HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

生成 prior を用いた決定論的ビデオ深度推定

解像プラグアンドプレイADMMを用いた弱い重力レンズのための銀河画像デコンボリューション
























生成 prior を用いた決定論的ビデオ深度推定
解像プラグアンドプレイADMMを用いた弱い重力レンズのための銀河画像デコンボリューション
人工知能は、超人適応知能による専門化を受け入れる必要がある
空理空論に陥るサイコパシーボット:理想的ベイズ推定者でさえも
混沌のエージェント
HarnessX: 組み合わせ可能で適応的で進化的なエージェント・ハルスのファウンドリ
Orchestra-o1: オムニモーダル agent オーケストレーション
チャットボットからデジタル同僚へ:永続的自律型AIへのパラダイムシフト
記憶は検索されるのではなく再構築される:LLM Agentsのためのグラフメモリ
APPO: エージェント的手続き的ポリシー最適化
OmniDirector: 共通データを用いない一般化マルチショットカメラクローニング
InterleaveThinker: エージェント型インターリーブ生成の強化
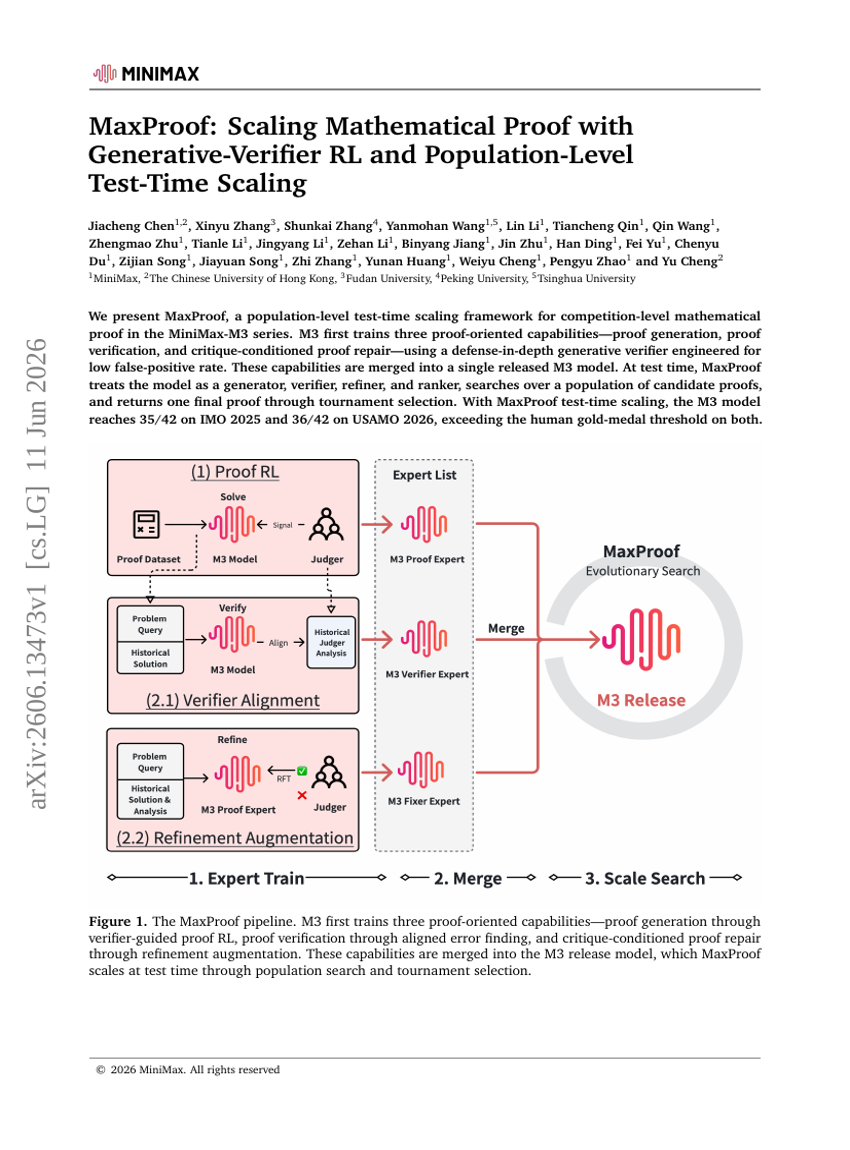
MaxProof: 生成検証型強化学習および集団レベルのテスト時スケーリングによる数学的証明のスケールアップ
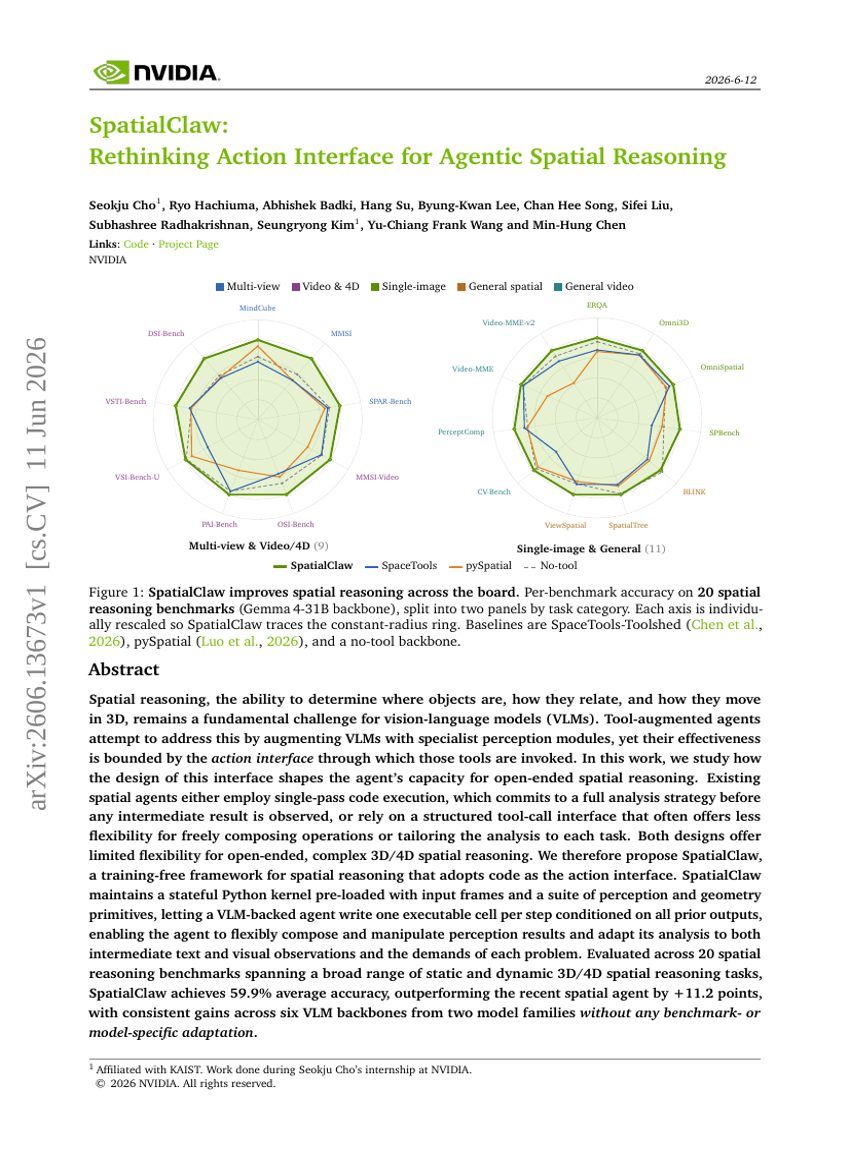
SpatialClaw: エージェント型空間推論のための行動インターフェースを再考する
WEAVEBENCH: ハイブリッドインターフェースを備えたComputer-Use Agentのためのロングホライズン・リアルワールドベンチマーク
MiniMax Sparse Attention
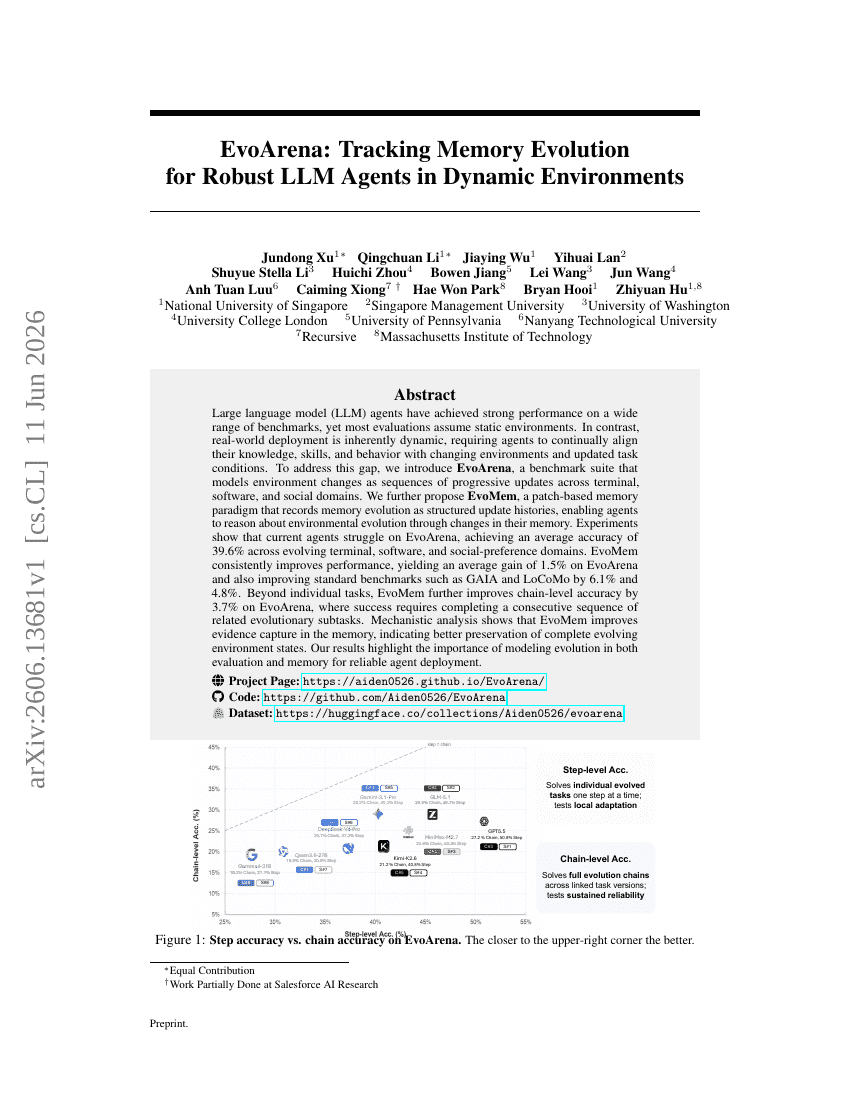
