HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

TriSplat: シミュレーション対応のフィードフォワード3Dシーン再構築

ファウンデーションプロトコル:エージェント社会のための協調レイヤー








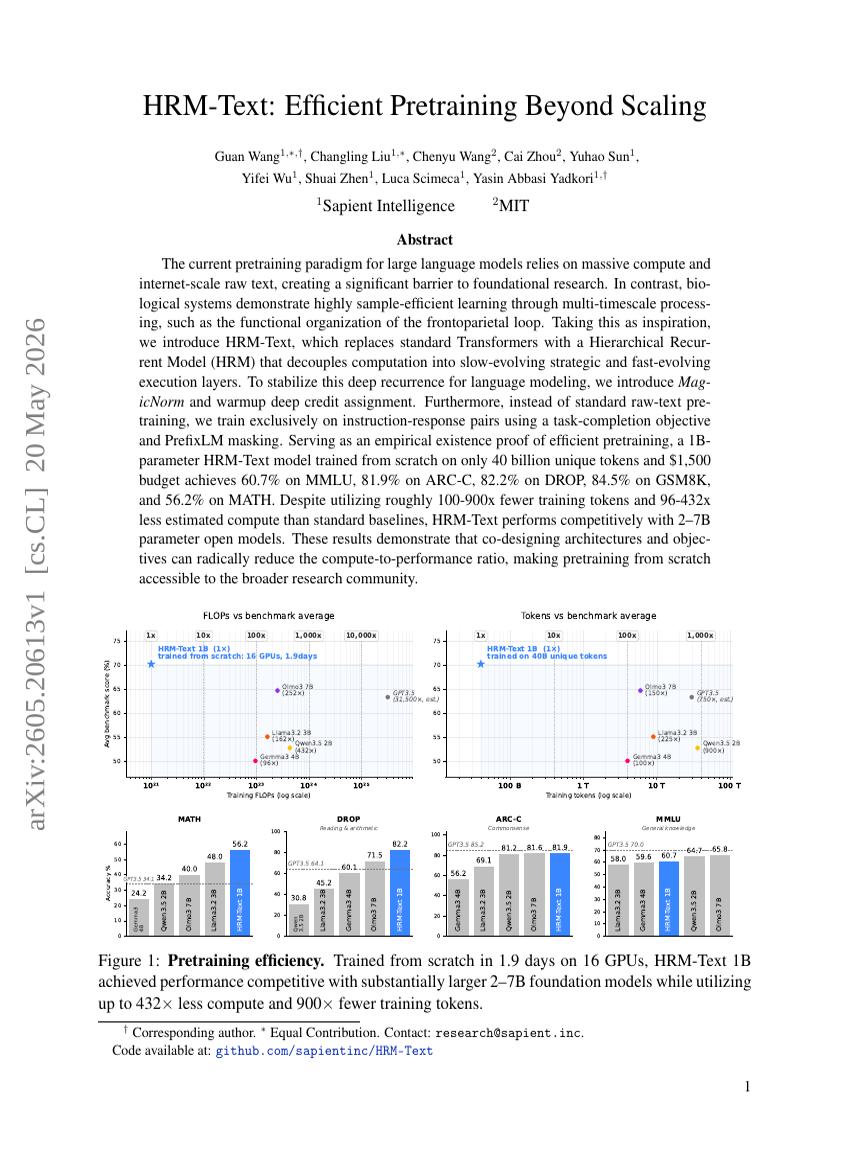
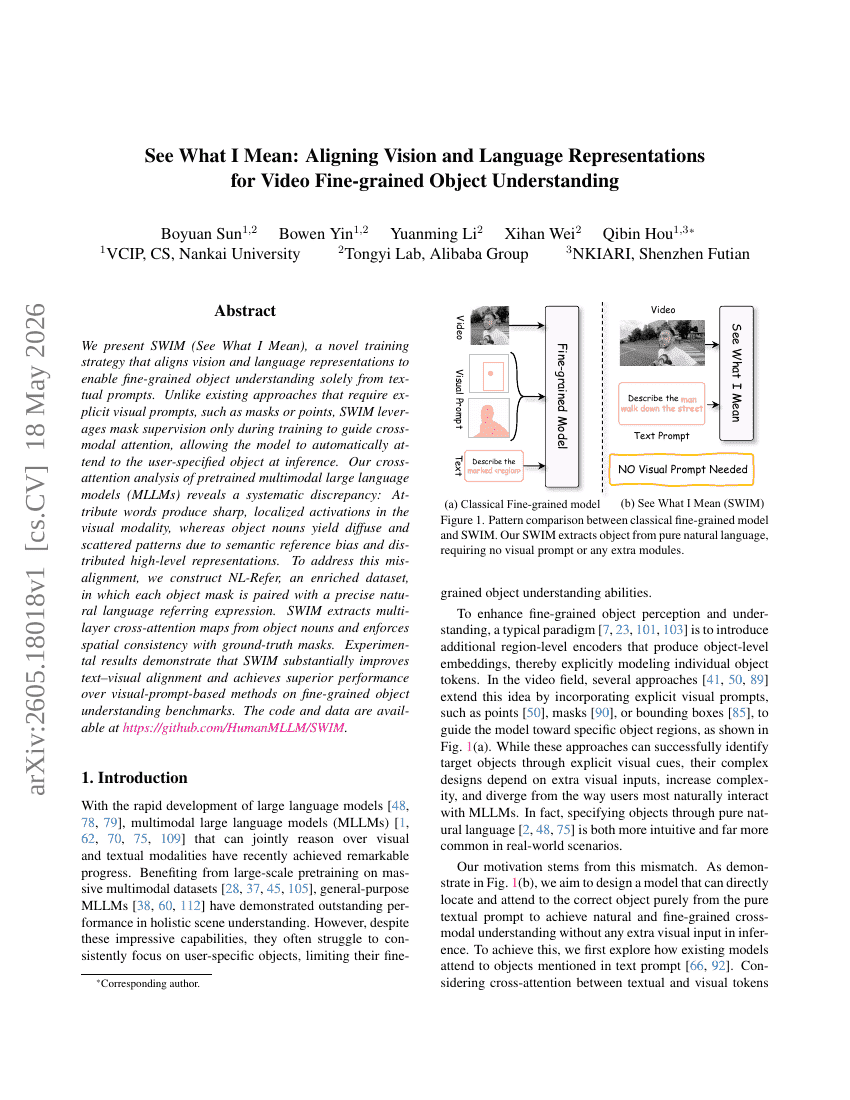

