Command Palette
Search for a command to run...
静的テンプレートから動的ランタイムグラフへ:LLM Agents 向けワークフロー最適化に関するsurvey
静的テンプレートから動的ランタイムグラフへ:LLM Agents 向けワークフロー最適化に関するsurvey
Ling Yue Kushal Raj Bhandari Ching-Yun Ko Dhaval Patel Shuxin Lin Nianjun Zhou Jianxi Gao Pin-Yu Chen Shaowu Pan
概要
大規模言語モデル(LLM)を基盤としたシステムは、LLM の呼び出し、情報検索、ツール利用、コード実行、メモリ更新、検証を交差させる実行可能なワークフローを構築することでタスクを解決する手法として、その普及が進んでいる。本調査論文では、これらのワークフローを「エージェント型計算グラフ(Agentic Computation Graphs: ACGs)」として捉え、その設計と最適化に関する最近の手法をレビューする。本稿では、ワークフロー構造が決定される時点に基づいて文献を整理する。ここでいう「構造」とは、どのコンポーネントやエージェントが存在するか、それらがどのように相互に依存するか、そして情報がいかに伝達されるかを指す。この視座により、デプロイ前に再利用可能なワークフローの骨格を固定する「静的手法」と、実行前または実行中に特定の実行に合わせてワークフローを選択・生成・修正する「動的手法」を区別する。さらに、先行研究を以下の 3 つの次元に沿って分類する。(1) 構造が決定される時点、(2) ワークフローのどの部分が最適化の対象となるか、(3) 最適化を導く評価シグナルは何か(タスク指標、検証シグナル、嗜好、あるいはトレースから導出されるフィードバックなど)。また、再利用可能なワークフローテンプレート、実行固有に実現されたグラフ、および実行トレースを明確に区別し、再利用可能な設計選択と、特定の実行において実際に展開された構造、ならびに実現されたランタイム挙動を分離する。最後に、下流タスクの指標に加え、グラフレベルの特性、実行コスト、頑健性、入力に対する構造的変動を補完する「構造を考慮した評価」の視点を提示する。本稿の目的は、LLM エージェントにおけるワークフロー最適化に関する将来の研究に対して、明確な用語体系、新手法の位置付けを可能にする統一フレームワーク、既存文献のより比較可能な視点、および再現性の高い評価基準を提供することにある。
One-sentence Summary
Researchers from Rensselaer Polytechnic Institute and IBM Research propose a unified framework for agentic computation graphs, distinguishing static and dynamic workflow structures to optimize LLM agent systems. This survey introduces a structure-aware evaluation perspective that enhances reproducibility and clarifies design choices for complex, tool-intelligent workflows.
Key Contributions
- The paper introduces agentic computation graphs (ACGs) as a unifying abstraction for executable LLM workflows, distinguishing between static methods that fix scaffolds before deployment and dynamic methods that generate or revise structures during execution.
- A three-dimensional taxonomy is presented to organize existing literature based on when structure is determined, which workflow components are optimized, and the specific evaluation signals that guide the optimization process.
- A structure-aware evaluation perspective is outlined that complements downstream task metrics with graph-level properties, execution cost, robustness, and structural variation to establish a more reproducible standard for future research.
Introduction
Large language model (LLM) systems are evolving from simple chatbots into complex agentic computation graphs that coordinate tools, code execution, and verification to solve tasks. The overall workflow structure, which dictates component dependencies and information flow, often determines system effectiveness and cost more than individual model capabilities alone. However, prior research and surveys have largely treated workflow design as a fixed implementation detail or focused on adjacent topics like tool selection and agent collaboration, leaving the optimization of the workflow structure itself as a first-class object largely unaddressed. To fill this gap, the authors introduce a unified framework that treats workflows as agentic computation graphs and categorizes methods based on when the structure is determined, ranging from static offline template search to dynamic runtime generation and editing. They further synthesize the literature across optimization targets, feedback signals, and update mechanisms while proposing a new evaluation protocol that separates downstream task metrics from graph-level properties and execution costs.
Dataset
The provided text does not contain a dataset description. It is an appendix section (42. A.1) that catalogs supporting materials such as tables for node-level prompt optimizers, adjacent routing methods, and background frameworks. Consequently, there is no information available regarding dataset composition, sources, subset details, training splits, or data processing strategies to include in the blog post.
Method
The authors introduce the Agentic Computation Graph (ACG) as a unifying abstraction for executable LLM-centered workflows. In this framework, nodes perform atomic actions such as LLM calls, information retrieval, or tool use, while edges encode control, data, or communication dependencies. The overall optimization process follows a cycle where a task input is mapped to an ACG, which is then instantiated as a reusable template. This template is executed to produce a trace, which is subsequently analyzed to optimize, observe, and refine the workflow before deployment.
