HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

見解:AI/MLによるディープフェイク研究はAI生成の非合意型性的画像(AIG-NCII)と整合していない

Grokkingを理解する:リッジ回帰における証明可能なGrokking
























見解:AI/MLによるディープフェイク研究はAI生成の非合意型性的画像(AIG-NCII)と整合していない
Grokkingを理解する:リッジ回帰における証明可能なGrokking
拡散モデルの一貫性に関するランダム行列理論からの視点
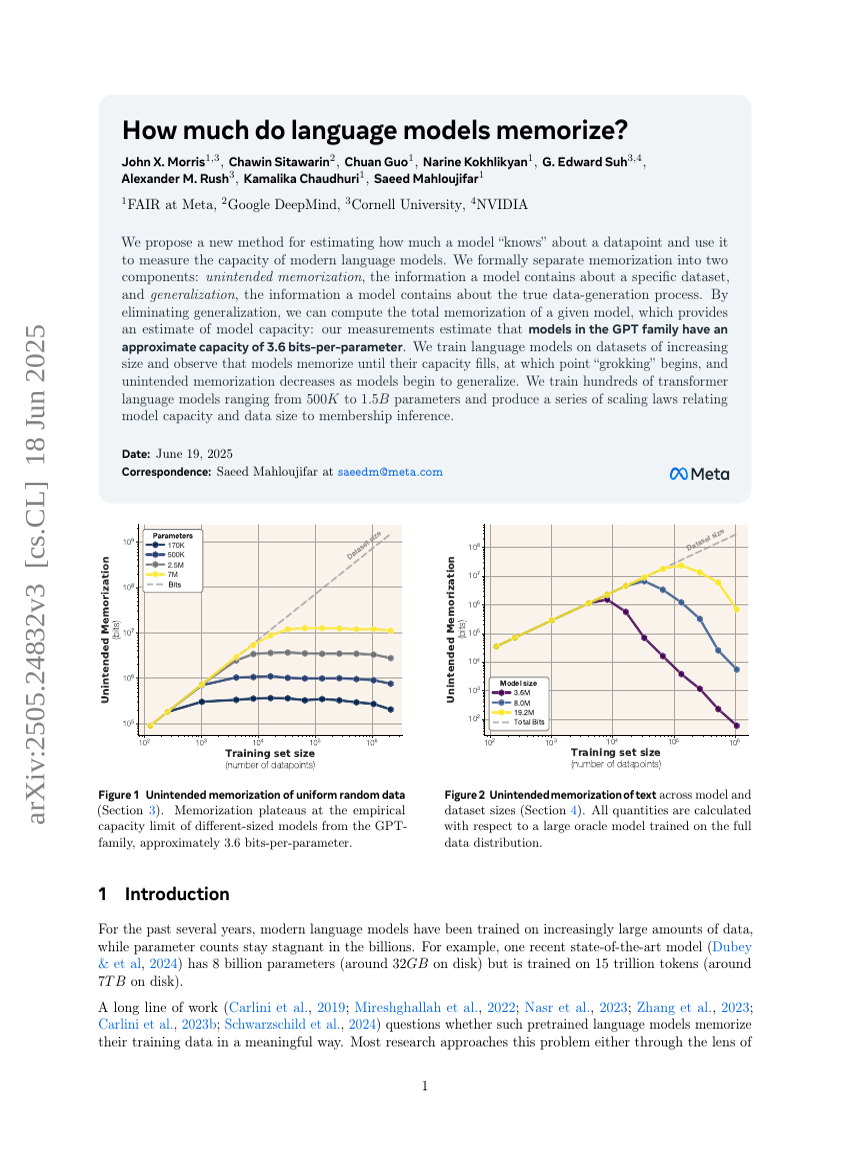
言語モデルはどの程度記憶しているのか?
