Command Palette
Search for a command to run...
Qwen-AgentWorld: 汎用Agents向けの言語世界モデル
Qwen-AgentWorld: 汎用Agents向けの言語世界モデル
概要
世界モデルは、現在の観測と行動に基づいて環境の動態を予測し、推論と計画のための中核的な認知機構として機能する。本研究では、言語モデルに基づく世界モデル構築が、一般化されたagentsの限界をさらにどのように押し広げ得るかを調査する。(i)まず、agents環境シミュレーションのための基盤モデルの構築に焦点を当てる。我々は、Qwen-AgentWorld-35B-A3BおよびQwen-AgentWorld-397B-A17Bを紹介する。これらは、長いchain-of-thought推論を通じて7つのドメインにわたるagents環境をシミュレーション可能な、初の言語世界モデルである。実環境における7つのドメインの1,000万以上の環境相互作用軌跡を活用し、Qwen-AgentWorldを3段階のトレーニングパイプラインによって開発する。CPTは状態遷移動態と拡張された専門コーパスから汎用的な世界モデル構築能力を注入し、SFTは次状態予測推論を活性化し、RLはハイブリッドなルーブリックおよびルール報酬を備えた専用フレームワークを通じてシミュレーションの忠実度を高める。言語世界モデルを評価するために、我々はAgentWorldBenchを提示する。これは、9つの既存ベンチマークにおいて5つの最先端モデルが実環境で相互作用したデータから構築された包括的なベンチマークである。実証結果は、Qwen-AgentWorldが既存の最先端モデルを大幅に上回ることを示している。(ii)基盤モデルを超えて、我々はさらに、世界モデル構築が一般化されたagentsをどのように強化するかという2つの補完的なパラダイムを調査する。第一に、独立した環境シミュレータとして、Qwen-AgentWorldはagents RLのために数千の実環境の拡張可能かつ制御可能なシミュレーションをサポートし、単独の実環境トレーニングのみでは達成できないほどの性能向上をもたらす。第二に、統合されたagent基盤モデルとして、世界モデルトレーニングは、7つのagentsベンチマーク全体で下流性能を向上させる、非常に効果的なウォームアップとして機能する。コード: https://github.com/QwenLM/Qwen-AgentWorld
One-sentence Summary
The Owen Team introduces Qwen-AgentWorld-35B-A3B and Qwen-AgentWorld-397B-A17B, the first language world models that simulate seven real-world agentic environment domains via long chain-of-thought reasoning, trained on more than 10 million trajectories through a three-stage pipeline of CPT, SFT, and RL with hybrid rubric-and-rule rewards, achieving significant gains over existing frontier models on AgentWorldBench, a comprehensive five-dimension rubric-based benchmark built from five frontier models' interactions on nine established benchmarks including Tool Decathlon, Terminal-Bench 1.0 & 2.0, and OSWorld-Verified, and they enable scalable decoupled simulation for agentic RL that surpasses real-environment training alone and provide a unified foundation model warm-up that improves downstream performance across seven agentic benchmarks.
Key Contributions
- The paper introduces Qwen-AgentWorld-35B-A3B and Qwen-AgentWorld-397B-A17B, the first language world models that simulate agentic environments across seven domains via long chain-of-thought reasoning, trained on over 10 million real-world interaction trajectories using a three-stage pipeline combining continual pretraining, supervised fine-tuning, and reinforcement learning with hybrid rubric-and-rule rewards.
- This work presents AgentWorldBench, a comprehensive benchmark built from interactions of five frontier models across nine established testbeds that evaluates world-modeling quality through ground-truth-grounded rubric judging along five dimensions.
- The study demonstrates that using Qwen-AgentWorld as a decoupled environment simulator enables scalable agentic reinforcement learning with gains surpassing real-environment training alone, and that world-model training serves as an effective warm-up that boosts downstream performance as a unified agent foundation model on seven agentic benchmarks.
