Command Palette
Search for a command to run...
Active Context Compression: LLM Agentにおける自律的メモリ管理
Active Context Compression: LLM Agentにおける自律的メモリ管理
Nikhil Verma
概要
大規模言語モデル(LLM)エージェントは、「コンテキストの肥大化(Context Bloat)」により、長期的なスパン(long-horizon)を要するソフトウェアエンジニアリング・タスクの遂行に困難を抱えています。対話履歴が増加するにつれ、計算コストの爆発的な増大、レイテンシの増加、さらには過去の無関係なエラーによる干渉(distraction)が生じることで、推論能力が低下するという問題が発生します。既存の解決策の多くは、エージェント自身が制御できない受動的な外部サマリー機構に依存しています。本論文では、粘菌(Physarum polycephalum)の生物学的な探索戦略に着想を得た、エージェント中心型のアーキテクチャである「Focus」を提案します。Focus Agentは、重要な学習内容を永続的な「Knowledge」ブロックへと集約するタイミングを自律的に決定し、生の対話履歴を能動的に削減(prune)します。業界のベストプラクティスに即して最適化されたスキャフォールド(永続的なbash + 文字列置換エディタ)を用い、Claude Haiku 4.5を使用して、SWE-bench Liteから抽出したコンテキスト集約型の5つのインスタンス(N=5)でFocusの評価を行いました。頻繁な圧縮を促すアグレッシブなpromptingを用いた結果、Focusは精度を維持したまま(両エージェント共に3/5 = 60%)、22.7%のtoken削減(14.9M → 11.5M tokens)を達成しました。Focusはタスクあたり平均6.0回の自律的な圧縮を実行し、個別のインスタンスにおいては最大57%のtoken削減を実現しました。本研究は、適切なツールとpromptingが提供されれば、能力の高いモデルは自律的にコンテキストを自己制御できることを実証しており、タスクのパフォーマンスを損なうことなく、コスト効率の高いエージェント・システムの構築に向けた道筋を示すものです。
One-sentence Summary
Nikhil Verma proposes Focus, an agent-centric architecture inspired by the biological exploration strategies of Physarum polycephalum that enables LLM agents to autonomously manage context through active consolidation and pruning, achieving a 22.7% token reduction on SWE-bench Lite instances using Claude Haiku 4.5 while maintaining 60% accuracy.
Key Contributions
- The paper introduces Focus, an agent-centric architecture inspired by the biological exploration strategies of slime mold that enables intra-trajectory context management. This method allows an agent to autonomously decide when to consolidate key learnings into a persistent knowledge block while actively pruning raw interaction history.
- This work implements an optimized scaffold using industry best practices, such as a persistent bash interface and a string-replacement editor, to facilitate autonomous self-regulation of context. This approach enables the agent to summarize recent trajectories into high-level insights and physically delete redundant logs during a single task.
- Evaluations on context-intensive SWE-bench Lite instances demonstrate that the Focus agent achieves a 22.7% total token reduction while maintaining identical task accuracy compared to standard agents. Results show that the method performs an average of 6.0 autonomous compressions per task, with individual instance token savings reaching up to 57%.
Introduction
As Large Language Model (LLM) agents tackle complex, long-horizon software engineering tasks, they face significant hurdles known as context bloat. Naive use of large context windows leads to quadratic cost increases, higher latency, and context poisoning where irrelevant trial-and-error logs distract the model from the primary task. While existing solutions use external memory hierarchies or separate compression models, they often rely on passive mechanisms that the agent cannot control during a continuous task trajectory. The authors propose Focus, an agent-centric architecture inspired by the biological exploration strategies of slime mold. This approach enables the agent to perform intra-trajectory compression by autonomously summarizing key learnings into a persistent knowledge block and actively pruning raw interaction history to maintain a lean, effective context.
Method
The authors introduce a novel architecture termed the Focus Loop, which augments the standard ReAct agent loop with two specialized primitives: start_focus and complete_focus. Unlike traditional approaches that rely on external timers or fixed heuristics to manage context length, this architecture grants the agent full autonomy to determine when to initiate and conclude a focus cycle.
