Command Palette
Search for a command to run...
OneVL: Vision-Languageによる説明を伴うワンステップの潜在的推論およびプランニング
OneVL: Vision-Languageによる説明を伴うワンステップの潜在的推論およびプランニング
概要
Chain-of-Thought (CoT) 推論は、VLAベースの自動運転における軌道予測の強力な推進力となっていますが、その自己回帰的な性質により、リアルタイムのデプロイメントを困難にするレイテンシ(遅延)コストが発生します。Latent CoT(潜在的CoT)手法は、推論を連続的な隠れ状態へと圧縮することでこのギャップを埋めようと試みていますが、明示的な(explicit)手法には一貫して及んでいません。我々は、この原因が、実際の運転を支配する因果的なダイナミクスではなく、世界の記号的な抽象化を純粋に言語的な潜在表現へと圧縮しようとしている点にあると考えています。そこで本論文では、OneVL (One-step latent reasoning and planning with Vision-Language explanations) を提案します。これは、2つの補助デコーダーによる監督を通じて、コンパクトな潜在tokenへと推論をルーティングする、VLAと世界モデル(World Model)を統合したフレームワークです。テキストのCoTを再構成する言語デコーダーに加え、我々は将来のフレームのtokenを予測する視覚的世界モデルデコーダーを導入しました。これにより、潜在空間に対して、道路の幾何学的構造、agentの動き、および環境の変化という因果的ダイナミクスを内面化(internalize)させることを強制します。3段階のトレーニングパイプラインにより、これらの潜在表現を軌道、言語、および視覚的な目的関数へと段階的に整合させ、安定した共同最適化を実現します。推論時には補助デコーダーを破棄し、すべての潜在tokenを単一の並列パスでプリフィル(prefill)することで、回答のみを生成する予測と同等の速度を実現します。4つのベンチマークにおいて、OneVLは明示的なCoTを上回る初のLatent CoT手法となり、「回答のみ」のレイテンシで最先端(SOTA)の精度を達成しました。これは、言語と世界モデルの両方の監督によって誘導される、よりタイトな圧縮が、冗長なtokenごとの推論よりも汎用性の高い表現を生み出すという直接的な証拠を提供しています。プロジェクトページ: https://xiaomi-embodied-intelligence.github.io/OneVL
One-sentence Summary
The Xiaomi Embodied Intelligence Team proposes OneVL, a unified VLA and world model framework that employs dual auxiliary decoders to supervise compact latent tokens through language reconstruction and future-frame prediction, enabling one-step latent reasoning and planning that surpasses explicit chain-of-thought performance at answer-only latency across four benchmarks.
Key Contributions
- The paper introduces OneVL, a unified Vision-Language-Action (VLA) and World Model framework that utilizes compact latent tokens for reasoning and planning. This method routes reasoning through a compressed latent space that is supervised by dual auxiliary decoders to capture both linguistic reasoning and causal environmental dynamics.
- A three-stage training pipeline is presented to progressively align latent representations with trajectory, language, and visual objectives. This approach ensures stable joint optimization by using a language decoder to reconstruct text-based Chain-of-Thought and a visual world model decoder to predict future-frame tokens.
- The framework achieves state-of-the-art accuracy across four benchmarks by enabling a single parallel pass at inference time where auxiliary decoders are discarded. This design allows the model to match the speed of answer-only prediction while surpassing the performance of explicit Chain-of-Thought methods.
Introduction
Vision-Language-Action (VLA) models are increasingly used in autonomous driving to unify scene understanding, reasoning, and trajectory planning. While Chain-of-Thought (CoT) reasoning improves prediction accuracy by surfacing intermediate driving intents, its autoregressive nature creates high inference latency that is unsuitable for real-time, safety-critical deployment. Existing latent CoT methods attempt to compress reasoning into continuous hidden states to save time, but they often underperform explicit CoT because they rely on purely linguistic representations that capture symbolic abstractions rather than the actual causal dynamics of the driving environment.
