HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

考える時間を見つける:リアルタイム強化学習における計画予算の学習

準最適な学習率スケジュールの形状とはどのようなものか?



























考える時間を見つける:リアルタイム強化学習における計画予算の学習
準最適な学習率スケジュールの形状とはどのようなものか?
IIDを超えて:表形式基盤モデルは本当にどれほど汎用的か?
ReFreeKV: 閾値フリーなKVキャッシュ圧縮を目指して
TUA-Bench: 汎用端末操作エージェントのためのベンチマーク
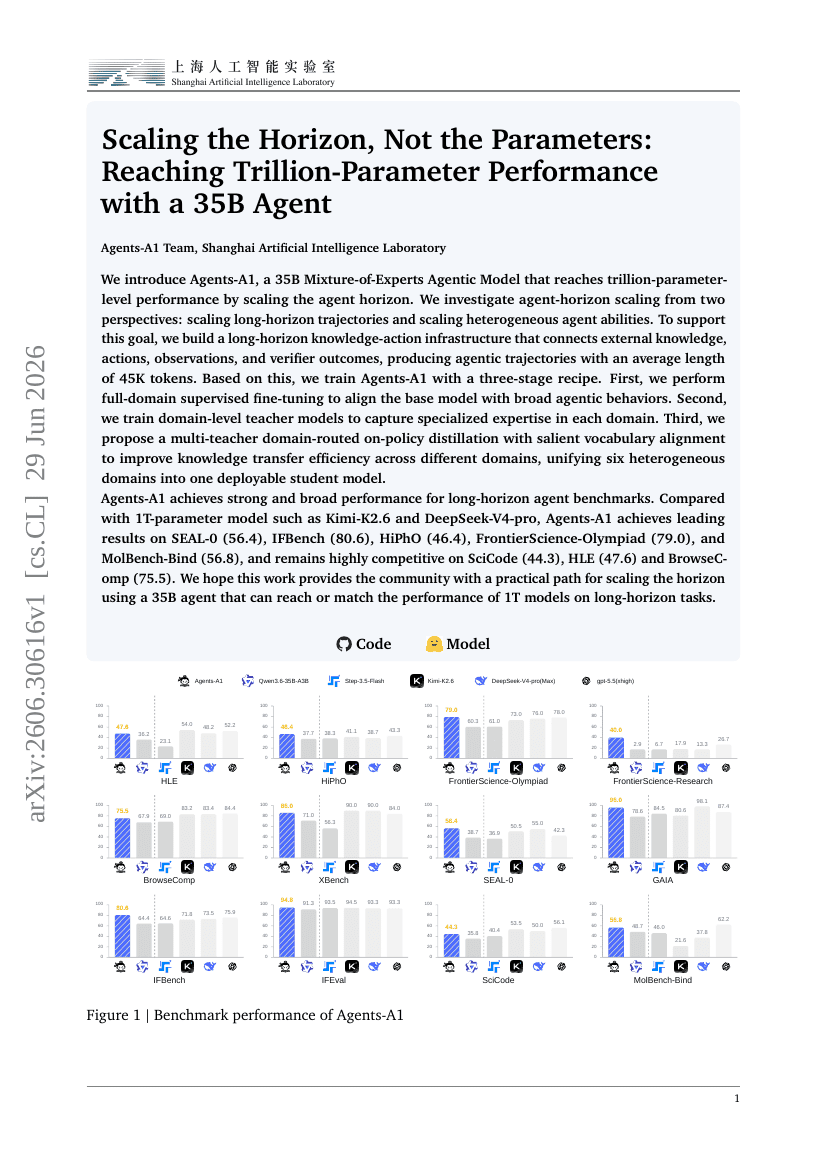
パラメータではなくホライズンをスケールする:35Bエージェントで1兆パラメータ級の性能を達成
LiveEdit: リアルタイム拡散ベースストリーミング動画編集に向けて
エージェント的棄権:エージェントは行動する代わりに停止すべき時を知っているか?
