Command Palette
Search for a command to run...
HydraHead: ヘッドレベルの機能的異方性から専門化された注意機構のハイブリッド化へ
HydraHead: ヘッドレベルの機能的異方性から専門化された注意機構のハイブリッド化へ
Zhentao Tan Wei Chen Jingyi Shen Yao Liu Xu Shen Yue Wu Jieping Ye
概要
アテンションの二次計算量は、長期コンテキスト処理における重要なボトルネックとなっており、ハイブリッド・アテンション設計への関心が高まっている。既存のオープンソース・ハイブリッドモデルのほとんどは、レイヤーごとの戦略を採用している。しかし、先行研究では、線形アテンション(Linear Attention, LA)とフルアテンション(Full Attention, FA)を統合することの難しさが指摘されており、アテンションのハイブリダイゼーションに関する設計空間は未だ十分に探求されていない。この設計空間を探求するため、私たちは解釈性分析を行い、以下の観測結果を得た。すなわち、ネットワークの層はブロックごとに機能的な類似性を示す一方で、同じ層内における個々のヘッドは入力特徴を共有しつつも、明確な機能的専門化を示すという点である。このヘッドレベルでの異质性は、ヘテロジニアスなアテンション信号を融合するための自然かつ理論的に妥当な粒度として、「ヘッド次元」が適していることを示唆している。こうした知見に基づき、本稿ではFAとLAをヘッド軸方向でハイブリダイズする新しいアーキテクチャ「HydraHead」を提案する。HydraHeadは、以下の2つの主要な革新技術を特徴とする:(1) 解釈性駆動型の選択戦略により、情報検索に重要なヘッドを特定し、FAをそれらのヘッドにのみ保持する仕組み、および (2) FAとLAのヘッド出力間の分布差を埋めるためのスケール正規化融合モジュール。パラメータの再利用と知識蒸留を伴う3段階の転移パイプラインを活用することで、私たちは最小限の訓練オーバーヘッドで高性能なハイブリッドモデルを実現した。統一された訓練環境において、HydraHeadは長期コンテキストタスクにおいて他のハイブリッド設計を上回りつつ、強力な一般的な推論能力を維持している。解釈性駆動型のヘッド選択により、HydraHeadはLA:FAの比率が7:1という構成にもかかわらず、レイヤーwiseなハイブリッド(比率3:1)の長期コンテキスト性能に追いついている。重要なのは、わずか15Bトークンで学習させるだけでありながら、HydraHeadは512Kのコンテキスト長においてベースラインと比較して69%以上の改善を達成し、ネイティブなコンテキスト長256Kを持つ同等サイズのリーディングモデルであるQwen3.5に迫る性能を示したことである。これは、ヘッドレベルのハイブリダイゼーションが持つ大幅なスケーリングの可能性を浮き彫りにしている。
One-sentence Summary
HydraHead, a novel architecture hybridizing full and linear attention at the head level via interpretability-driven selection of retrieval-critical heads and a scale-normalized fusion module, trained on only 15B tokens, outperforms layer-wise hybrid designs in long-context tasks, achieving over 69% improvement over the baseline at 512K context length and matching a 3:1 layer-wise hybrid’s long-context performance at a 7:1 linear-to-full attention ratio.
Key Contributions
- HydraHead is a hybrid attention architecture that mixes full attention and linear attention at the head level, using an interpretability-driven selection strategy to reserve full attention only for retrieval-critical heads.
- A scale-normalized fusion module reconciles the distributional mismatch between full and linear attention head outputs, enabling stable integration of their complementary signals.
- A three-stage transfer pipeline with parameter reuse and distillation yields high-performance hybrids with minimal training overhead; trained on 15B tokens, HydraHead improves over the baseline by more than 69% at 512K context, approaches Qwen3.5, and matches a 3:1 layer-wise hybrid’s long-context performance with a 7:1 linear-to-full attention ratio.
