Command Palette
Search for a command to run...
LLMのFP4事前学習における収束バイアスの再考:幾何学的起源、系統的影響、およびUFP4レシピ
LLMのFP4事前学習における収束バイアスの再考:幾何学的起源、系統的影響、およびUFP4レシピ
概要
FP4トレーニングは、大規模言語モデル(LLM)の事前トレーニングにおけるメモリおよび計算コストの大幅な削減を約束しているものの、NVIDIAのBlackwell/RubinクラスシステムやAMD MI350シリーズGPUを含む現在のFP4向けハードウェア実装およびトレーニングレシピは、E2M1データ要素を中心としたものにとどまっている。本研究では、この選択が抱える根本的な制約を特定する。具体的には、E2M1のような非一様なフォーマットは、表現可能な量子化ビンの幾何学的非対称性に起因する系統的な負の丸め誤差である「シュリンケージバイアス(Shrinkage Bias)」を本質的に受容せざるを得ないことである。我々は、このバイアスが層を超えて乗法的に蓄積し、Random Hadamard Transform (RHT) によって増幅されることを示す。これにより、既存のE2M1ベースのFP4レシピで観察されるトレーニングの不安定性に対し、統一された説明が提供される。一方、一様なグリッド(E1M2/INT4)はこのグリッド幾何学的エラーを回避し、RHTによって改善されたバケット利用率を、より高い量子化品質へと効率的に変換できる。この知見に基づき、本研究ではUFP4を提案する。UFP4は、全てのトレーニングにおけるGEMM(General Matrix Multiplication)にRHTを適用しつつ、確率的丸め処理をdY(デルタY)に限定する、一様な4ビットのトレーニングレシピである。Dense 1.5B、MoE 7.9B、MoE 124Bの長期事前トレーニングにおいて、UFP4はスケーリング則の解析およびアブレーション研究によって裏付けられ、強力なE2M1ベースのベースラインと比較して、BF16相対的な損失劣化を一貫して低く抑える結果を示した。本研究の結果は、将来のアクセラレータは、E2M1と同様に、一様な4ビットグリッドであるE1M2/INT4スタイルを、トレーニングにおける第一級のプリミティブとしてサポートすべきであることを示唆している。
One-sentence Summary
Ant Group researchers identify Shrinkage Bias in E2M1-based FP4 training as a systematic negative rounding error arising from geometric bin asymmetry and propose UFP4, a uniform 4-bit recipe using E1M2/INT4 grids with the Random Hadamard Transform applied to all three training GEMMs and stochastic rounding restricted to dY, achieving lower BF16-relative loss degradation across Dense 1.5B, MoE 7.9B, and MoE 124B pretraining.
Key Contributions
- The paper identifies Shrinkage Bias, a systematic negative rounding error caused by the geometric asymmetry of the non-uniform E2M1 grid, and shows that it accumulates multiplicatively across layers and is amplified by the Random Hadamard Transform, explaining the training instability observed in existing E2M1-based FP4 recipes.
- It proposes UFP4, a uniform 4-bit training recipe that applies RHT to all three training GEMMs, restricts stochastic rounding to the dY gradient path, and uses an E1M2/INT4-style uniform grid to convert improved bucket utilization from RHT into higher quantization quality.
- On Dense 1.5B, MoE 7.9B, and MoE 124B long-run pretraining, UFP4 consistently achieves lower BF16-relative loss degradation than strong E2M1-based baselines, supported by scaling-law analysis and ablation studies.
Introduction
The authors investigate the training of Large Language Models using 4-bit floating-point formats, a technique that promises significant reductions in memory and computational cost. Current hardware and training recipes predominantly rely on the non-uniform E2M1 format, but end-to-end FP4 pretraining remains unstable and suffers from accuracy loss compared to higher precision baselines. Prior work attempts to mitigate this instability with techniques like the Random Hadamard Transform (RHT) and stochastic rounding, yet retains the problematic E2M1 data format.
The authors identify a fundamental limitation: non-uniform grids like E2M1 inherently suffer from Shrinkage Bias, a systematic negative rounding error caused by the geometric asymmetry of their representable bins. They demonstrate that this bias accumulates multiplicatively across network layers, causing signal decay, and is paradoxically amplified by RHT, which shifts tensor mass into the format's most asymmetric regions. The authors’ main contribution is UFP4, a training recipe that replaces the E2M1 grid with a uniform 4-bit format like E1M2 or INT4. This approach bypasses the grid-geometry error, enabling the effective use of RHT on all critical matrix multiplications while restricting stochastic rounding to a single gradient tensor, thereby achieving superior training stability and accuracy at scale.
Dataset
The authors describe the quantization formats and the blockwise quantization procedure used to construct low-precision training data.
- Format codebooks: Two 4-bit floating-point formats, E2M1 and E1M2, and one 4-bit integer format (INT4) are considered. Each format defines a normalized codebook G with a fixed set of representable levels.
- Blockwise quantization: A tensor is partitioned into contiguous blocks. For each block, a shared scale sB is computed from the maximum absolute value in the block divided by the largest magnitude level in the codebook. Every element is then scaled and mapped to a codebook level via a rounding rule.
