Command Palette
Search for a command to run...
OpenRath: Agent システムのためのセッション中心実行時状態
OpenRath: Agent システムのためのセッション中心実行時状態
Fukang Wen Zhijie Wang Ruilin Xu
概要
現代のagentシステムはしばしば断片化されたランタイム状態に悩まされている。会話記録、ツール実行結果、メモリイベント、ワークスペース配置、分岐の履歴、およびリプレイ証拠は別々に記録され、検査や再現が困難となる。OpenRathは、マルチagent・マルチセッションシステム向けのPyTorchに類似したプログラミングモデルにより、この課題に対処する。この類推は、テンソル計算ではなく、中核となる第一級ランタイム抽象概念の役割に関するものである。その中核抽象概念はSessionであり、これはagentsとワークフロー間で渡されるランタイム値である。Sessionは、ブランチ可能、検査可能、リプレイ可能、バックエンド認識型、および合成可能である。Sessionは会話チャンク、サンドボックス配置、系統メタデータ、token使用量、保留中の作業、およびツール証拠を記録するとともに、メモリ操作がランタイム記録にどこから組み込まれるかを定義する。この状態がプログラム実行に用いられるのと同じ値によって伝達されるため、フォーク、マージ、およびリプレイは外部トレースから再構築される状態ではなく、明示的なランタイム操作となる。OpenRathはさらにSandbox、Tool、Agent、Memory、Workflow、およびSelectorを定義しており、Selectorはコントロールフローをランタイムルーティングによる意思決定に変換する。本報告書は、プログラミングモデル、アーキテクチャ、監査済みマイルストーン、および証拠プロトコルを提示する。本システムの主張は制御されたランタイム特性に限定されており、広範な定量的比較、ライブプロバイダ品質、オプションバックエンドの利用可能性、およびメモリ品質は後続の評価に委ねられる。中核的な主張は、Sessionがagentシステムに対して監査可能な合成のための第一級ランタイム値を提供するという点にある。
One-sentence Summary
The authors propose OpenRath, a PyTorch-like programming model that centralizes fragmented agent runtime state within a first-class Session abstraction, embedding conversation chunks, tool evidence, and lineage metadata into composable runtime values to enable explicit forking, merging, and replay, while restricting its current claims to controlled runtime properties pending broader quantitative evaluation.
Key Contributions
- OpenRath introduces a programming model centered on Session, a first-class runtime value that consolidates conversation chunks, tool outputs, sandbox placement, and lineage metadata into a single composable object flowing through agent execution.
- The framework replaces external trace reconstruction by treating branching, merging, and replay as explicit runtime operations on Session. A dedicated Selector component routes control flow based on this runtime state, ensuring memory interactions and tool calls remain auditable without relying on controller-side conventions.
- The system records token usage, pending work, and memory operations as explicit runtime events on Session rather than hiding them within prompts or external logs. This architecture supports a structured evidence protocol and audited milestone system that enables deterministic replay and systematic debugging.
Introduction
As multi-agent systems transition from isolated demos to complex, long-running workflows, maintaining a clear view of runtime state across tools, memory, and execution branches has become essential for debugging, auditing, and systematic evaluation. Existing frameworks and runtime layers typically handle orchestration, tracing, or memory in isolation, often burying intermediate state in controller code or framework-specific objects. This fragmentation obscures execution paths, making it difficult to reconstruct decisions, audit provenance, or reliably replay runs. The authors address this gap by introducing OpenRath, which proposes the Session as a first-class runtime state object. This connective layer preserves conversation history, tool effects, and memory operations in a single branchable and inspectable structure, enabling seamless state transfer across agents and workflows without forcing existing infrastructure to adopt incompatible representations.
