Command Palette
Search for a command to run...
OCC-RAG: 忠実な質問応答のための最適な認知コア
OCC-RAG: 忠実な質問応答のための最適な認知コア
Maksim Savkin Mikhail Goncharov Alexander Gambashidze Alla Chepurova Dmitrii Tarasov Nikita Andriianov Daria Pugacheva Vasily Konovalov Andrey Galichin Ivan Oseledets
概要
言語モデルの開発における近年の進歩は規模によって特徴づけられており、各世代はより多くの世界の知識をその重みに蓄積している。しかし、多くの実用的な応用分野では、広範なパラメトリック知識よりも堅牢な推論能力の方がより大きな恩恵をもたらす。このような状況において、タスク特化型小規模言語モデル(SLMs)は原理に基づいた設計選択を提供する。本研究では、この前提に基づいて構築されたSLMのシリーズであるOptimal Cognitive Core(OCC)を紹介する。OCCの派生モデルとして、提供されたコンテキストに忠実な質問応答(QA)に最適化されたOCC-RAGを提案する。このタスクはOCCの設計アプローチと直接整合し、記憶された知識を無視しつつ、提供されたテキスト断片に対してマルチホップ推論を行うことを要求する。OCC-RAGの学習には、マルチコンテキスト・マルチホップQAデータを大規模に合成するための新規パイプラインを実装し、マルチホップ推論、厳格なコンテキスト忠実性、および適切に調整された拒否を目的とした300万例以上のデータコーパスを生成した。本研究では、このコーパスを用いて中間学習(mid-training)を行ったOCC-RAG-0.6BおよびOCC-RAG-1.7Bを公開する。これらのモデルは、コンテキストからの原文そのままの引用に基づいた出典引用を伴う構造化された推論トレースを出力する。OCC-RAGを通じて、コンパクトなタスク特化型SLMsが、マルチホップ推論(HotpotQA, MuSiQue, TAT-QA)、忠実性(ConFiQA)、および拒否(MuSiQue-Un)の各ベンチマークにおいて、自身の2倍から6倍の規模を持つ汎用モデルと同等、あるいはそれ以上の性能を発揮することを示す。
One-sentence Summary
OCC-RAG is a task-specialized small language model optimized for faithful, context-grounded question answering that leverages a novel pipeline synthesizing over three million multi-hop training examples to generate structured reasoning traces with source citations and match or exceed general-purpose models two to six times its size across multi-hop reasoning (HotpotQA, MuSiQue, TAT-QA), faithfulness (ConFiQA), and refusal (MuSiQue-Un) benchmarks.
Key Contributions
- The paper introduces the Optimal Cognitive Core (OCC) family of small language models, specifically the OCC-RAG-0.6B and OCC-RAG-1.7B variants, which are engineered to prioritize multi-hop reasoning and strict context grounding over extensive parametric knowledge.
- A novel data synthesis pipeline generates over three million multi-context, multi-hop question-answering examples to train these models, enabling structured reasoning traces with literal source citations and calibrated abstention when contexts are insufficient.
- Comprehensive evaluations across HotpotQA, MuSiQue, TAT-QA, ConFiQA, and MuSiQue-Un demonstrate that these compact architectures match or exceed general-purpose models 2 to 6 times their size in multi-hop reasoning, faithfulness, and refusal benchmarks.
Introduction
The authors address the practical need for context question answering systems that prioritize robust reasoning over the massive parametric knowledge typical of frontier language models. Prior approaches frequently fail in this setting because large models tend to override supplied text with memorized facts, resulting in hallucinations and poor performance on multi-hop or unanswerable queries. To resolve these limitations, the authors introduce Optimal Cognitive Core and specifically present OCC-RAG, a family of small language models engineered for strict context grounding. They leverage a novel data synthesis pipeline to generate over three million multi-hop training examples that enforce evidence-based reasoning and calibrated abstention. The resulting 0.6B and 1.7B models produce structured reasoning traces with literal source citations and consistently outperform general-purpose models two to six times their size across faithfulness, multi-hop reasoning, and refusal benchmarks.
Dataset

- Dataset Composition and Sources: The authors construct a large-scale reasoning corpus by combining cleaned English Wikipedia paragraphs with structured knowledge extracted from the MuSiQue training split. They ground entity normalization in Wikidata ontologies and adopt the DRAGON benchmark taxonomy to define question complexity.
- Subset Details and Filtering Rules: The final corpus contains approximately 3.25 million question-answer pairs. Single-hop examples (2.78 million) are generated from Wikipedia paragraphs using gpt-oss-120B, with distractor contexts mined via TF-IDF cosine similarity and capped at the top twenty matches per paragraph. Multi-hop examples (427,000 total) are synthesized from MuSiQue data. The authors transform these into an RDF knowledge graph and use SPARQL templates to sample specific subgraph shapes, covering simple, two-hop, and three-hop bamboo-style questions. The refusal subset (43,000 pairs) is constructed by feeding reduced context windows into a SQuAD-fine-tuned DeBERTa model and flagging mismatches as hard abstention cases.