- Rounding rules: The paper supports both Round-To-Nearest-Even (RTNE), which is deterministic, and Stochastic Rounding (SR), which samples a level with probability proportional to the distance between adjacent levels. RTNE is noted as the widely adopted choice in recent low-precision recipes such as the NVFP4 method.
- Usage in the model: The quantized tensor QG(T) is used throughout the training pipeline; in arithmetic expressions it denotes the dequantized numerical tensor, ensuring that the low-precision representation is directly integrated into forward and backward passes.
Method
The authors address the challenge of quantizing training tensors, which often contain outlier coordinates that cause most codebook levels to be underutilized. To mitigate this, they leverage Random Hadamard Transforms (RHT). RHT applies a norm-preserving rotation that disperses outlier energy across all coordinates before quantization. The authors use Sylvester Hadamard matrices defined recursively as:
H2n=21[HnHnHn−Hn],H1=[1],where Hn⊤Hn=In for n=2k. An RHT additionally applies a random sign matrix Sn=diag(ϵ1,…,ϵn), ϵi∈{−1,+1}, before the Hadamard transform. Since Hn′=SnHn is orthogonal, applying the same transform to the shared GEMM dimension preserves the full-precision result:
Hn′=SnHn,Y=XW⊤=(XHn′)(WHn′)⊤.The corresponding low-precision GEMM quantizes the rotated operands:
Y=QG(χHn′)QG(WHn′)⊤.While RHT reduces outlier dominance, its effectiveness depends heavily on the underlying quantization grid. The authors identify a fundamental issue with the mainstream E2M1 format, which they term Shrinkage Bias. This bias arises from the geometric asymmetry of Round-to-Nearest-Even (RTNE) rounding bins in non-uniform grids. For an interior quantization level qi, the RTNE rounding bin has left and right widths ℓi and ri. If the density inside the bin is locally uniform, the conditional expected error is:
E[ρG(t)−t∣t∈Bi]=2ℓi−ri=42qi−qi−1−qi+1.An asymmetric bin with ri>ℓi inherently yields a negative expected error, causing magnitude shrinkage. As shown in the figure below, the E2M1 grid exhibits these asymmetric bins at spacing-transition points, whereas uniform grids like E1M2 and INT4 maintain symmetric bins (ℓi=ri), thereby eliminating this geometric source of bias.
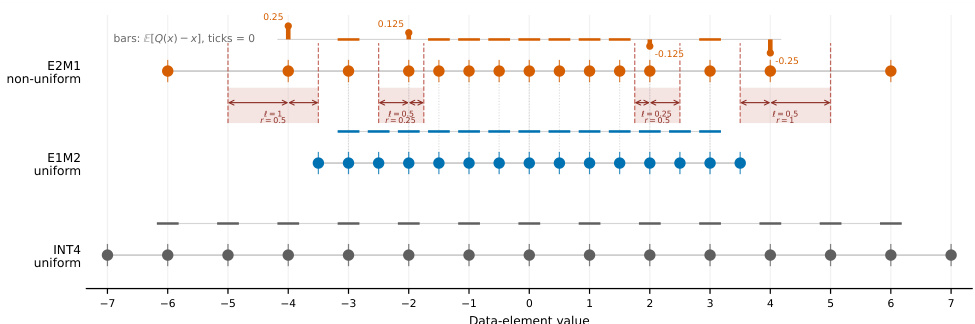
To resolve this, the authors propose UFP4, a 4-bit training recipe based on uniform grids (E1M2/INT4). Once RHT shifts tensors from a dynamic-range-limited to a local-resolution-limited regime, the 4-bit grid prioritizes local magnitude preservation over extreme dynamic range. Refer to the framework diagram for the complete training pipeline.
