HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

最後の人間による論文:エージェントネイティブな研究アーティファクト
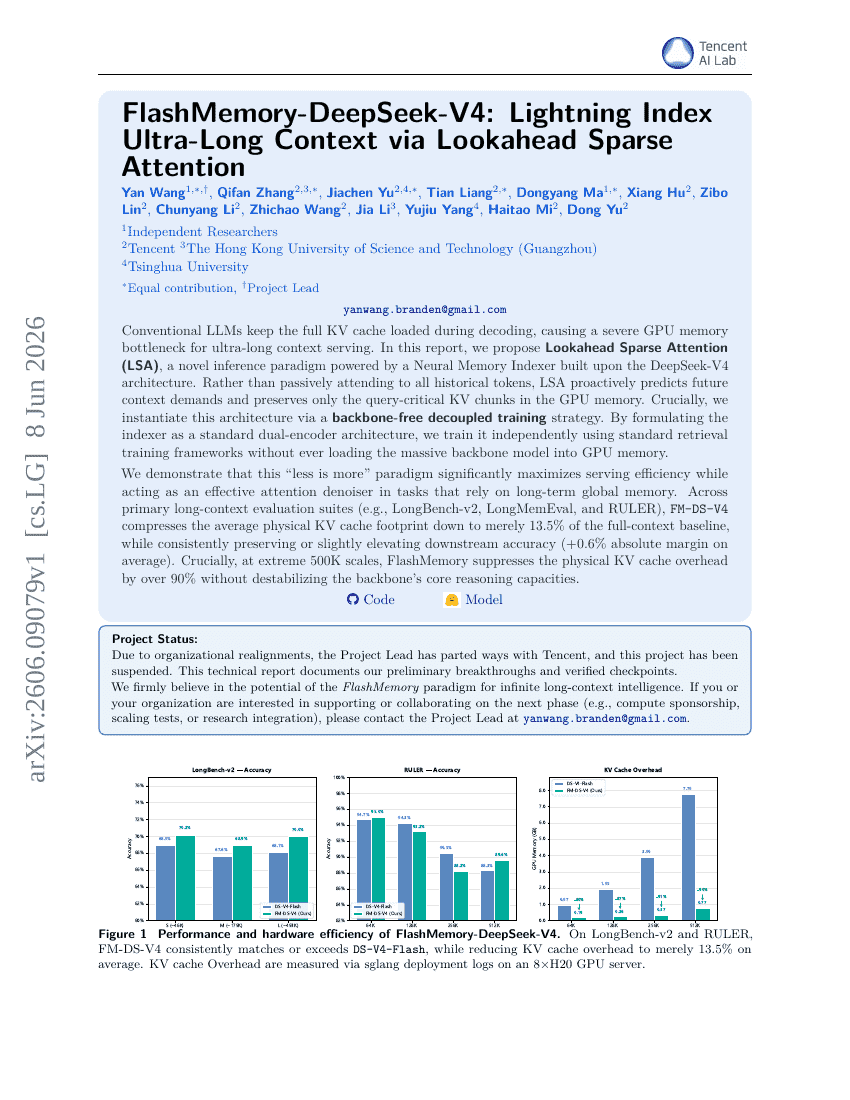
FlashMemory-DeepSeek-V4: 先読みスパースアテンションによる超長コンテキスト用の超高速インデックス





























最後の人間による論文:エージェントネイティブな研究アーティファクト
FlashMemory-DeepSeek-V4: 先読みスパースアテンションによる超長コンテキスト用の超高速インデックス
LatentSkill: コンテキスト内テキストスキルから重み内潜在スキルへ LLM Agents 向け
CoVEBench: 動画編集モデルは複雑な指示を処理できるか?