- Training Usage and Mixture Ratios: All generated pairs are allocated to the training split. The mixture is heavily weighted toward single-hop data, which consumes roughly 7.76 billion out of 8 billion total Qwen3 tokens. Distractor contexts consistently occupy between 35% and 75% of the token budget across all subsets, ensuring the model learns to navigate irrelevant information alongside gold passages.
- Metadata Construction and Processing Pipeline: Every pair is enriched with a structured reasoning trace generated by Qwen3.5-27B, following a fixed schema that includes Query Analysis, Source Analysis, Reasoning, Answer, and a binary Status field. The authors disable the model's native thinking mode to control costs and prevent redundant internal traces. Traces undergo a four-step validation process: format completeness checks, exact answer matching, LLM-as-judge verification using Qwen3-4B, and an overthinking filter that discards chains exceeding 1,256 tokens or containing more than ten manual thinking markers. Paragraph-level chunking remains the fundamental context unit, and all final outputs are strictly extractive and self-contained.
Method
The authors leverage a structured reasoning framework to design the OCC-RAG model architecture, emphasizing multi-hop inference, faithfulness to context, and calibrated abstention. The core of the model's reasoning process is defined by a sequential workflow that begins with query and context input, progressing through distinct analytical stages before producing a final answer and status verdict. Refer to the framework diagram  .
.
The first stage, Query Analysis, involves interpreting the question to identify the required information. This is followed by Source Analysis, where the model evaluates the provided context passages, each tagged with a unique source identifier, to determine which sources contain relevant information. The subsequent Reasoning stage integrates information from the identified sources, applying logical steps such as inference and verification to derive a conclusion. The output of this process is a status (ANSWERABLE or UNANSWERABLE) and the final answer. This modular structure ensures that each step in the reasoning process is explicitly grounded in the input context.
The model is trained via supervised fine-tuning on synthetic data generated from structured reasoning traces. The training objective focuses on response tokens, with the full prompt/response format designed to mirror the evaluation setup, eliminating train-test mismatch. The prompt consists of a question and context passages in random order, each labeled with a numeric identifier. The response includes a detailed reasoning trace formatted according to the defined structure, with the final answer and answerability verdict embedded within the trace. Special tokens are used to delineate different components of the prompt and response, with their embeddings initialized from the mean of subword embeddings corresponding to their natural-language names.
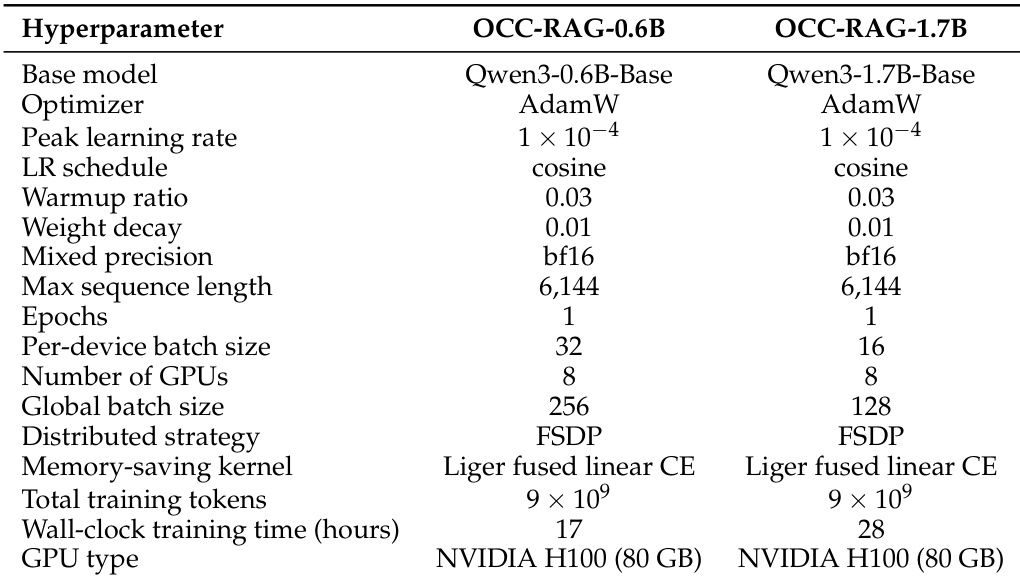
The training corpus comprises three subsets: single-hop, multi-hop single-context, and multi-hop multi-context. To emphasize the development of multi-hop reasoning capabilities, the multi-hop subsets are oversampled three times per epoch relative to single-hop examples. This data mixing strategy improves multi-hop accuracy without degrading performance on single-hop tasks. The models, OCC-RAG-0.6B and OCC-RAG-1.7B, are derived from the Qwen3-Base models, selected for their superior performance in initial evaluations. Both models are trained on approximately 9×109 tokens using 8 NVIDIA H100 GPUs, with full training details provided in the appendix.