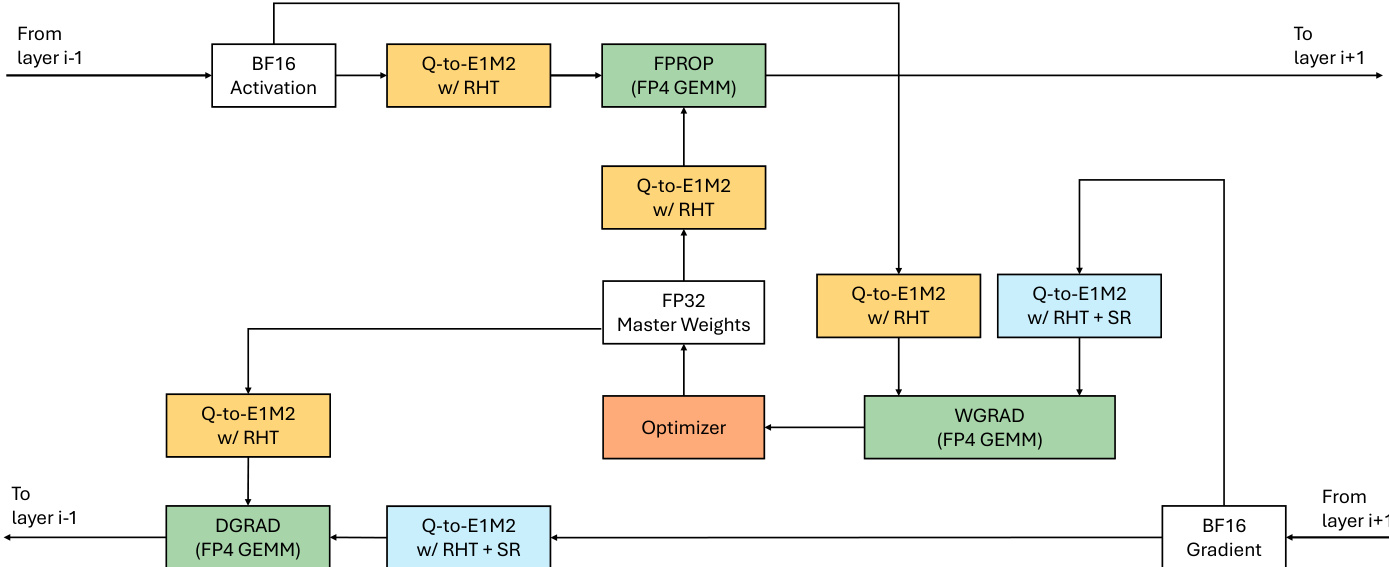
In the UFP4 recipe, for every linear-layer GEMM, the authors apply RHT and quantize the operands to the uniformly spaced grid. Crucially, while E2M1 recipes typically restrict RHT to the weight-gradient path to avoid compounding geometric errors, the unbiased nature of UFP4 allows them to safely enable RHT across all three GEMMs: FPROP (fwd_y), DGRAD (bwd_dx), and WGRAD (bwd(dw)). Stochastic rounding (SR) is applied to dY to preserve gradient expectations. The scale hierarchy design remains orthogonal to this format-level solution, allowing for single-level, two-level, or block scales depending on hardware efficiency.
Experiment
The experiments examine how FP4 grid geometry and random Hadamard transform (RHT) scope interact across local quantization and end-to-end training. Single-tensor and GEMM-output diagnostics show that RHT reverses the preferred format ranking on outlier-heavy tensors, making the uniform E1M2 grid outperform E2M1 after rotation. In long-run pretraining across dense and MoE models up to 124B parameters, the E1M2-based UFP4 recipe consistently reduces the BF16-relative loss gap compared to an E2M1 reference, and scaling-law validation confirms this advantage persists across model scales. Ablation studies reveal that full RHT coverage and stochastic rounding on the output gradient both contribute to the gain, while range-restricted E2M1 cannot substitute for native uniform-grid support, and kernel benchmarks show that fusing RHT into FP4 quantization incurs only modest overhead.
The authors conduct an ablation study to evaluate the impact of Random Hadamard Transform scope and stochastic rounding on FP4 E1M2 training. Results indicate that applying full transform coverage across all GEMM outputs yields the lowest language modeling loss, and adding stochastic rounding further improves performance. Full transform coverage outperforms partial applications, demonstrating that rotating all GEMM outputs is beneficial under the E1M2 grid. Stochastic rounding provides an additional loss reduction when combined with full transform coverage. The UFP4 recipe achieves the best overall performance compared to configurations with limited scope or no stochastic rounding.
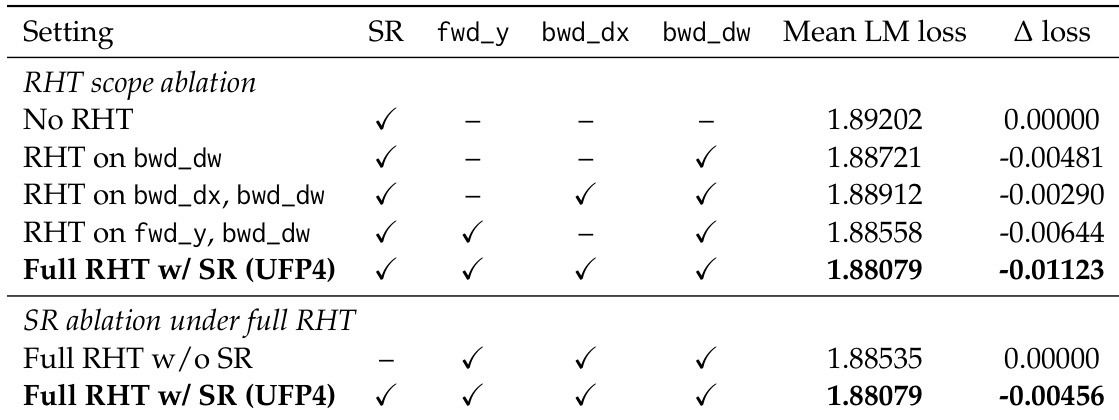
The ablation study examines how the scope of the Random Hadamard Transform and the use of stochastic rounding affect FP4 E1M2 training. Applying the transform to all GEMM outputs consistently yields lower language modeling loss than partial coverage, confirming that full rotation is beneficial under this data format. Adding stochastic rounding on top of full transform coverage further reduces loss, and the combined UFP4 recipe achieves the best overall performance.