Dataset
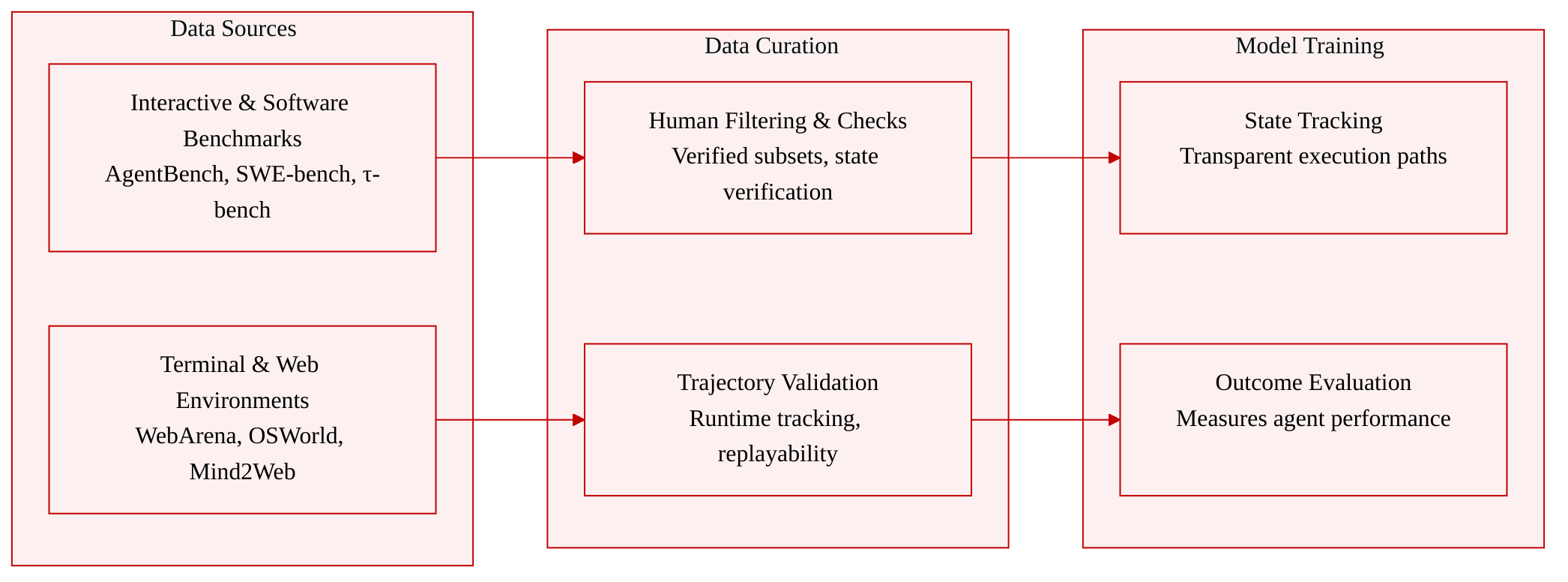
• Dataset composition and sources: The authors utilize a curated collection of established agent benchmarks and simulated environments spanning interactive tasks, software engineering, terminal operations, and web or desktop workflows.
• Subset details and filtering: The evaluation suite includes AgentBench and τ-bench for interactive settings, SWE-bench alongside SWE-agent and the human-filtered SWE-bench Verified subset for software engineering, TerminalBench and TerminalWorld for terminal tasks, and a broad range of web and embodied environments such as WebArena, VisualWebArena, WorkArena, OSWorld, WebShop, Mind2Web, ALFWWorld, ScienceWorld, GAIA, and TheAgentCompany. Specific subsets apply targeted constraints, including database-state verification in τ-bench and human curation for the SWE-bench Verified split.
• Data usage and processing: Rather than functioning as a training corpus, this collection serves as an interactive evaluation framework. The authors leverage these environments to measure agent outcomes in realistic settings while prioritizing trajectory inspectability and replayability. This approach treats reproducible execution paths as a foundational requirement for reliable performance scoring.
• Additional processing details: The authors do not apply traditional training splits, mixture ratios, or cropping strategies. Instead, the pipeline focuses on runtime state tracking and trajectory validation to ensure transparent and verifiable agent behavior during evaluation.
