告
MemSlides:マルチターンローカル修正を用いたパーソナライズされたスライド生成のための階層型メモリ駆動型Agentフレームワーク
PerceptionDLM: マルチモーダル拡散言語モデルを用いた並列領域知覚
一般ゲームプレイのためのコード世界モデル
静的リーダーボードを超えて:LLM agentsの評価における予測妥当性
S-Agent: 空間的ツール使用が空間知能のための推論を引き出す
Multi-LCB: LiveCodeBenchを複数のプログラミング言語に拡張する
プレイフルなエージェント型ロボット学習
DragMesh-2: 関節付き物体との物理的に妥当な器用な手と物体の相互作用
モエビウス: 10Bレベルの性能を備えた0.2B軽量画像インペインティングフレームワーク
EfficientRollout:RLロールアウトのためのシステム認識型自己推測デコーディング
正しい教師を信頼する:GUIグラウンディングのための品質認識型自己蒸留
空間視覚言語モデルにおける双経路推論の強化
SAE介入は信頼できない:介入後の抑制された行動の回復
Kairos:物理AIのためのネイティブ世界モデルスタック
グアバ:具身操作のための効果的かつ汎用的なハネス
LifeSciBench: 現実的で専門家が扱うレベルのタスクにおいて Language Models を評価する
TRIAGE: 不規則サンプリングされた医療時系列におけるLLMを用いた説明可能なリスク予測のための弁証法的推論
LectūraAgents: 適応的パーソナライズドAI支援学習および具身化教育のためのMulti-Agentフレームワーク
GameCraft-Bench: Agentsは実際のゲームエンジンでプレイ可能なゲームをエンドツーエンドで構築できるか?
近接政策最適化の領域:プロンプトに教師を、勾配にはない
ACE-Ego-0: VLA事前学習のための自己中心の人間およびロボットのデータの統合
LoopCoder-v2: 効率的なテスト時計算スケーリングのために一度だけループする
展開をシミュレートすることによるLLMのリリース前の安全性予測
FastContext: コーディングAgentsのための効率的なリポジトリエクスプローラの訓練
VibeThinker-3B: 小規模言語モデルにおける検証可能な推論の最前線を探索する
DreamX-World 1.0: 汎用インタラクティブ・ワールドモデル
ロボット方策学習のための幾何学的行動モデル
データジャーナリストAgent: データを検証可能なマルチモーダルストーリーに変換する
JoyAI-VL-Interaction: リアルタイム視覚・言語インタラクションインテリジェンス
dots.tts 技術報告