Command Palette
Search for a command to run...
MobileForge: アノテーション不要のモバイルGUI Agentsへの階層フィードバック誘導ポリシー最適化による適応
MobileForge: アノテーション不要のモバイルGUI Agentsへの階層フィードバック誘導ポリシー最適化による適応
概要
MLLMベースのモバイルGUI agentsは、UIの理解とアクション実行において大幅な進歩を遂げているが、モバイルアプリは数が多く頻繁に更新されるため、人間が記述したタスク、デモンストレーション、または報酬ラベルで網羅するのは困難であり、それらを実際のターゲットアプリに適応させるコストは依然として高い。既存のannotation-free GUI学習は手動監督を削減するものの、ターゲットアプリの探索、カリキュラムマイニング、rollout実行、フィードバックを接続する統合基盤を欠いており、さらにポリシー最適化はしばしば孤立したrolloutと粗い報酬に依存しており、それらは信頼性の高い改善シグナルに変換するのが困難である。本研究では、モバイルGUI agents向けのannotation-free適応システムであるMobileForgeを提案する。MobileForgeは、実際のモバイルアプリのインタラクションに基づいてタスク生成とrollout評価を grounding するMobileGymと、軌道結果、ステップレベルのプロセスフィードバック、修正ヒントをヒント文脈化されたステップレベルのGRPO更新に変換する階層型フィードバック誘導ポリシー最適化(HiFPO)から構成される。自動生成されたannotation-free適応データのみを使用し、MobileForgeはAndroidWorldにおいてQwen3-VL-8BをPass@3 67.2%に適応させ、これはクローズドデータを用いたGUI特化型ベースモデルGUI-Owl-1.5-8Bの69.0%に迫る結果である。MobileForge適応版のForgeOwl-8Bは、AndroidWorldにおいてさらにPass@3 77.6%、ドメイン外のMobileWorld GUI-onlyスプリットにおいて41.0%の成功率を達成し、本評価において最も強力なオープンデータモバイルGUI agentを確立した。コード、データ、および学習済みモデルは https://mobile-forge.github.io/ で公開される。
One-sentence Summary
MobileForge is an annotation-free adaptation system that employs MobileGym to ground task generation and rollout evaluation in real mobile app interaction, while its Hierarchical Feedback-Guided Policy Optimization (HiFPO) component converts trajectory outcomes and corrective hints into hint-contextualized step-level GRPO updates, enabling the Qwen3-VL-8B model to achieve 67.2% Pass@3 on AndroidWorld and the adapted ForgeOwl-8B variant to reach 77.6% Pass@3.
Key Contributions
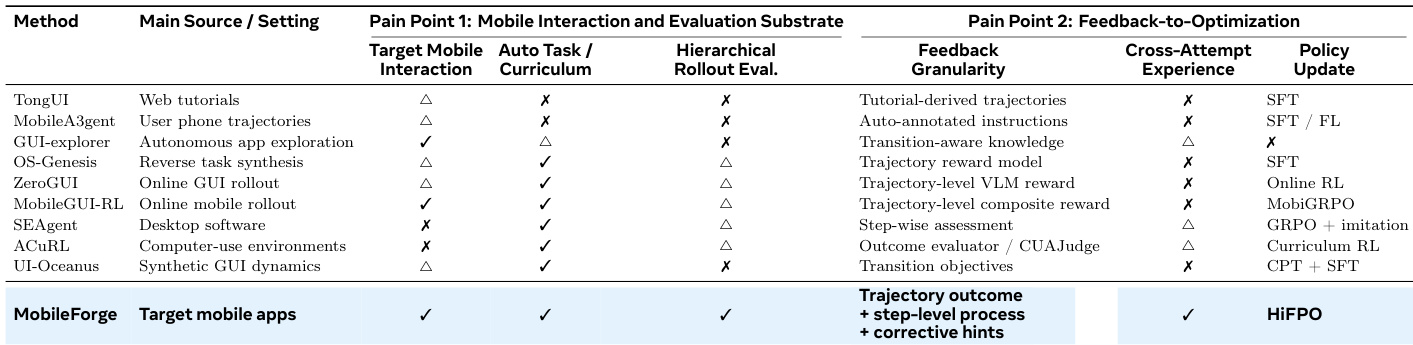
- This work introduces MobileGym, an interaction and evaluation substrate that grounds task generation and rollout execution directly within real mobile application traces. The component extracts executable tasks and provides hierarchical outcome feedback alongside corrective hints to align evaluation with policy learning.
