Command Palette
Search for a command to run...
UI-Voyager: 失敗経験を通じた自己進化型 GUI Agent
UI-Voyager: 失敗経験を通じた自己進化型 GUI Agent
概要
マルチモーダル大規模言語モデル(MLLMs)の進展に伴い、自律型モバイル GUI エージェントへの関心が高まっています。しかし、既存手法では、長期的な GUI タスクにおけるスパースな報酬下での失敗軌道からの非効率的な学習や、曖昧なクレジット割り当てが課題として残されています。そこで本研究では、UI-Voyager と呼ばれる新たな 2 段階の自己進化型モバイル GUI エージェントを提案します。第一段階では、Rejection Fine-Tuning(RFT)を採用し、データとモデルが自律的なループ内で継続的に共進化することを可能にします。第二段階では、Group Relative Self-Distillation(GRSD)を導入し、グループロールアウトにおける重要な分岐点を特定するとともに、成功軌道からステップレベルの密な教師信号を構築して失敗軌道を修正します。AndroidWorld における広範な実験により、本研究で提案する 4B パラメータモデルは 81.0% の Pass@1 成功率を達成し、多数の最近のベースラインを上回るだけでなく、人間レベルのパフォーマンスも超えることが示されました。アブレーション研究およびケーススタディにより、GRSD の有効性がさらに実証されました。本手法は、高価な手動データアノテーションを必要とせず、効率的かつ自己進化型で高性能なモバイル GUI 自動化を実現する重要な飛躍です。
One-sentence Summary
Tencent Hunyuan researchers propose UI-Voyager, a two-stage self-evolving mobile GUI agent that utilizes Rejection Fine-Tuning and Group Relative Self-Distillation to overcome sparse rewards in long-horizon tasks. This approach achieves human-level performance on AndroidWorld without expensive manual annotation, significantly advancing efficient mobile automation.
Key Contributions
- The paper introduces UI-Voyager, a two-stage self-evolving mobile GUI agent that automates the co-evolution of data and models through Rejection Fine-Tuning without requiring manual annotation.
- A Group Relative Self-Distillation method is presented to resolve ambiguous credit assignment by identifying critical fork points in group rollouts and generating dense step-level supervision from successful trajectories to correct failed ones.
- Experiments on the AndroidWorld benchmark demonstrate that the 4B model achieves an 81.0% Pass@1 success rate, outperforming recent baselines and exceeding reported human-level performance.
Introduction
Autonomous mobile GUI agents are critical for enabling AI to navigate complex, dynamic smartphone interfaces, yet current approaches struggle with data inefficiency and ambiguous credit assignment when learning from sparse, trajectory-level rewards. Prior methods often discard failed interaction attempts and lack the precision to identify which specific steps caused a task failure, hindering stable policy optimization for long-horizon tasks. To address these issues, the authors introduce UI-Voyager, a self-evolving agent that employs a two-stage pipeline combining Rejection Fine-Tuning for autonomous data-model co-evolution and Group Relative Self-Distillation to generate dense, step-level supervision from successful trajectories to correct failed ones.
Dataset
- The authors focus on the AndroidWorld environment, a dynamic interactive benchmark designed for training and evaluating GUI agents on mobile devices.
- The dataset consists of 116 diverse, programmatic tasks that vary in complexity and optimal interaction steps to challenge agent performance.
- Unlike static datasets, this environment allows actions to alter the UI state and provides reward signals upon successful task completion.
- The paper utilizes this setup to evaluate how well agents handle unpredictable UI behaviors and learn from trial-and-error rather than relying solely on pre-collected interaction logs.
- No specific training splits, mixture ratios, or image cropping strategies are detailed in the provided text, as the environment serves primarily as a rigorous evaluation benchmark.