動画世界モデルのための潜在空間記憶
オンポリシー蒸留の幾何学について
SWE-Explore: コーディング agents がリポジトリを探索する方法のベンチマーク
VoxCPM2技術報告書
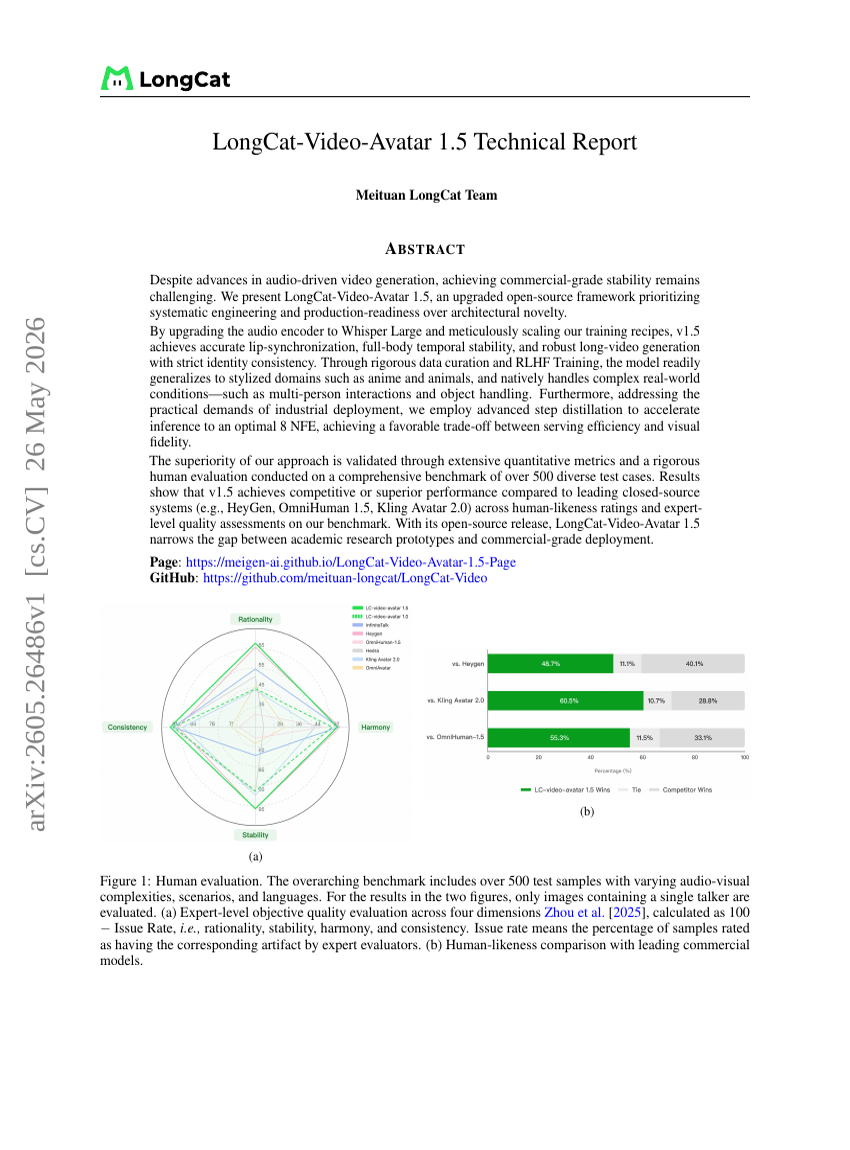
LongCat-Video-Avatar 1.5 技術報告
ChartNet: 堅牢なチャート理解のための百万規模・高品質マルチモーダルデータセット
ACL-Verbatim: 研究におけるハルシネーションフリーの質問応答
静的対話を超える:現実的、多様で進化し続ける長期記憶のためのベンチマーク
ソフトウェアエンジニアリングの終焉:AIエージェントがどのようにソフトウェアのパラダイムを根本から再構築しているか
なぜ大規模なモデルはより多くのことを学習するのか:容量、干渉、および稀なタスク保持の影響
ツールが失敗したとき:LLM Agentsにおける動的再計画と異常回復のベンチマーク
分解された視覚プロキシを用いた直接3D認識物体挿入
AnchorWorld: 視点に基づく進化カスタマイズを用いた具身自己中心世界シミュレーション
SoCRATES: ドメインおよび社会認知の多様性にわたる能動的LLM仲介の信頼性の高い自動評価に向けて
MMAE: 大規模マルチタスクオーディオ編集ベンチマーク
あなたのアンエンベディング行列は実はテキスト埋め込みのための特徴レンズである
ChordEdit:画像編集のためのワンステップ・低エネルギー輸送
NitroGen: 汎用ゲームエージェントのためのオープンな基盤モデル
D4RTごとに動的シーンを効率的に再構築する
Continual Learning Bench:現実世界の状態保持環境における最先端AIシステムの評価
MEMORY CACHING: Growing Memoryを持つRNN
RobotValues: 人間の価値観が衝突する際の家庭用ロボットの評価
VideoKR: 知識・推論集中型の動画理解へ向けて
AdaPlanBench: 世界制約とユーザー制約下における大規模言語モデル Agents の適応的計画の評価
TIDE: テンプレート誘導型反復による複数問題の先制的発見
ArcANE: ロールプレイ言語Agentsは適切なタイミングでキャラクターを維持しているか?
Code2LoRA: ソフトウェア進化におけるコード言語モデル用のハイパーネットワーク生成アダプタ
自己蒸留型方策勾配
