Command Palette
Search for a command to run...
Harness-1:状態外部化ハarnessを用いた探索エージェントのための強化学習
Harness-1:状態外部化ハarnessを用いた探索エージェントのための強化学習
Pengcheng Jiang Zhiyi Shi Kelly Hong Xueqiang Xu Jiashuo Sun Jimeng Sun Hammad Bashir Jiawei Han
概要
検索エージェントは、通常、成長する対話履歴(トランスクリプト)上のポリシーとして学習される。これは、モデルが検索方法を決定するだけでなく、自分が何を目撃したかを記憶し、どの証拠が有用か、どの制約が未解決か、そしてどの主張が実際に検証済みかを区別する必要があることを意味する。我々は、この定式化ではポリシー内に過度に定型的な状態管理(state management)が含まれていると論じる。強化学習(RL)は、セマンティックな検索判断と、環境側がより信頼性の高い形で管理可能な回復可能な簿記的処理の両方を最適化することを強いられている。本研究では、状態を保持する検索ハーネス(stateful search harness)内で強化学習を用いて訓練された20Bパラメータの検索エージェント(検索サブエージェント)であるHarness-1を導入する。このハーネスは、環境側での作業メモリを維持する。具体的には、候補プール、重要度タグ付きのキュレーション済みセット、圧縮された証拠リンク、検証記録、圧縮・重複削除された観測データ、および予算を考慮したコンテキストレンダリングを含む。一方、ポリシーはセマンティックな判断役割を保持する。すなわち、「何を検索するか」、「どの文書を保持または除外するか」、「何を検証するか」、そして「いつ停止するか」といった決定である。Web、金融、特許、マルチホップ質問応答(QA)にわたる8つの検索ベンチマークにおいて、Harness-1は平均キュレーションリコール0.730を達成し、次に強力なオープンソースの検索サブエージェントを+11.4ポイント上回り、はるかに大規模なフロンティアモデル搭載の検索システムとも競争力のある性能を示した。
One-sentence Summary
Harness-1 is a 20B search agent trained with reinforcement learning inside a stateful search harness that externalizes routine state management to the environment while the policy retains semantic decisions, achieving 0.730 average curated recall across eight retrieval benchmarks spanning web, finance, patents, and multi-hop QA and outperforming the next strongest open search subagent by 11.4 points.
Key Contributions
- The paper introduces Harness-1, a 20B search agent trained with reinforcement learning inside a stateful search harness. This formulation moves routine state management out of the policy and into the environment for more reliable bookkeeping.
- The harness maintains environment-side working memory including a candidate pool, an importance-tagged curated set, compact evidence links, and verification records. The policy retains semantic decisions such as what to search, which documents to keep, and when to stop.
- Harness-1 achieves 0.730 average curated recall across eight retrieval benchmarks spanning web, finance, patents, and multi-hop QA. The method outperforms the next strongest open search subagent by 11.4 points and remains competitive with much larger frontier-model searchers.
Introduction
Search agents typically operate as policies over growing transcripts where they must manage memory and evidence while deciding how to search. This formulation places excessive routine state management inside the policy, forcing reinforcement learning to optimize both semantic search decisions and recoverable bookkeeping that the environment could maintain more reliably. The authors introduce Harness-1, a 20B search agent trained with reinforcement learning inside a stateful search harness. This harness maintains environment-side working memory including candidate pools and verification records, allowing the policy to retain only semantic decisions like what to search or verify. This separation enables Harness-1 to outperform existing open search subagents by 11.4 points on average across eight retrieval benchmarks while remaining competitive with larger frontier models.
Dataset
- Dataset Composition and Sources: The authors generate supervised fine-tuning trajectories using GPT-5.4 running natively inside the Harness-1 harness. The data spans encyclopedic web search, finance filings, patents, and multi-hop question answering domains.
- Subset Details: Raw quotas target 300 BC+, 250 SEC, 150 Patents, and 150 Web samples, alongside simplified variants. A 0.10 recall gate filters out low-quality trajectories, resulting in a final corpus of 899 trajectories.
- Training Usage: The 899 trajectories undergo per-trajectory expansion into turn-conditional datums to yield approximately 26K training examples. This data is used to train the policy on tool selection and document management.
