HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
MobileForge: アノテーション不要のモバイルGUI Agentsへの階層フィードバック誘導ポリシー最適化による適応
NatureBench: Coding AgentsはNature系論文の公開済みSOTAに匹敵できるか?
























MobileForge: アノテーション不要のモバイルGUI Agentsへの階層フィードバック誘導ポリシー最適化による適応
NatureBench: Coding AgentsはNature系論文の公開済みSOTAに匹敵できるか?
Qwen-AgentWorld: 汎用Agents向けの言語世界モデル
ユニバーサル音声強化のための学習目標、アーキテクチャ、およびデータ品質の再考
学習された密度制御を備えた生成型3Dガウス分布
TADA: テキスト・音響二重整合性を介した音声モデリングのための生成フレームワーク
孤立した単語を超えて:手書きテキスト行生成のためのDiffusion Brush
gsplat: ガウシアンスプッティングのためのオープンソースライブラリ
OmniVideo-100K: 構造化スクリプトと証拠連鎖を通じた映像推理のためのデータセット
OPEN-SWE-TRACES: ソフトウェアエンジニアリングエージェントのための双モード多言語ディストillationの進展
言語モデルの推論におけるリセットを用いた信用配分
無制限のOCR処理:ワンショット長文脈解析の時代へようこそ
PlanBench-XL: 大規模ツールエコシステムにおけるLLMツール使用Agentsの長期計画の評価
