Command Palette
Search for a command to run...
静的リーダーボードを超えて:LLM agentsの評価における予測妥当性
静的リーダーボードを超えて:LLM agentsの評価における予測妥当性
概要
agentベンチマークは急速に拡大しているが、デプロイメントが露呈する次元のうち、単一のベンチマークがカバーするのは4〜5次元に過ぎない。本論文は、これまでにないMCPベースの産業用agentベンチマークに対する最大規模の協調的詳細分析を統合する。これは、新しいアセットクラス(マルチモーダル視覚拡張を含む)、代替オーケストレーション、検索戦略、推論モード、インフラストラクチャ最適化、および評価手法プローブをカバーする14の並列実装研究から構成される。これらの研究を7つの既存のagentベンチマークと統合し、集計スコアに基づくリーダーボードはデプロイ済みagentの評価を系統的に詳細指定が不足している状態にしていると主張する。集計スコアから導出される順位は分布外設定へ移行しない。最近の公開コンペティションから非公開コンペティションへの移行に関する回顧分析は、この順位の変動性に対する直接的な実証的証拠を提供している。我々は、サンプル内平均ではなく、予測妥当性(サンプル内ランクとサンプル外ランクの相関)に基づいて構成をランク付けすることを提案し、HELMおよびそのagent時代後継が単純化して見落としてしまうデプロイメント関連の次元を可視化する12段階の測定装置を報告する。この立場は、明示的な閾値を伴う3つの反証可能な分布外基準を通じて操作化される。既存の証拠はこれを部分的に支持しているが、確認するには不十分である。最後に、事前登録されたパイロット設計と、次世代のagent型ベンチマークが報告すべき事項に関する分野全体のビジョンを提示して締めくくる。
One-sentence Summary
Instead of relying on static aggregate scores, this paper evaluates LLM agents by predictive validity, the correlation between in-sample and out-of-sample rank, and operationalizes this approach through a twelve-tier measurement apparatus and three falsifiable out-of-distribution criteria with explicit thresholds to capture deployment-relevant performance.
Key Contributions
- The paper aggregates fourteen parallel implementation studies of an MCP-based industrial agent benchmark to systematically evaluate diverse architectural configurations, retrieval strategies, and reasoning modes across multiple asset classes.
- It proposes a predictive validity ranking framework that replaces aggregate score leaderboards with a criterion measuring the correlation between in-sample and out-of-sample performance to address rank instability under distributional shifts.
- The work introduces a twelve-tier measurement apparatus that isolates deployment-relevant evaluation dimensions previously collapsed by existing benchmarks, supported by cross-benchmark rank correlation analyses and public-to-hidden competition retrospectives.
Introduction
As large language model agents transition into high-stakes deployment environments like industrial asset operations, reliable evaluation becomes essential for ensuring operational safety and resource efficiency. Current benchmarks struggle with this transition because they rely on aggregate scores that collapse orthogonal deployment dimensions such as multi-turn artifact reuse, retrieval latency, and tool-call hygiene. These single-metric leaderboards exhibit severe rank instability, failing to predict how systems will perform on out-of-distribution tasks, while heavy reliance on LLM-as-judge scoring introduces subjective bias and measurement drift without independent verification. The authors leverage these limitations to propose predictive validity as a new ranking criterion, prioritizing the correlation between in-sample and out-of-sample performance over raw in-sample means. By consolidating seven established benchmarks and fourteen parallel implementation studies, they introduce a twelve-tier measurement apparatus that surfaces deployment-critical dimensions and outline three falsifiable criteria to rigorously test rank stability across distributional shifts.
Dataset
-
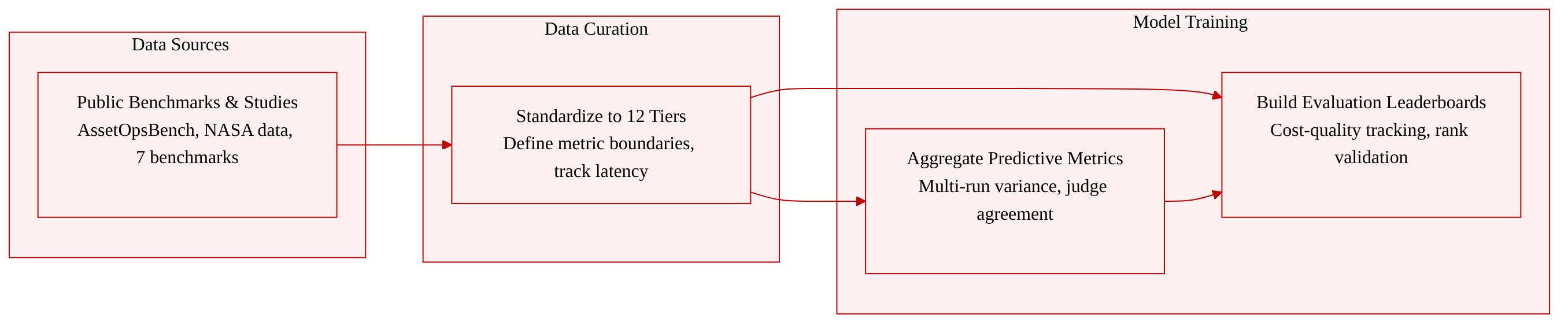
Dataset Composition and Sources: The authors do not release a single training corpus. Instead, they compile an evaluation framework synthesized from seven established benchmarks and fourteen parallel implementation studies. The primary data sources include the publicly released AssetOpsBench dataset, NASA PCOE Li-ion cycling data, and open evaluation suites such as ARE, Gaia2, MCP-Bench, TaskBench, MCP-Universe, SmartGridBench, and PHMForge. All materials rely on synthetic or publicly available industrial data, with no human subjects or sensitive deployment traces involved.