Introduction
Training autonomous agents typically requires massive interaction data, but live environments are slow, expensive, or inaccessible. Language world models that simulate environment responses can scale up cheaper, faster training, yet prior approaches mostly fine-tune general-purpose LLMs on agent trajectories. These simulate one or few domains, often with unreliable fidelity and limited controllability. The authors introduce Qwen-AgentWorld, a native language world model pre-trained from scratch on trajectories spanning seven agent domains and refined through a three-stage pipeline of continual pre-training, supervised fine-tuning, and reinforcement learning. This design yields a single foundation model that delivers high-fidelity, controllable simulation. They further show two complementary benefits: decoupling the world model from the agent enables simulated training (Sim RL) that matches or outperforms real-environment training, while pre-training the agent with the world model significantly boosts its downstream performance.
Dataset
Training data for the language world model
-
Sources and composition
The authors collect environment trajectories from three complementary pipelines, covering seven domains: software engineering (SWE), terminal, search, MCP tool use, Android, browser, and desktop OS.- Dedicated agent infrastructure – Containerized sandboxes, MCP servers, persistent shell sessions, and GUI environments (Android VMs, browser, desktop OS) that represent observations as accessibility trees or view hierarchies. This continuously running pipeline automatically synthesises task queries and executes them end-to-end, providing controllable, reproducible interaction data.
- Open interaction traces – Public terminal session recordings, open-source agent tool-call logs, and execution traces. A multi-agent cleaning pipeline handles fetching, denoising, segmentation, semantic alignment, and quality scoring; only sequences that pass all stages enter the pool, capturing rare shell workflows and error modes.
- In‑house agentic trajectories – Agentic data accumulated during internal foundation‑model SFT development, converted to the unified trajectory format.
Data pools for the three training stages are kept strictly disjoint:
- CPT uses dedicated‑infrastructure traces, open traces, and specialised domain‑knowledge corpora.
- SFT and RL draw exclusively from internal, in‑house trajectories.
-
Key details for each source and filtering rules
- Trajectory‑level filters: Drop sequences with fewer than two turns; discard MCP/SWE trajectories that invoke tools not in the declared action space; exclude GUI trajectories affected by environment failures (missing state files, CAPTCHA, HTTP errors) that break the causal action‑observation chain.
- Turn‑level filters: Strip empty‑action turns (pauses or narration).
- Retry‑cycle skipping – Collapse “garbage output → error → retry” loops while preserving the environment state, so the next valid turn inherits the correct history.
- No‑change turn filtering (GUI domains) – Remove turns where pre‑ and post‑action states are identical (often due to latency), preventing the model from learning to blindly copy the previous observation.
- Turn expansion – Every trajectory is expanded into turn‑level prediction samples: for a trajectory with T turns, any turn t can be a target, with the preceding history and the current action as input. For the final training split, the authors randomly sample one turn per trajectory to diversify objectives.
-
System prompt construction and metadata
Each sample follows the unified schema: system prompt (task description, action space, optional initial state, demonstrations, optional simulation instruction) plus alternating action/observation turns.- Static components (action space, demonstrations) are shared across trajectories except for MCP and SWE, where action spaces are per‑trajectory because tools differ across server instances or repos.
- Dynamic components (initial state, simulation instruction) are filled per trajectory. For GUIs the initial state is intentionally diverse; for search and terminal, a subset of data carries output‑controlling simulation instructions to enable controllable simulation.
- Prompt templates are not hand‑crafted. An automated research loop (AutoResearch) iteratively improves candidates: an optimizer agent analyses failures on held‑out trajectories, revises the prompt, and re‑evaluates prediction accuracy against real environment responses. Twelve parallel runs produce templates v0‑v11, which are assigned to disjoint training pools (RL uses v0, CPT uses v1, SFT randomly samples from v2‑v11 per sample) for prompt‑format diversity.
-
How the paper uses the data
All data is formatted as input‑target pairs where the model predicts the next environment observation given the full prior interaction and the agent’s current action.- CPT consumes the broad, multi‑source data to warm‑start the world model.
