Command Palette
Search for a command to run...
信頼域行動混合によるオンポリシー蒸留
信頼域行動混合によるオンポリシー蒸留
Daniil Plyusov Alexey Gorbatovski Alexey Malakhov Nikita Balagansky Boris Shaposhnikov Daria Korotyshova Daniil Gavrilov
概要
オンポリシー蒸留(OPD)は、より強力な教師モデルに追従させながら、自身のポリシーからサンプリングされたプレフィックス上で学生モデルを訓練する。これはオフライン蒸留におけるプレフィックスの不整合を解消するが、初期の学生ロールアウトは依然として質が低く、教師からの監督が弱かったり質の低いプレフィックスに適用されてしまう問題が残る。本研究では、Trust-Region behavior Blending(TRB)を提案する。これは、学生中心のKL信頼領域内において教師に最も近い行動ポリシーに初期ロールアウトポリシーを置き換え、かつプレフィックスごとの逆KL-OPD損失は変更しないウォームアップ手法である。KL予算はゼロに減衰されるため、ウォームアップ終了後は純粋な学生ロールアウトのみによる訓練に戻る。2つの数学推論蒸留設定において、TRBは比較対象の手法の中で最も高い平均性能を達成した。
One-sentence Summary
Trust-Region behavior Blending (TRB) is a warmup method for on-policy distillation that replaces poor early student rollouts with a closest-to-teacher behavior policy inside a student-centered KL trust region, preserving the per-prefix reverse-KL loss while achieving the strongest average performance across two mathematical reasoning distillation settings.
Key Contributions
- Trust-Region behavior Blending (TRB) replaces early student rollouts in on-policy distillation with a behavior policy constrained within a student-centered KL trust region to preserve supervision quality.
- The method optimizes the early prefix distribution instead of altering post-generation targets or token selection, and its KL budget anneals to zero to restore pure student rollouts after the warmup horizon.
- Experiments across two math-reasoning distillation settings show that TRB achieves the strongest average performance among vanilla on-policy distillation and alternative teacher-guidance baselines.
Introduction
Knowledge distillation transfers reasoning capabilities from large teacher models to smaller student models, but traditional methods suffer from exposure bias because students train on fixed teacher prefixes rather than their own rollouts. On-policy distillation addresses this by supervising the student on trajectories it actually generates, yet early training remains brittle since weak students produce low-quality prefixes and stronger teacher intervention risks breaking the on-policy guarantee. The authors leverage Trust-Region behavior Blending (TRB) to stabilize early rollout collection by optimizing a teacher-guided behavior policy within a strict KL trust region around the student. This approach delivers targeted teacher supervision during the critical warmup phase without modifying the underlying distillation objective, and the blending mechanism is systematically annealed once the student policy matures.
Method
The authors leverage a trust-region optimization framework to design Trust-Region behavior Blending (TRB), a warmup strategy for on-policy distillation (OPD) that improves early training stability by guiding rollout generation toward the teacher policy while respecting a student-centered trust region. The core idea is to replace the student’s own policy for generating prefixes during the initial phase of training with a behavior policy that balances proximity to the teacher and adherence to the student’s current behavior. This approach preserves the reverse-KL OPD loss, which remains unchanged throughout training, but modifies the sampling distribution used to collect prefixes. The behavior policy is defined as the closest-to-teacher policy within a KL-divergence constraint relative to the current student policy, ensuring that the generated prefixes are both teacher-informed and not excessively divergent from the student’s current behavior.
Refer to the framework diagram, which illustrates the optimization process at a given prefix h. The student policy πS is represented as a point in the policy space, and the teacher policy πT is another point. The dashed circle around πS represents the student-centered KL trust region, defined by the constraint DKL(μ∥πS)≤ε. The behavior policy μ∗ is the solution to minimizing the KL divergence to the teacher policy DKL(μ∥πT) subject to this constraint. This solution lies on the boundary of the trust region and is the closest policy to the teacher within the allowed deviation. The figure highlights that the optimal policy μ∗ is obtained by balancing the influence of the teacher and the student, with the constraint ensuring that the policy does not stray too far from the student’s current distribution.