- The framework incorporates Hierarchical Feedback-Guided Policy Optimization (HiFPO), which filters trajectories through hierarchical feedback and converts step-level process signals into hint-contextualized GRPO updates. This mechanism accumulates reusable experience across multi-attempt rollouts to refine agent capabilities beyond isolated optimization loops.
- Evaluations on the AndroidWorld and MobileWorld GUI-only benchmarks demonstrate that the adaptation pipeline effectively transfers to both generalist and specialized models. The resulting ForgeOwl-8B agent achieves a 77.6% Pass@3 score on AndroidWorld and 41.0% success on MobileWorld GUI-only, establishing the strongest open-data mobile GUI agent in the evaluation.
Introduction
Modern mobile GUI agents powered by multimodal language models demonstrate strong UI comprehension, yet adapting them to real-world applications remains costly due to the vast and rapidly evolving app ecosystem. Prior annotation-free approaches attempt to reduce manual supervision but suffer from fragmented pipelines that fail to connect app exploration, curriculum mining, and feedback execution. Their policy optimization also typically treats interactions as isolated episodes with sparse rewards, preventing the accumulation of reliable step-level improvement signals. The authors address these gaps with MobileForge, an annotation-free adaptation framework that grounds task generation and evaluation in real app interactions through MobileGym and introduces Hierarchical Feedback-Guided Policy Optimization to convert corrective hints into hint-contextualized GRPO updates for significant benchmark improvements.
Dataset

-
Dataset Composition and Sources: The authors construct an adaptation task pool anchored by 527 reference trajectory identifiers drawn from 20 distinct applications. This foundation yields a comprehensive candidate pool of 3,249 tasks specifically designed for AndroidWorld environments.
-
Subset Details and Filtering Rules: Each source application contributes a curriculum-generated subset of three to eight new tasks. The authors apply strict generation constraints to ensure tasks span different core functionalities, vary in length between one and forty steps, and remain pedagogically useful. Redundancy is actively avoided, and parameter variations are limited to a maximum of three per functionality to emphasize meaningful behavioral differences over minor tweaks.
-
Data Usage and Processing: The curated tasks feed directly into the model training pipeline to support annotation-free adaptation. Before integration, every candidate undergoes automated evaluation to filter out low-quality samples. The authors process the data through a scoring mechanism that measures task reasonableness, completion likelihood, and step quality, retaining only high-confidence trajectories for hierarchical feedback-guided policy optimization.
-
Metadata Construction and Processing Details: The final dataset entries are formatted as JSON objects that pair evaluation metrics with task specifications. Each record contains a self-contained instruction, estimated step count, targeted core functionality, variation type, and explicit prerequisites. The accompanying metadata block supplies confidence scores and explanatory summaries, which the authors use to guide the training loop and validate step-level quality during policy updates.