Introduction
The authors examine the challenge of extending LLM context windows for autonomous reasoning agents, where standard full attention scales quadratically and pure linear attention often suffers expressivity collapse on precise retrieval tasks. Prior hybridization efforts primarily adopt layer-wise designs, but layer outputs vary smoothly, offering weak signal for placing different attention mechanisms, and training hybrids that combine full and linear attention has proven difficult. The key insight is that attention heads within a layer exhibit sharp functional heterogeneity: only a sparse subset drives token-level retrieval, while the rest remain largely inactive. The authors leverage this head-level specialization to propose HydraHead, a fine-grained architecture that uses interpretability-based selection to assign full attention solely to retrieval-critical heads and linear attention to the rest, combined with a head-wise scale-normalized fusion to mitigate interference, enabling aggressive full-attention compression and state-of-the-art long-context performance with little loss in reasoning.
Method
The authors leverage causal intervention techniques to determine which attention heads require Full Attention (FA) and which can be approximated by Linear Attention (LA). This process involves three steps. First, they use activation patching to measure the direct causal effect of individual heads on target behaviors, identifying receiver heads that write critical signals into the residual stream. Second, they employ path patching to trace upstream contributions, identifying sender heads that feed into the receivers. Finally, they fuse these per-head scores across multiple capabilities to create a unified ranking. The top-ranked heads are assigned to the FA branch to preserve precise retrieval capabilities, while the remaining heads are assigned to the LA branch.
To harness the complementary strengths of both mechanisms, the authors introduce a Head-wise Hybrid Attention mechanism. As shown in the figure below:
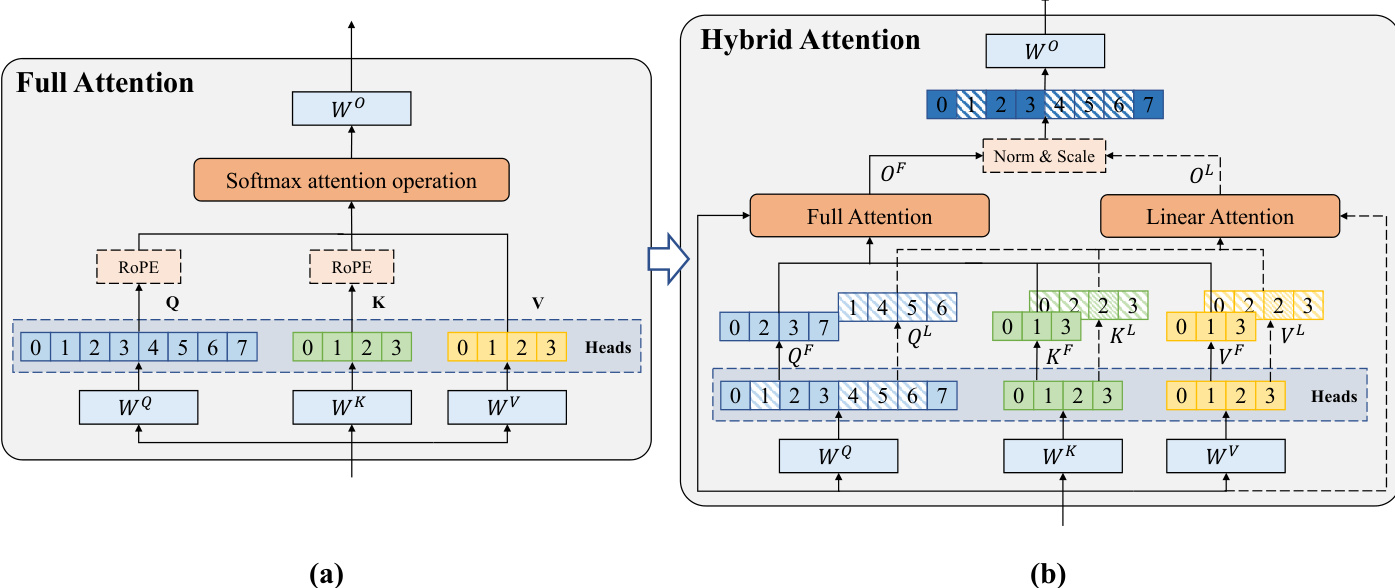
Instead of applying a uniform attention pattern across all layers or tokens, the model selectively assigns each query head to either the FA branch or the Gated DeltaNet (GDN) branch based on the functional importance estimated previously. This fine-grained hybridization allows the model to retain critical reasoning capabilities in specific heads via FA, while leveraging the efficiency of GDN for context extension.