- Processing and Metadata: Search observations are processed with BM25 sentence compression limited to the top-4 sentences per chunk. Content deduplication applies MinHash-LSH with 64 permutations and a 0.85 threshold. An auto-populate feature adds the top-8 reranked results to the curated set after the first search, marked with an [AUTO-POPULATED] tag.
Method
The authors introduce Harness-1, a retrieval agent architecture designed around the principle of stateful cognitive offloading. In this framework, the policy is relieved of the burden of maintaining search state, allowing it to focus on semantic decisions such as query formulation and evidence selection. The environment maintains a persistent working memory that evolves over the course of an episode.
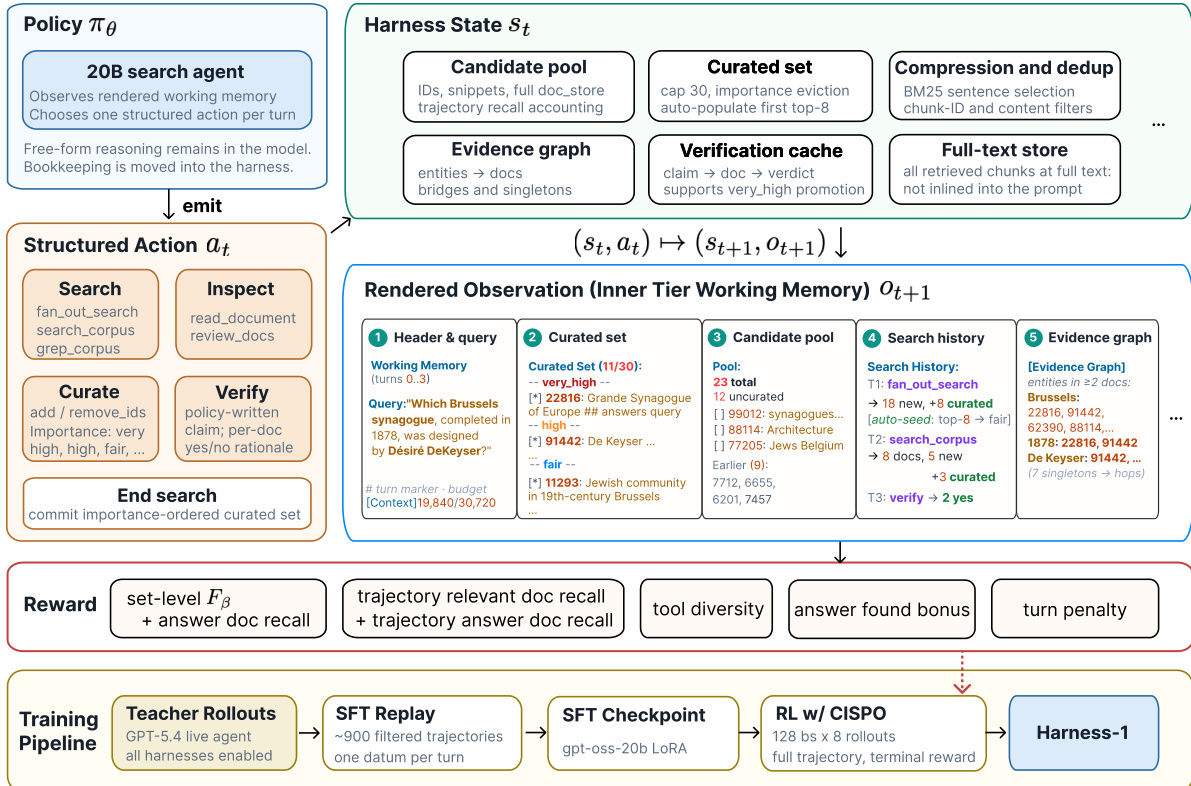
Refer to the framework diagram above to see the interaction between the policy and the harness. The system operates as a state machine where the transition is defined as (st,at)↦(st+1,ot+1). The harness state St comprises a candidate pool for uncurated documents, a curated set capped at 30 items with importance tags, an evidence graph summarizing cross-document entity links, and a verification cache. A full-text store retains all retrieved chunks for later inspection without cluttering the prompt.
The policy πθ, instantiated as a 20B parameter model, observes a rendered version of this state known as the Working Memory. Based on this observation, the model emits a single structured action at per turn. These actions are categorized into retrieval, inspection, curation, verification, and termination. Retrieval actions like fan_out_search and search_corpus bring new evidence into the candidate pool. Curation actions allow the policy to add or remove documents from the curated set and assign importance levels such as very_high, high, fair, or low. Verification actions enable the policy to write claims and check them against the full-text store.