難読化アトラス:欺瞞プローブを用いたRLVRにおいて正直さが現れる場所の地図化
立場表明:アライメントコミュニティは意図せず検閲ツールキットを構築している
拡散モデルと対数凹分布に対する高精度サンプリング
AgenticDataBench: データエージェントのための包括的ベンチマーク
マルチレゾリューションフローマッチング: 段階的サンプリングによる訓練不要な拡散加速
ハイブリッドアテンションモデルへのモーフィング
EvoPolicyGym: インタラクティブ環境における自律的方針進化の評価
AgenticSTS:長期間タスク向けLLMエージェントのための制約付きメモリテストベッド
Program-as-Weights: ファジィ関数のためのプログラミングパラダイム
MatAnyone 2: 学習型品質評価器によるビデオマッティングのスケーリング
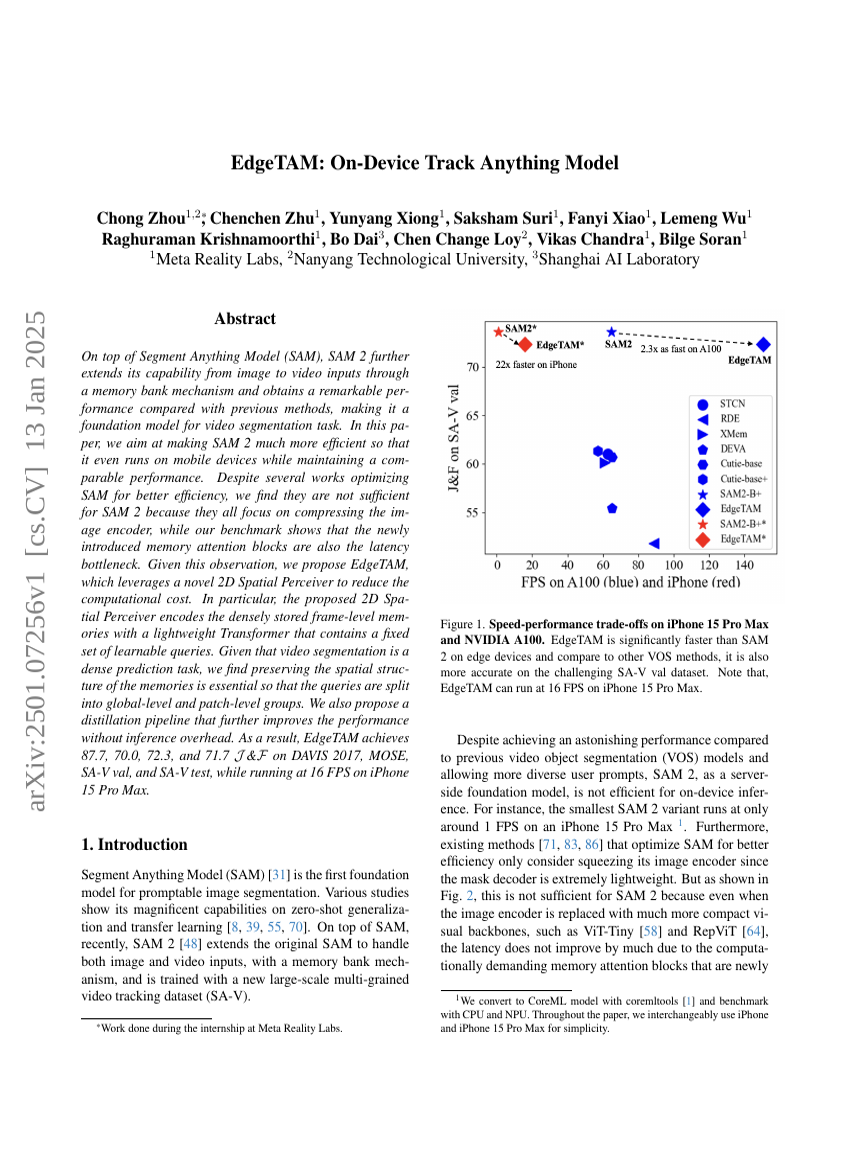
EdgeTAM: オンデバイスTrack Anything Model