LatentSkill: コンテキスト内テキストスキルから重み内潜在スキルへ LLM Agents 向け
CoVEBench: 動画編集モデルは複雑な指示を処理できるか?
動画世界モデルのための潜在空間記憶
オンポリシー蒸留の幾何学について
SWE-Explore: コーディング agents がリポジトリを探索する方法のベンチマーク
VoxCPM2技術報告書
LongCat-Video-Avatar 1.5 技術報告
ChartNet: 堅牢なチャート理解のための百万規模・高品質マルチモーダルデータセット
ACL-Verbatim: 研究におけるハルシネーションフリーの質問応答
静的対話を超える:現実的、多様で進化し続ける長期記憶のためのベンチマーク
ソフトウェアエンジニアリングの終焉:AIエージェントがどのようにソフトウェアのパラダイムを根本から再構築しているか
なぜ大規模なモデルはより多くのことを学習するのか:容量、干渉、および稀なタスク保持の影響
ツールが失敗したとき:LLM Agentsにおける動的再計画と異常回復のベンチマーク
分解された視覚プロキシを用いた直接3D認識物体挿入
AnchorWorld: 視点に基づく進化カスタマイズを用いた具身自己中心世界シミュレーション
SoCRATES: ドメインおよび社会認知の多様性にわたる能動的LLM仲介の信頼性の高い自動評価に向けて
MMAE: 大規模マルチタスクオーディオ編集ベンチマーク
あなたのアンエンベディング行列は実はテキスト埋め込みのための特徴レンズである
ChordEdit:画像編集のためのワンステップ・低エネルギー輸送
NitroGen: 汎用ゲームエージェントのためのオープンな基盤モデル
D4RTごとに動的シーンを効率的に再構築する
Continual Learning Bench:現実世界の状態保持環境における最先端AIシステムの評価
MEMORY CACHING: Growing Memoryを持つRNN
RobotValues: 人間の価値観が衝突する際の家庭用ロボットの評価
VideoKR: 知識・推論集中型の動画理解へ向けて
AdaPlanBench: 世界制約とユーザー制約下における大規模言語モデル Agents の適応的計画の評価
TIDE: テンプレート誘導型反復による複数問題の先制的発見
ArcANE: ロールプレイ言語Agentsは適切なタイミングでキャラクターを維持しているか?
Code2LoRA: ソフトウェア進化におけるコード言語モデル用のハイパーネットワーク生成アダプタ
自己蒸留型方策勾配