Command Palette
Search for a command to run...
シンプルさによる高速化:音声・動画生成基盤モデルのための単一ストリームアーキテクチャ
シンプルさによる高速化:音声・動画生成基盤モデルのための単一ストリームアーキテクチャ
概要
私たちは、人間中心の生成に特化したオープンソースのオーディオ・ビデオ生成基盤モデル「daVinci-MagiHuman」を提案します。daVinci-MagiHuman は、テキスト、ビデオ、オーディオを単一のトークン系列として統合し、自己注意のみを用いて処理するシングルストリーム Transformer により、同期されたビデオとオーディオを共同生成します。このシングルストリーム設計は、マルチストリームまたはクロスアテンションアーキテクチャの複雑さを回避しつつ、標準的なトレーニングおよび推論インフラストラクチャを用いた最適化を容易に実現します。本モデルは、特に人間中心のシナリオにおいて顕著な性能を発揮し、表情豊かな顔の演技、自然な音声と表情の協調、リアルな身体運動、そして精密なオーディオ・ビデオ同期を実現します。また、中国語(普通話および広東語)、英語、日本語、韓国語、ドイツ語、フランス語にわたる多言語の音声生成をサポートします。効率的な推論のため、シングルストリームバックボーンにモデル蒸留、潜在空間スーパー解像度、および Turbo VAE デコーダを組み込むことで、単一の H100 GPU 上で 2 秒以内に 256p の 5 秒間ビデオを生成可能としています。自動評価においては、daVinci-MagiHuman は主要なオープンモデルの中で最高レベルの視覚品質とテキスト整合性を達成し、音声明瞭度に関する単語誤り率(WER)も 14.60% と最低値を記録しました。人間によるペア比較評価では、2000 回の比較において Ovi 1.1 に対して 80.0%、LTX 2.3 に対して 60.9% の勝利率を達成しました。私たちは、ベースモデル、蒸留済みモデル、スーパー解像度モデル、および推論コードベースを含む完全なモデルスタックをオープンソース化しました。
One-sentence Summary
SII-GAIR and Sand.ai introduce daVinci-MagiHuman, an open-source audio-video foundation model that uses a single-stream Transformer to generate synchronized human-centric content without complex cross-attention. This approach enables efficient multilingual speech and motion synthesis, achieving superior visual quality and speech intelligibility compared to leading open models.
Key Contributions
- The paper introduces daVinci-MagiHuman, an open-source audio-video generative foundation model that utilizes a single-stream Transformer to process text, video, and audio within a unified token sequence via self-attention only, avoiding the complexity of multi-stream or cross-attention architectures.
- This work demonstrates strong human-centric generation capabilities, including expressive facial performance and precise audio-video synchronization, while supporting multilingual spoken generation across six major languages and achieving a 14.60% word error rate in automatic evaluations.
- The authors present an efficient inference pipeline combining model distillation, latent-space super-resolution, and a Turbo VAE decoder to generate a 5-second 256p video in 2 seconds on a single H100 GPU, alongside a fully open-source release of the complete model stack and codebase.
Introduction
Video generation is rapidly evolving toward synchronized audio-video synthesis, yet open-source solutions struggle to balance high-quality output, multilingual support, and inference efficiency within a scalable architecture. Existing open models often rely on complex multi-stream designs that are difficult to optimize jointly with training and inference infrastructure. The authors introduce daVinci-MagiHuman, an open-source model that leverages a single-stream Transformer to unify text, video, and audio processing within a shared-weight backbone. This simplified approach enables fast inference through latent-space super-resolution while delivering strong human-centric generation quality and broad multilingual capabilities across languages like English, Chinese, and Japanese.
Method
The authors propose daVinci-MagiHuman, which centers on a single-stream Transformer architecture designed to jointly generate synchronized video and audio. Unlike dual-stream approaches that process modalities separately, this model represents text, video, and audio tokens within a unified sequence processed via self-attention only. This design avoids the complexity of cross-attention modules while remaining easy to optimize with standard infrastructure.