PixelRefer: 任意の粒度での時空間オブジェクト参照のための統一フレームワーク
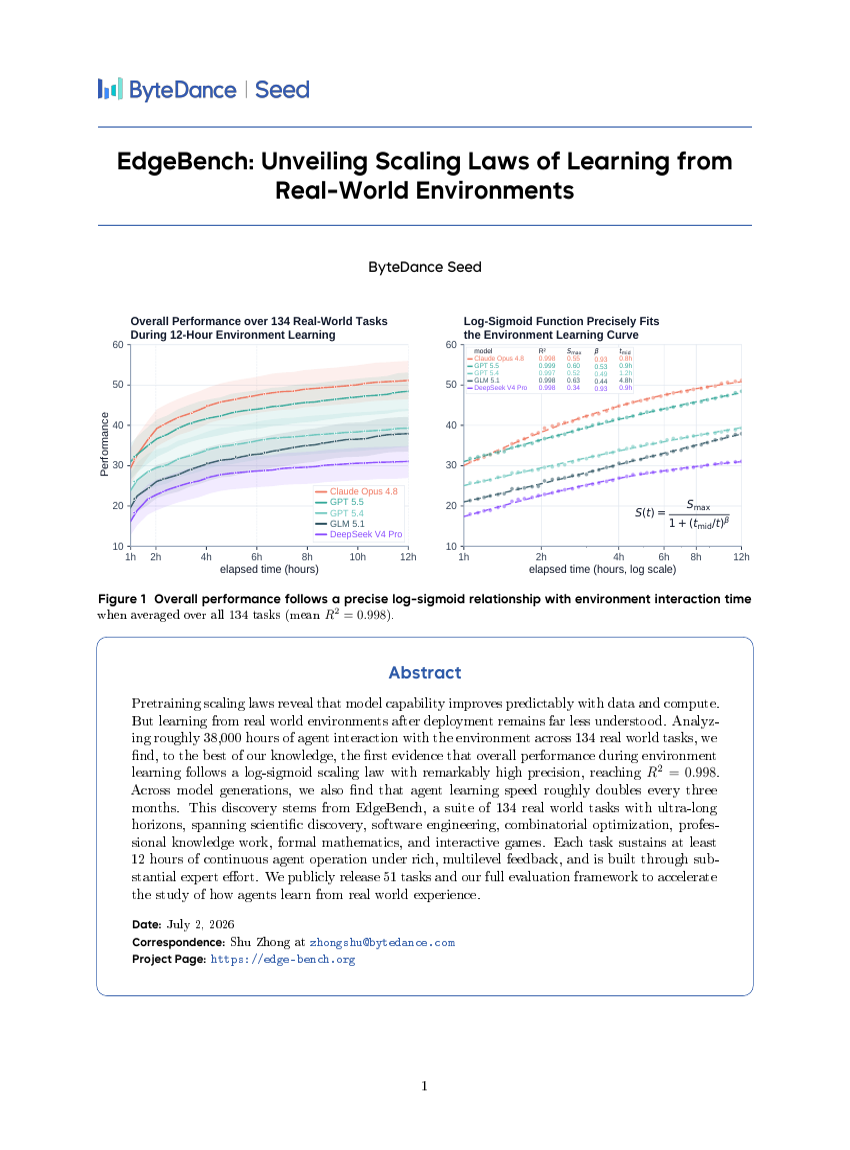
EdgeBench: 実世界環境からの学習におけるスケーリング則の解明
ASPIRE: ロボティクスのためのエージェント型スキル発見
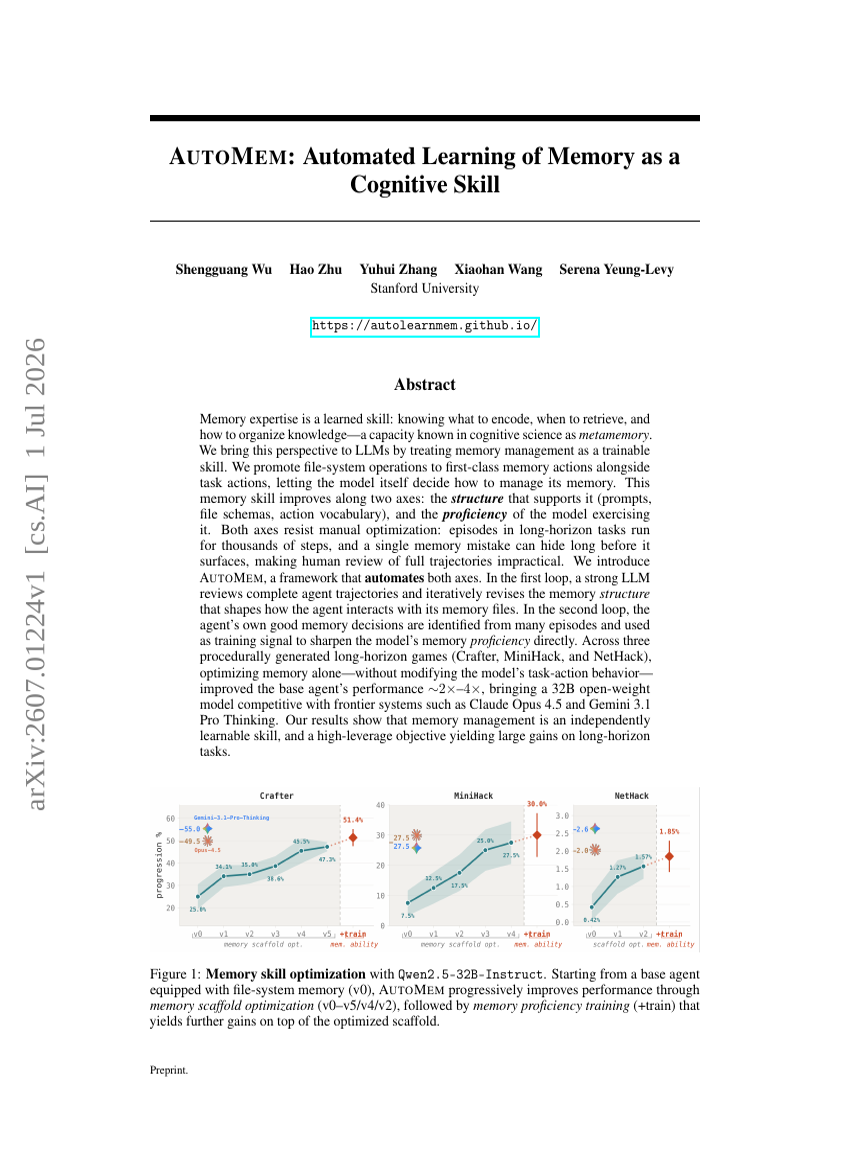
AUTOMEM: 認知的スキルとしての記憶の自動学習
デコードワークの法則:圧縮幾何データに対するマージン支配型・証明可能な厳密空間結合
組合せ最適化問題に対するニューラル証明書価格付け
自律型実験室オーケストレーターのための最適資源活用
TERA: 統一テイラーモデルによる到達可能性解析フレームワーク
Perceive-to-Reason: 細粒度視覚推論のための知覚と推論の分離
効率的なIRパイプライン実験のためのトライベース実験計画
LLM訓練における学習率スケーリングの非線形性について