- SFT fine‑tunes on the in‑house agentic trajectories with a mixture of prompt templates v2‑v11.
- RL further refines the model using on‑policy rollouts from internal trajectories and template v0; because RL can amplify artefacts, the authors applied the most thorough filtering to this pool.
-
Evaluation: AgentWorldBench
For benchmarking, the authors construct 2,170 evaluation samples from frontier‑model trajectories on established agent benchmarks across all seven domains, ensuring real ground‑truth observations and out‑of‑distribution data partitions.- Turn sampling: Text‑domain trajectories keep the first turn, the last turn, and three uniformly sampled intermediate turns (five evaluation turns per trajectory). GUI domains selectively sample more challenging turns, then a 50% random subset is retained.
- Statistics: SWE (21.8%), Search (21.1%), Terminal (16.3%), MCP (13.2%), each GUI domain 9.2%. Average context length ranges from ~12.9k tokens (Terminal) to ~59.3k tokens (MCP, due to full tool schemas in the system prompt).
Method
The authors introduceQwen-AgentWorld, a unified native language world model designed to simulate agentic environments across seven distinct domains: MCP Servers, Search Engine, IDE, Terminal/CLI, Android System, Web Browser, and Operating System. By unifying these domains under a shared textual representation, the model enables cross-domain generalization for language world modeling.
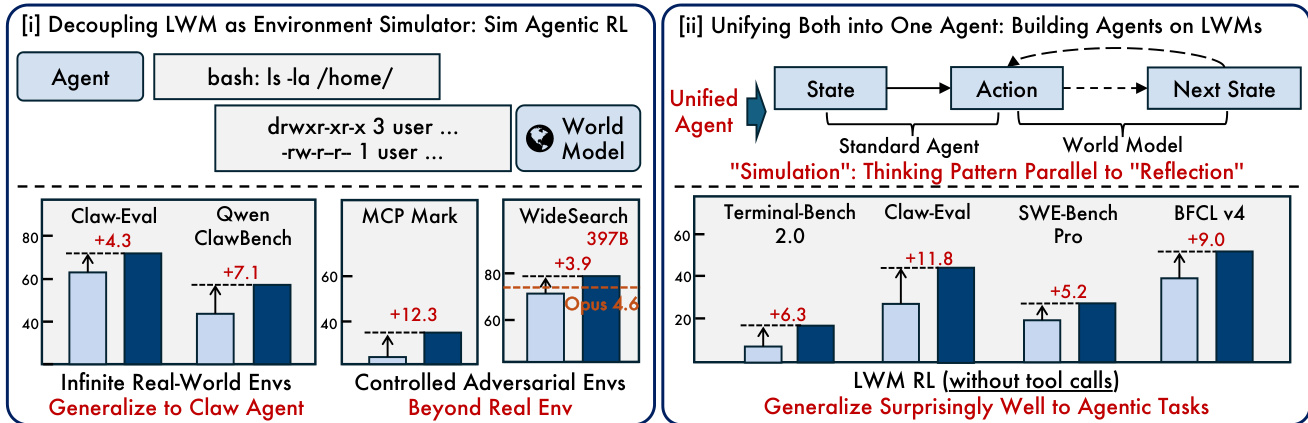
Beyond serving as a foundation model, the authors investigate two complementary paradigms for applying world modeling to enhance language agents. In the "Decouple" strategy, the world model acts as an environment simulator for scalable agentic RL (Sim RL). This allows agent training to scale to domains and conditions beyond what real environments can provide, such as generating controlled adversarial environments. In the "Unify" strategy, the world model serves as the agent foundation model itself. Here, world-model training acts as a highly effective warm-up that improves downstream performance across agentic tasks, generalizing surprisingly well to tasks without tool calls.
Training Pipeline
Qwen-AgentWorld is trained end-to-end with environment modeling as the explicit objective from continual pre-training onward. The authors adopt a three-stage pipeline summarized as "CPT injects, SFT activates, RL sharpens".

