HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

SMoA: パラメータ効率的なファインチューニングのためのスペクトラム変調アダプタ

スペクトル回帰分析によるトロイ化DNNの検出



























SMoA: パラメータ効率的なファインチューニングのためのスペクトラム変調アダプタ
スペクトル回帰分析によるトロイ化DNNの検出
思考の幻想:問題複雑性の視点から推論モデルの強みと限界を理解する
生成再帰的推論
セーフティプレトレーニング:次世代の安全なAIに向けて
RubricEM: 検証可能な報酬を超えたルールに基づく政策分解によるメタ強化学習
視覚が音のために話すとき
AutoResearchClaw: 人間とAIの協働による自己強化型自律的研究
学習された信頼性を用いたプロセス報酬
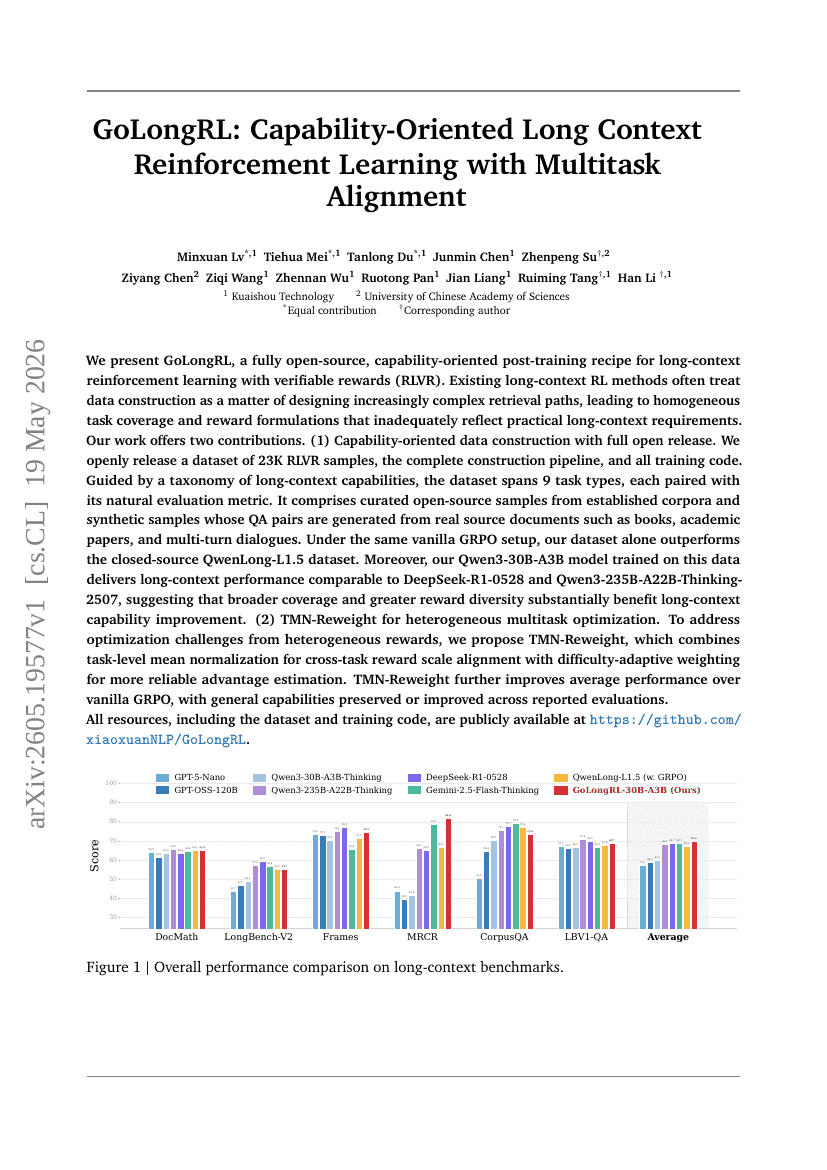
GoLongRL: マルチタスクアライメントによる能力指向型長期コンテキスト強化学習
OpenComputer: コンピュータ使用エージェントのための検証可能なソフトウェア世界
ポイントワイズ相互情報量を用いた推論RLのためのアンチ自己蒸留
Contrastive Pair Searchによる標的ニューロン修飾
連続拡散は言語における離散拡散と競合的にスケールする
KVPO: KV意味探索による自己回帰的ビデオアライメントのためのODEネイティブGRPO
Code-as-Room: エージェント型コード合成によるトップダウンビュー画像からの3Dルーム生成
自動研究のためのAI:ロードマップとユーザーガイド
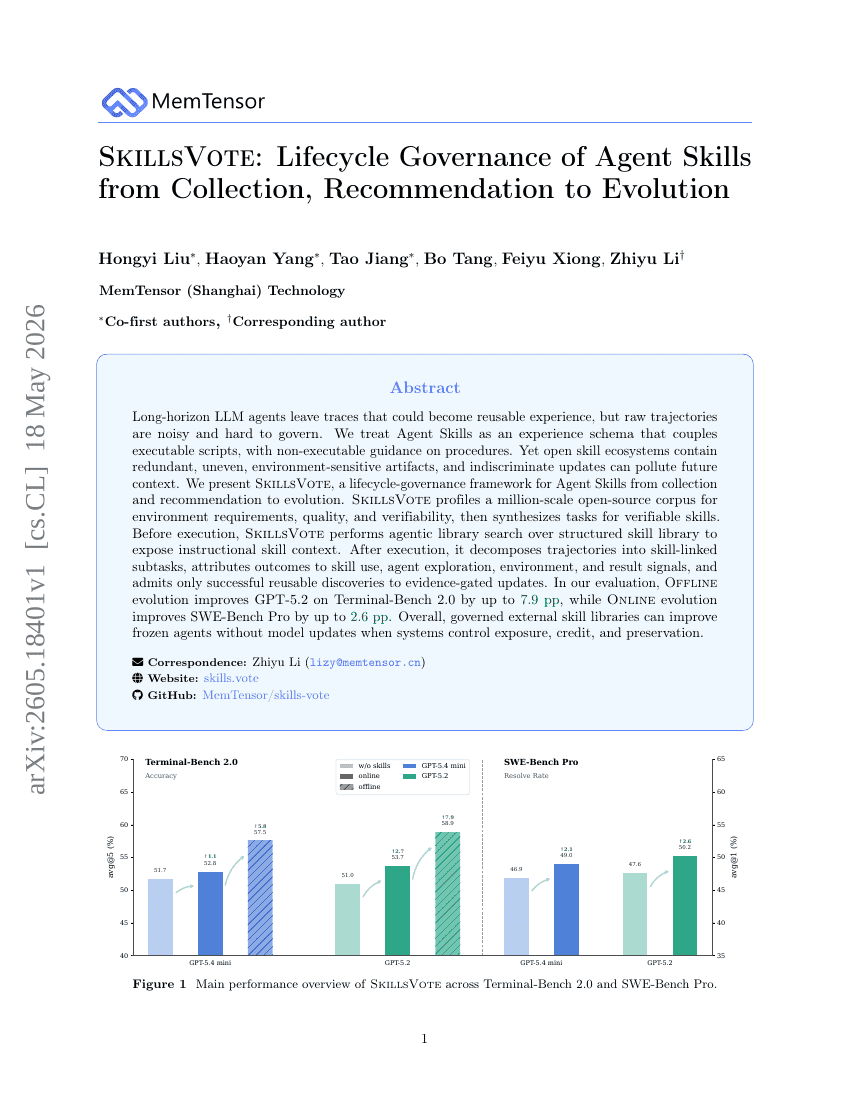
SkillsVote: コレクション、レコメンデーションから進化に至るまでのエージェントスキルのライフサイクルガバナンス