The internal structural designs of the two branches are specifically refined to support this hybridization. As shown in the figure below:
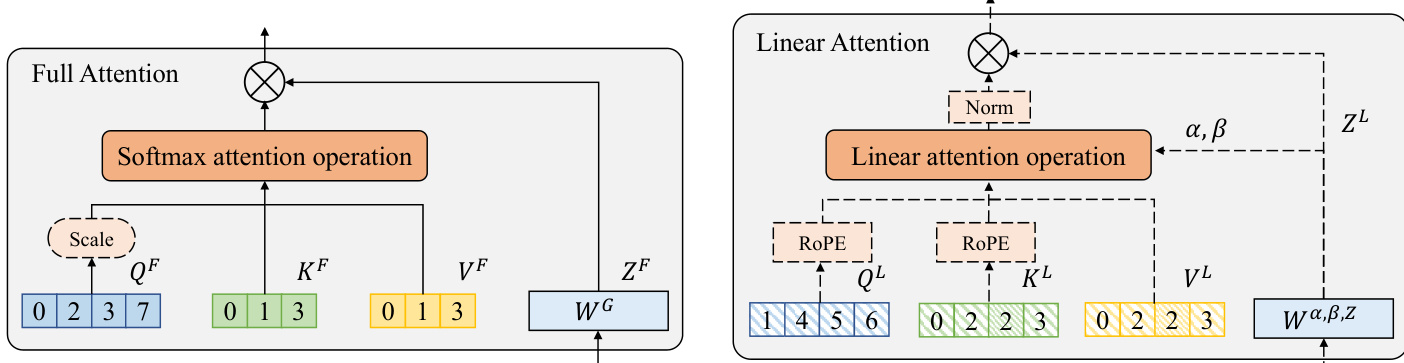
For the FA branch, the authors remove Rotary Position Embedding (RoPE) and apply a log-scale coefficient to query features to stabilize attention distributions in long contexts. They also introduce an auxiliary gate branch to alleviate the attention sink phenomenon. For the GDN branch, they explicitly integrate RoPE into query and key projections to enhance positional awareness within the receptive field and expand the number of key-value heads to match the query heads, transitioning to a Multi-Head Attention-like configuration.
The authors also contextualize this design against other hybrid strategies. As shown in the figure below:
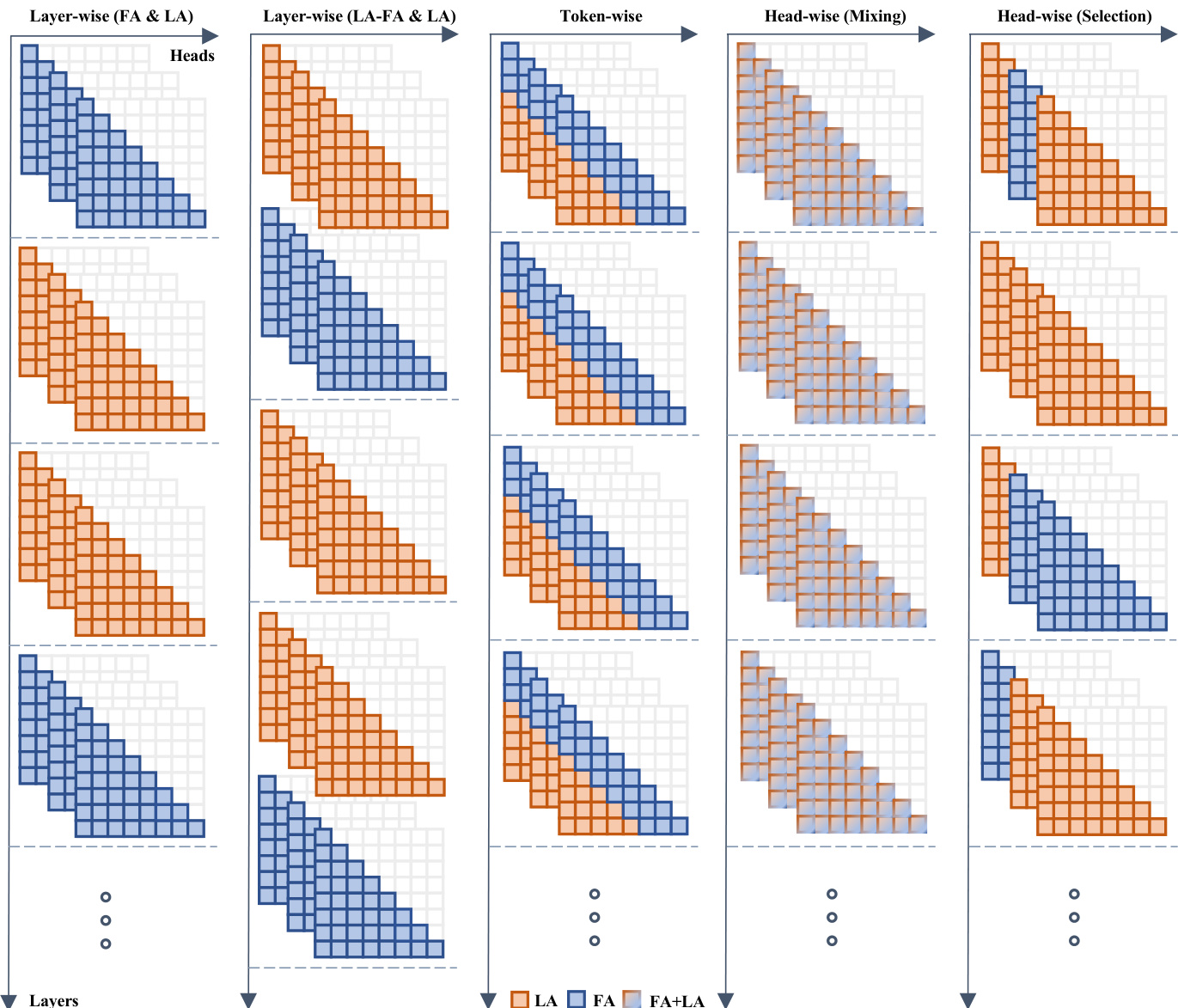
They compare head-wise selection against layer-wise and token-wise hybrids, demonstrating that head-level granularity provides a natural space for fusing heterogeneous attention signals.
A fundamental challenge in fusing FA and LA outputs is the distributional gap. FA produces sharp, low-entropy distributions modulated by query norm, while LA yields smoother, higher-entropy representations. To reconcile this, the authors propose a scale-normalized fusion module. They apply RMSNorm independently to each head's output Oh to unify feature scales:
O^h=Norm(Oh)
These normalized outputs are concatenated along the head dimension according to their original indices to maintain functional identity. Finally, a learnable head-wise scaling vector γ is applied to adaptively recalibrate the contribution of each head:
O~:,h:=γh⋅O^:,h:
The modulated tensor is then reshaped and projected to produce the final attention output.
Transforming a pre-trained Transformer into a hybrid architecture requires a principled initialization to avoid optimization instability. The authors adopt a three-stage transfer pipeline.
In the first stage, they focus on parameter migration and layer-wise output alignment. For FA heads, they introduce a gate branch initialized to approximate an identity function. For GDN heads, they reuse the Q, K, V projection weights from the pre-trained FA layers, using channel-wise repetition to handle dimension mismatches for key-value heads. They freeze the pre-trained backbone and optimize the hybrid layers using a Mean Squared Error loss to align the hidden states of the hybrid layers with the original FA layers:
Lalign=∑l=1L∣∣HFA(l)(x)−HHybrid(l)(x)∣∣22
In the second stage, they perform global logits distillation. The entire model is unfrozen, and the student model's output distribution is aligned with the teacher model using KL divergence loss combined with cross-entropy loss. This ensures global semantic coherence and recovers performance degradation from the linear approximation.
In the final stage, the authors conduct long-context fine-tuning. Using the Next Token Prediction objective with a longer context length, the model consolidates its long-context capabilities, building upon the stable initialization from the previous stages.