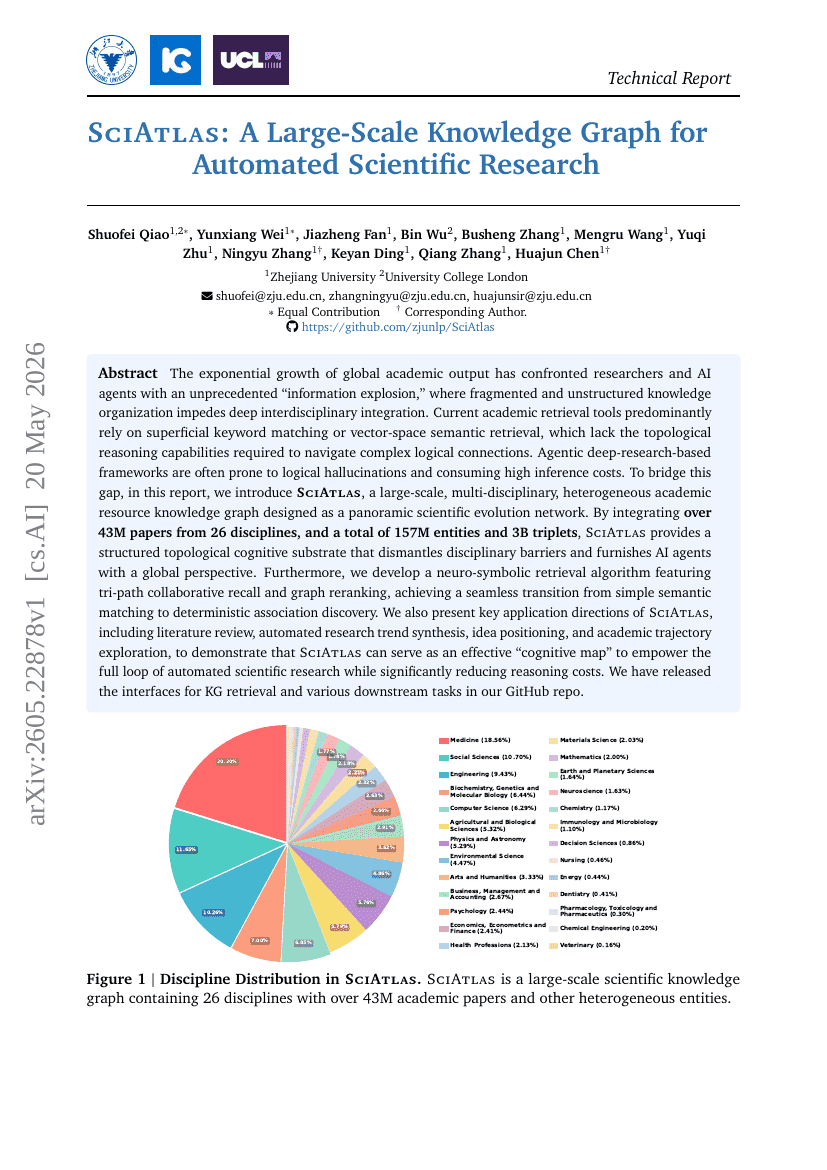
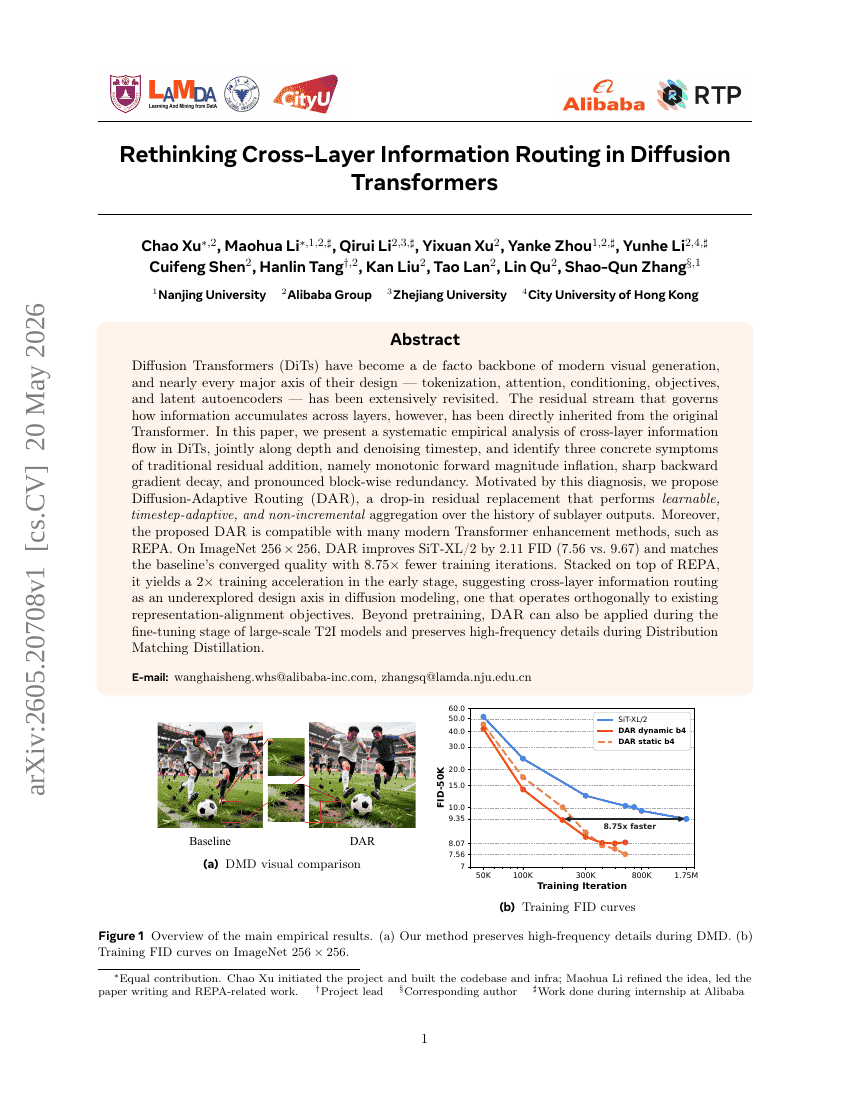
















TriSplat: シミュレーション対応のフィードフォワード3Dシーン再構築
ファウンデーションプロトコル:エージェント社会のための協調レイヤー
WBench: インタラクティブなビデオワールドモデル評価のための包括的なマルチターンベンチマーク
Macaron-A2UI: パーソナルエージェントにおける生成UIのためのモデル
DVAO: 多報酬強化学習のための動的分散適応型アドバンテージ最適化
ViMU: ビデオの比喩的理解の評価
SMOL:115の過小代表言語のための専門的に翻訳された並列データ
Chi-Bench: AIエージェントは、エンドツーエンドで長期にわたる、政策に富む医療ワークフローを自動化できるか?