OpenRath: Agent システムのためのセッション中心実行時状態
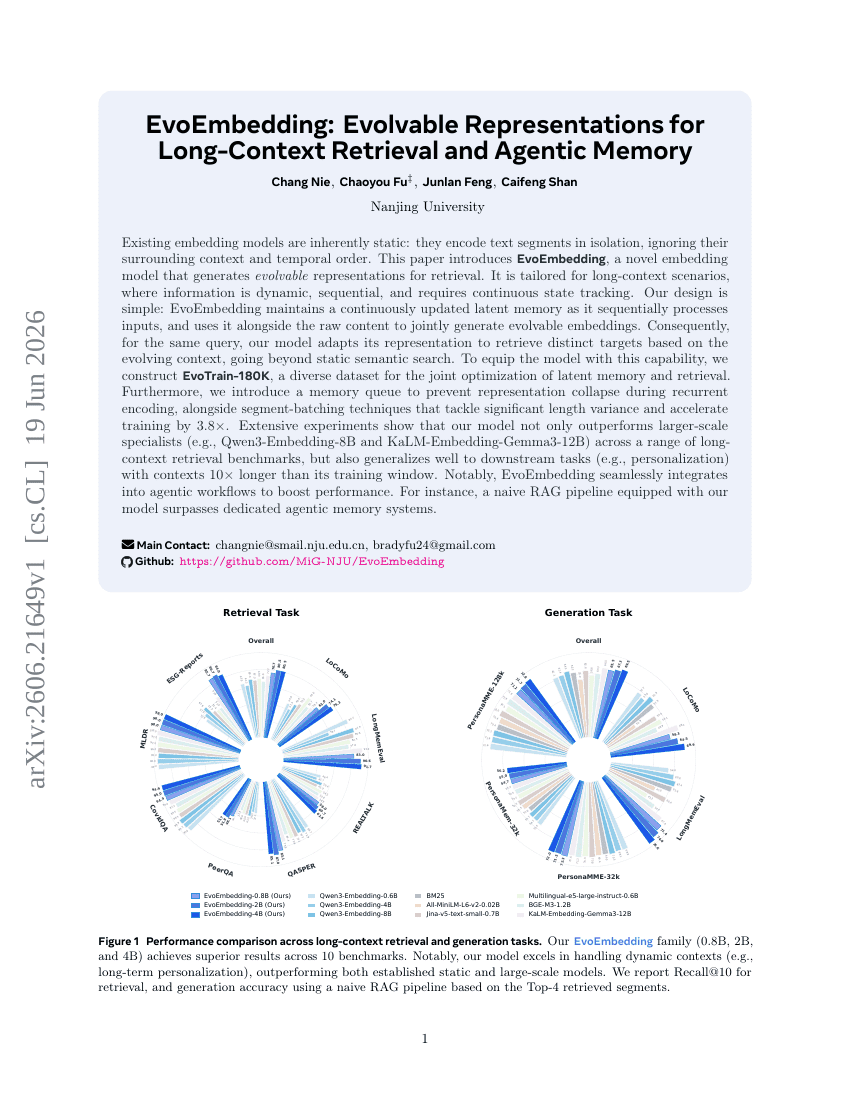
EvoEmbedding: 長文脈検索およびエージェントメモリのための進化可能な表現
自分の間違いから学ぶ:自己蒸留のための学習可能な微小反射軌跡の構築
世界行動モデル:総説
KaLM-Reranker-V1: 圧縮文書の再ランク付けのための高速だが後期相互作用ではない
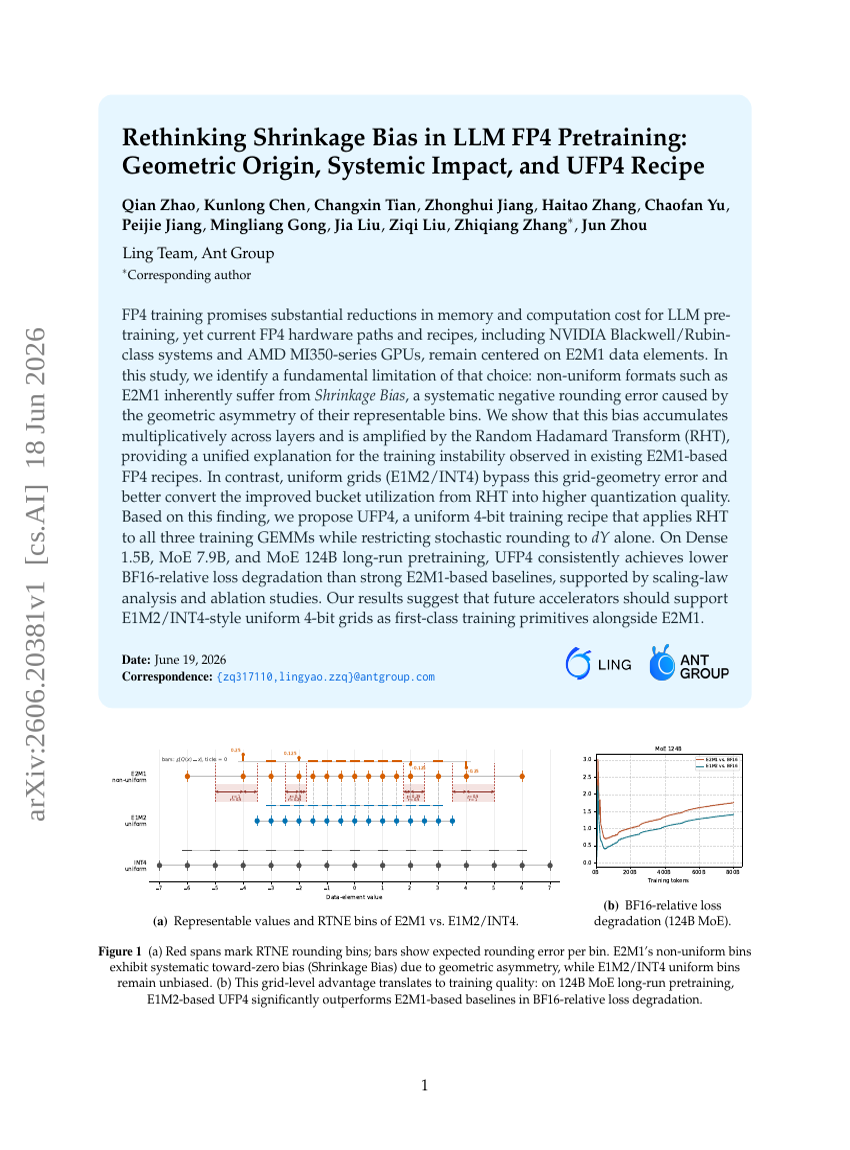
LLMのFP4事前学習における収束バイアスの再考:幾何学的起源、系統的影響、およびUFP4レシピ
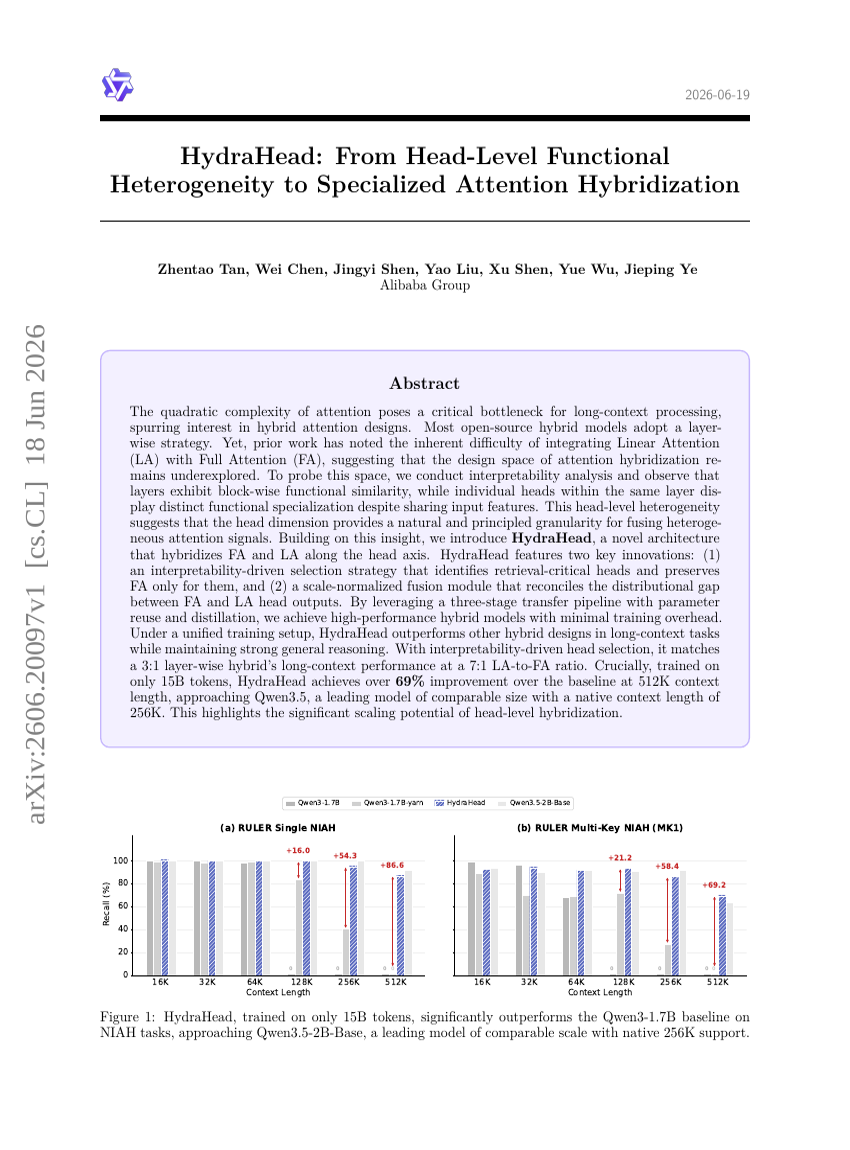
HydraHead: ヘッドレベルの機能的異方性から専門化された注意機構のハイブリッド化へ
3DCodeBench: コードによるエージェント型手続的3Dモデリングの評価
RadImageNet-VQA: 放射線学的視覚質問応答のための大規模なCTおよびMRIデータセット
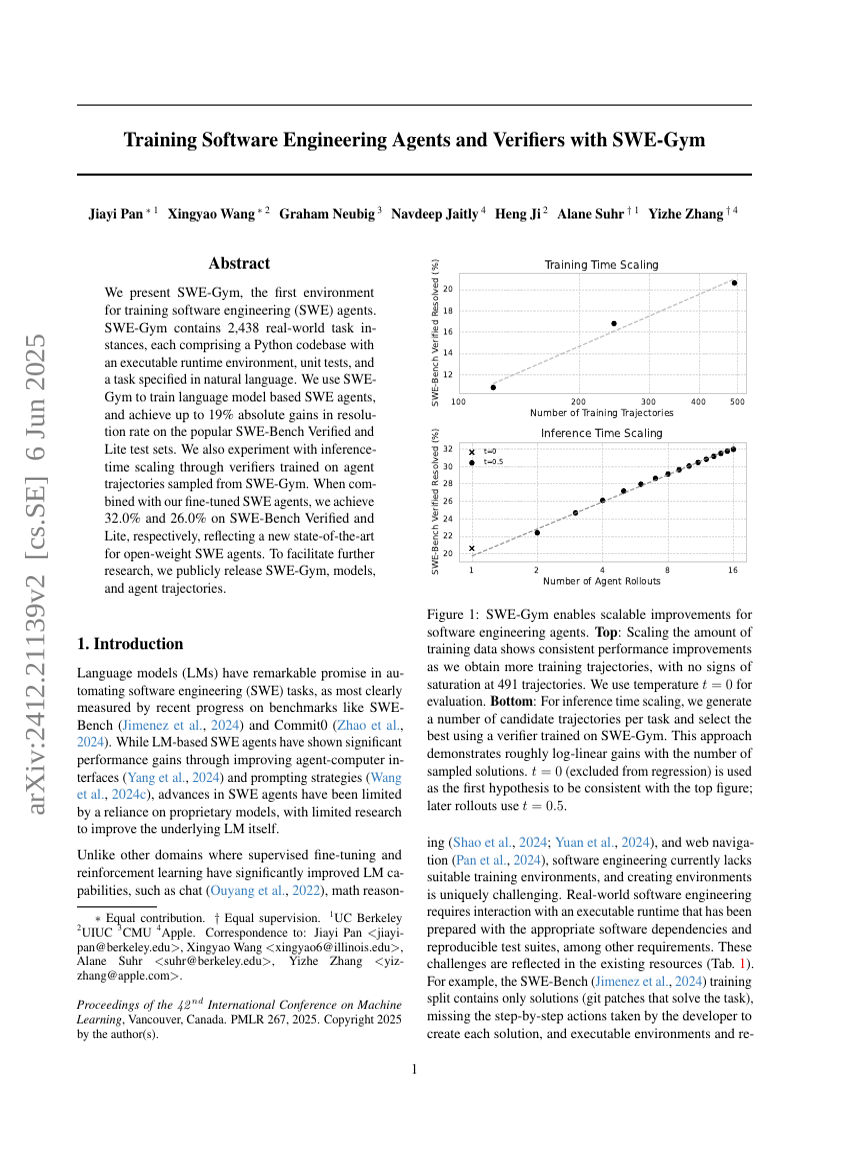
SWE-Gymを用いたソフトウェアエンジニアリングエージェントおよびベンチマークのトレーニング
MAKIEVAL: 大規模言語モデルの文化的認識評価のための多言語・自動的なWiKIdataベースのフレームワーク
GeneralVLA-2: 幾何構造認識型再構築と制御されたメモリによるロボット計画
多ターン内省的マスキングはマスク拡散モデルにおける推論を引き出す