Experiment
The HydraHead architecture is evaluated on Qwen3-1.7B against layer-wise, token-wise, and other head-wise hybrids using long-context retrieval (RULER) and general reasoning benchmarks, with ablations examining structural components, fusion designs, and head selection strategies. Interpretability-guided global head selection, which identifies a sparse subset of critical attention heads scattered across layers, coupled with head-wise scale modulation and an optimized three-stage transfer learning pipeline, consistently yields the best balance between long-context extrapolation and reasoning capability. Scaling to over 15B tokens shows that HydraHead surpasses standard Transformers and other hybrid models at extreme context lengths while preserving strong general reasoning, validating that head-level specialization is the right axis for efficient hybridization.
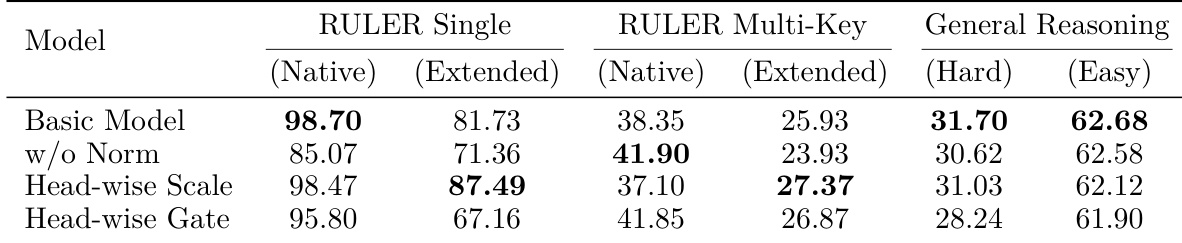
The authors investigate feature fusion strategies for their head-wise hybrid architecture, comparing direct concatenation, head-wise scale modulation, and head-wise gated competition. Results indicate that feature normalization is essential, as removing it leads to significant performance drops in long-context retrieval tasks. Head-wise scale modulation emerges as the most effective fusion method, consistently outperforming gated competition, particularly in extended context scenarios. Removing feature normalization causes severe degradation in long-context retrieval performance. Head-wise scale modulation outperforms gated competition across nearly all evaluation metrics. Scale modulation provides substantial gains in long-context extension scenarios compared to dynamic gating.
The authors compare their proposed head-wise hybrid model against standard Transformers and other hybrid architectures on long-context retrieval benchmarks. Results show that while standard models and competing hybrids suffer severe performance degradation or complete failure at extended context lengths, the proposed method maintains robust retrieval capabilities across both single and multi-key tasks. The proposed model sustains high accuracy on single-key retrieval tasks even at the longest evaluated context lengths, whereas other hybrid models and standard Transformers drop to near-zero performance. On multi-key