The authors leverage a unified VLA and World Model framework called OneVL to bridge this gap. They introduce dual auxiliary decoders to supervise compact latent tokens: a language decoder to reconstruct text-based reasoning and a visual world model decoder to predict future-frame tokens. This dual supervision forces the latent space to internalize both semantic intent and the spatiotemporal causal dynamics of road geometry and agent motion. By using a three-stage training pipeline and a single-pass prefill inference method, OneVL achieves state-of-the-art accuracy at the speed of answer-only prediction.
Dataset

The authors evaluate OneVL using four complementary datasets designed to support Chain-of-Thought (CoT) reasoning and complex driving scenarios:
-
Dataset Composition and Sources
- NAVSIM: A large-scale autonomous driving benchmark derived from nuPlan driving logs, used for non-reactive simulation-based planning.
- ROADWork: A specialized dataset focusing on autonomous navigation in road construction zones, featuring hazards like temporary signage, barriers, and non-standard lane configurations.
- Impromptu: A large-scale vision-language-action benchmark distilled from eight open driving datasets, targeting unstructured corner-case scenarios.
- APR1: A dataset featuring Chain of Causation (CoC) annotations that provide decision-grounded reasoning traces for complex driving behaviors.
-
Annotation and Processing Details
- CoT Construction: The authors use various pipelines to generate reasoning traces for supervision. For NAVSIM, they leverage existing annotations from AdaThinkDrive. For ROADWork, they use an in-house pipeline to annotate work-zone hazards and lane interpretations. For Impromptu, they employ a VLM-centric pipeline to categorize unstructured scenarios and generate planning-oriented rationales. For APR1, they use a released model checkpoint to replicate CoC labels.
- Trajectory Subsampling: To make waypoint prediction suitable for autoregressive modeling, the authors apply a heuristic subsampling strategy to the APR1 waypoints, reducing the sequence from 64 points to 8 points while ensuring the final points are preserved.
- Test Set Construction: Due to the lack of an official test set for APR1, the authors subsample 700 examples from available video clips to create a custom evaluation set.
- Data Format: Training samples are structured to include visual latent tokens, language latent tokens, a trajectory answer, CoT reasoning steps, and future image tokens.
Method