As shown in the figure below:
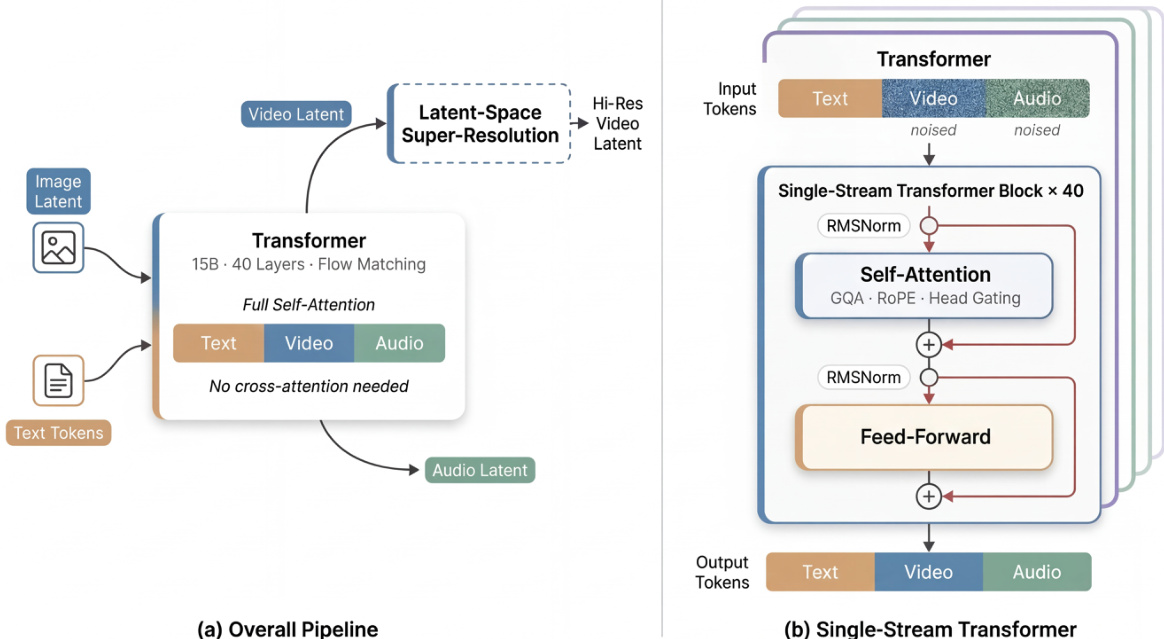
The base generator accepts text tokens, a reference image latent, and noisy video and audio tokens. It jointly denoises the video and audio tokens using a 15B-parameter, 40-layer Transformer. A latent-space super-resolution stage can subsequently refine the generated video at higher resolutions. The internal architecture adopts a sandwich structure where the first and last 4 layers utilize modality-specific projections and normalization parameters, while the middle 32 layers share parameters across all modalities. This design preserves modality sensitivity at the boundaries while enabling deep multimodal fusion in the shared representation space.
Several key mechanisms enhance the model's performance and stability. The system employs timestep-free denoising, inferring the denoising state directly from the noisy inputs rather than using explicit timestep embeddings. Additionally, the model incorporates per-head gating within the attention blocks. For each attention head h, a learned scalar gate modulates the output oh via a sigmoid function σ, resulting in a gated output:
o~h=σ(qh)ohThis improves numerical stability and representability with minimal overhead.
To ensure efficient inference, the authors integrate several complementary techniques. Latent-space super-resolution allows the base model to generate at a lower resolution before refining in latent space, avoiding expensive pixel-space operations. A Turbo VAE decoder replaces the standard decoder to reduce overhead on the critical path. Furthermore, full-graph compilation via MagiCompiler fuses operators across layer boundaries, and model distillation using DMD-2 reduces the required denoising steps to 8 without classifier-free guidance.
Experiment
- Quantitative benchmarks on VerseBench and TalkVid-Bench validate that daVinci-MagiHuman achieves superior visual quality, text alignment, and speech intelligibility compared to Ovi 1.1 and LTX 2.3, while maintaining competitive physical consistency.
- Pairwise human evaluations confirm a strong preference for daVinci-MagiHuman over both baselines, with raters favoring its overall audio-video quality, synchronization, and naturalness in the majority of comparisons.
- Inference efficiency tests demonstrate that the pipeline generates high-resolution 1080p videos in under 40 seconds on a single H100 GPU, utilizing a distilled base stage and Turbo VAE decoder to balance speed and output quality.