Command Palette
Search for a command to run...
Voxtral TTS
Voxtral TTS
概要
本稿では、3 秒程度の参照音声から自然な発話を生成する表現豊かな多言語テキスト音声合成モデル「Voxtral TTS」を提案する。Voxtral TTS は、意味音声トークンの自己回帰的生成と、音響トークンに対するフローマッチングを組み合わせたハイブリッドアーキテクチャを採用している。これらのトークンは、ハイブリッドな VQ-FSQ 量子化方式を用いてゼロから訓練された音声トークナイザー「Voxtral Codec」によってエンコードおよびデコードされる。ネイティブ話者による人間評価において、Voxtral TTS は自然性と表現力に優れ、多言語音声クローン化の用途において ElevenLabs Flash v2.5 に対して 68.4% の勝率を記録し、高い評価を得た。本モデルの重みは CC BY-NC ライセンス下で公開する。
One-sentence Summary
Mistral AI introduces Voxtral TTS, a multilingual text-to-speech model that leverages a hybrid architecture combining auto-regressive semantic token generation with flow-matching for acoustic tokens. This approach enables high-fidelity voice cloning from minimal audio references, outperforming ElevenLabs Flash v2.5 in human evaluations for naturalness and expressivity.
Key Contributions
- The paper introduces Voxtral TTS, a multilingual zero-shot text-to-speech model that utilizes a hybrid architecture combining auto-regressive generation for semantic tokens with flow-matching for acoustic tokens to balance long-range consistency and rich acoustic detail.
- A new speech tokenizer called Voxtral Codec is presented, which is trained from scratch using a hybrid VQ-FSQ quantization scheme to encode reference audio into low-bitrate semantic and acoustic token streams.
- Human evaluations demonstrate that the model achieves a 68.4% win rate over ElevenLabs Flash v2.5 in multilingual voice cloning tasks, while the authors release the model weights under a CC BY-NC license.
Introduction
Natural and expressive text-to-speech remains critical for applications like virtual assistants and accessibility tools, yet capturing human speech nuances in zero-shot settings remains difficult. Prior systems often rely on depth-wise autoregressive acoustic generation, which can limit efficiency and the richness of acoustic detail despite using factorized speech representations. The authors introduce Voxtral TTS, a multilingual zero-shot system that combines an autoregressive transformer for semantic tokens with a lightweight flow-matching model for acoustic tokens to improve both consistency and detail. They further adapt Direct Preference Optimization to this hybrid discrete-continuous setting, achieving superior speaker similarity and naturalness compared to leading proprietary models while supporting low-latency streaming.
Method
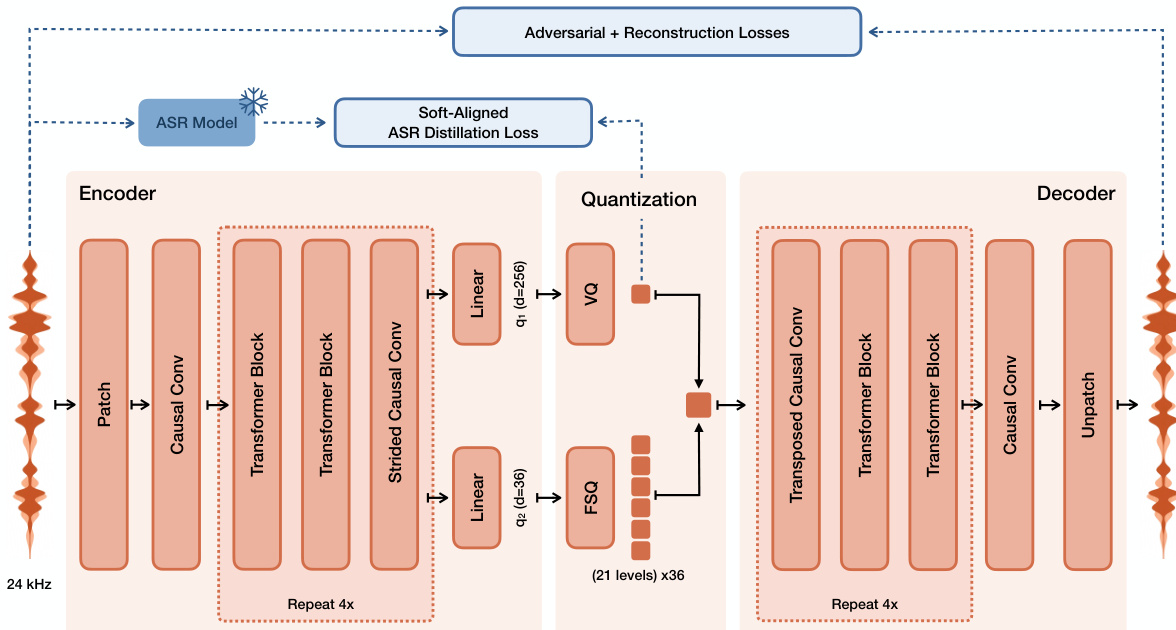
The authors introduce Voxtral TTS, which relies on a novel speech tokenizer called Voxtral Codec to discretize audio into semantic and acoustic tokens. The Codec architecture is detailed in the figure below. It processes 24 kHz mono waveforms through a convolutional-transformer encoder that projects input patches into embeddings. These embeddings pass through multiple blocks containing causal self-attention and causal CNN layers for downsampling. The resulting latent representation is split into a 256-dimensional semantic component and 36 acoustic dimensions, which are quantized independently. The semantic component uses Vector Quantization (VQ) with a codebook of size 8192, while the acoustic dimensions use Finite Scalar Quantization (FSQ) with 21 uniform levels. This hybrid scheme achieves a low bitrate of approximately 2.14 kbps. The decoder mirrors the encoder structure to reconstruct the waveform from these discrete tokens.
