Command Palette
Search for a command to run...
Large Language Model 推論のための高速な NF4 量子化解除カーネル
Large Language Model 推論のための高速な NF4 量子化解除カーネル
Xiangbo Qi Chaoyi Jiang Murali Annavaram
概要
大規模言語モデル(LLMs)のパラメータサイズは単一GPUのメモリ容量を超えつつあり、実用的なデプロイメントに向けて量子化技術の導入が不可欠となっている。NF4(4-bit NormalFloat)量子化はメモリ使用量を4分の1に削減可能である一方、現在のNVIDIA GPU(例:Ampere A100)における推論では、FP16形式への高コストな逆量子化(dequantization)が必要となり、これが深刻なパフォーマンスのボトルネックとなっている。本論文では、エコシステムとの完全な互換性を維持しつつ、メモリ階層の原理に基づいた活用を行うことでこの課題を解決する、軽量な共有メモリ(shared memory)最適化手法を提案する。我々は提案手法をオープンソースのBitsAndBytes実装と比較検証した結果、3つのモデル(Gemma 27B、Qwen3 32B、Llama3.3 70B)において2.0〜2.2倍のカーネル高速化を達成した。また、グローバルメモリへのアクセスと比較して12〜15倍のレイテンシ優位性を持つ共有メモリを活用することで、エンドツーエンドで最大1.54倍の性能向上を実現した。本最適化は、インデックス作成ロジックを簡素化することで命令数(instruction counts)を削減し、かつスレッドブロックあたりわずか64バイトの共有メモリのみを使用する。これにより、最小限のエンジニアリング工数で軽量な最適化が大幅なパフォーマンス向上をもたらし得ることを実証した。本研究は、HuggingFaceエコシステムに対してプラグアンドプレイ(plug-and-play)なソリューションを提供し、既存のGPUインフラストラクチャ上での高度なモデルへのアクセスを民主化するものである。
One-sentence Summary
By utilizing a lightweight shared memory optimization to replace expensive global memory access, this method achieves up to 2.2x kernel speedup and 1.54x end-to-end improvement across the Gemma 27B, Qwen3 32B, and Llama3.3 70B models while maintaining full compatibility with the HuggingFace ecosystem.
Key Contributions
- The paper introduces a lightweight shared memory optimization that exploits the memory hierarchy of the Ampere architecture to address dequantization bottlenecks in NF4 quantized models.
- This method transforms redundant per-thread global memory accesses into efficient per-block loading, reducing lookup table traffic by 64x per thread block and simplifying indexing logic to reduce instruction counts by 71%.
- Experimental evaluations on Gemma 27B, Qwen3 32B, and Llama3.3 70B demonstrate 2.0 to 2.2x kernel speedups and up to 1.54x end-to-end performance improvements while maintaining full compatibility with the HuggingFace and BitsAndBytes ecosystems.
Introduction
As large language models grow beyond the memory capacity of single GPUs, NF4 quantization has become essential for reducing memory footprints by 4x. However, because current NVIDIA Ampere architectures lack native 4-bit compute support, weights must be dequantized to FP16 during every matrix multiplication. This process creates a major performance bottleneck, with dequantization accounting for up to 40% of end-to-end latency due to redundant and expensive global memory accesses. The authors leverage a lightweight shared memory optimization to address this inefficiency by transforming per-thread global memory loads into efficient per-block loads. This approach exploits the significant latency advantage of on-chip memory to achieve a 2.0 to 2.2x kernel speedup while maintaining full compatibility with the HuggingFace and BitsAndBytes ecosystems.
Experiment
The evaluation uses a single NVIDIA A100 GPU to test optimized NF4 dequantization kernels against baseline implementations across three models: Gemma 27B, Qwen3 32B, and Llama3.3 70B. The experiments validate that the original dequantization process creates a significant bottleneck due to high memory overhead and warp divergence caused by complex tree-based decoding. Results demonstrate that the shared memory optimization consistently accelerates kernel execution, leading to substantial end-to-end latency and throughput improvements that are particularly pronounced in larger models.
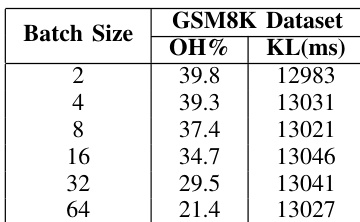
The authors analyze the dequantization overhead and kernel latency for the Qwen3-32B model using the GSM8K dataset. The results show that dequantization remains a significant portion of total inference time across various batch sizes. Dequantization overhead percentage decreases as the batch size increases Kernel latency remains relatively consistent regardless of the batch size The dequantization process represents a substantial bottleneck in end-to-end inference
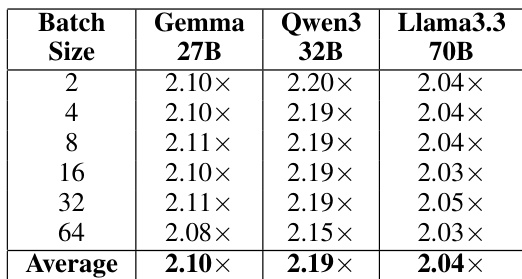
The authors evaluate the kernel-level speedup of their optimized NF4 dequantization implementation across different model architectures and batch sizes. Results show that the optimization provides consistent performance gains regardless of the specific model or workload scale. The optimization achieves a consistent speedup across all tested models and batch sizes. Larger models and different batch configurations all experience similar levels of kernel-level improvement. The performance gains remain stable across varying batch sizes from small to large workloads.
The authors evaluate dequantization overhead and the effectiveness of an optimized NF4 implementation using the Qwen3-32B model and various architectures. While dequantization is identified as a significant bottleneck in end-to-end inference, the optimized kernel provides consistent performance gains across different models and batch sizes. These results demonstrate that the optimization maintains stable speedups regardless of the specific workload scale or model architecture.