BrainG3N: 制御可能な3D脳MRI生成のための二重目的トークナイザー
GateMem: 複数主体共有メモリAgentsにおけるメモリガバナンスのベンチマーク
MemSlides:マルチターンローカル修正を用いたパーソナライズされたスライド生成のための階層型メモリ駆動型Agentフレームワーク
PerceptionDLM: マルチモーダル拡散言語モデルを用いた並列領域知覚
一般ゲームプレイのためのコード世界モデル
静的リーダーボードを超えて:LLM agentsの評価における予測妥当性
Qwen-AgentWorld: 汎用Agents向けの言語世界モデル
ユニバーサル音声強化のための学習目標、アーキテクチャ、およびデータ品質の再考
学習された密度制御を備えた生成型3Dガウス分布
TADA: テキスト・音響二重整合性を介した音声モデリングのための生成フレームワーク
孤立した単語を超えて:手書きテキスト行生成のためのDiffusion Brush
gsplat: ガウシアンスプッティングのためのオープンソースライブラリ
OmniVideo-100K: 構造化スクリプトと証拠連鎖を通じた映像推理のためのデータセット
OPEN-SWE-TRACES: ソフトウェアエンジニアリングエージェントのための双モード多言語ディストillationの進展
言語モデルの推論におけるリセットを用いた信用配分
無制限のOCR処理:ワンショット長文脈解析の時代へようこそ
PlanBench-XL: 大規模ツールエコシステムにおけるLLMツール使用Agentsの長期計画の評価
OpenRath: Agent システムのためのセッション中心実行時状態