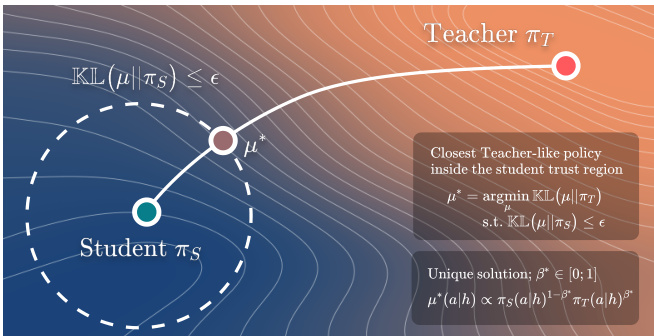
The per-prefix behavior policy is defined as the solution to a constrained optimization problem. At a prefix h, the goal is to find a policy μ∗(⋅∣h) that minimizes the KL divergence to the teacher policy πT(⋅∣h) while ensuring that the KL divergence to the student policy πS(⋅∣h) does not exceed a predefined budget ε. This is formulated as:
μ∗(⋅∣h)=μargminDKL(μ∥πT)s.t.DKL(μ∥πS)≤ε,∑aμ(a)=1,μ(a)≥0.This optimization selects the most teacher-like distribution that remains within a local deviation from the current student policy, effectively guiding the student toward the teacher while maintaining stability. The solution to this problem has a closed-form expression that combines the student and teacher policies in a weighted manner. Specifically, the behavior policy is given by:
μβ(a∣h)=Zβ(h)πS(a∣h)1−βπT(a∣h)β,where β∈[0,1] controls the degree of influence from the teacher, and Zβ(h) is a normalization constant. The optimal value β∗(h) is the largest feasible β such that the KL divergence constraint is satisfied:
β∗(h)=max{β∈[0,1]∣DKL(μβ∥πS)≤ε}.When ε=0, the policy remains unchanged from the student policy, and if the teacher policy itself satisfies the constraint, the behavior policy becomes the teacher policy. Otherwise, β∗(h) is computed via binary search, leveraging the monotonicity of DKL(μβ∥πS) in β, which ensures convergence.
To further control the transition from teacher-guided to student-driven sampling, TRB employs an annealed warmup schedule. The KL budget ε is gradually reduced over a warmup horizon K, starting from an initial value ε0 and decreasing linearly to zero. The budget at step k is given by:
εk=ε0(1−Kk),k≤K.This annealing ensures that early rollouts are more influenced by the teacher, providing stable supervision, while the policy gradually reverts to pure student rollouts as training progresses, allowing the student to eventually learn from its own behavior. This mechanism introduces two key hyperparameters: the initial KL budget ε0 and the warmup horizon K, which determine the strength and duration of the teacher guidance during the warmup phase.
Experiment
The evaluation compares TRB against vanilla OPD and persistent off-policy baselines across two Qwen3 teacher-student model pairs to determine whether limited early behavioral guidance improves final reasoning performance. Benchmark comparisons validate that TRB achieves superior average outcomes by leveraging the same local solver more effectively than fixed blending strategies, while early-training analyses confirm that targeted warmup interventions successfully shift initial rollouts toward teacher-aligned prefixes. These findings indicate that brief early guidance effectively resolves initial student-teacher misalignment, whereas maintaining off-policy behavior throughout training yields diminishing returns and unnecessary computational overhead.