The authors leverage a unified vision-language model architecture, built upon the Qwen3-VL-4B-Instruct foundation, to enable one-step latent reasoning, planning, and explainability in autonomous driving. The core framework integrates a vision encoder (ViT), a visual projector (MLP Aligner), and a large language model (LLM), forming a backbone that processes interleaved image and text inputs. To facilitate compact, interpretable reasoning, the model introduces two specialized latent token types: visual latent tokens (Zv) and language latent tokens (Zl). These tokens are inserted into the model's output sequence, with the visual latents preceding the language latents, to serve as compressed carriers of reasoning. During training, the hidden states corresponding to these latent token positions are extracted and fed into two auxiliary decoders. The visual auxiliary decoder predicts future-frame visual tokens, acting as a world model that validates the causal structure of the scene dynamics, while the language auxiliary decoder reconstructs human-readable chain-of-thought (CoT) reasoning. This dual-supervision mechanism ensures that the latent representations encode genuinely generalizable and causal information, grounding both semantic intent and physical dynamics. Refer to the framework diagram 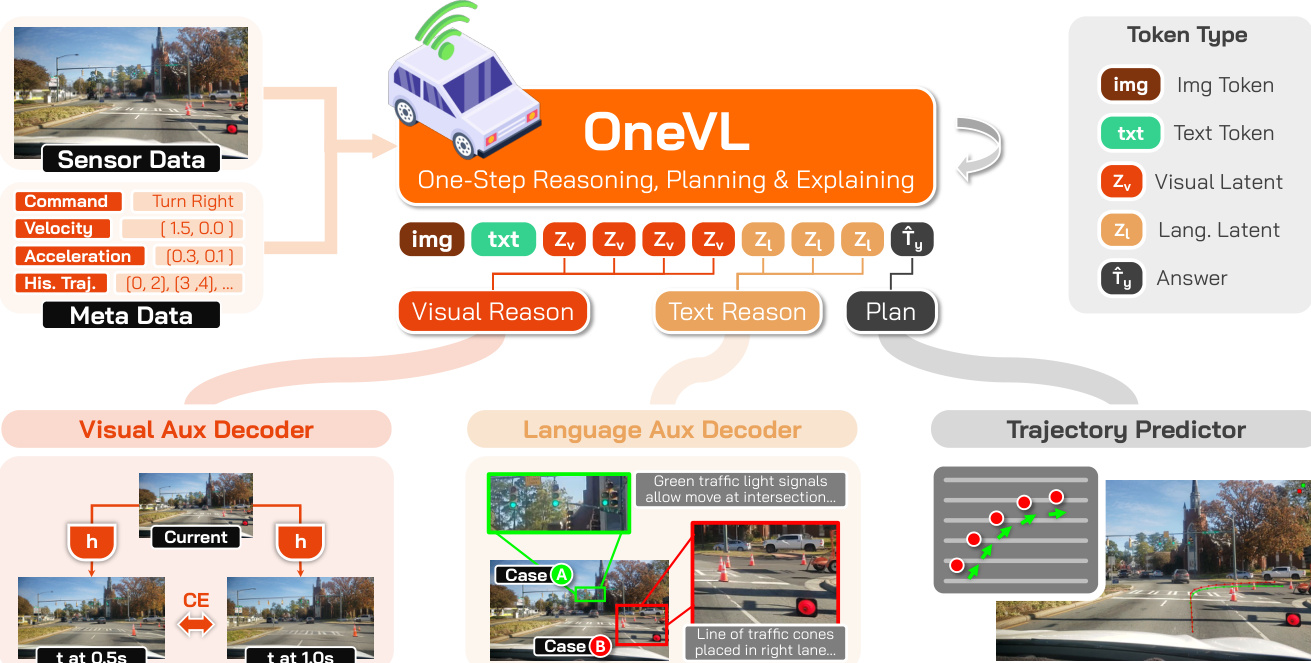 for a visual overview of this architecture.
for a visual overview of this architecture.
The language auxiliary decoder is designed to recover explicit reasoning text from the language latent hidden states. It takes as input the hidden states from the language latent tokens (Hl) and the current-frame ViT patch embeddings (V), concatenates them after projecting both into the decoder's embedding space, and then predicts the ground-truth CoT text. The visual auxiliary decoder, meanwhile, performs future-frame prediction conditioned on both the current visual context and the visual latent hidden states (Hv). To represent images as discrete sequences, the model employs the IBQ visual tokenizer, which uses a large codebook of 131,072 discrete visual codes, extending the base model's vocabulary. The visual decoder is trained to predict the concatenated discrete visual token sequences for future frames at 0.5s and 1.0s. The total training objective is a weighted sum of the main model's cross-entropy loss for trajectory and latent token prediction (Lc), the language explanation loss (Ll), and the visual explanation loss (Lv), with a lower weight for the visual task to prevent it from dominating the training signal.