Stage 1: Continual Pre-Training (CPT) The objective of CPT is to inject environment world knowledge and broad factual knowledge into the model. The training data comprises environment interaction trajectories and specialized-domain world knowledge corpora spanning professional fields like industrial control, cybersecurity, and medicine. The model is trained under the standard next-token prediction objective. Multi-turn environment trajectories are framed as world-modeling tasks where the system prompt defines the simulation context, user turns carry the agent's actions, and assistant turns carry the environment's responses. This maps the language-modeling objective directly onto p(ot+1∣o≤t,a<t).
To address the issue of low-quality gradients from boilerplate turns (such as tools simply echoing their input), the authors introduce Turn-Level Information-Theoretic Loss Masking. They compute four statistics per (action, observation) pair: Overlap (OL), Novelty (Nov), Jaccard (Jac), and length ratio (R). These statistics categorize turns into seven semantic categories to identify those carrying genuine world knowledge. Masked turns are excluded from loss computation but retained as context for subsequent turns. This effectively decouples learning the next state from learning the next token.
Stage 2: Supervised Fine-Tuning (SFT) While CPT teaches the model implicit state transitions through next-token prediction, SFT explicitly activates next-state prediction as a reasoning pattern. The authors shift from non-thinking trajectories to thinking trajectories that contain explicit reasoning chains. This stage employs a 256k-token context window to accommodate long multi-step trajectories.
The data curation process involves prompt template diversification and rejection sampling. Each sample's default system prompt is replaced by one sampled from 10 template variants to improve generalization. For each query, multiple rollouts are generated from a general-purpose reasoning model and scored by an independent judge. The highest-quality trajectory is selected via rejection sampling, ensuring the model learns robust state-transition reasoning that reduces hallucinations and improves consistency.
Stage 3: Reinforcement Learning (RL) The final stage sharpens simulation fidelity using hybrid rubric-and-rule rewards. The reward design combines two complementary signals:
- Five-Dimensional Rubric (LLM Judge): Predicted observations are scored by an LLM judge on five dimensions: Format, Factuality, Consistency, Realism, and Quality. Each dimension is scored on a 1-5 scale, and the total reward is the mean multiplied by 5. This addresses open-ended evaluation needs where exact matching is impossible.
- Rule-Based Verifier: A subset of the data carries executable verifier code that produces a binary 0/1 correctness signal, scaled to align with the rubric range. This acts as an objective anchor to mitigate reward hacking induced by open-ended rewards.