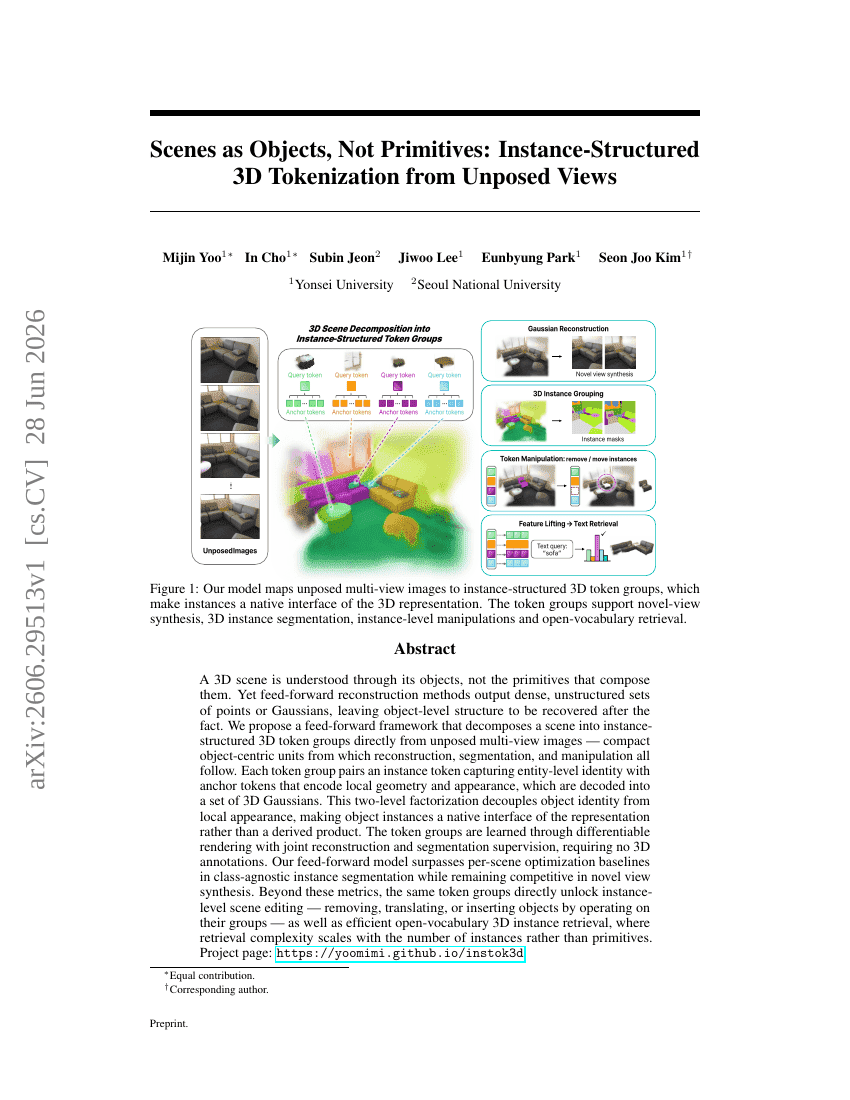
プリミティブではなくオブジェクトとしてのシーン:未知視点画像からのインスタンス構造化3Dトークン化
BlockPilot: 拡散型投機的デコーディングのためのインスタンス適応型ポリシー学習
DOPD: デュアル・オン・ポリシー蒸留
Dockerless: コーディングエージェントのための環境不要プログラム検証器
Orca: The World is in Your Mind
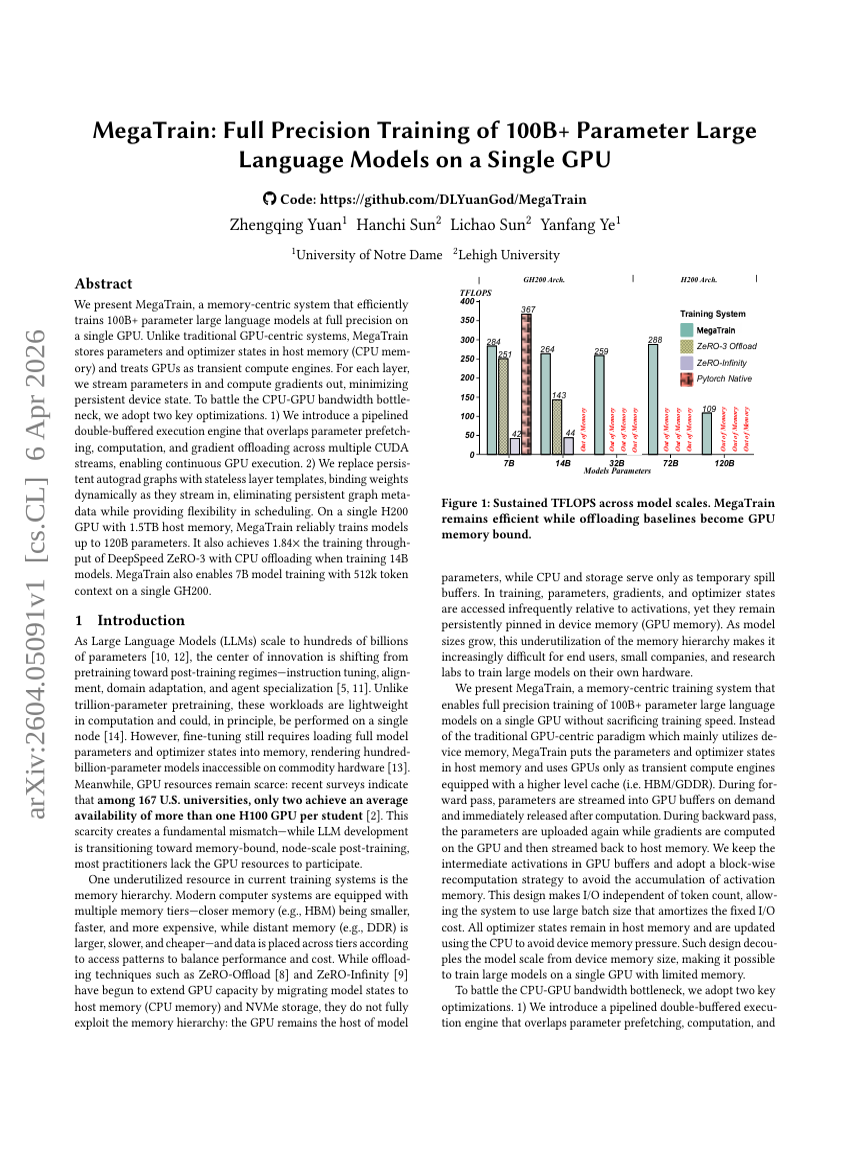
MegaTrain: 単一GPU上での100B+パラメータ大規模言語モデルの完全精度学習
拡散モデルの一貫性に関するランダム行列理論からの視点
言語モデルはどの程度記憶しているのか?
難読化アトラス:欺瞞プローブを用いたRLVRにおいて正直さが現れる場所の地図化
立場表明:アライメントコミュニティは意図せず検閲ツールキットを構築している
拡散モデルと対数凹分布に対する高精度サンプリング