Method
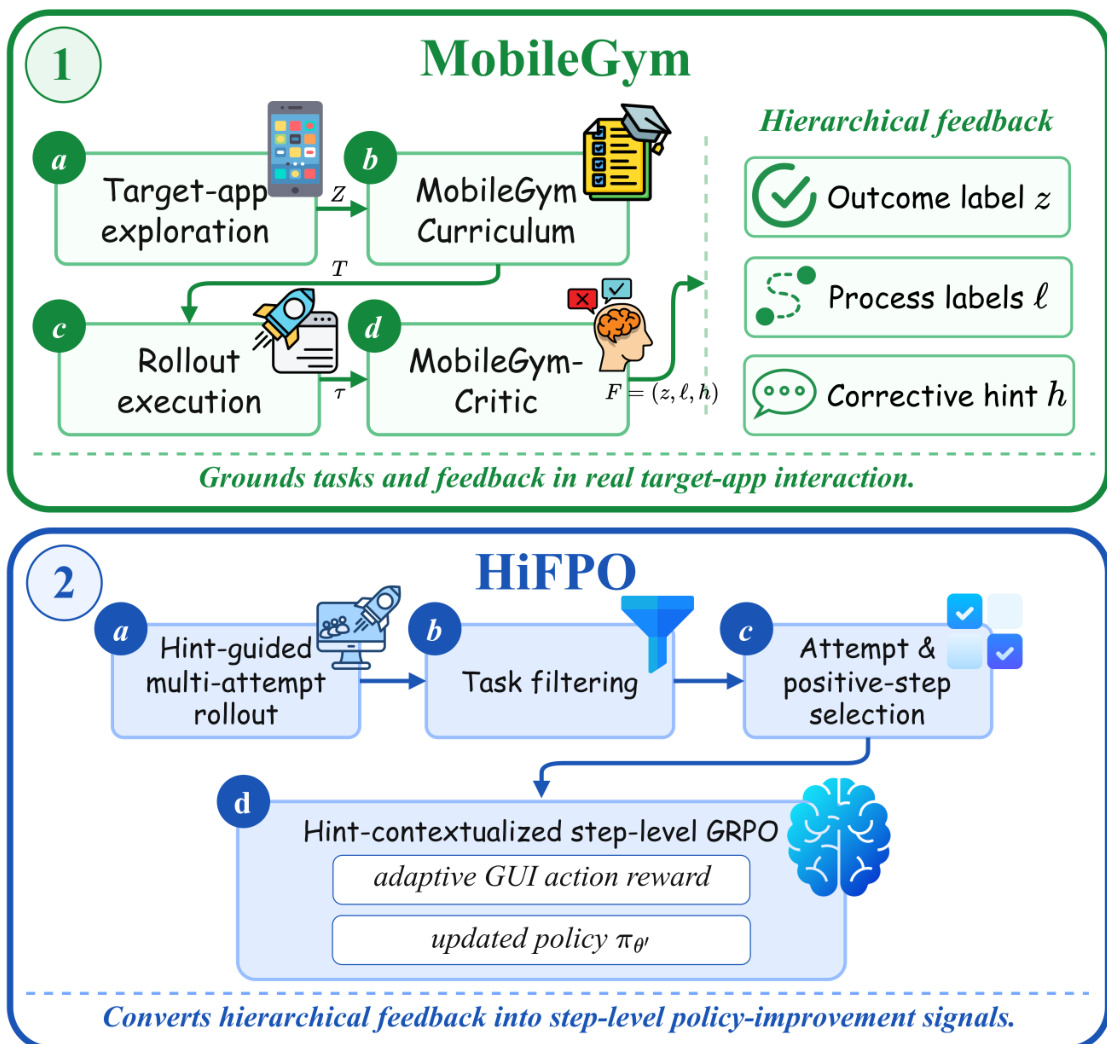
The authors propose MobileForge, an annotation-free adaptation framework designed to autonomously adapt mobile GUI agents to target applications without relying on human-written tasks, expert demonstrations, or reward labels. The architecture is divided into two coupled components: MobileGym, which serves as the interaction and evaluation substrate, and HiFPO, which drives the feedback-guided policy optimization. Refer to the framework diagram for the overall adaptation loop.