retrieval tasks, the proposed approach significantly outperforms existing hybrid architectures at extended context lengths, demonstrating superior scalability. Standard Transformer models without specific length extrapolation enhancements lose their retrieval capability beyond their native context window, highlighting the advantage of the head-wise hybrid design.
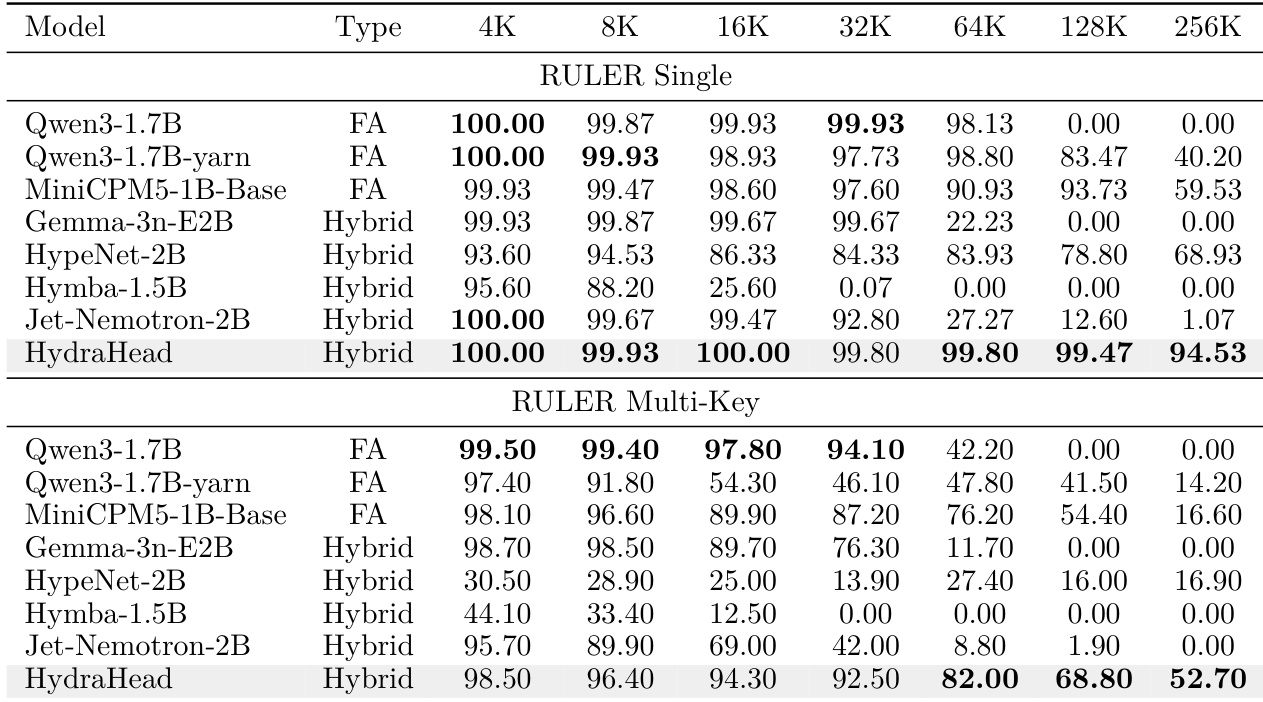
The authors compare their head-wise hybrid model using a 7:1 ratio against a layer-wise hybrid baseline using a 3:1 ratio. Results show that the head-wise approach achieves broadly comparable long-context retrieval performance despite using a much higher proportion of linear attention. Furthermore, the head-wise model demonstrates a substantial advantage in general reasoning capabilities, highlighting the effectiveness of interpretability-guided head selection in preserving domain knowledge under aggressive sparsity. The head-wise hybrid model with a 7:1 ratio maintains long-context retrieval performance comparable to the layer-wise hybrid with a 3:1 ratio. The head-wise approach significantly outperforms the layer-wise baseline on both hard and easy general reasoning benchmarks. Interpretability-guided head selection allows for aggressive linear attention ratios without severely compromising general-domain capabilities.

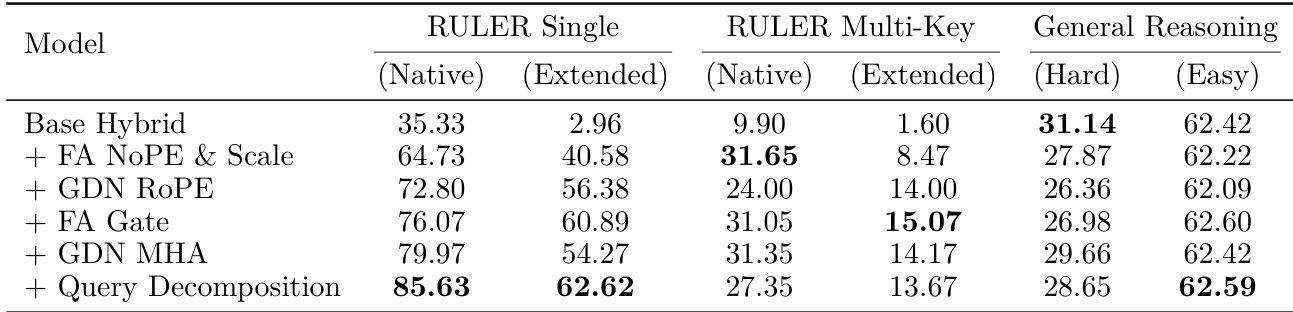
The authors conduct an ablation study to evaluate the contribution of various structural components in their head-wise hybrid architecture. Progressive integration of modules such as positional scaling, gating mechanisms, and multi-head attention configurations significantly enhances long-context retrieval capabilities while maintaining general reasoning performance. The final configuration with query decomposition achieves the best balance across all evaluation dimensions. Replacing positional encoding in the full attention branch with scale modulation substantially improves long-context retrieval but initially reduces general reasoning performance. Incorporating multi-head attention in the linear attention branch helps recover the lost general reasoning capabilities. The complete model configuration with query decomposition achieves optimal performance on single-key retrieval tasks while maintaining robust results across other benchmarks.