Method
The authors propose UI-Voyager, a self-evolving training pipeline designed to optimize mobile GUI agents through a two-stage iterative process. The overall framework integrates Rejection Fine-Tuning (RFT) for high-quality data curation and Group Relative Self-Distillation (GRSD) for step-level policy refinement. Refer to the framework diagram for the complete pipeline structure.
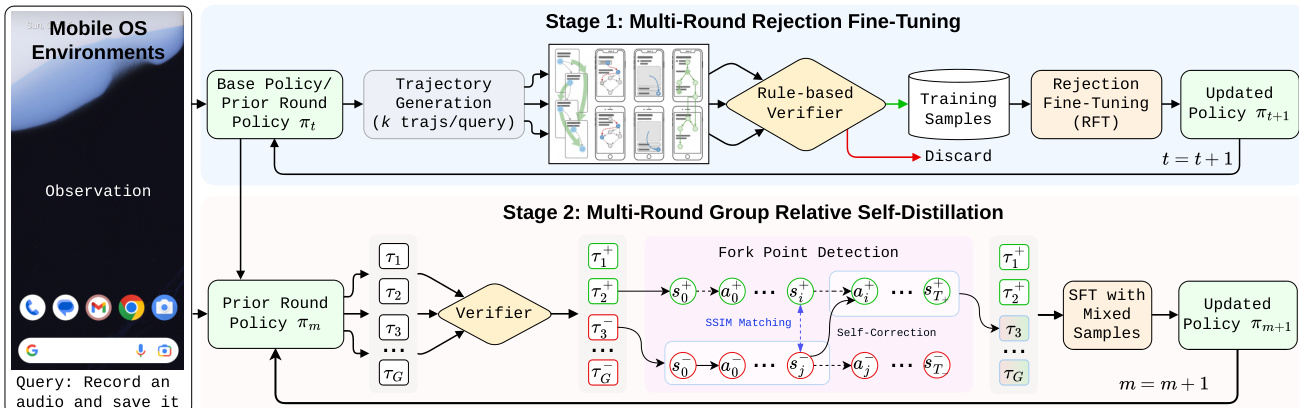
The first stage, Rejection Fine-Tuning (RFT), establishes a closed-loop system to enhance data quality. The base policy generates multiple trajectories for a given task, which are then evaluated by a rule-based verifier. Only trajectories that successfully complete the task or pass the verifier are retained for Supervised Fine-Tuning (SFT). This rejection sampling mechanism ensures that the model is updated using high-fidelity samples, fostering a co-evolutionary cycle where model improvements lead to better trajectory synthesis in subsequent rounds.
The second stage, Group Relative Self-Distillation (GRSD), addresses the credit assignment problem inherent in long-horizon multi-turn tasks. Unlike standard reinforcement learning methods like PPO or GRPO that rely on sparse trajectory-level rewards, GRSD leverages successful trajectories within a group to provide dense, step-level supervision for failed attempts. As shown in the figure below, the method identifies specific divergence points between successful and failed trajectories to guide self-correction.