-
Subset Details: The compiled data is organized into twelve orthogonal measurement tiers. Tiers one through seven consolidate metrics from prior benchmarks, covering headline pass rates, tool-call hygiene, planning quality, capability axes, cost efficiency, failure modes, and reproducibility. Tiers eight through twelve emerge from deployment-focused implementation studies, addressing infrastructure overhead, multi-turn dialog dynamics, reasoning adaptivity, knowledge augmentation, and judge-independent evidence grounding. Each tier explicitly maps to specific source benchmarks, such as leveraging MCP-Bench for tool validation and TaskBench for decomposition scoring.
-
Usage in the Model: The authors apply this synthesized data exclusively for model evaluation and leaderboard construction rather than training. They aggregate metrics across the twelve tiers to measure predictive validity and expose the gap between current scoring practices and the underlying measurement space. The framework is designed to prevent systematic over-trusting of rankings by tracking cost-quality Pareto positions, multi-run variance, and judge-human agreement rates.
-
Processing and Framework Construction: The authors bypass traditional cropping and metadata construction. Instead, they standardize diverse evaluation outputs into a unified tiered apparatus by defining clear metric boundaries, such as uninformative pass-rate floors and dependency-order correctness checks. They track operational details like latency decomposition, step counts, and context-bloat trade-offs while maintaining reference adversarial-perturbation suites as community artifacts. The orthogonality of the twelve dimensions is treated as a working hypothesis validated through empirical testing in subsequent research.
Method
The authors introduce AssetOpsBench, a comprehensive evaluation framework designed to assess the predictive validity of LLM agents in industrial operations. Rather than relying on single-shot benchmarks, the framework extends a base agent across six distinct axes to capture the multidimensional nature of real-world deployment. As shown in the framework diagram below:
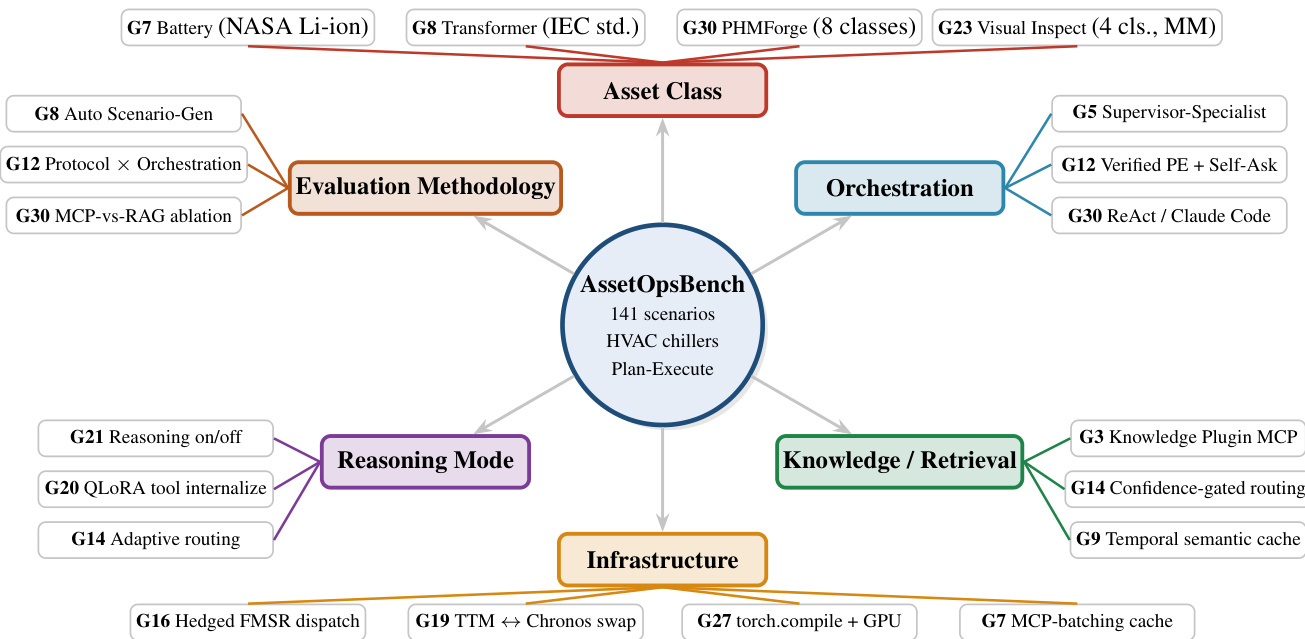
The central component represents the base benchmark, comprising 141 scenarios focused on HVAC chillers. The framework branches into six operationalization axes. The Asset Class axis tests generalization across different equipment types, such as batteries, transformers, and visual inspection tasks. Evaluation Methodology explores different testing protocols, including automated scenario generation and protocol versus orchestration comparisons. Orchestration examines agent architectures like supervisor-specialist setups or verified plan-execute loops. Knowledge and Retrieval investigates strategies such as knowledge plugins, confidence-gated routing, and temporal semantic caching. Reasoning Mode evaluates the impact of reasoning capabilities, including QLoRA internalization and adaptive routing. Finally, Infrastructure addresses system-level factors like hedged dispatch, model swapping, and persistent server modes to reduce latency.
To evaluate agents within this framework, the authors propose a rigorous methodology based on three operationalizations of Out-of-Distribution (OOD) shift. The first criterion, Held-Out Scenarios, involves a stratified random split to test if performance on a sample predicts performance on the full population. The second criterion, Cross-Subset Transfer, assesses moderate shift by ranking agents on k−1 subsets and testing them on the held-out subset, creating a rank-stability matrix across asset classes. The third criterion, Adversarial Perturbation, applies the strongest shift by generating semantically equivalent paraphrases, renaming identifiers, shifting time windows, and injecting distractors to test robustness.