To ensure efficient training and inference, the harness employs derived-state rendering. Search observations are compressed using BM25 sentence selection and deduplicated by content fingerprint before reaching the prompt. The rendered observation Ot+1 includes a header with the query, the curated set grouped by importance, the candidate pool, search history, and the evidence graph. This compact representation prevents context overflow while preserving actionable information.
The training pipeline consists of two stages. First, Supervised Fine-Tuning (SFT) is performed on trajectories generated by a teacher agent. This stage teaches the model the correct tool-call formats and the rhythm of search followed by curation. Second, Reinforcement Learning (RL) is applied using the CISPO algorithm. The RL process optimizes the policy over full search episodes using a terminal reward signal. This reward combines set-level quality metrics, trajectory coverage, answer evidence bonuses, tool diversity incentives, and turn penalties to encourage efficient and accurate search behavior.
Experiment
Harness-1 was evaluated across eight diverse retrieval benchmarks using recall-oriented metrics to assess evidence coverage against open and frontier baselines. The agent demonstrates stronger gains on held-out transfer tasks than on source-family benchmarks, validating that it learns general search operations rather than dataset-specific patterns. Ablation studies reveal that disabling harness mechanisms causes the policy to revert to shallow search modes, while modular RAG tests show these curated sets improve downstream answer accuracy.
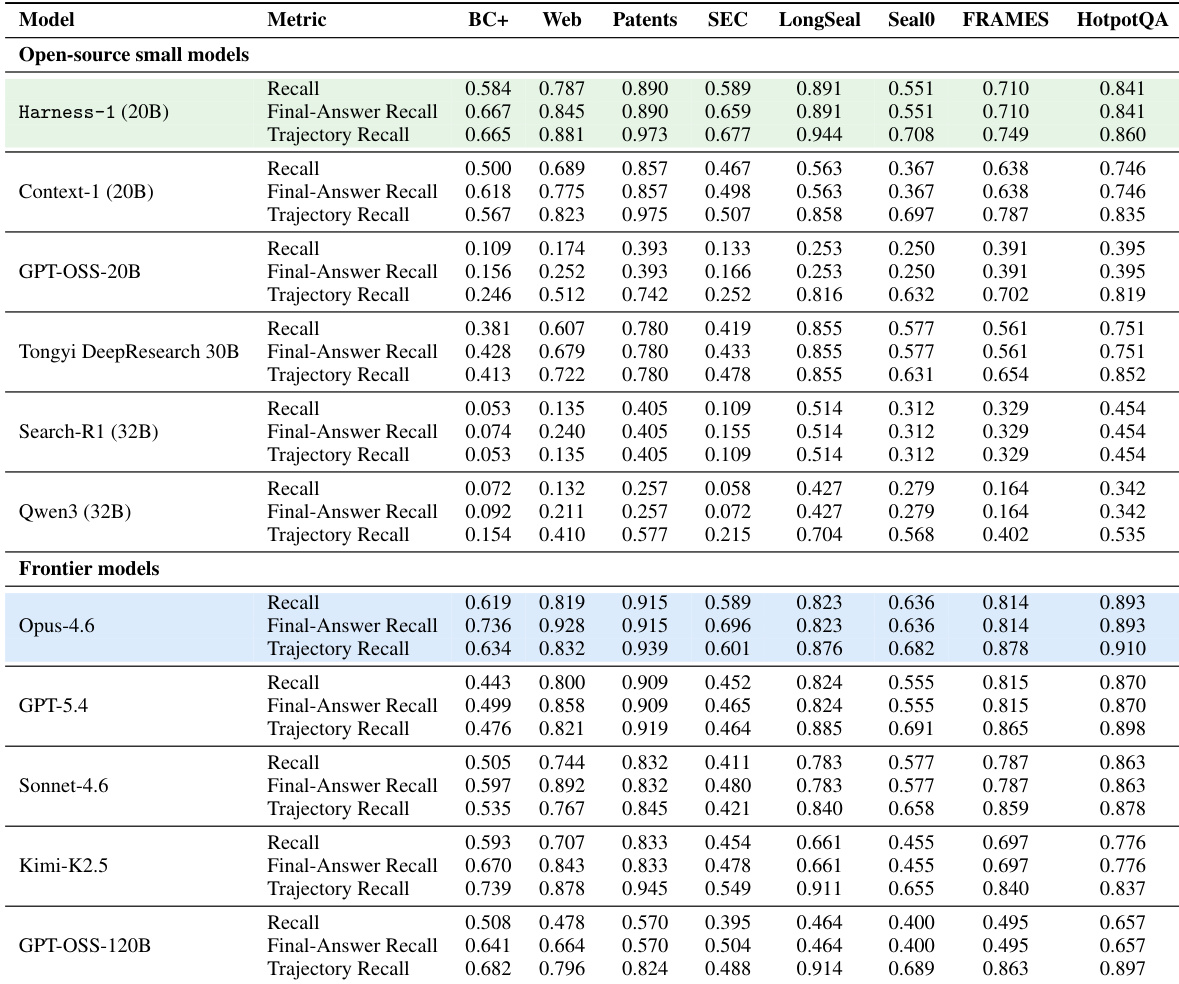
The authors introduce Harness-1, a 20B search agent that achieves the strongest average recall among open-source retrieval models while remaining competitive with larger frontier models. The results highlight that the agent's performance relies heavily on a stateful harness design, which enables better generalization on held-out transfer benchmarks compared to training data sources. Ablation experiments further demonstrate that specific harness mechanisms are essential for high-quality