Command Palette
Search for a command to run...
RealRestorer: Large-Scale Image Editing Models による汎用性のある実世界画像復元への挑戦
RealRestorer: Large-Scale Image Editing Models による汎用性のある実世界画像復元への挑戦
概要
現実世界の劣化下での画像復元は、自動運転や物体検出などの下流タスクにとって極めて重要です。しかし、既存の復元モデルは、訓練データの規模と分布に制約され、現実世界のシナリオへの汎化性能が不十分であるという課題を抱えています。近年、大規模な画像編集モデルは復元タスクにおいて優れた汎化能力を示しており、特に Nano Banana Pro のようなクローズドソースモデルは、画像の復元と一貫性の維持を両立させています。もっとも、そのような大規模汎用モデルで同等の性能を達成するには、膨大なデータと計算コストが必要です。この課題に対処するため、本研究では 9 種類の代表的な現実世界の劣化タイプを網羅する大規模データセットを構築し、最先端のオープンソースモデルを訓練することで、クローズドソースモデルとの性能格差を縮小しました。さらに、劣化除去と一貫性維持に焦点を当てた 464 枚の現実世界劣化画像と専用評価指標を含む RealIR-Bench を新たに導入しました。広範な実験により、提案モデルはオープンソース手法の中で首位に立ち、最先端(state-of-the-art)の性能を達成することが実証されました。
One-sentence Summary
Researchers from StepFun and Southern University of Science and Technology propose RealRestorer, an open-source model trained on a new large-scale dataset to restore diverse real-world image degradations. This approach narrows the performance gap with closed-source alternatives while introducing RealIR-Bench for rigorous evaluation in autonomous driving and object detection.
Key Contributions
- The paper introduces RealRestorer, an open-source image restoration model fine-tuned from a large image editing architecture to handle nine common real-world degradation types while achieving state-of-the-art performance comparable to closed-source systems.
- A comprehensive data generation pipeline is developed to synthesize high-quality training data with diverse and representative degradations, effectively narrowing the gap between synthetic distributions and real-world conditions.
- RealIR-Bench is presented as a new benchmark containing 464 real-world degraded images and tailored evaluation metrics to assess both degradation removal and consistency preservation in authentic scenarios.
Introduction
Real-world image restoration is essential for critical downstream applications like autonomous driving and object detection, yet existing models struggle to generalize because they rely on limited synthetic training data that fails to capture the complexity of real-world degradations. While large-scale closed-source image editing models demonstrate superior performance, their high computational costs and lack of transparency hinder reproducibility and broader research adoption. To address these challenges, the authors leverage a comprehensive data synthesis pipeline to train RealRestorer, an open-source model that fine-tunes large image editing architectures to achieve state-of-the-art results across nine degradation types. They further introduce RealIR-Bench, a new benchmark featuring authentic degraded images and tailored metrics to better evaluate restoration quality and content consistency without relying on clean references.
Dataset
-
Dataset Composition and Sources The authors construct a comprehensive dataset for nine image restoration tasks by combining two primary sources: Synthetic Degradation Data and Real-World Degradation Data. The synthetic component leverages clean images collected from the internet, while the real-world component sources naturally degraded images from web platforms and high-quality open-source sites like Pexels and Pinterest.