Method
The authors introduce OpenRath as a programming model that addresses the fragmentation of runtime state in modern agent systems. Instead of treating conversation transcripts, tool logs, memory updates, and branch provenance as separate side channels, the framework promotes these effects into a single, first-class runtime value called Session. Refer to the framework diagram below for a visual comparison of traditional loop-scattered state versus the proposed session boundary.
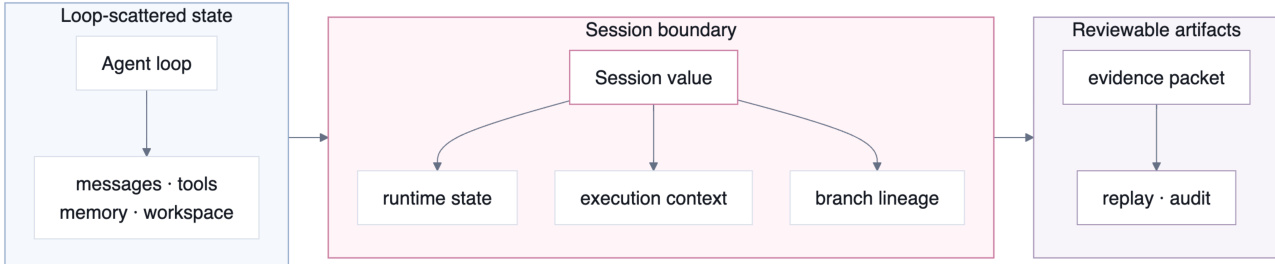
This design ensures that a Session is branchable, inspectable, replayable, and backend-aware. It carries conversation chunks, sandbox placement metadata, lineage records, token usage, pending work, and tool evidence. By keeping this state attached to the value used in program execution, operations such as forking, merging, and replaying become explicit runtime steps rather than states reconstructed from external traces.
To structure agent programs, the authors adopt a PyTorch-inspired programming model. The analogy focuses on architectural interfaces for composable computation rather than tensor mathematics. In this paradigm, a central value flows through reusable modules that expose a uniform transformation contract. The framework defines a compact vocabulary of runtime objects, each with a narrow boundary but preserving the same input-output shape.
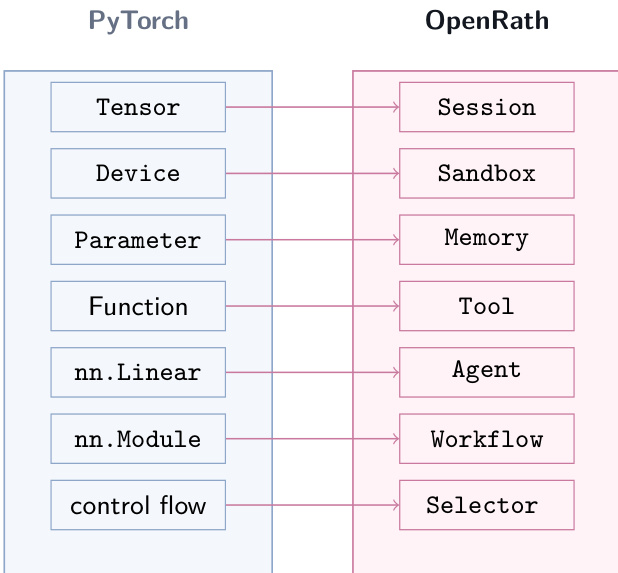
Under this mapping, Session functions as the flowing value, analogous to a tensor. Agent modules act as reusable transformations similar to neural network layers, following a forward mapping contract. Workflow serves as a compositional container, while Sandbox handles explicit placement, Memory manages persistent agent-bound state, and Tool defines executable functions. Control flow is routed dynamically by a Selector object, which reads the current Session to decide the next step, ensuring branching and looping remain inspectable runtime decisions rather than hard-coded logic.
The runtime architecture governs how a Session remains inspectable as it moves through agents, tools, sandboxes, and stored artifacts. Rather than introducing separate runtime objects for every phase, OpenRath employs a concise lifecycle. A session is initialized from user or agent context, placed on an execution backend when necessary, transformed by agents or workflows, branched for parallel work, merged after review, and persisted for later replay.