evidence curation, as removing them leads to significant performance degradation. Harness-1 outperforms other open-source agents and most frontier models in average curated recall, with only Opus-4.6 performing better on average. The model exhibits superior transfer capabilities, showing larger performance gains on benchmarks excluded from training compared to those included in the training set. Disabling individual harness mechanisms results in consistent drops in recall and final-answer accuracy, validating the importance of the stateful interface.
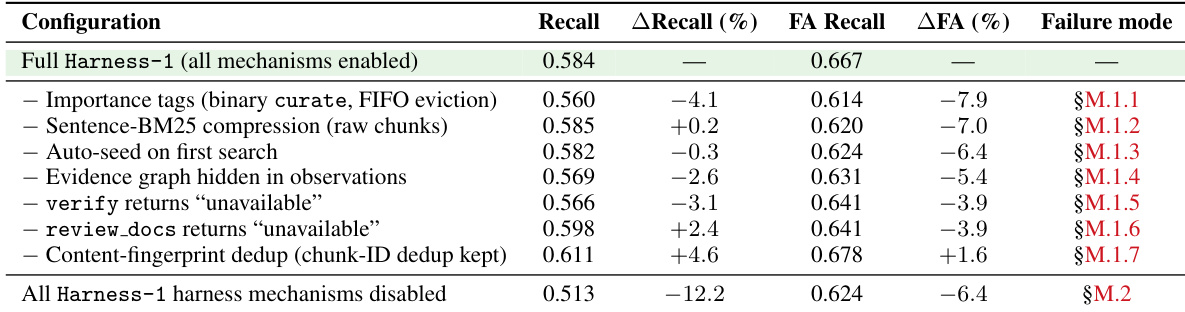
The the the table presents an ablation study of the Harness-1 system on the BrowseComp+ benchmark, isolating the impact of individual inference-time mechanisms. The results demonstrate that most components, such as importance tagging and evidence graphs, are critical for maintaining search quality, as disabling them leads to performance degradation. Furthermore, removing all harness mechanisms simultaneously causes a more severe decline in recall than any single ablation, confirming that the stateful interface is fundamental to the agent's ability to curate evidence effectively. Disabling most individual harness mechanisms results in consistent decreases in Final-Answer Recall. The cumulative effect of the harness is significant, with the full system outperforming the version with all mechanisms disabled by a wide margin. Content fingerprint deduplication is the sole exception, showing a slight performance gain when removed due to the presence of near-duplicate gold documents in the dataset.
The authors evaluate Harness-1 against open-source and frontier retrieval models to assess recall and transfer capabilities. Ablation studies on the BrowseComp+ benchmark isolate the impact of individual inference-time mechanisms, revealing that components such as importance tagging and evidence graphs are critical for maintaining search quality. These results confirm that the stateful harness design is fundamental to effective evidence curation, as disabling these mechanisms consistently leads to significant performance degradation in recall and final-answer accuracy.