The core of the evaluation method is the Predictive-Validity Score (PV), a composite metric designed to rank agents based on their generalization reliability rather than just in-sample performance. The score is calculated as:
PV(c)=αYˉc−βσYc,OOD−γIQR(Yc)
In this equation, Yˉc represents the in-sample mean performance. The term σYc,OOD captures the cross-OOD-criterion standard deviation of rank positions, penalizing agents whose performance fluctuates significantly across different OOD criteria. The term IQR(Yc) represents the interquartile range of per-scenario scores, penalizing high variance. The weights α,β,γ are fitted to maximize the Spearman correlation between the PV rank and the ranks derived from the OOD criteria.
The authors also specify a structured approach for reporting these results through a proposed leaderboard design. This design mandates declared configuration columns to attribute performance to specific architectural choices, such as reasoning mode or retrieval strategy. It further recommends a layered presentation, starting with a headline table of PV ranks, followed by cost-Pareto plots and drill-down panels to expose deployment-relevant dimensions. This ensures that rankings are not conflated by varying transport or orchestration methods, providing a more accurate reflection of agent capabilities in production environments.
Experiment
The evaluation setup synthesizes findings from fourteen independent implementation studies that employ controlled ablations and cross-model comparisons to assess ranking stability, reasoning modes, knowledge augmentation strategies, and evaluation methodologies. Qualitative results indicate that extended reasoning enhances clarity but introduces latency without uniformly improving task correctness, while knowledge retrieval approaches reveal distinct accuracy-speed trade-offs that necessitate deployment-aware reporting. Additional experiments demonstrate that LLM-as-judge scoring requires external anchors to ensure reliability and that system performance is predominantly constrained by substrate specifications and orchestration limitations rather than raw model capability. Together, these convergent findings validate the need for a multi-dimensional evaluation framework that captures architectural trade-offs, judge independence, and deployment-specific constraints.
The authors present findings from fourteen implementation studies of MCP-based industrial agents, grouped by the specific extension axis they address. The results reveal convergent architectural sensitivities, showing that performance improvements vary significantly depending on whether the intervention targets knowledge retrieval, orchestration, or infrastructure. The studies collectively indicate that current baselines often suffer from inefficiencies in protocol overhead and caching, and that evaluation metrics must account for these underlying structural factors. Agentic knowledge retrieval methods achieve substantially higher accuracy than standard retrieval-augmented generation, despite requiring more computational resources. Optimizing orchestration and infrastructure components, such as through better caching or dispatch strategies, leads to significant reductions in latency and execution time. Enabling extended reasoning capabilities enhances output clarity and reduces hallucinations, though it introduces a trade-off with increased processing time.