The process begins when the agent invokes start_focus to declare a specific investigation objective, such as debugging a database connection. This action establishes a formal checkpoint within the conversation history. Following this checkpoint, the agent enters the exploration phase, where it utilizes standard tools like reading, editing, and executing code to perform its tasks.
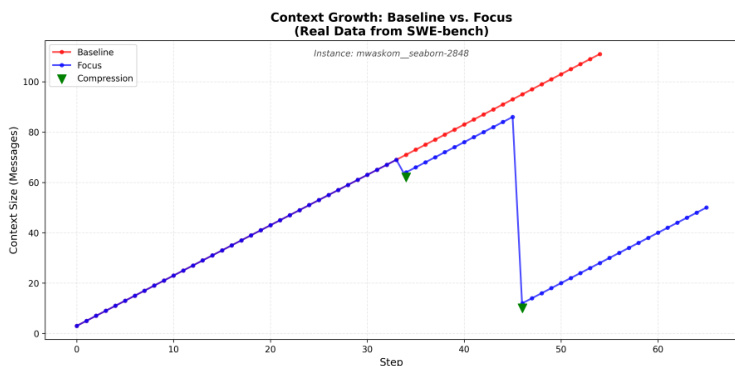
As the agent reaches a natural conclusion to a sub-task or encounters a dead end, it invokes complete_focus. During this consolidation phase, the agent generates a structured summary that captures the attempted actions, the facts or bugs learned, and the final outcome. The system then executes a withdrawal process: the generated summary is appended to a persistent "Knowledge" block located at the top of the context, and all intermediate messages between the initial checkpoint and the current step are deleted. This mechanism transforms the context from a monotonically increasing log into a "Sawtooth" pattern, where the context expands during exploration and collapses during consolidation. This allows the model to manage its own context based on the inherent structure of the task rather than arbitrary step counts.
To support this loop, the authors implement an optimized scaffold designed for software engineering tasks. This scaffold consists of two primary tools: a Persistent Bash session and a String-Replace Editor. The Persistent Bash tool provides a stateful shell environment where the working directory and environment remain consistent across multiple calls, mimicking a real-world developer terminal. To ensure precise file manipulation, the String-Replace Editor allows for targeted edits through exact string replacement, including operations such as viewing, creating, replacing, and inserting text. This approach avoids the common errors associated with full-file rewrites. The agent is guided by a system prompt to utilize these tools extensively, with a maximum limit of 150 steps, and is encouraged to implement tests before attempting to solve the primary problem.
Experiment
The Focus architecture was evaluated on five context-intensive SWE-bench Lite instances using an A/B comparison to determine if aggressive context compression could reduce token usage without sacrificing task accuracy. The experiments demonstrate that directive prompting, which enforces frequent and structured compression phases, enables significant token savings while maintaining the same success rate as a baseline agent. While the architecture is highly effective for exploration-heavy tasks, the results also indicate that compression overhead can occasionally exceed benefits in tasks requiring continuous iterative refinement.
The authors compare a baseline agent against their Focus architecture on context-intensive software engineering tasks. Results show that the Focus agent achieves significant token reductions while maintaining the same level of task success as the baseline. The Focus agent achieves a substantial reduction in total token consumption compared to the baseline. Task success rates remain identical between the baseline and the Focus architecture. The Focus approach utilizes frequent compressions and message dropping to manage context efficiency.
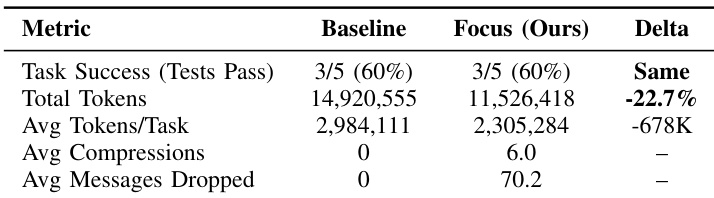
The authors evaluate the Focus architecture against a baseline agent on context-intensive software engineering tasks to test its ability to manage context efficiency. By utilizing frequent compressions and message dropping, the Focus approach significantly reduces total token consumption. Ultimately, the architecture maintains the same level of task success as the baseline while operating much more efficiently.