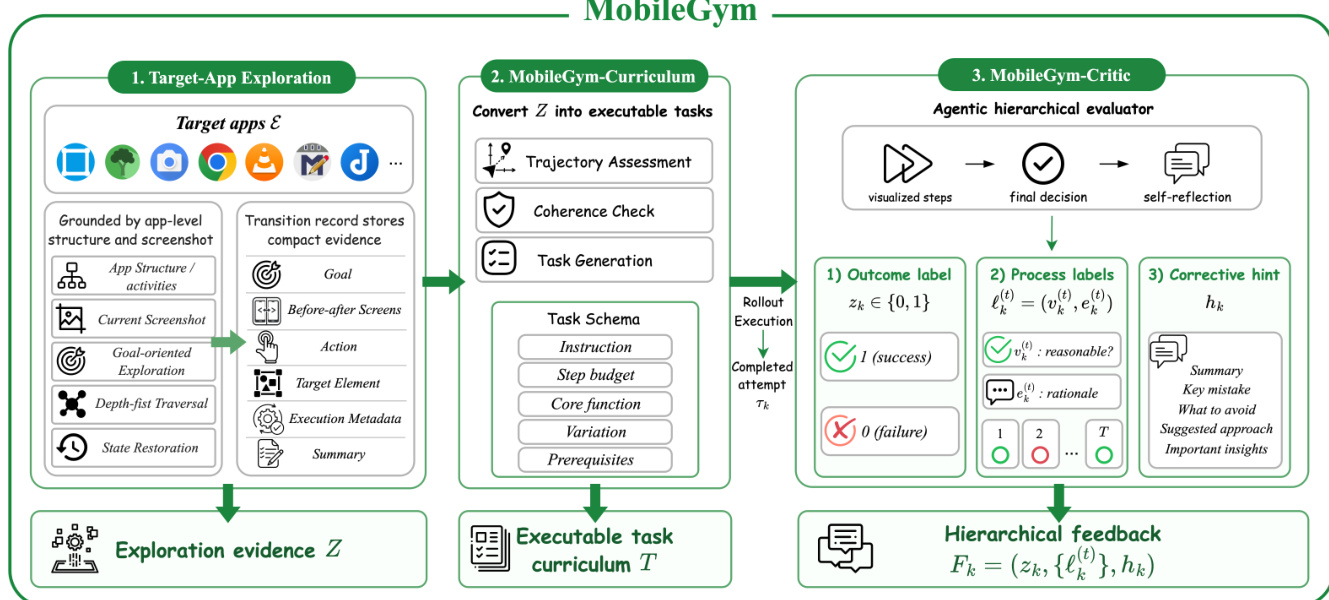
MobileGym grounds the adaptation process in real target-app interactions. It begins with a function-aware exploration phase that records reachable GUI transitions, app-level structural anchors, and interaction summaries to form an exploration evidence pool Z. This evidence is then processed by the MobileGym-Curriculum module, which assesses trajectory coherence and generates a set of executable tasks T grounded in observed app behavior. During rollout execution, the MobileGym-Critic evaluates completed attempts to produce hierarchical feedback. As shown in the figure below, this critic operates as an agentic evaluator that transforms raw execution logs into visual action traces and generates a structured verdict containing an outcome label zk∈{0,1}, step-level process labels ℓk(t), and corrective hints hk.
HiFPO leverages this hierarchical feedback to drive policy updates through a multi-attempt rollout protocol. For each task in the curriculum, the system executes K attempts in a serialized manner. Before each attempt k, the framework aggregates corrective hints from previous attempts to form a hint context η<k=Aggregate(h1,…,hk−1). The policy then generates a new rollout attempt conditioned on this accumulated context. The system filters out mastered tasks where the success rate equals one, retaining only partially solved or failed tasks for further optimization.