AgenticDataBench: データエージェントのための包括的ベンチマーク
マルチレゾリューションフローマッチング: 段階的サンプリングによる訓練不要な拡散加速
ハイブリッドアテンションモデルへのモーフィング
EvoPolicyGym: インタラクティブ環境における自律的方針進化の評価
AgenticSTS:長期間タスク向けLLMエージェントのための制約付きメモリテストベッド
Program-as-Weights: ファジィ関数のためのプログラミングパラダイム
MatAnyone 2: 学習型品質評価器によるビデオマッティングのスケーリング
EdgeTAM: オンデバイスTrack Anything Model
PixelRefer: 任意の粒度での時空間オブジェクト参照のための統一フレームワーク
EdgeBench: 実世界環境からの学習におけるスケーリング則の解明
ASPIRE: ロボティクスのためのエージェント型スキル発見
AUTOMEM: 認知的スキルとしての記憶の自動学習
デコードワークの法則:圧縮幾何データに対するマージン支配型・証明可能な厳密空間結合
組合せ最適化問題に対するニューラル証明書価格付け
自律型実験室オーケストレーターのための最適資源活用
TERA: 統一テイラーモデルによる到達可能性解析フレームワーク
Perceive-to-Reason: 細粒度視覚推論のための知覚と推論の分離
効率的なIRパイプライン実験のためのトライベース実験計画
LLM訓練における学習率スケーリングの非線形性について
プリミティブではなくオブジェクトとしてのシーン:未知視点画像からのインスタンス構造化3Dトークン化
BlockPilot: 拡散型投機的デコーディングのためのインスタンス適応型ポリシー学習
DOPD: デュアル・オン・ポリシー蒸留
Dockerless: コーディングエージェントのための環境不要プログラム検証器
Orca: The World is in Your Mind
MegaTrain: 単一GPU上での100B+パラメータ大規模言語モデルの完全精度学習