The signals are combined at a 9:1 ratio. A multi-strategy JSON parser ensures that only the predicted observation reaches the judge, preventing self-praise in the reasoning from affecting the score.
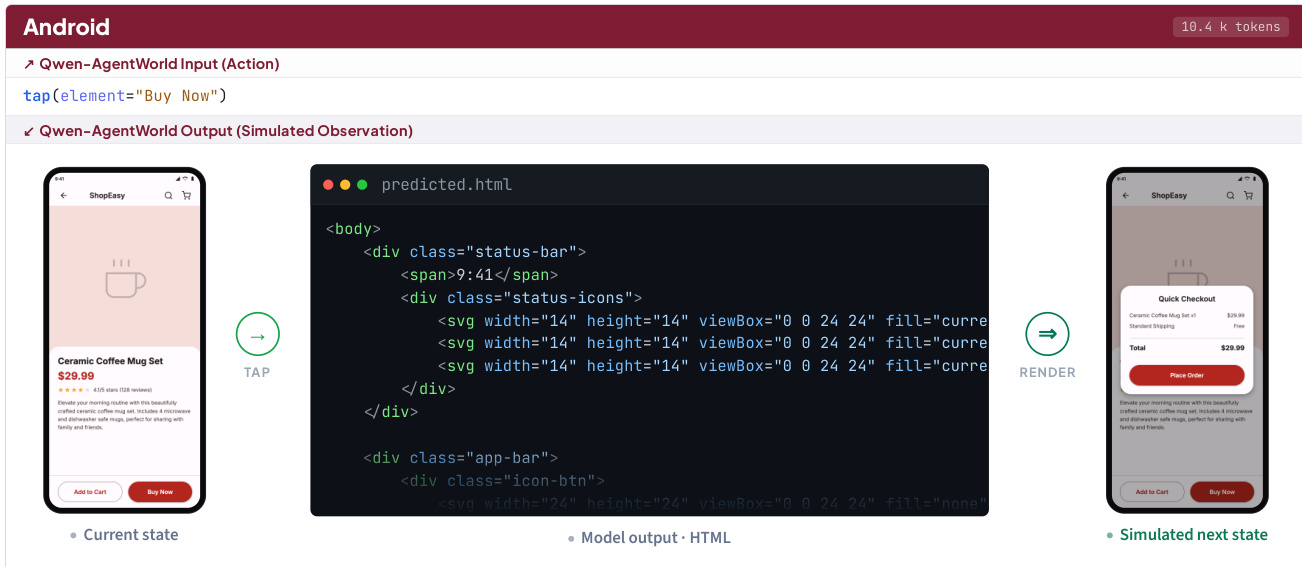
To illustrate the simulation capability in the Android domain, the model takes an action such as tap(element="Buy Now") and predicts the next state. The model outputs an HTML representation of the UI structure, which captures the state transition. This output is then rendered to show the simulated next state, such as a "Quick Checkout" modal appearing over the original product page.
The system prompt structure for the Terminal domain exemplifies how the model is conditioned for these tasks. It includes static components shared across trajectories, such as the Task Description defining the role as a precise terminal state simulator, and the Action Space defining user actions as JSON arrays. Dynamic components, such as the Initial State (container snapshot) and Simulation Instruction (specific constraints like disk space limits), are injected per trajectory. This structure ensures the model understands the specific constraints and context of the environment it is simulating.

Experiment
Qwen-AgentWorld, a native language world model trained through a three-stage pipeline, is evaluated on AgentWorldBench across seven domains using an open-ended rubric that compares predictions against ground-truth observations. The model achieves the highest overall simulation fidelity, and in a decoupled simulator role, its controllability enables targeted perturbations and fictional-world training that surpass real-environment RL on search and tool-use benchmarks. In a unified agent architecture, single-turn world-model warm-up transfers to multi-turn, tool-calling tasks across diverse benchmarks, with analysis attributing gains to the agent’s learned ability to internally predict environment responses before acting, establishing language world modeling as a foundational axis for scaling general agents.
The authors evaluate the impact of controllable simulation on agent training using a language world model. Standard simulation without control instructions fails to improve performance and even degrades results on certain benchmarks due to insufficient grounding. Introducing targeted control instructions significantly boosts performance across multiple tool-use domains, demonstrating that controllability is essential for effective simulation-based reinforcement learning. Controllable simulation yields substantial improvements over the baseline on both the Tool Decathlon and MCPMark benchmarks, whereas standard simulation provides negligible or negative gains. The performance gains are particularly pronounced in domains requiring complex tool interactions, such as file system operations, database queries, and API integrations. Certain domains show no improvement from the controlled simulation, indicating that the effectiveness of this approach varies depending on the specific task requirements.