Lance: マルチタスクシナジーによる統一マルチモーダルモデリング
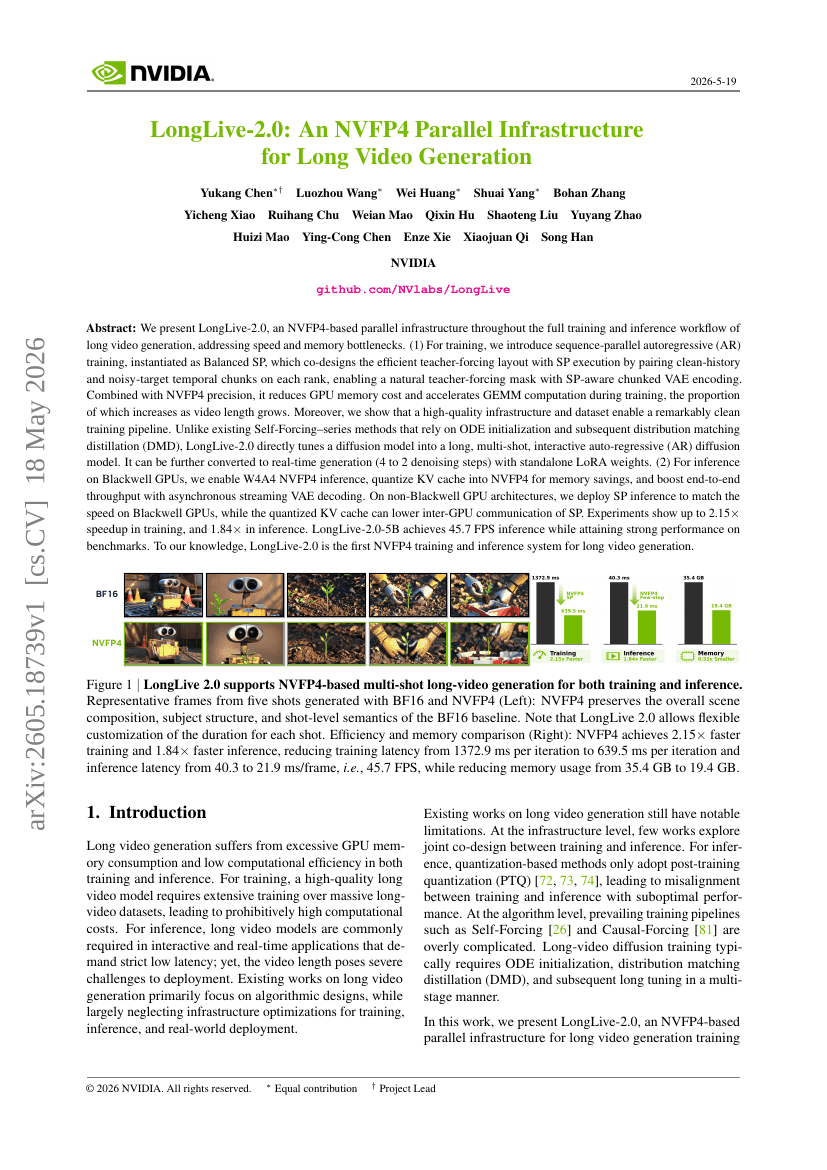
LongLive-2.0: 長編動画生成のためのNVFP4並列インフラストラクチャ
スライシングとダイシング:最適のエキスパート混合の構成
エージェント型ニューラルアーキテクチャ探索: AIRA-ComposeおよびAIRA-Design
先読みする学習:オンポリシー蒸留の解錠効率の解明
DexJoCo: MuJoCo上でのタスク指向の巧みな操作のためのベンチマークおよびツールキット
FashionChameleon: リアルタイムかつインタラクティブな人間-衣類ビデオカスタマイズに向けて
CiteVQA: 信頼性の高いドキュメントインテリジェンスのための根拠帰属の評価
MMSkills: 一般視覚エージェントのためのマルチモーダルスキルに向けて
PhysBrain 1.0 技術報告書
価値モデルの復活:LLM強化学習における価値モデル化のための生成批評
NEXUS: 時系列予測のためのエージェント型フレームワーク
MemEye: 多モーダルエージェントのメモリに対する視覚中心の評価フレームワーク
SANA-WM: ハイブリッド線形拡散トランスフォーマーによる効率的な分単位の世界モデル
思考の幻想:問題複雑性の視点から推論モデルの強みと限界を理解する
生成再帰的推論
セーフティプレトレーニング:次世代の安全なAIに向けて
RubricEM: 検証可能な報酬を超えたルールに基づく政策分解によるメタ強化学習
視覚が音のために話すとき
AutoResearchClaw: 人間とAIの協働による自己強化型自律的研究
学習された信頼性を用いたプロセス報酬
GoLongRL: マルチタスクアライメントによる能力指向型長期コンテキスト強化学習
OpenComputer: コンピュータ使用エージェントのための検証可能なソフトウェア世界