大規模言語モデルにおける長期文脈の推論のためのオンポリシー最適化と蒸留の融合
対照のレンズを通じて:VLMにおける自己改善型視覚推論
HRM-Text: スケーリングを超えた効率的な事前トレーニング
私が何を意味しているかを見る:ビデオの細粒度オブジェクト理解のためにビジョンと言語表現をアラインする
StepAudio 2.5 技術報告書
SciAtlas: 自動化された科学的研究のための大規模知識グラフ
拡散トランスフォーマーにおけるクロスレイヤー情報ルーティングの再考
Lens: 基礎的なテキストから画像へのモデルのトレーニング効率を再考する
SkillOpt: 自己進化するエージェントスキルのための実行戦略
CVEvolve: 非構造化科学データ処理のための自律的アルゴリズム発見
Poly-EPO: 探索的推論モデルのトレーニング
概要
ACC: 長期コンテキストトレーニングのためのエージェント軌道のコンパイル
フルアテンションが再び襲来:数百のトレーニングステップ内でフルアテンションをスパースに変換する
π-Bench: 長期ワークフローにおけるプロアクティブなパーソナルアシスタントエージェントの評価
知覚か偏見か:大規模言語モデルは性格の第一印象を超えられるか?
TransitLM: マップフリーな交通経路生成のための大規模データセットとベンチマーク
DelTA: 検証可能な報酬からの強化学習における判別トークン信用割り当て
インタラクティブな評価にはデザイン科学が必要である
ESI-BENCH: 知覚と行動のループを閉じる具現化された空間知能 towards
複数の可視スペクトラムにわたるドローン画像を用いた軍事検出の比較分析
精神疾患診断のICD分類の自動化:古典的NLPから大規模言語モデルへ
コミュニティIBRの残存容量を用いた配電系統における協調的最適な電力品質管理
EllipseLIO: 楕円体表現を用いた適応型LiDAR慣性オドメトリ
WBench: インタラクティブなビデオワールドモデル評価のための包括的なマルチターンベンチマーク
Macaron-A2UI: パーソナルエージェントにおける生成UIのためのモデル
DVAO: 多報酬強化学習のための動的分散適応型アドバンテージ最適化
ViMU: ビデオの比喩的理解の評価
SMOL:115の過小代表言語のための専門的に翻訳された並列データ
Chi-Bench: AIエージェントは、エンドツーエンドで長期にわたる、政策に富む医療ワークフローを自動化できるか?
大規模言語モデルにおける長期文脈の推論のためのオンポリシー最適化と蒸留の融合
対照のレンズを通じて:VLMにおける自己改善型視覚推論
HRM-Text: スケーリングを超えた効率的な事前トレーニング
私が何を意味しているかを見る:ビデオの細粒度オブジェクト理解のためにビジョンと言語表現をアラインする
StepAudio 2.5 技術報告書
SciAtlas: 自動化された科学的研究のための大規模知識グラフ
拡散トランスフォーマーにおけるクロスレイヤー情報ルーティングの再考
Lens: 基礎的なテキストから画像へのモデルのトレーニング効率を再考する
SkillOpt: 自己進化するエージェントスキルのための実行戦略
CVEvolve: 非構造化科学データ処理のための自律的アルゴリズム発見
Poly-EPO: 探索的推論モデルのトレーニング
概要
ACC: 長期コンテキストトレーニングのためのエージェント軌道のコンパイル
フルアテンションが再び襲来:数百のトレーニングステップ内でフルアテンションをスパースに変換する
π-Bench: 長期ワークフローにおけるプロアクティブなパーソナルアシスタントエージェントの評価
知覚か偏見か:大規模言語モデルは性格の第一印象を超えられるか?
TransitLM: マップフリーな交通経路生成のための大規模データセットとベンチマーク
DelTA: 検証可能な報酬からの強化学習における判別トークン信用割り当て
インタラクティブな評価にはデザイン科学が必要である
ESI-BENCH: 知覚と行動のループを閉じる具現化された空間知能 towards
複数の可視スペクトラムにわたるドローン画像を用いた軍事検出の比較分析
精神疾患診断のICD分類の自動化:古典的NLPから大規模言語モデルへ
コミュニティIBRの残存容量を用いた配電系統における協調的最適な電力品質管理
EllipseLIO: 楕円体表現を用いた適応型LiDAR慣性オドメトリ