EVA-Bench: 音声エージェント評価のための新たなエンドツーエンドフレームワーク
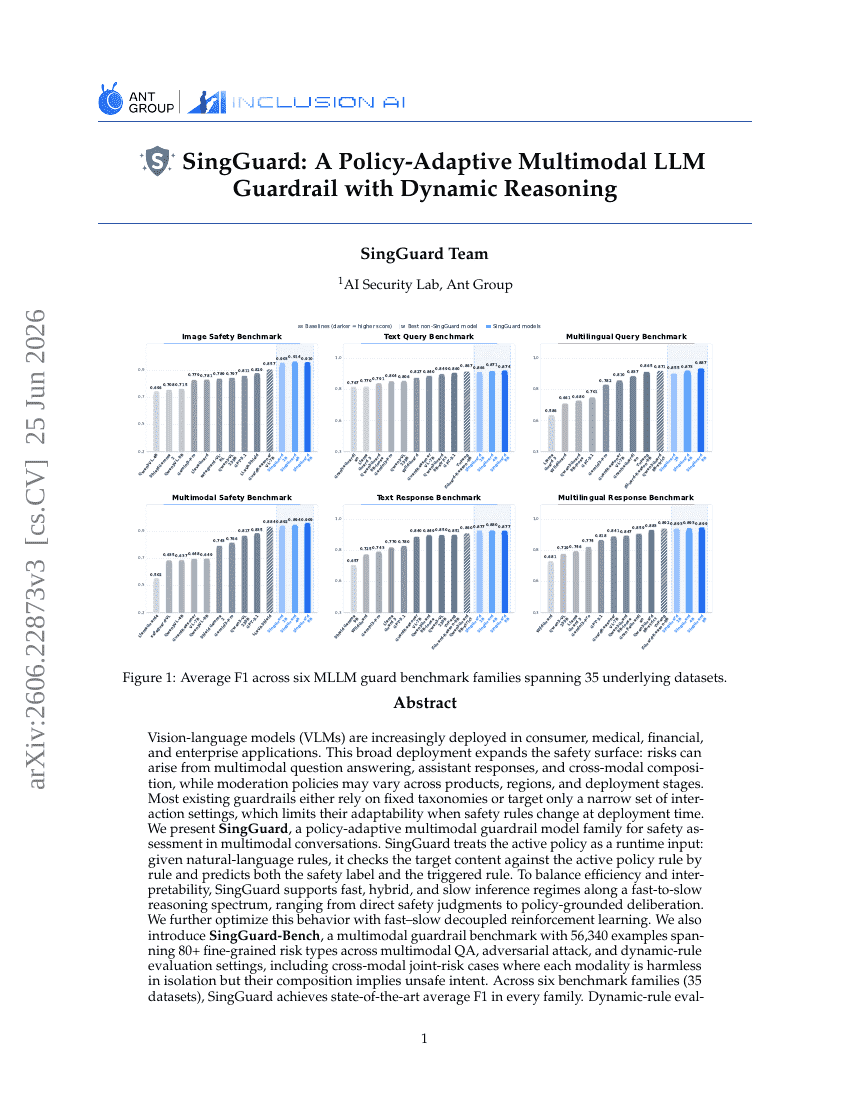
SingGuard: 動的推論を備えたポリシー適応型マルチモーダルLLMガードレール
潜在思考の形式化:LLMsにおける思考表現の四つの公理
MultiHashFormer: ハッシュベースの生成言語モデル
Qwen-Image-2.0-RL 技術報告
橋渡し動作としての並進移動:人間からロボットへの操作スキルの伝達
PhysisForcing: ロボット操作のための物理強化型世界シミュレータ
OpenTME: TCGA由来のAI駆動H&E腫瘍微小環境プロファイルのオープンデータセット
FlashAttention-4: 非対称ハードウェア拡張のためのアルゴリズムとカーネルパイプラインの共同設計
DSpark:半自己回帰的生成による自信スケジュール型擬似推論
ViQ: 任意の解像度におけるテキストと整合した視覚量子化表現
検証の地平線:コーディングagent報酬に対する銀の弾丸はない
Qwen-Image-Agent: 実世界における画像生成のコンテキストギャップを埋める
OPID: エージェント型強化学習のためのオンポリシースキル蒸留
ロボット制御のための文脈内世界モデル
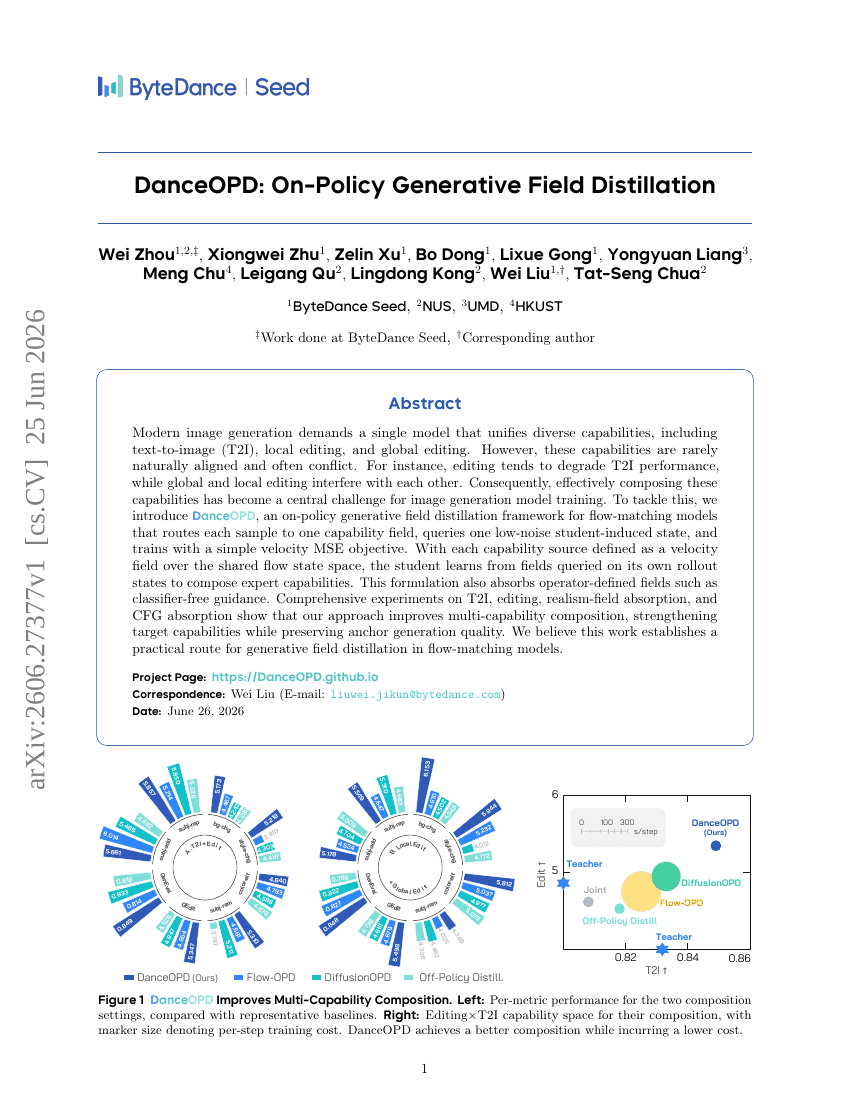
DanceOPD: オンポリシー生成フィールド蒸留
Autodata: 高品質な合成データを作成するためのエージェント型データサイエンティスト
大規模言語拡散モデルの改良
OCR推論はどれほど堅牢か?視覚摂動下におけるビジョン・ランゲージモデルのOCR推論堅牢性の評価
RoboAtlas: 文脈対応アクティブSLAM
意図を考慮したシーン表現による群衆におけるロボット視覚ナビゲーションの学習
ディープ強化学習強化型イベントトリガー型データ駆動型予測制御のための3次元ケーブル駆動型ソフトロボットアーム
自然なアングロッキング:事前学習においてどのルールが生き残るかに対する非対称な制御
任意の非負整数は三角数、五角数、および七角数の和である
IIDを超えて:表形式基盤モデルは本当にどれほど汎用的か?
ReFreeKV: 閾値フリーなKVキャッシュ圧縮を目指して