ポイントワイズ相互情報量を用いた推論RLのためのアンチ自己蒸留
Contrastive Pair Searchによる標的ニューロン修飾
連続拡散は言語における離散拡散と競合的にスケールする
KVPO: KV意味探索による自己回帰的ビデオアライメントのためのODEネイティブGRPO
Code-as-Room: エージェント型コード合成によるトップダウンビュー画像からの3Dルーム生成
自動研究のためのAI:ロードマップとユーザーガイド
SkillsVote: コレクション、レコメンデーションから進化に至るまでのエージェントスキルのライフサイクルガバナンス
Lance: マルチタスクシナジーによる統一マルチモーダルモデリング
LongLive-2.0: 長編動画生成のためのNVFP4並列インフラストラクチャ
スライシングとダイシング:最適のエキスパート混合の構成
エージェント型ニューラルアーキテクチャ探索: AIRA-ComposeおよびAIRA-Design
先読みする学習:オンポリシー蒸留の解錠効率の解明
DexJoCo: MuJoCo上でのタスク指向の巧みな操作のためのベンチマークおよびツールキット
FashionChameleon: リアルタイムかつインタラクティブな人間-衣類ビデオカスタマイズに向けて
CiteVQA: 信頼性の高いドキュメントインテリジェンスのための根拠帰属の評価
MMSkills: 一般視覚エージェントのためのマルチモーダルスキルに向けて
PhysBrain 1.0 技術報告書
価値モデルの復活:LLM強化学習における価値モデル化のための生成批評
NEXUS: 時系列予測のためのエージェント型フレームワーク
MemEye: 多モーダルエージェントのメモリに対する視覚中心の評価フレームワーク
SANA-WM: ハイブリッド線形拡散トランスフォーマーによる効率的な分単位の世界モデル