The authors compare their proposed HydraHead architecture against layer-wise, token-wise, and head-wise hybrid transformers to evaluate performance trade-offs. Results indicate that while layer-wise hybrids favor long-context tasks and token-wise or head-wise hybrids excel at general reasoning, HydraHead achieves the best overall balance. It delivers state-of-the-art performance in long-context retrieval while maintaining robust general reasoning capabilities with a moderate cache footprint. HydraHead achieves the highest performance in both native and extended context single-key retrieval tasks, significantly outperforming other hybrid architectures. Token-wise and head-wise hybrids demonstrate substantially better general reasoning capabilities compared to layer-wise hybrids, though they struggle with long-context extrapolation. The proposed method maintains strong general reasoning performance while using a smaller key-value cache size compared to full head-wise mixing baselines.
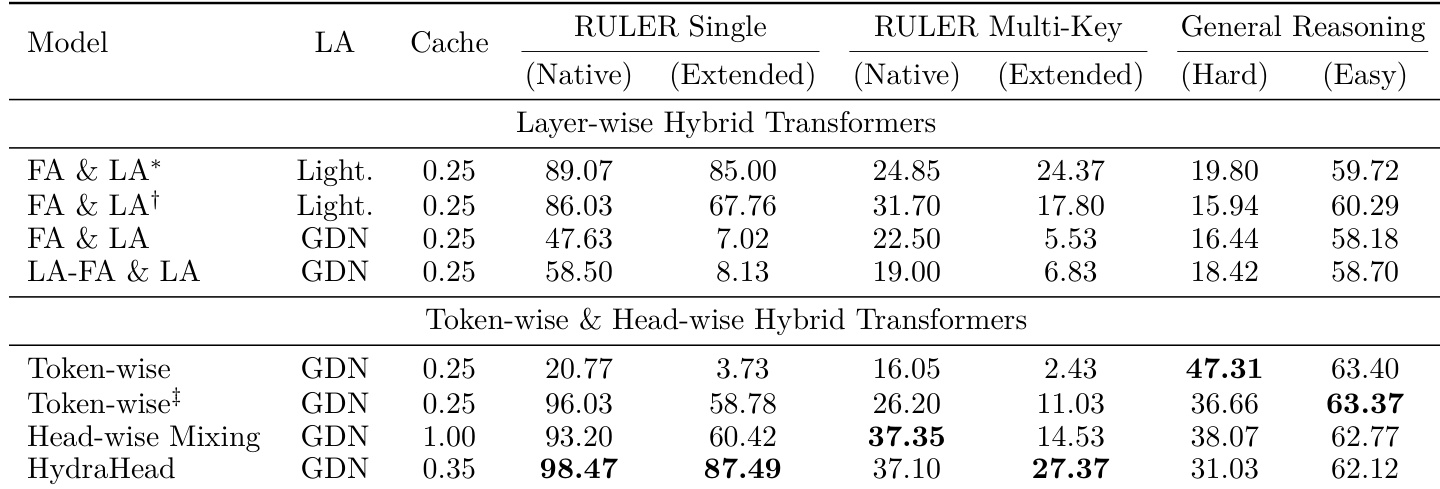
The experiments evaluate head-wise hybrid attention architectures for long-context retrieval and general reasoning. A comparison of fusion strategies finds that head-wise scale modulation with feature normalization provides the best scalability, consistently surpassing gated competition at extended context lengths. Benchmarks against standard Transformers and other hybrids confirm that the proposed design maintains robust single- and multi-key retrieval where alternatives fail, while interpretability-guided head selection allows aggressive linear attention ratios without degrading general reasoning. Ablation studies demonstrate that integrating multi-head attention in the linear branch, positional scaling, and query decomposition progressively balances long-context and reasoning performance, and the final HydraHead achieves state-of-the-art retrieval with strong general capabilities and a smaller cache footprint.