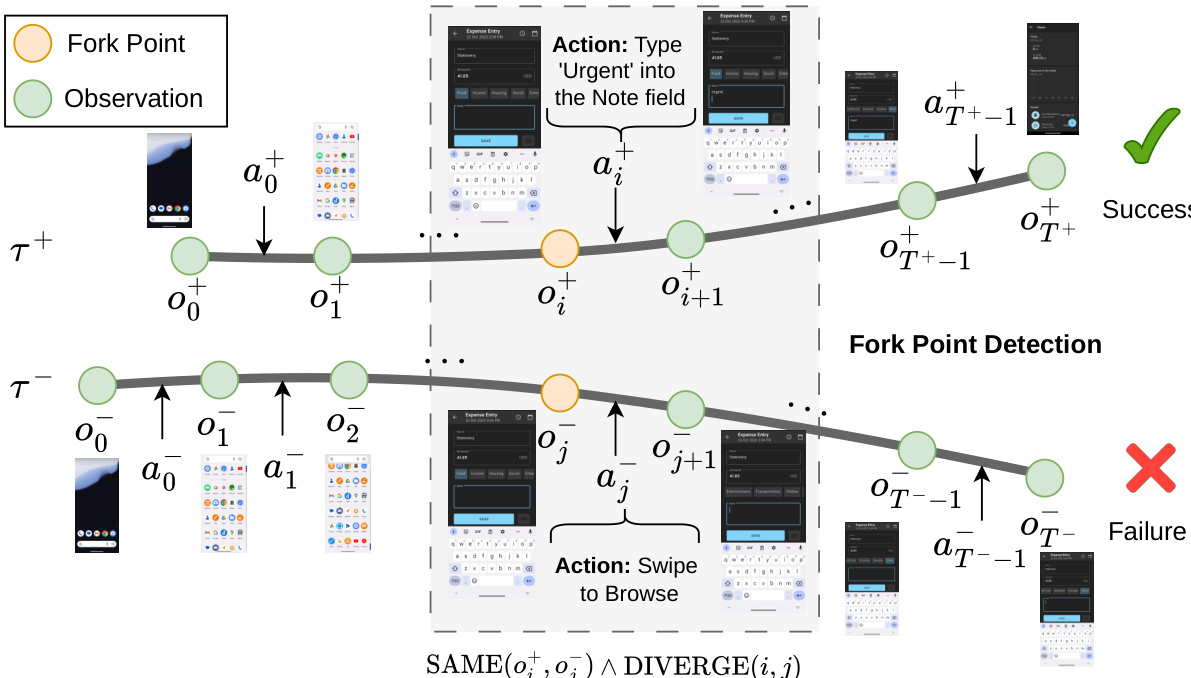
The core mechanism of GRSD is Fork Point Detection. Given a successful trajectory τ+ and a failed trajectory τ−, the system searches for steps where the agent observes the same screen state but takes different actions. To determine state equivalence, the authors utilize the Structural Similarity Index (SSIM) on preprocessed screenshots. A fork point is identified at step j in the failed trajectory if there exists a step i in the successful trajectory such that the observations match, denoted as SAME(oi+,oj−), but the subsequent transitions diverge, denoted as DIVERGE(i,j).
Once fork points are identified, the model undergoes Step-Level Self Distillation. For each matched pair, a training sample is constructed by using the context from the failed trajectory and the correct action from the successful trajectory as the target. The training objective minimizes the autoregressive next-token prediction loss over these constructed samples:
LGRSD=−∣D∣1x∈D∑Tx1t=1∑Txlogπθ(yt∣s1,…,spx,y<t),where D represents the set of samples derived from fork points. This approach effectively transforms sparse feedback into precise corrective signals, allowing the agent to learn from its own mistakes without requiring external teacher policies.
Experiment
- Evaluation on the AndroidWorld benchmark demonstrates that UI-Voyager achieves superior performance compared to diverse baselines, including specialized GUI agents and large-scale proprietary models, while surpassing reported human-level success rates with only 4B parameters.
- Rejection Fine-Tuning (RFT) is validated as a critical initialization strategy that provides consistent performance gains and serves as an efficient warm-start, whereas direct application of standard RL algorithms like GRPO and PPO from the base model yields marginal improvements and high sample inefficiency.
- Fork point detection effectively identifies critical divergence moments between successful and failed trajectories, enabling the system to provide dense, step-level supervision and correct erroneous actions at key decision points in long-horizon tasks.
- The GRSD framework leverages self-distillation to transform failed trajectories into high-quality supervised data, significantly outperforming standard RL baselines in sparse-reward environments by addressing credit assignment challenges and facilitating rapid error correction.
- Analysis of real-time execution highlights that while SSIM-based matching is effective, it faces challenges from temporal misalignment and transient visual perturbations, suggesting future improvements through time-aware matching and noise reduction techniques.