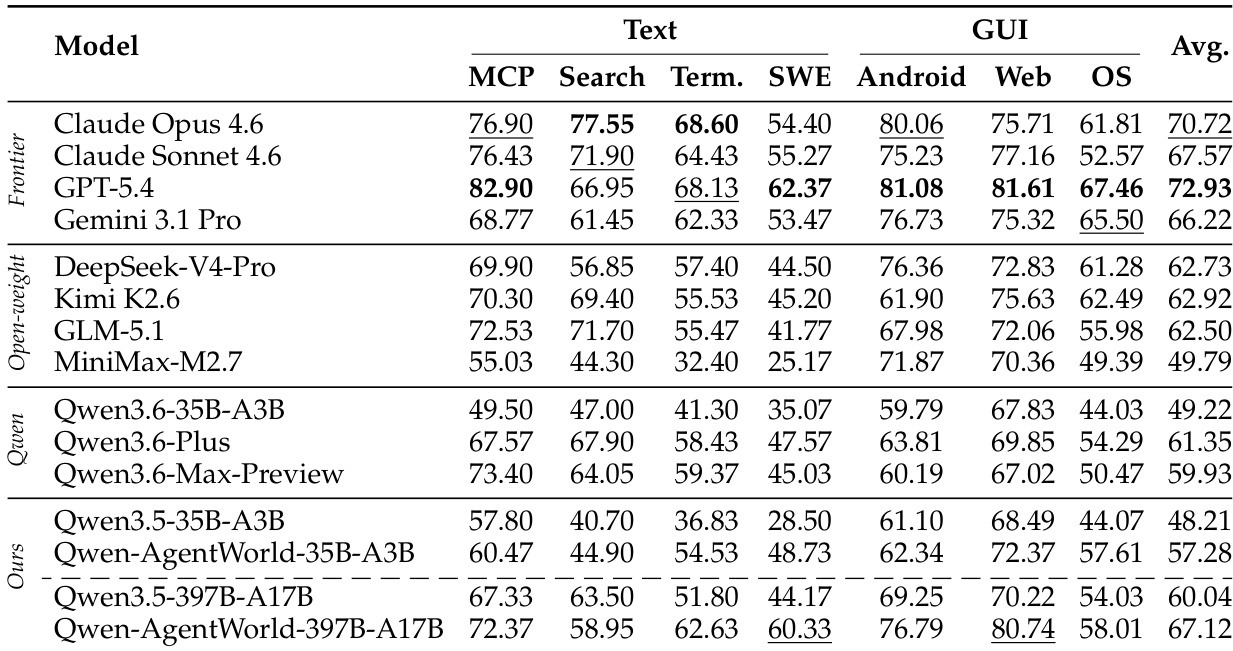
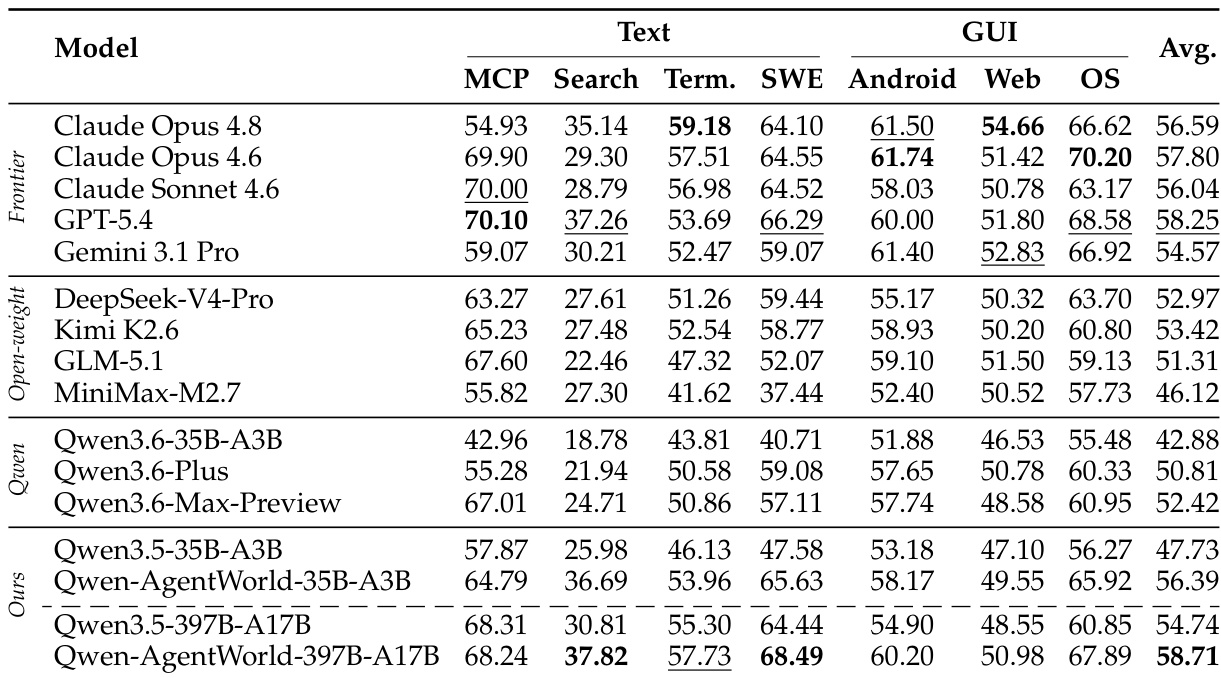
The authors evaluate their proposed language world models against various frontier and open-weight baselines across text-based and GUI domains. The results indicate that the largest proposed model achieves the highest overall average performance, demonstrating particular strength in text-based environments while remaining competitive in GUI domains. Furthermore, comparing the proposed models to their base counterparts reveals consistent performance gains across all domains, confirming the effectiveness of the world-model training pipeline. The largest proposed model outperforms all frontier and open-weight baselines in overall average score. World-model training consistently improves performance across both text-based and GUI domains compared to base model checkpoints. The proposed models show the most significant advantages in text-based domains such as Terminal and Software Engineering.
The the the table presents rejection sampling statistics across seven domains, detailing the number of candidate queries, the retain rate after quality filtering, the final count of SFT samples, and the average number of turns per trajectory. The Web domain has the largest number of candidates and final SFT samples, while the Terminal domain achieves the highest retain rate. The SWE domain has the longest average turns, whereas the Web domain has the shortest. The Web domain has the largest number of candidates and final SFT samples, but a relatively lower retain rate compared to other domains. The Terminal domain achieves the highest retain rate among all domains. The SWE domain has the longest average turns per trajectory, while the Web domain has the shortest.
The authors evaluate Qwen-AgentWorld on a comprehensive benchmark across seven text-based and GUI domains, comparing it against various frontier models. Results indicate that the largest Qwen-AgentWorld model achieves the highest overall performance, particularly excelling in text-based domains such as Terminal and Software Engineering. Additionally, comparing the trained models against their base checkpoints confirms that the world-model training pipeline consistently improves simulation fidelity across all environments. The largest Qwen-AgentWorld model outperforms all frontier baselines in overall average score and leads in text-based domains. Applying the world-model training pipeline yields substantial performance gains over base checkpoints across both text and GUI domains. The Search domain proves to be the most challenging for all evaluated models, with scores significantly lower than those on other text-based tasks.