For the generation process, the authors leverage a hybrid architecture combining auto-regressive modeling with flow-matching. Refer to the framework diagram for the overall system layout. The input consists of voice reference audio tokens and text tokens fed into an autoregressive decoder backbone based on Ministral 3B. This backbone auto-regressively generates a sequence of semantic tokens. At each timestep, the hidden state from the backbone is passed to a flow-matching transformer to predict the corresponding acoustic tokens. The flow-matching transformer models the velocity field transporting Gaussian noise to the acoustic embedding space over a series of function evaluation steps. The semantic tokens are predicted via a linear head projecting hidden states to logits over the semantic vocabulary. Finally, the generated semantic and acoustic tokens are decoded into the final waveform by the Voxtral Codec decoder.
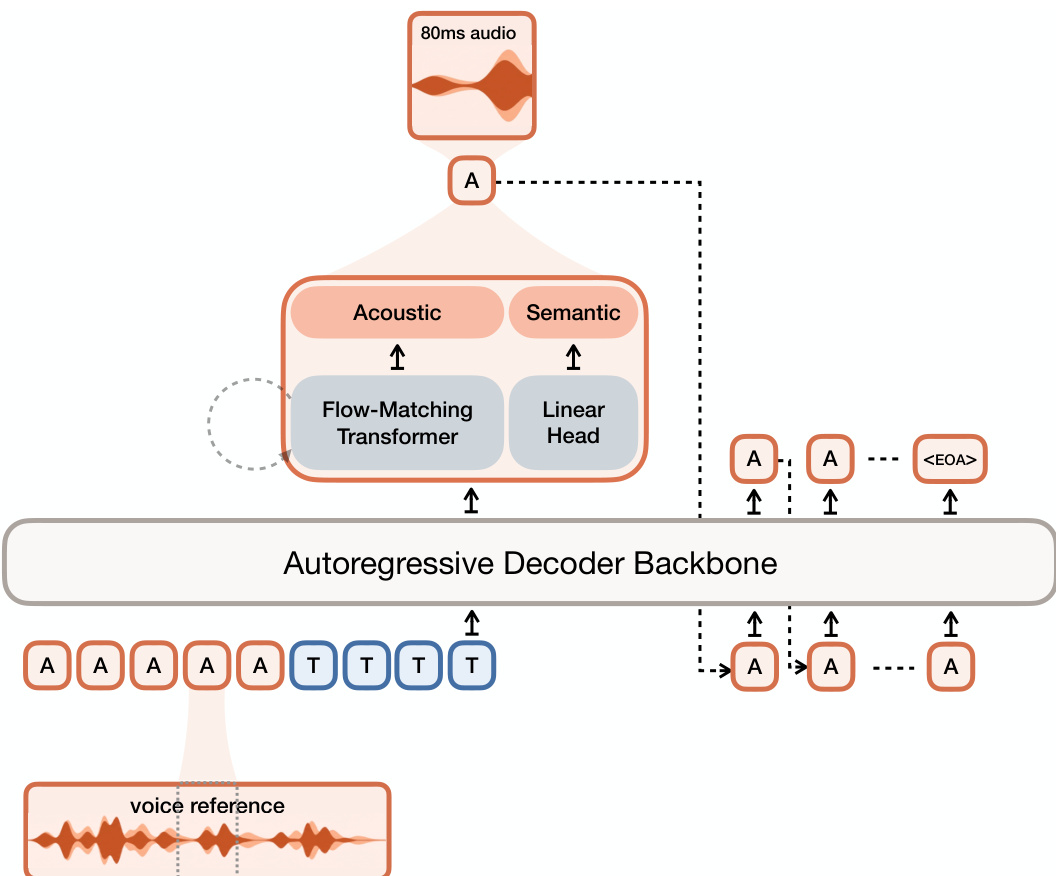
Training involves optimizing the codec with a combination of reconstruction losses, adversarial losses, and an auxiliary ASR distillation loss to align semantic tokens with text content. The TTS model is trained using a two-part loss function consisting of a cross-entropy loss on the semantic tokens and a flow-matching loss on the acoustic tokens. The flow-matching objective minimizes the difference between the predicted velocity field and the conditional velocity target derived from the data distribution and Gaussian noise.
Experiment
- Voxtral Codec outperforms Mimi across all objective metrics and matches or exceeds it in subjective speech quality when configured with similar bitrates.
- Automatic evaluations show Voxtral TTS significantly surpasses ElevenLabs models in speaker similarity, though ElevenLabs Flash v2.5 leads in some automated intelligibility and quality scores.
- Human evaluations reveal that while automated metrics like UTMOS poorly correlate with human preference, Voxtral TTS consistently outperforms competitors in implicit emotion steering and zero-shot voice cloning across diverse languages.
- Direct Preference Optimization (DPO) training reduces hallucinations and volume tapering while improving intelligibility and quality, with minimal impact on speaker similarity.
- Increasing inference steps to 8 and tuning CFG parameters balances quality and emotion adherence, with lower CFG values preferred for high-quality audio and higher values for in-the-wild recordings.
- CUDA graph acceleration reduces latency by 47% and improves real-time factor by 2.5x, enabling high-throughput serving that supports over 30 concurrent users with sub-second latency on a single GPU.