EvoEmbedding: 長文脈検索およびエージェントメモリのための進化可能な表現
自分の間違いから学ぶ:自己蒸留のための学習可能な微小反射軌跡の構築
世界行動モデル:総説
KaLM-Reranker-V1: 圧縮文書の再ランク付けのための高速だが後期相互作用ではない
LLMのFP4事前学習における収束バイアスの再考:幾何学的起源、系統的影響、およびUFP4レシピ
HydraHead: ヘッドレベルの機能的異方性から専門化された注意機構のハイブリッド化へ
3DCodeBench: コードによるエージェント型手続的3Dモデリングの評価
RadImageNet-VQA: 放射線学的視覚質問応答のための大規模なCTおよびMRIデータセット
SWE-Gymを用いたソフトウェアエンジニアリングエージェントおよびベンチマークのトレーニング
MAKIEVAL: 大規模言語モデルの文化的認識評価のための多言語・自動的なWiKIdataベースのフレームワーク
GeneralVLA-2: 幾何構造認識型再構築と制御されたメモリによるロボット計画
多ターン内省的マスキングはマスク拡散モデルにおける推論を引き出す
BrainG3N: 制御可能な3D脳MRI生成のための二重目的トークナイザー
GateMem: 複数主体共有メモリAgentsにおけるメモリガバナンスのベンチマーク
MemSlides:マルチターンローカル修正を用いたパーソナライズされたスライド生成のための階層型メモリ駆動型Agentフレームワーク
PerceptionDLM: マルチモーダル拡散言語モデルを用いた並列領域知覚
一般ゲームプレイのためのコード世界モデル
静的リーダーボードを超えて:LLM agentsの評価における予測妥当性