EvoArena: 動的環境における堅牢なLLM Agentsのためのメモリ進化追跡
Flex4DHuman: 4D人体再構築のための柔軟なマルチビュー動画拡散モデル
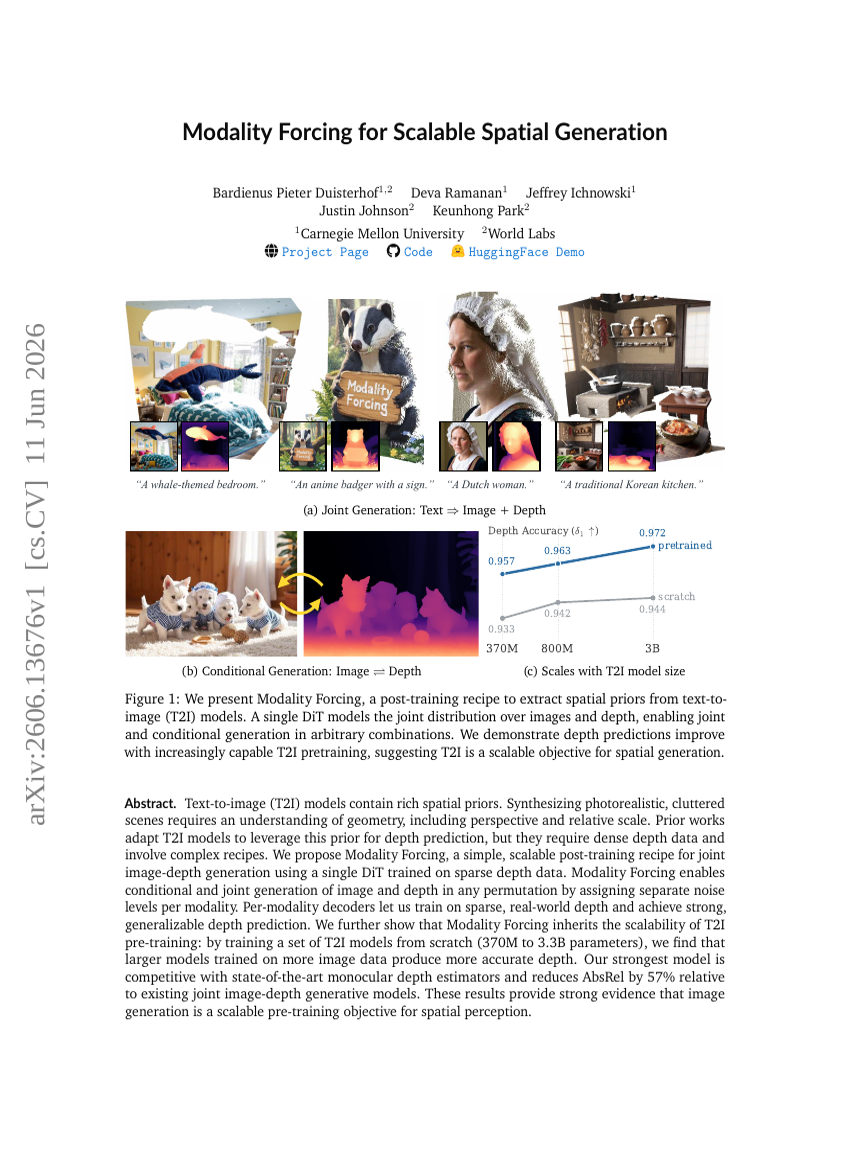
スケーラブルな空間生成のためのモダリティ強制
AGIからASIへ
ワールド・トレーシング:可視領域を超えた生成ピクセルアラインドジオメトリ
正則化f発散核検定
再帰なしで再帰型ネットワークを事前学習する
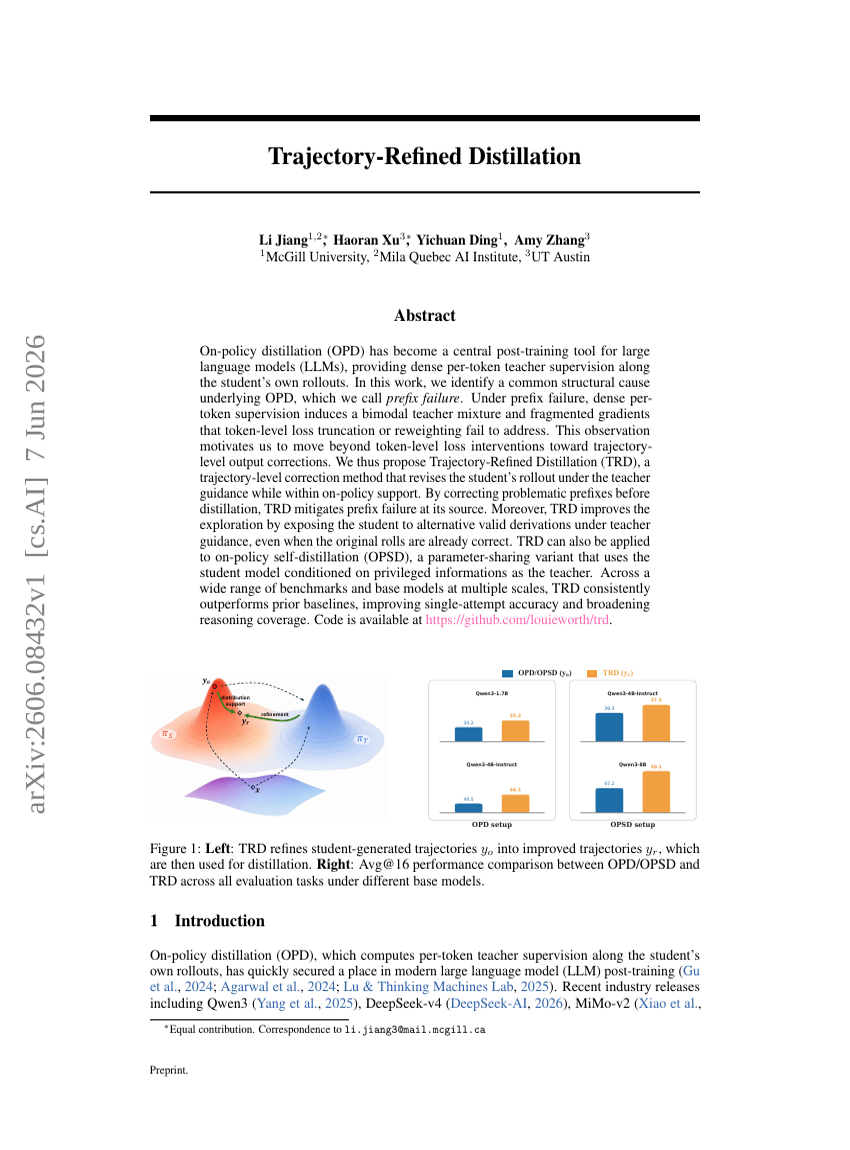
軌跡精緻化蒸留
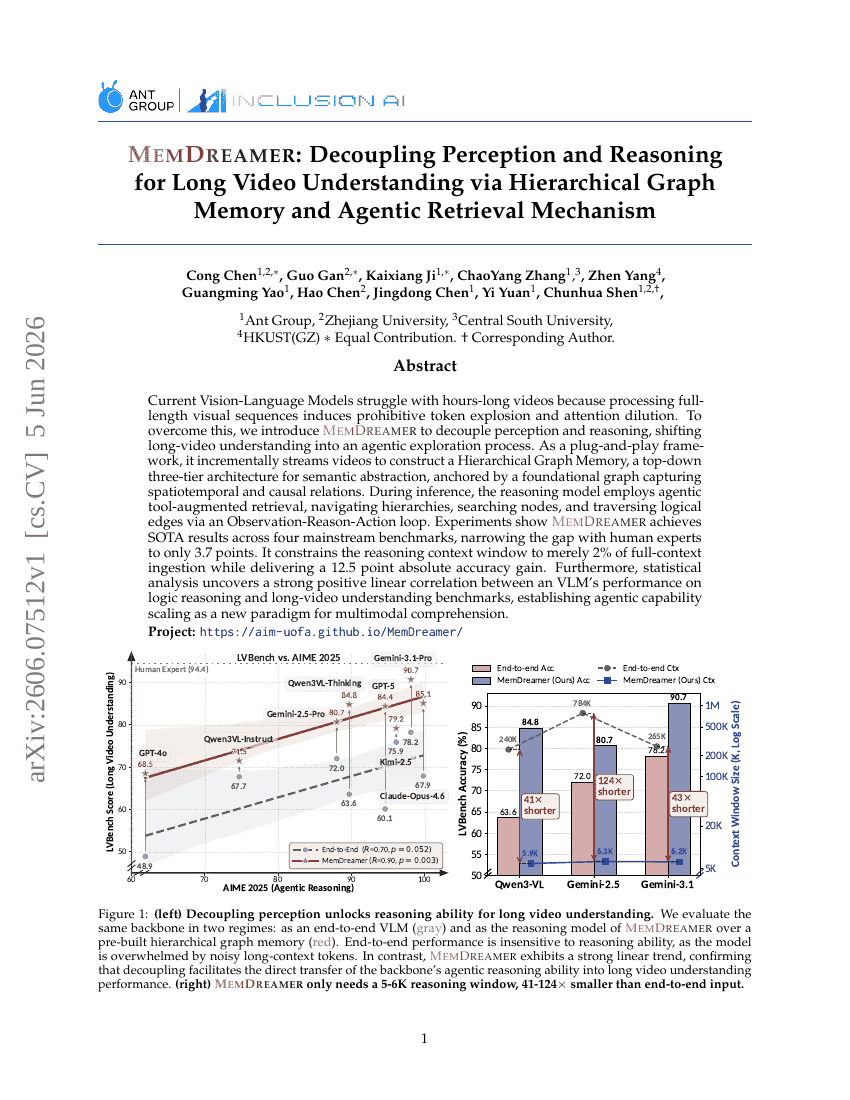
MemDreamer:階層グラフメモリとエージェント検索機構による長尺動画理解のための知覚と推論の分離
SearchSwarm:長期の深層研究におけるエージェント型LLMの委譲知能に向けて