Experiment
The evaluation assesses the OCC-RAG models across three core dimensions: multi-hop reasoning, faithfulness to provided context, and refusal when evidence is insufficient. These experiments validate whether compact models can accurately synthesize information across multiple sources, strictly adhere to counterfactual prompts rather than relying on parametric knowledge, and appropriately abstain from answering when context is lacking. The qualitative results demonstrate that the models successfully prioritize supplied evidence over memorized facts while maintaining robust refusal capabilities despite their small size. Ultimately, the study concludes that targeted training enables small language models to achieve reliable, context-grounded reasoning and calibrated abstention, offering a highly efficient alternative to scaling larger general-purpose models.
The authors evaluate models on multi-hop reasoning, faithfulness, and refusal using benchmarks that assess context grounding and reasoning capabilities. The evaluation focuses on how well models adhere to provided context, handle multi-hop questions, and refuse answers when evidence is insufficient, with results showing that smaller models can achieve performance comparable to larger ones in specific dimensions. Models are evaluated on multi-hop reasoning, faithfulness, and refusal using datasets that require context grounding and reasoning. OCC-RAG models achieve competitive results on faithfulness and refusal metrics despite being smaller than many baselines. The evaluation includes benchmarks that measure In-Accuracy, F1, Memorization Ratio, and Refusal Accuracy to assess different aspects of model behavior.

The authors compare two OCC-RAG models, a 0.6B and a 1.7B parameter variant, trained with similar hyperparameters except for model size and batch size. Both models use the same base architecture and training setup, with the larger model requiring more training time and a larger global batch size. The training configuration supports efficient distributed training on NVIDIA H100 GPUs with mixed precision and a cosine learning rate schedule. Both OCC-RAG models use the same base architecture and training setup, differing primarily in model size and batch size. The training configuration employs a cosine learning rate schedule, mixed precision, and distributed training with FSDP. The larger model requires more training time and a larger global batch size, reflecting its increased scale.
The authors evaluate various language models on multi-hop reasoning, faithfulness, and refusal tasks, using benchmarks that assess context grounding and the ability to avoid hallucination. Results show that OCC-RAG models, despite being significantly smaller, achieve competitive or superior performance compared to larger models, particularly in faithfulness and refusal, demonstrating effective context adherence without relying on memorized knowledge. OCC-RAG models achieve high faithfulness and refusal performance, outperforming larger models on context grounding benchmarks. Despite being 2-6 times smaller, OCC-RAG models match or exceed the performance of models up to 4B parameters on multi-hop reasoning and refusal. OCC-RAG-1.7B achieves the best results on faithfulness and refusal, showing strong adherence to provided context and effective abstention when evidence is insufficient.
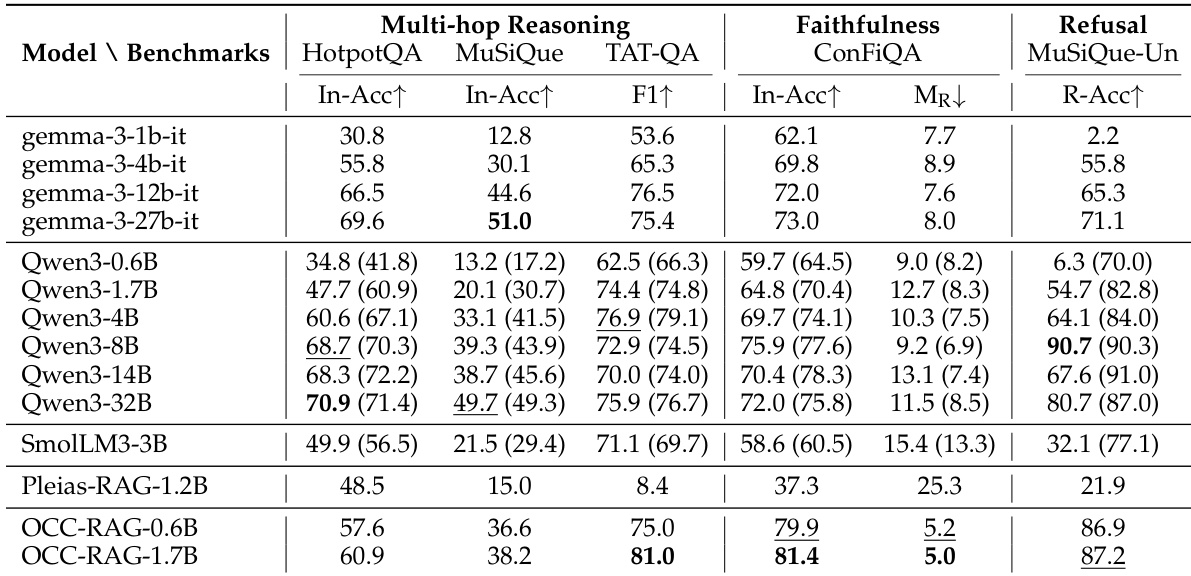
The evaluation employs benchmarks designed to assess multi-hop reasoning, faithfulness, and refusal capabilities, specifically validating how models adhere to provided context and appropriately decline responses when evidence is insufficient. Despite their significantly smaller parameter counts, the OCC-RAG variants achieve competitive or superior performance against larger baselines, particularly excelling in context grounding and evidence-based abstention. These qualitative results demonstrate that efficient model scaling can effectively maintain strong reasoning capabilities and minimize hallucination without relying on memorized knowledge.