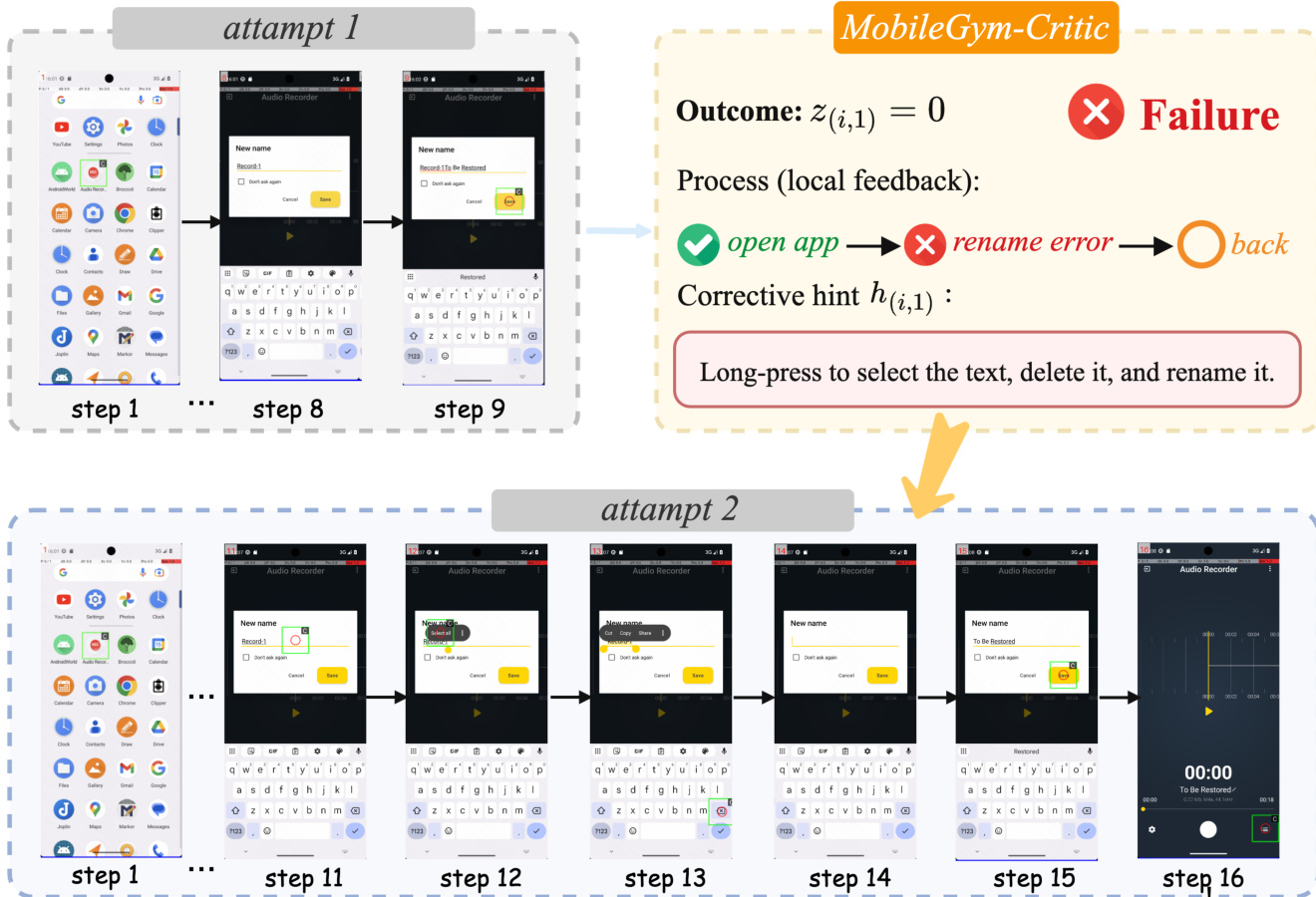
To convert long-horizon trajectories into dense supervision signals, HiFPO performs dual-feedback filtering. It selects the most informative attempt for each retained task by prioritizing successful rollouts with the highest fraction of reasonable local steps, or the best-failed attempt otherwise. From the selected attempt, only locally reasonable steps are extracted to form the step-level training set D. The corrective hints are appended to the task instruction before the next rollout attempt, allowing the agent to learn from past mistakes. An example of this hint-guided refinement is illustrated in the figure below.