-
Key Details for Each Subset
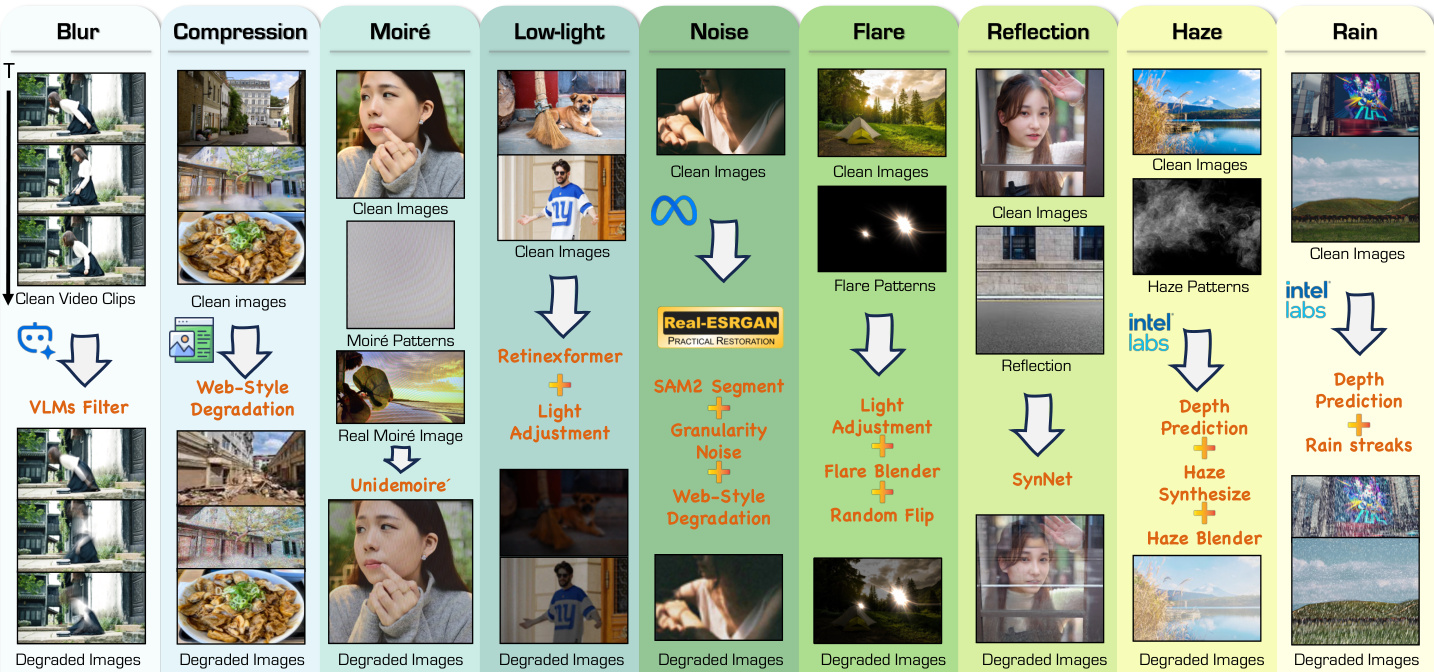
- Synthetic Degradation Data: This subset generates paired data by applying specific degradation models to clean images. The authors utilize open-source models like SAM-2 and MiDaS to extract semantic masks and depth cues for realistic synthesis.
- Blur: Synthesized via temporal averaging of video clips and web-style operations like Gaussian blur.
- Compression Artifacts: Simulated using JPEG compression and resizing to mimic web effects.
- Moiré Patterns: Created by fusing 3,000 generated patterns at multiple scales into clean images.
- Low-Light: Achieved through brightness attenuation, gamma correction, and a specialized model trained on LOL and LSRW datasets.
- Noise: Uses web-style degradation with added granular and segment-aware noise.
- Flare: Involves blending over 3,000 collected glare patterns with random flipping.
- Reflection: Combines portrait images as transmission layers with diverse scenes as reflection layers, following the SynNet pipeline.
- Haze: Generated using the atmospheric scattering model enhanced with nearly 200 collected haze patterns.
- Rain: Incorporates physical effects like splashes and perspective distortion alongside 200 real rain patterns and 70K samples from the FoundIR dataset.
- Real-World Degradation Data: This subset pairs real degraded images with clean references generated by high-performance restoration models. It covers six degradation types (blur, rain, low light, haze, reflection, and flare) that exhibit significant gaps compared to synthetic patterns.
- Synthetic Degradation Data: This subset generates paired data by applying specific degradation models to clean images. The authors utilize open-source models like SAM-2 and MiDaS to extract semantic masks and depth cues for realistic synthesis.