The authors evaluate the effectiveness of using their language world model as a simulator for reinforcement learning on out-of-distribution environments. Results show that training with the dedicated world model simulator yields substantial performance gains on both evaluated benchmarks, whereas using a standard baseline model as the simulator provides only marginal improvements. This demonstrates that high-fidelity environment simulation is critical for effective simulated reinforcement learning. Using the dedicated world model as a simulator significantly improves agent performance on both evaluated benchmarks compared to the base model. A standard baseline model used as a simulator fails to produce meaningful gains, highlighting the necessity of specialized world-model training for simulation fidelity. The world model enables scalable and generalizable environment simulation that effectively transfers to real-world tasks absent from its training data.

The experiments evaluate a language world model across three configurations: controllable simulation for agent training, intrinsic fidelity benchmarking against frontier and base baselines, and reinforcement learning in out-of-distribution environments. Controllable simulation with instruction-based control is essential for meaningful gains, yielding large improvements on complex tool interactions such as file systems, databases, and API integrations, while standard simulation degrades or provides negligible benefit. In direct simulator evaluations the world‑model training pipeline consistently improves performance over base checkpoints, with the largest model achieving top scores and excelling in text‑based domains like Terminal and Software Engineering, though the Search domain remains the most challenging. For reinforcement learning, only the dedicated world model simulator delivers substantial performance boosts, whereas a standard baseline simulator yields marginal gains, confirming that high‑fidelity simulation is critical for effective simulated training.