To ensure effective training of this complex architecture, the authors employ a three-stage pipeline. The process begins with a preliminary self-supervised pretraining of the visual auxiliary decoder to learn a strong unconditional prior for future-frame prediction from the current frame alone. This is followed by Stage 0, a main model warmup where the backbone is trained on trajectory prediction with the latent tokens embedded, allowing the model to learn to generate meaningful latent representations. Stage 1 then focuses on training the auxiliary decoders while keeping the main model frozen, ensuring they align with stable latent features. Finally, Stage 2 performs joint end-to-end fine-tuning of all components, enabling a virtuous cycle where the auxiliary decoders' supervisory signals refine the latent representations, which in turn improve the model's overall performance. At inference time, the auxiliary decoders are discarded, and the latent tokens are prefilled into the prompt context, enabling single-pass generation of the trajectory answer with inference speed comparable to answer-only prediction while retaining the interpretability of the reasoning process. 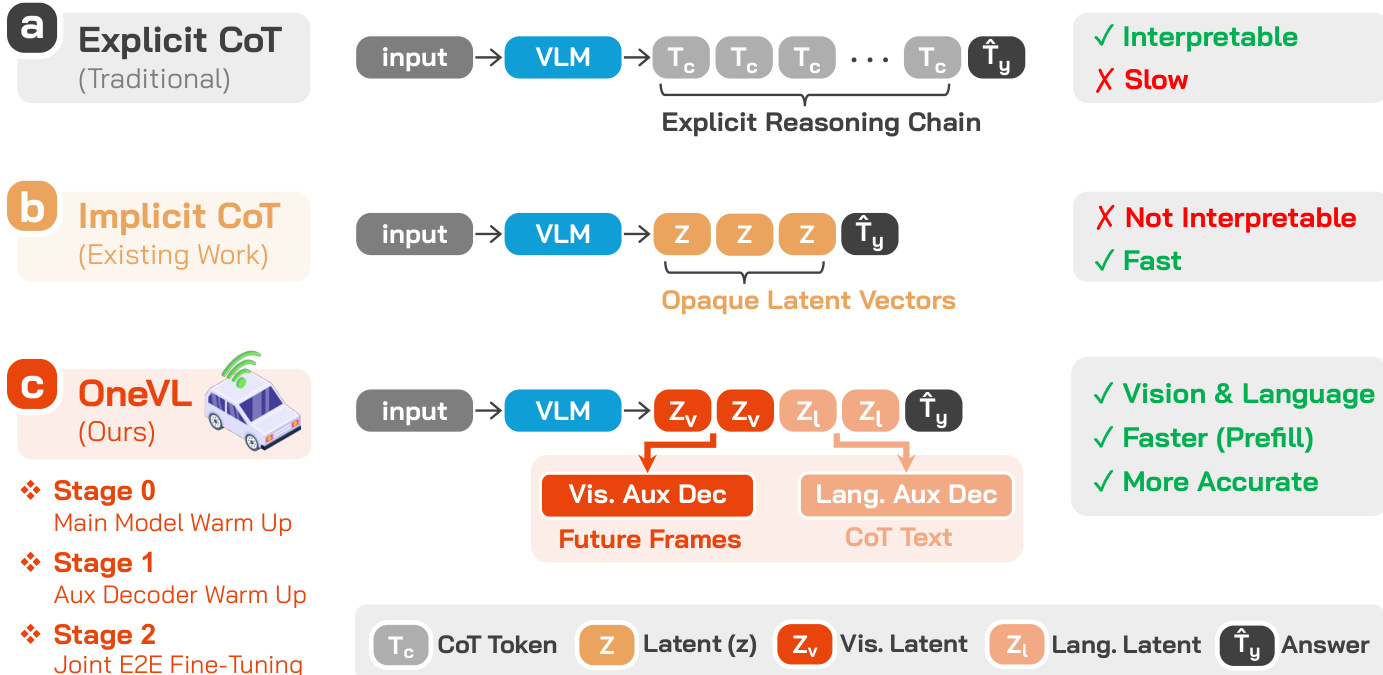
Experiment
The evaluation assesses the OneVL framework across four benchmarks, including NAVSIM, ROADWork, Impromptu, and APR1, to validate its trajectory prediction accuracy, explanation quality, and inference efficiency. By comparing OneVL against autoregressive and latent chain-of-thought baselines, the experiments demonstrate that combining linguistic reasoning with visual world-model supervision significantly improves planning performance. The results conclude that OneVL achieves state-of-the-art accuracy and provides human-interpretable explanations while maintaining the low latency required for real-world autonomous driving deployment.