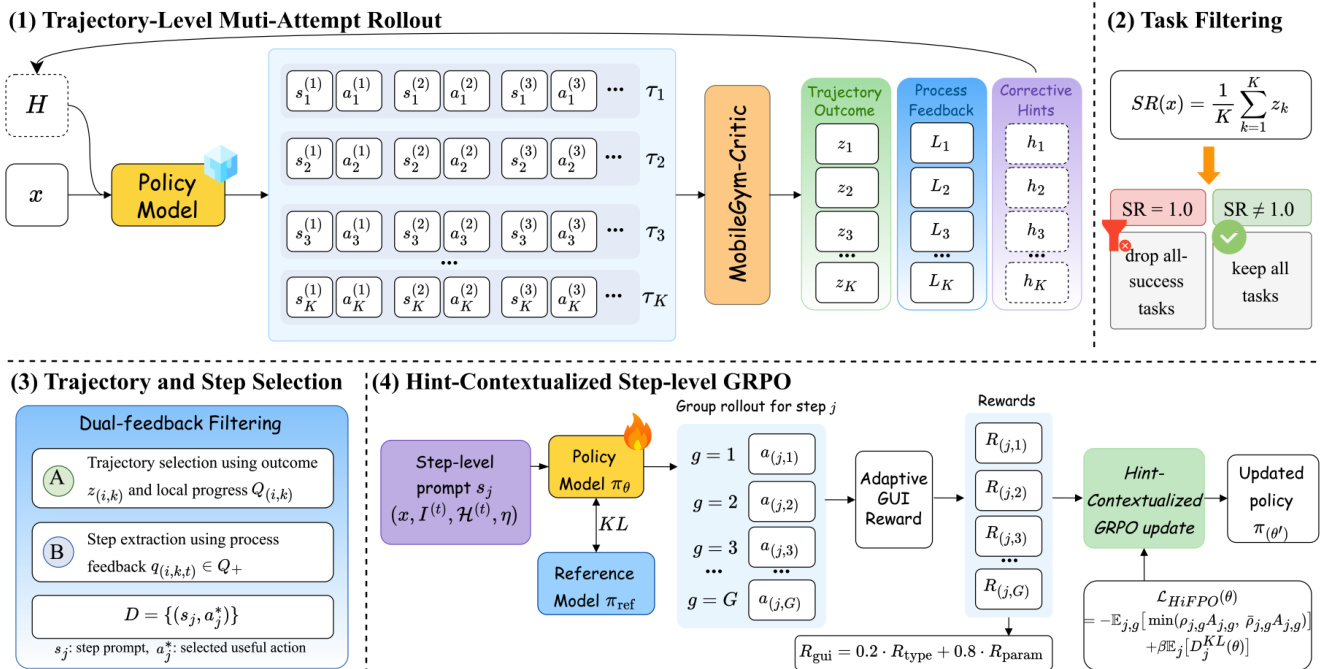
The final training stage employs a hint-contextualized step-level GRPO algorithm. For each selected step, the decision state is augmented with the corrective hint context and rendered into a prompt s~j. The policy samples a group of G candidate responses from the old policy. Each response is parsed into a structured GUI action and scored using an adaptive GUI action reward that separates action type correctness from argument precision. The reward for a response is computed as Rj,g=λtyperj,gtype+λargrj,garg. Rewards are normalized within the response group to compute the relative advantage Aj,g=(Rj,g−μj)/(σj+ϵstd). The policy is then updated via a clipped GRPO objective with KL regularization:
LHiFPO(θ)=−Ej,g[min(ρj,gAj,g,ρˉj,gAj,g)]+βEj[DjKL(θ)],where ρj,g and ρˉj,g represent the importance ratio and its clipped version, respectively. This design ensures that the policy optimization is strictly conditioned on the feedback-aware state, enabling robust step-level credit assignment without relying on external reward models.
Experiment
The evaluation assesses annotation-free adaptation across an in-domain AndroidWorld benchmark and an out-of-domain MobileWorld split using two 8B-scale base agents, with performance scaled across 200 to 900 generated tasks. The primary experiments demonstrate that the proposed adaptation framework successfully aligns generalist models with specialized GUI agents in-domain while enabling meaningful cross-domain generalization. Ablation studies validate that multi-attempt corrective hints, hint-contextualized GRPO optimization, strategic filtering that retains difficult or partially solved tasks, and trajectory-grounded curriculum design are all essential for effective learning. Qualitative analysis confirms that these components collectively strengthen the agent's capacity to maintain task intent through complex UI sequences and improve core interaction skills, although limitations persist for extended multi-step and cross-application workflows.