Branching operations duplicate state while preserving parent-child relations. Merging joins compatible sessions and records both parents, with compatibility checks extending to sandbox handles to ensure placement consistency. This approach treats placement as an integral part of the runtime graph.
As a crossing object in the agent runtime stack, Session connects specialized layers without absorbing their responsibilities. The framework integrates with multi-agent APIs, graph runtimes, tracing SDKs, tool protocols, and real-environment evaluation harnesses by making their effects visible within a single Session object.
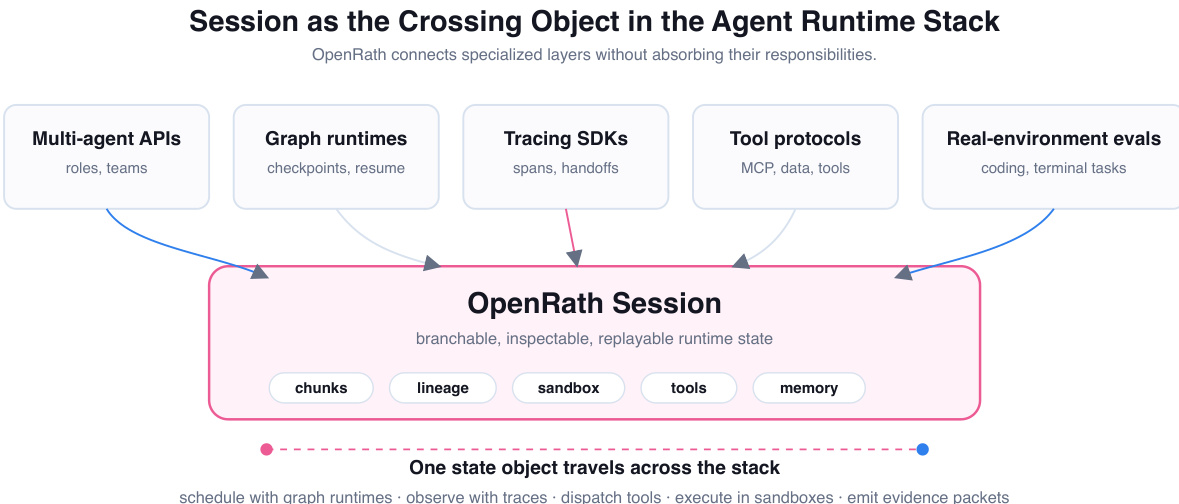
This ecosystem role allows OpenRath to coexist with existing infrastructure. Graph state records execution checkpoints for schedulers, trace spans record observed events for observers, and Session serves as the live value written for the agent program itself. Evidence is attached directly to this value, enabling fork, merge, handoff, and replay operations to function on ordinary program values.
Tool execution follows a layered path that separates runtime state from the execution backend. The model interacts with FlowToolCall schemas, while the session loop combines built-in and user tools to resolve calls by name. Arguments are validated against the session, and payloads are dispatched through the active sandbox to the backend. Side effects, stdout, artifacts, and errors return as tool-result chunks rather than disappearing into controller flow. Memory interactions are similarly bounded, with recall and commit operations exposed as visible runtime events that update the session record.

In multi-agent and multi-session designs, the framework maintains a consistent boundary. Agents act as reusable layers, workflows serve as reusable compositions, and the moving runtime value remains Session. This prevents the introduction of hidden message buses or controller-only traces when scaling from single-agent scripts to nested agent teams. The engineering contract ensures that handoffs, routing, and composition rely entirely on reading and returning Session state, preserving deterministic lineage export, local sandbox packets, and workflow transcripts across complex, multi-agent workflows.
Experiment
The evaluation substantiates a Session-centered runtime object for a narrow set of claims using deterministic evidence, establishing clear scope boundaries for the technical report. These qualitative findings separate implemented runtime semantics from optional integrations, unverified features like broad benchmark superiority or local-memory verification, and unaddressed safety risks. The framework mandates rigorous supporting evidence before any boundary expands, ensuring that all reported claims remain tightly aligned with documented artifacts.