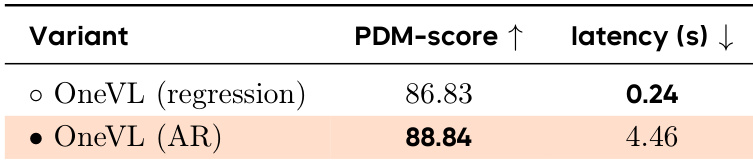
The authors compare a regression-based variant of OneVL with its autoregressive counterpart, showing that the regression version achieves a slightly lower PDM-score but significantly reduced inference latency. The results indicate that the regression approach maintains competitive performance while enabling much faster inference, supporting real-time deployment. OneVL regression achieves lower latency than OneVL AR while maintaining competitive performance. The regression variant of OneVL shows a minor drop in PDM-score compared to the autoregressive version. The regression approach enables significantly faster inference, making it suitable for real-time deployment.
The authors evaluate the quality of text explanations generated by different methods on the NAVSIM benchmark, focusing on how well the predicted reasoning aligns with ground-truth annotations. OneVL with a language auxiliary decoder achieves competitive results in explanation quality, showing strong performance across multiple metrics while maintaining efficiency. The comparison highlights that explicit reasoning methods outperform latent CoT approaches in explanation quality, but OneVL's latent framework still provides a strong balance between interpretability and performance. OneVL with language auxiliary decoder achieves competitive explanation quality compared to explicit reasoning methods on NAVSIM. Explicit reasoning methods outperform latent CoT methods in all evaluation metrics for text explanation quality. OneVL's latent framework provides a balance between explanation quality and inference efficiency.

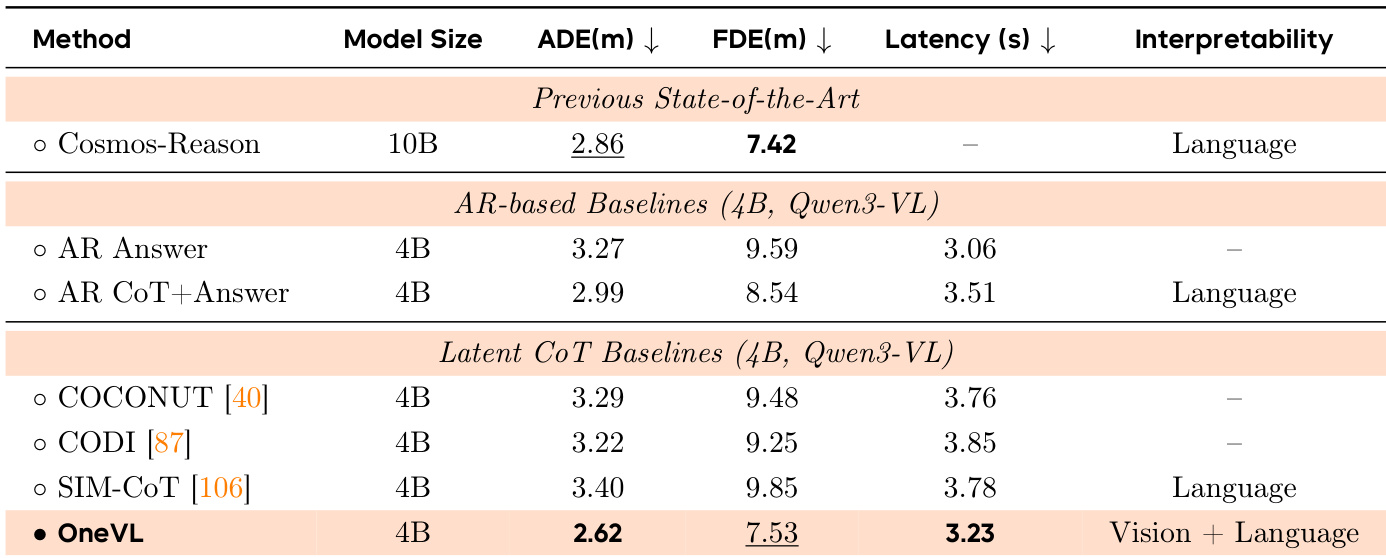
The authors compare various methods for autonomous driving trajectory prediction, focusing on performance, latency, and interpretability. Results show that OneVL achieves competitive accuracy with lower latency compared to previous state-of-the-art methods and outperforms other latent CoT approaches, particularly in trajectory prediction metrics. OneVL also provides interpretable outputs through both visual and language-based reasoning. OneVL achieves competitive trajectory prediction accuracy with lower latency than previous state-of-the-art methods. OneVL outperforms other latent CoT methods, especially in trajectory prediction metrics, while providing interpretable outputs. The visual auxiliary decoder contributes more to performance than the language decoder, indicating the importance of spatial-temporal grounding in reasoning.