回顧的ハーネス最適化:経路 rollout に対する自己選好による LLM Agents の改善
ロールエージェント:デュアルロール進化によるLLM Agentsのブートストラップ
ABot-Earth 0.5: 生成3D地球モデル
Kwai Keye-VL-2.0 技術報告
TESSERA: 地表スペクトルの時間的埋め込みを用いた地球表現と解析
大規模言語モデル(LLMs)に人間らしい属性が備わっているとするならば、アジェ・オブ・エンパイアIIも同様である。
人工知能は、超人適応知能による専門化を受け入れる必要がある
空理空論に陥るサイコパシーボット:理想的ベイズ推定者でさえも
混沌のエージェント
HarnessX: 組み合わせ可能で適応的で進化的なエージェント・ハルスのファウンドリ
Orchestra-o1: オムニモーダル agent オーケストレーション
チャットボットからデジタル同僚へ:永続的自律型AIへのパラダイムシフト
記憶は検索されるのではなく再構築される:LLM Agentsのためのグラフメモリ
APPO: エージェント的手続き的ポリシー最適化
OmniDirector: 共通データを用いない一般化マルチショットカメラクローニング
InterleaveThinker: エージェント型インターリーブ生成の強化
MaxProof: 生成検証型強化学習および集団レベルのテスト時スケーリングによる数学的証明のスケールアップ
SpatialClaw: エージェント型空間推論のための行動インターフェースを再考する
WEAVEBENCH: ハイブリッドインターフェースを備えたComputer-Use Agentのためのロングホライズン・リアルワールドベンチマーク
MiniMax Sparse Attention
EvoArena: 動的環境における堅牢なLLM Agentsのためのメモリ進化追跡
Flex4DHuman: 4D人体再構築のための柔軟なマルチビュー動画拡散モデル
スケーラブルな空間生成のためのモダリティ強制
AGIからASIへ
ワールド・トレーシング:可視領域を超えた生成ピクセルアラインドジオメトリ
正則化f発散核検定
再帰なしで再帰型ネットワークを事前学習する
軌跡精緻化蒸留
MemDreamer:階層グラフメモリとエージェント検索機構による長尺動画理解のための知覚と推論の分離
SearchSwarm:長期の深層研究におけるエージェント型LLMの委譲知能に向けて
回顧的ハーネス最適化:経路 rollout に対する自己選好による LLM Agents の改善
ロールエージェント:デュアルロール進化によるLLM Agentsのブートストラップ
ABot-Earth 0.5: 生成3D地球モデル
Kwai Keye-VL-2.0 技術報告
TESSERA: 地表スペクトルの時間的埋め込みを用いた地球表現と解析
大規模言語モデル(LLMs)に人間らしい属性が備わっているとするならば、アジェ・オブ・エンパイアIIも同様である。