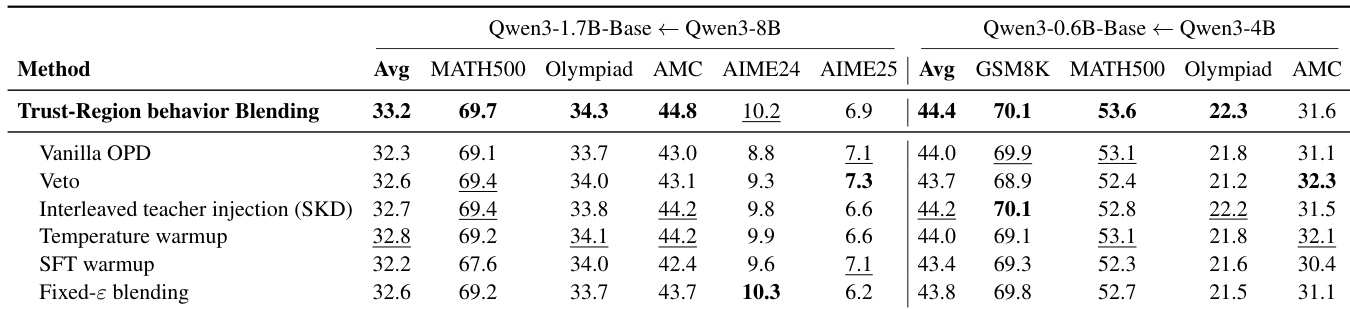
The authors conduct experiments to evaluate TRB, a method that uses limited early guidance from the teacher to improve OPD outcomes. Results show that TRB achieves the highest average performance across two model-pair settings, outperforming baselines that use stronger or more persistent off-policy guidance. The method is most effective during the initial training phase, where it shifts the student's early rollouts toward more promising prefixes, with diminishing returns once the student and teacher behavior aligns. TRB achieves the best average performance in both model-pair settings compared to other off-policy methods. TRB's effectiveness is concentrated during early training, with no need for persistent teacher guidance. The method improves early student rollouts by guiding them toward prefixes that are more likely to succeed under both teacher and student continuation.
The authors evaluate Trust-Region Behavior Blending (TRB) against several baselines in two model-pair settings, showing that TRB achieves the highest average performance across all tasks. Results indicate that early guidance from the teacher improves final outcomes, with TRB outperforming methods that apply teacher guidance persistently or use different warmup strategies. The best-performing methods consistently achieve higher scores in the Qwen3-1.7B-Base setup compared to the smaller Qwen3-0.6B-Base setup. TRB achieves the best average performance in both model-pair settings, outperforming all baselines. TRB shows superior results compared to methods with persistent teacher guidance or fixed epsilon blending. The performance gap between TRB and other methods is most pronounced in the larger model-pair setup.
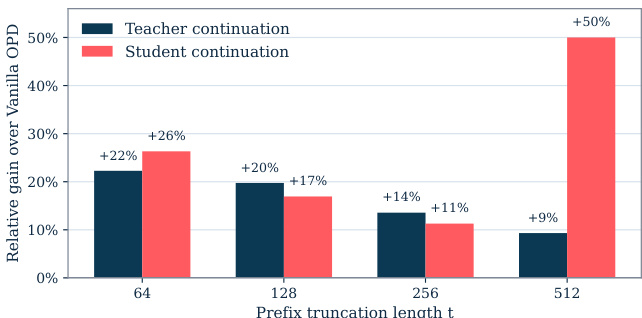
The authors analyze the impact of early behavior guidance on off-policy distillation by comparing teacher and student continuation strategies during the warmup phase. Results show that teacher-guided continuation consistently outperforms student continuation across different prefix truncation lengths, with the performance gap increasing as the prefix length grows. The relative gain of teacher continuation over vanilla OPD is higher at longer truncation lengths, indicating that early guidance becomes more effective when the student's initial rollouts are further from the teacher's distribution. Teacher continuation provides higher relative gains than student continuation across all prefix lengths. The performance advantage of teacher continuation increases with longer prefix truncation lengths. The relative gain of teacher continuation over vanilla OPD is more pronounced at longer prefix lengths.
The authors evaluate Trust-Region Behavior Blending against multiple off-policy baselines across two model-pair configurations to determine how limited early teacher guidance impacts distillation outcomes. The primary experiments validate that strategically applying brief teacher guidance during initial training significantly improves final performance by steering early rollouts toward successful prefixes, while continuous guidance yields diminishing returns. A secondary analysis of warmup strategies confirms that teacher-guided continuation consistently outperforms student-led approaches, with the most substantial improvements occurring when initial rollouts diverge substantially from the target distribution. Collectively, these findings establish that targeted early intervention is a more efficient and effective strategy than persistent supervision for optimizing off-policy distillation.