As shown in the figure below:
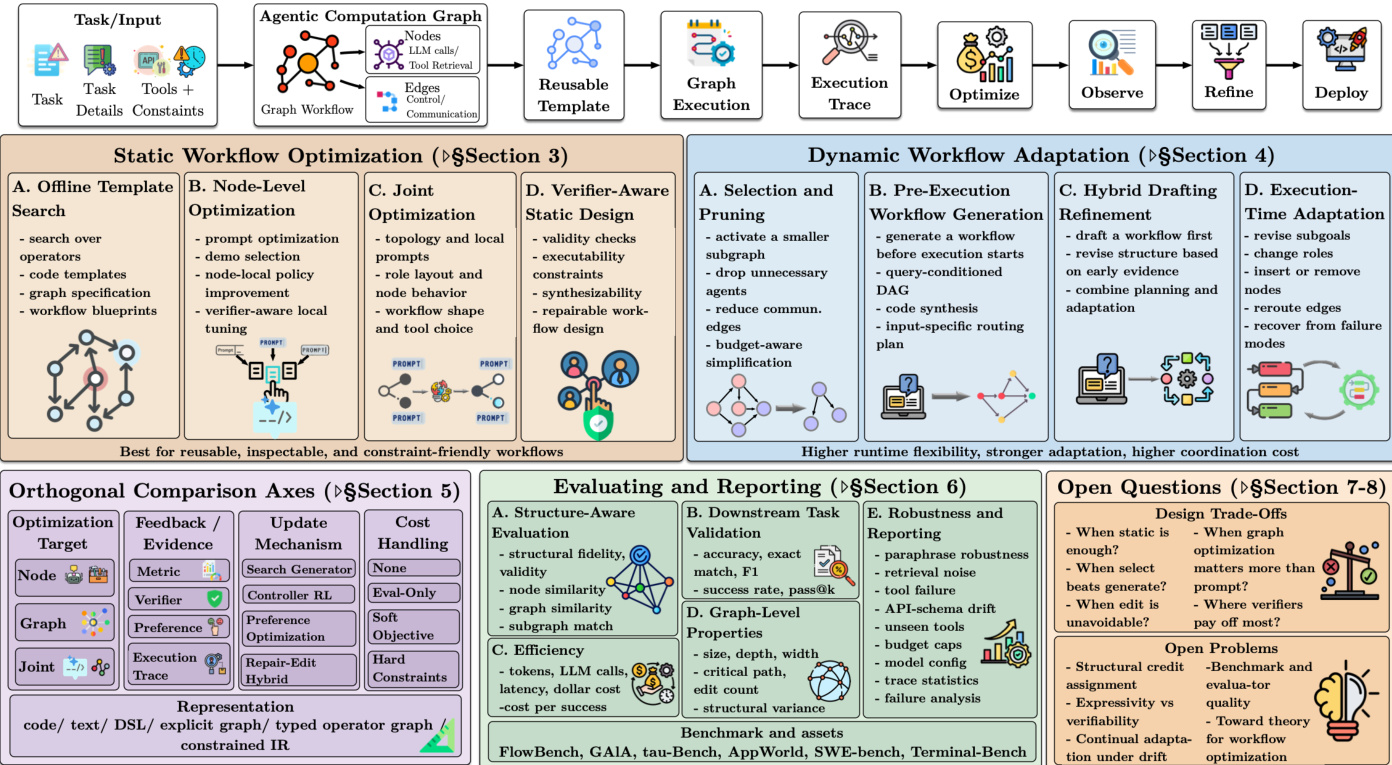
The framework distinguishes between three key objects: the ACG template, the realized graph, and the execution trace. The template is a reusable executable specification defined as Gˉ=(V,E,Φ,Σ,A), where V and E represent nodes and edges, Φ contains node parameters like prompts and tools, Σ is the scheduling policy, and A defines admissible actions. The realized graph Grun is the specific structure actually used for a particular run, which may differ from the template through selection or editing. The execution trace τ={(st,at,ot,ct)}t=1T records the sequence of states, actions, observations, and costs produced during execution.
Workflow optimization methods are categorized based on when the structure is determined. Static methods optimize a reusable template before deployment, focusing on offline template search, node-level optimization, or joint optimization of structure and local configuration. Dynamic methods determine part of the workflow at inference time, allowing for runtime adaptation. This includes selection and pruning of a fixed super-graph, pre-execution workflow generation based on query difficulty, or in-execution editing where the structure is revised during execution in response to feedback. The optimization objective generally balances task quality R(τ;x) against execution cost C(τ), formulated as maximizing E[R(τ;x)−λC(τ)].
The framework also outlines orthogonal comparison axes such as optimization target (node, graph, joint), feedback mechanisms (metric, verifier, preference), and update mechanisms (search generator, controller RL). Evaluation involves structure-aware assessment, downstream task validation, and efficiency metrics. Finally, the authors identify open questions regarding design trade-offs, such as when static optimization suffices versus when dynamic adaptation is necessary, and the role of verifiers in ensuring workflow validity.
Experiment
- A standardized classification card is used to compare methods across stable dimensions like structural settings, optimization levels, and update mechanisms, ensuring consistent evaluation rather than relying on paper-specific descriptions.
- Experiments validate that specific algorithm choices depend heavily on the available signals and evidence; for instance, search works best with trusted evaluators and discrete action spaces, while reinforcement learning suits sequential generation but requires careful reward design.
- Evaluation protocols are shown to require a separation between structure-aware assessment of workflow quality and downstream task validation to distinguish between plausible graph generation and actual task success.
- Studies demonstrate that reporting graph-level properties and robustness under perturbations, such as tool failures or schema drift, is essential to differentiate genuine structural improvements from brute-force compute or uncontrolled cost growth.