The authors present MobileForge, a framework that addresses mobile interaction and feedback challenges by employing auto-generated curricula, hierarchical rollout evaluation, and corrective hints within a cross-attempt experience loop. Results indicate that this annotation-free adaptation significantly enhances both generalist and GUI-specialized agents, enabling generalist models to approach the performance of specialized systems on in-domain benchmarks while demonstrating transferability to out-of-domain environments. Ablation studies confirm that specific design choices, such as hint-contextualized optimization, retaining difficult tasks through strategic filtering, and using trajectory-grounded curriculum generation, are essential for maximizing these improvements. MobileForge utilizes corrective hints and cross-attempt experience to substantially improve multi-attempt rollout success rates. The adaptation process allows generalist models to achieve performance levels comparable to GUI-specialized agents on in-domain tasks. Trajectory-grounded curriculum generation provides broader functional coverage than methods relying solely on initial app screens.
The experiment evaluates the impact of different decision models on the adaptation loop. Results indicate that Gemini 2.5 Pro yields the strongest performance across most metrics, while the open-source Qwen3-VL-8B model also significantly outperforms the untrained baseline. This demonstrates that the adaptation process remains effective even with a less powerful or open-source evaluator. Gemini 2.5 Pro achieves the highest success rates across the majority of Pass@k metrics. Qwen3-VL-8B as a decision model significantly outperforms the base untrained policy. The feedback-to-optimization loop provides benefits regardless of whether a proprietary or open-source decision model is used.

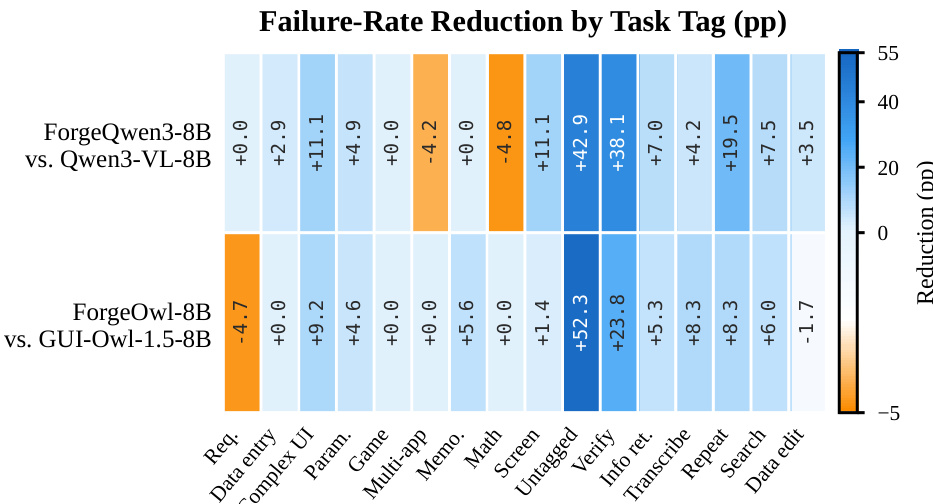
The authors analyze the reduction in failure rates across various task categories for two adapted models compared to their base agents. The data indicates that the adaptation process significantly improves performance in specific UI-related skills, while performance in complex or multi-step reasoning tasks remains challenging. Verification and search tasks show the largest reductions in failure rates for both adapted models. Adaptation leads to notable improvements in handling complex user interfaces and information retrieval. Multi-application tasks and game-playing scenarios exhibit regressions or a lack of improvement.