-
Data Usage and Processing The authors employ a rigorous filtering pipeline to ensure data quality and alignment.
- Filtering: Vision-Language Models (VLMs) and quality assessment models remove watermarked or low-quality images. CLIP filters real-world data based on semantic cues, while Qwen3-VL-8B-Instruct verifies degradation severity.
- Alignment Checks: The team uses low-level metrics and skeleton-shift-based methods to detect content shifts and alignment errors between degraded and clean pairs.
- Human Curation: A subset of filtered pairs undergoes manual review by three experts to confirm degradation type and severity alignment.
- Training Mixture: The final training set combines both synthetic and real-world pairs, with specific statistics provided per degradation type to balance the dataset.
-
Benchmark and Evaluation The authors introduce RealIR-Bench, a test set containing 464 non-reference degraded images sourced directly from the internet. This benchmark covers all nine restoration tasks and includes complex mixed degradations. Evaluation uses a fixed enhancement instruction to minimize instruction variation, focusing on restoration capability and scene consistency. Quality is assessed using metrics like LPIPS, RS, and FS, alongside human-rated scores for enhancement capability and overall visual quality.
Method
The proposed method is built upon the Step1X-Edit base model, which utilizes a Diffusion in Transformer (DiT) backbone effective for generation tasks. The architecture incorporates QwenVL as a text encoder to inject high-level semantic extraction into the DiT denoising pathway. Within the diffusion network, a dual-stream design is employed to jointly process semantic information along with noise and the conditional input image. Both the reference image and the output image are encoded into latent space using Flux-VAE. During the training phase, the Flux-VAE and text encoder are frozen, while only the DiT component is fine-tuned.
The training strategy is divided into two distinct stages to optimize restoration performance. The first stage is a Transfer-training phase designed to transfer high-level knowledge and priors from image editing to image restoration using synthetic paired data. This stage operates at a high resolution of 1024×1024 with a constant learning rate of 1e−5 and a global batch size of 16. To ensure broad generalization, single and fixed prompts are adopted for each of the nine degradation tasks, and an average sampling ratio is used for multi-task learning.
The second stage involves Supervised Fine-tuning to enhance restoration fidelity and generalization under real-world degradation scenarios. This stage emphasizes adaptation to complex and authentic degradation patterns using a cosine annealing learning rate schedule. A Progressively-Mixed training strategy is adopted, which retains a small proportion of synthetic paired samples alongside real-world data to prevent overfitting and preserve cross-task robustness. Additionally, a web-style degradation data augmentation strategy is introduced to improve robustness against images collected from the web, which often suffer from low visual quality and compression artifacts.
The pipeline addresses nine specific degradation types: blur, compression artifacts, moiré patterns, low-light, noise, flare, reflection, haze, and rain. As shown in the figure below, the data generation process for these diverse degradations involves specific processing steps such as VLMs filtering, Retinexformer for low-light adjustment, and Real-ESRGAN for noise simulation, ultimately producing the degraded images used for training.
Experiment
- RealIR-Bench evaluation validates that RealRestorer effectively removes diverse real-world degradations while preserving content fidelity, ranking first among open-source models and closely trailing top closed-source systems across nine tasks including deblurring, low-light enhancement, and reflection removal.
- FoundIR benchmark testing confirms the model achieves superior performance on isolated degradation tasks compared to other image editing models, demonstrating a strong balance between restoration quality and perceptual consistency despite the inherent limitations of generative approaches on reference-based metrics.
- Zero-shot generalization experiments show the model successfully handles unseen restoration scenarios like snow removal and old photo restoration by leveraging learned priors without specific fine-tuning.
- Ablation studies establish that a two-stage training strategy combining synthetic and real-world data is essential, as it prevents overfitting and artifacts while ensuring robust generalization and structural consistency.
- User studies and metric correlation analysis verify that the proposed non-reference evaluation framework aligns well with human judgment, confirming the model's ability to produce visually stable and coherent results.