The authors compare the performance of OneVL against Impromptu VLA on a trajectory prediction task, focusing on prediction accuracy over time. Results show that OneVL achieves significantly lower trajectory prediction errors across all time steps, indicating improved accuracy in predicting future vehicle paths compared to the baseline. The performance gap widens over time, suggesting that OneVL's predictions remain more consistent and accurate as the prediction horizon extends. OneVL achieves substantially lower trajectory prediction errors across all time steps compared to Impromptu VLA. The performance gap between OneVL and the baseline increases with longer prediction horizons. OneVL demonstrates superior accuracy in predicting future vehicle trajectories over time, especially at later time points.

The authors evaluate OneVL on multiple autonomous driving benchmarks, demonstrating superior performance compared to both autoregressive and latent chain-of-thought baselines. The model achieves state-of-the-art results while maintaining inference speeds comparable to answer-only prediction, highlighting the effectiveness of its multimodal auxiliary supervision and staged training approach. Key findings indicate that visual world model supervision and a three-stage training pipeline are essential for effective latent reasoning in trajectory prediction. OneVL outperforms all baselines on NAVSIM, ROADWork, Impromptu, and APR1, achieving state-of-the-art results across multiple metrics. The model matches the inference speed of answer-only prediction, demonstrating that prefilling latent tokens incurs negligible latency overhead. Visual auxiliary supervision and the three-stage training pipeline are critical, as their absence leads to significant performance degradation and failure in learning causal scene dynamics.
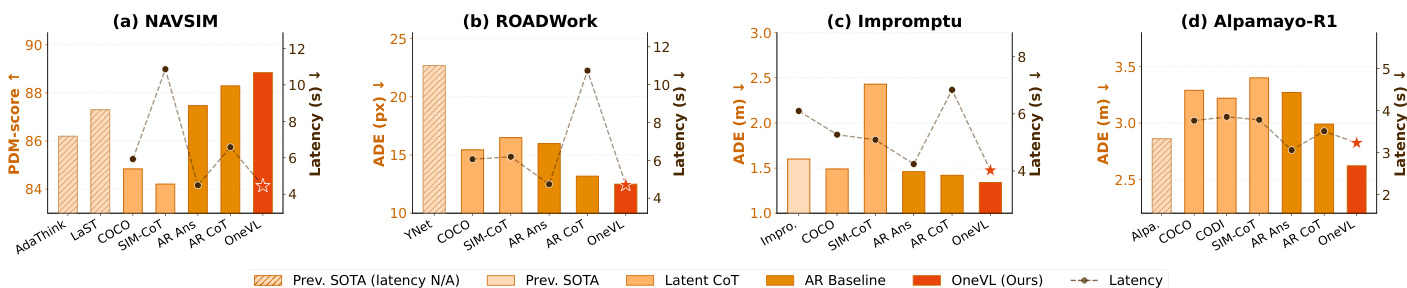
The authors evaluate OneVL through various comparative experiments focusing on inference efficiency, explanation quality, and trajectory prediction accuracy across multiple autonomous driving benchmarks. The results demonstrate that OneVL achieves state-of-the-art performance and superior long-term prediction consistency while maintaining inference speeds comparable to answer-only models. Ultimately, the findings highlight that the model's multimodal auxiliary supervision and staged training approach are essential for effective latent reasoning and real-time deployment.