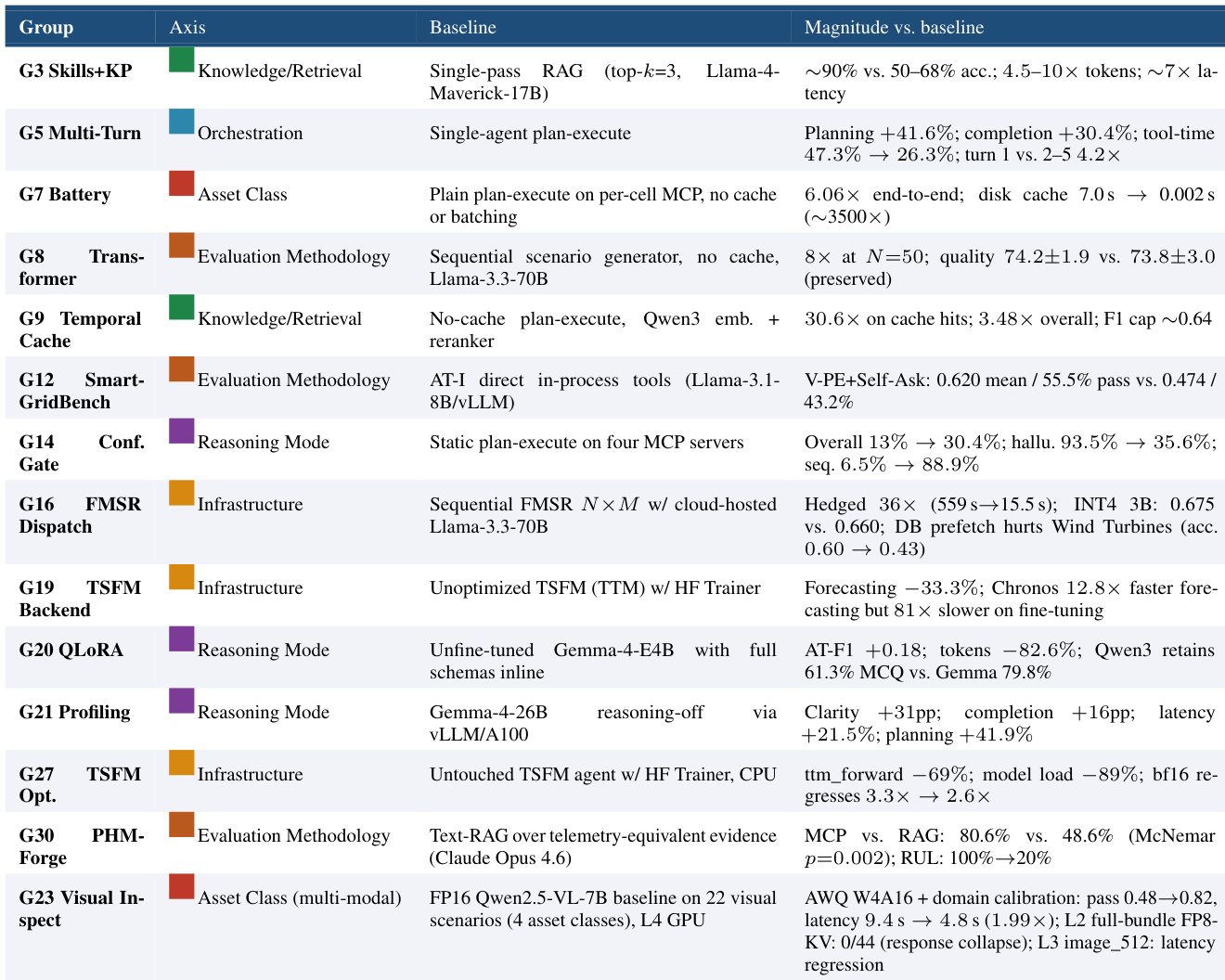
Based on fourteen implementation studies of MCP-based industrial agents, the experiments validate how distinct architectural extensions influence system performance, efficiency, and output quality. The findings demonstrate that performance gains are highly dependent on the targeted intervention, with knowledge retrieval methods yielding superior accuracy at the expense of higher computational demands. Meanwhile, optimizing orchestration and infrastructure components substantially reduces latency, while extended reasoning capabilities improve output clarity and minimize hallucinations despite increasing processing time. Collectively, these results highlight persistent baseline inefficiencies in protocol overhead and caching, underscoring the necessity for evaluation frameworks that account for underlying structural factors.