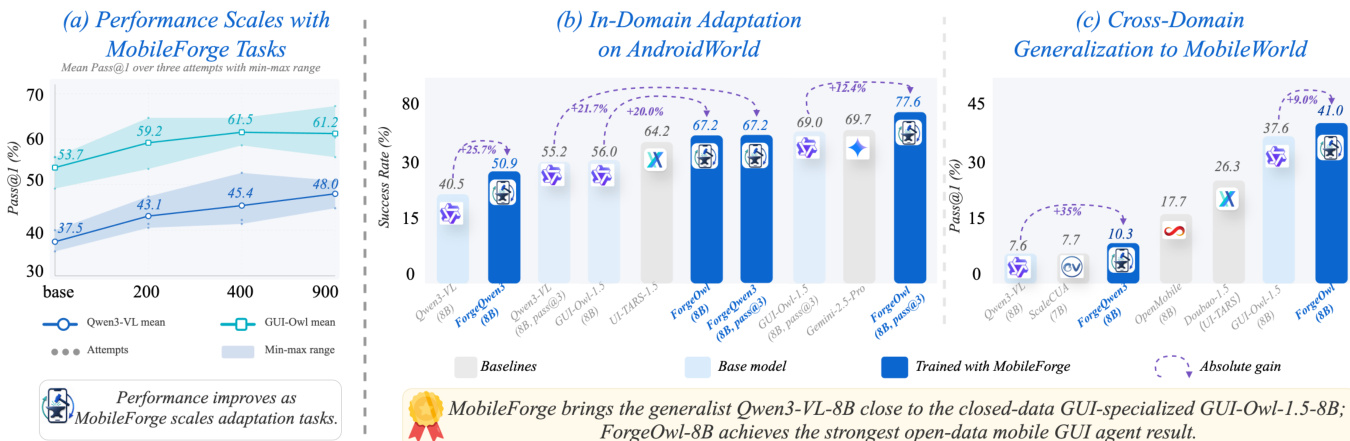
The experiments demonstrate that MobileForge significantly enhances mobile GUI agent performance through annotation-free adaptation on AndroidWorld. The adapted models, specifically ForgeQwen3 and ForgeOwl, show substantial gains over their base versions and competitive performance against specialized baselines. Furthermore, the method generalizes well to out-of-domain MobileWorld tasks, with ForgeOwl achieving the strongest results among open-data agents. Performance consistently improves as the number of adaptation tasks increases, indicating effective scaling with more training data. The adapted ForgeOwl model achieves the highest success rate on AndroidWorld tasks, surpassing both base models and other specialized baselines. The adapted ForgeOwl model demonstrates strong generalization to MobileWorld, achieving the highest success rate among the evaluated models in the out-of-domain setting.
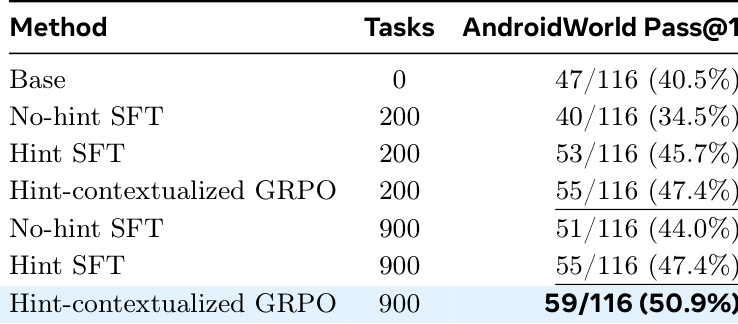
The authors investigate the effectiveness of different training objectives and hint usage on model adaptation across varying task scales. The results demonstrate that training without hints can lead to performance degradation relative to the base model, while the inclusion of hints yields improvements. The hint-contextualized group relative policy optimization approach consistently outperforms supervised fine-tuning methods, establishing it as the most effective strategy for adaptation. Training without hints results in lower performance compared to the base model. Incorporating hints into supervised fine-tuning improves performance over the base model. Hint-contextualized group relative policy optimization achieves the highest performance across all task scales.
The experiments evaluate the MobileForge framework across in-domain and out-of-domain mobile environments to validate its annotation-free adaptation process, which integrates corrective hints, trajectory-grounded curricula, and a cross-attempt experience loop. Comparisons across different decision models, training objectives, and task categories confirm that hint-contextualized optimization and strategic filtering are essential for maximizing agent performance, particularly for user interface navigation and information retrieval. Ultimately, the framework enables generalist models to approach specialized systems in-domain while scaling effectively with additional tasks and maintaining robust transferability even with open-source evaluators.