TUA-Bench: 汎用端末操作エージェントのためのベンチマーク
パラメータではなくホライズンをスケールする:35Bエージェントで1兆パラメータ級の性能を達成
LiveEdit: リアルタイム拡散ベースストリーミング動画編集に向けて
エージェント的棄権:エージェントは行動する代わりに停止すべき時を知っているか?
EVA-Bench: 音声エージェント評価のための新たなエンドツーエンドフレームワーク
SingGuard: 動的推論を備えたポリシー適応型マルチモーダルLLMガードレール
潜在思考の形式化:LLMsにおける思考表現の四つの公理
MultiHashFormer: ハッシュベースの生成言語モデル
Qwen-Image-2.0-RL 技術報告
橋渡し動作としての並進移動:人間からロボットへの操作スキルの伝達
PhysisForcing: ロボット操作のための物理強化型世界シミュレータ
OpenTME: TCGA由来のAI駆動H&E腫瘍微小環境プロファイルのオープンデータセット
FlashAttention-4: 非対称ハードウェア拡張のためのアルゴリズムとカーネルパイプラインの共同設計
DSpark:半自己回帰的生成による自信スケジュール型擬似推論
ViQ: 任意の解像度におけるテキストと整合した視覚量子化表現
検証の地平線:コーディングagent報酬に対する銀の弾丸はない
Qwen-Image-Agent: 実世界における画像生成のコンテキストギャップを埋める
OPID: エージェント型強化学習のためのオンポリシースキル蒸留
ロボット制御のための文脈内世界モデル
DanceOPD: オンポリシー生成フィールド蒸留
Autodata: 高品質な合成データを作成するためのエージェント型データサイエンティスト
大規模言語拡散モデルの改良
OCR推論はどれほど堅牢か?視覚摂動下におけるビジョン・ランゲージモデルのOCR推論堅牢性の評価
RoboAtlas: 文脈対応アクティブSLAM
意図を考慮したシーン表現による群衆におけるロボット視覚ナビゲーションの学習
ディープ強化学習強化型イベントトリガー型データ駆動型予測制御のための3次元ケーブル駆動型ソフトロボットアーム
自然なアングロッキング:事前学習においてどのルールが生き残るかに対する非対称な制御
任意の非負整数は三角数、五角数、および七角数の和である