Command Palette
Search for a command to run...
UI-TARS:Native AgentによるGUI自動インタラクションの先駆的研究
UI-TARS:Native AgentによるGUI自動インタラクションの先駆的研究
概要
本論文では、スクリーンショットのみを入力として認識し、人間のようなインタラクション(キーボードやマウス操作など)を実行するネイティブなGUI agentモデル「UI-TARS」を提案する。エキスパートによるプロンプトやワークフローを用いて、高度にラッピングされた商用モデル(GPT-4oなど)に依存する既存のagentフレームワークとは異なり、UI-TARSはエンドツーエンドのモデルであり、これらの洗練されたフレームワークを凌駕する性能を持つ。実験の結果、UI-TARSの優れた性能が実証された。具体的には、認識(perception)、グラウンディング(grounding)、およびGUIタスク実行を評価する10以上のGUI agent benchmarkにおいて、SOTA(State-of-the-Art)を達成した。特筆すべき点として、OSWorld benchmarkにおいて、UI-TARSは50ステップで24.6、15ステップで22.7のスコアを記録し、それぞれClaudeの22.0および14.9を上回った。また、AndroidWorldにおいても、UI-TARSは46.6を達成し、GPT-4oの34.5を凌駕した。
One-sentence Summary
The authors propose UI-TARS, an end-to-end native GUI agent that performs human-like keyboard and mouse operations by perceiving screenshots directly, achieving state-of-the-art performance across more than ten benchmarks including OSWorld, where it outperforms Claude, and AndroidWorld, where it surpasses GPT-4o.
Key Contributions
- This paper introduces UI-TARS, a native GUI agent model that functions as an end-to-end system by perceiving screenshots directly to perform human-like keyboard and mouse interactions.
- The model incorporates several novel technical innovations including enhanced perception, unified action modeling, system-2 reasoning, and iterative refinement through the use of online traces.
- Experimental results demonstrate state-of-the-art performance across more than 10 GUI agent benchmarks, specifically outperforming Claude and GPT-4o on the OSWorld and AndroidWorld datasets.
Introduction
Automating graphical user interface (GUI) interactions is essential for streamlining complex digital workflows and increasing productivity. While existing agent frameworks rely on modular designs and expert-crafted prompts to wrap commercial models like GPT-4o, these systems are often fragile, difficult to maintain, and lack the ability to learn from new experiences. The authors introduce UI-TARS, an end-to-end native agent model that perceives screenshots directly and performs human-like interactions without the need for manual workflow engineering. To achieve this, the authors leverage enhanced visual perception, a unified action modeling space, and System-2 reasoning to support deliberate, multi-step decision making. Furthermore, they implement an iterative training process using reflective online traces to allow the model to continuously learn from its mistakes.
Dataset
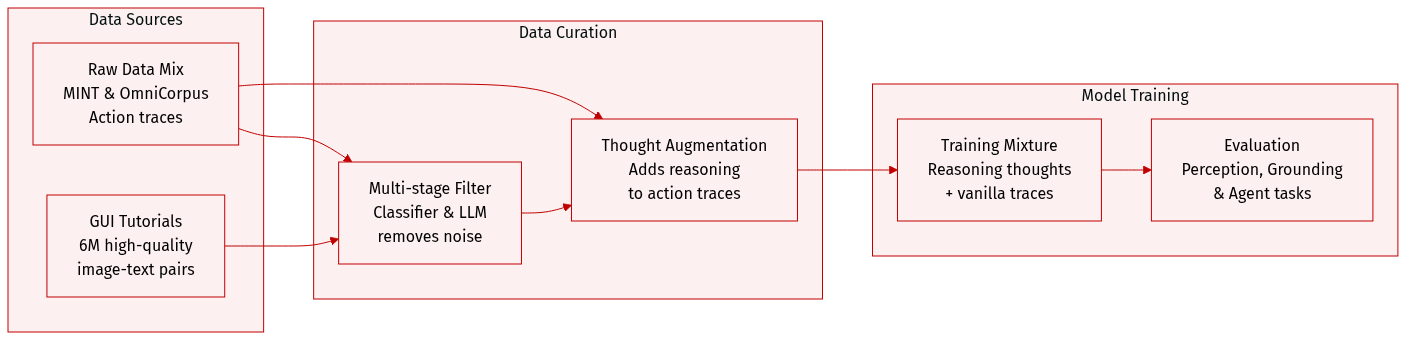
The authors develop a multi-faceted dataset designed to enhance the perception, grounding, and reasoning capabilities of GUI agents. The dataset composition and processing are summarized below:
-
Dataset Composition and Sources
- GUI Tutorials: The authors curate approximately 6M high-quality tutorials from the MINT and OmniCorpus image-text interleaved datasets. On average, each tutorial consists of 3.3 images and 510 text tokens.
- Action Traces: The dataset includes action-focused traces consisting of sequences of observations and actions.
-
Data Processing and Filtering
- Multi-stage Tutorial Filtering: To extract high-quality GUI tutorials from noisy sources, the authors employ a three-step pipeline:
- Coarse-Grained Filtering: A fastText classifier, trained on manually curated tutorials and random samples, performs an initial screening.
- Fine-Grained Filtering: An LLM removes false positives to ensure samples strictly conform to GUI tutorial characteristics.
- Deduplication and Refinement: The authors use URL-based and Locality-Sensitive Hashing (LSH) methods to remove duplicates, followed by LLM-based rephrasing to eliminate low-quality or irrelevant text.
- Thought Augmentation: To move beyond simple action-following, the authors transform action traces into reasoning-enhanced sequences by annotating "thoughts" (t) between observations and actions.
- Multi-stage Tutorial Filtering: To extract high-quality GUI tutorials from noisy sources, the authors employ a three-step pipeline:
-
Reasoning Construction Strategies
- ActRe (Iterative Annotation): A VLM generates thoughts for each step by looking at the preceding context and the target action. This process encourages specific reasoning patterns, including task decomposition, long-term consistency, milestone recognition, trial and error, and reflection.
- Thought Bootstrapping: To prevent the model from simply justifying a pre-determined action, the authors use a bootstrapping approach. They sample multiple thought-action pairs and select only the thought that causally leads to the correct ground-truth action.
-
Model Usage and Training Details
- Linguistic Diversity: Reasoning thoughts are annotated in both Chinese and English.
- Training Mixture: While the authors augment all traces with reasoning thoughts to stimulate System-2 reasoning, they also include vanilla action traces (sequences containing only observations and actions) during the training process.
Method
The authors propose UI-TARS, a native GUI agent model designed to operate without the need for manual rules or cascaded modules. Instead of relying on separate perception and action modules, UI-TARS directly perceives screenshots, applies reasoning, and generates actions autonomously.
As shown in the framework diagram:
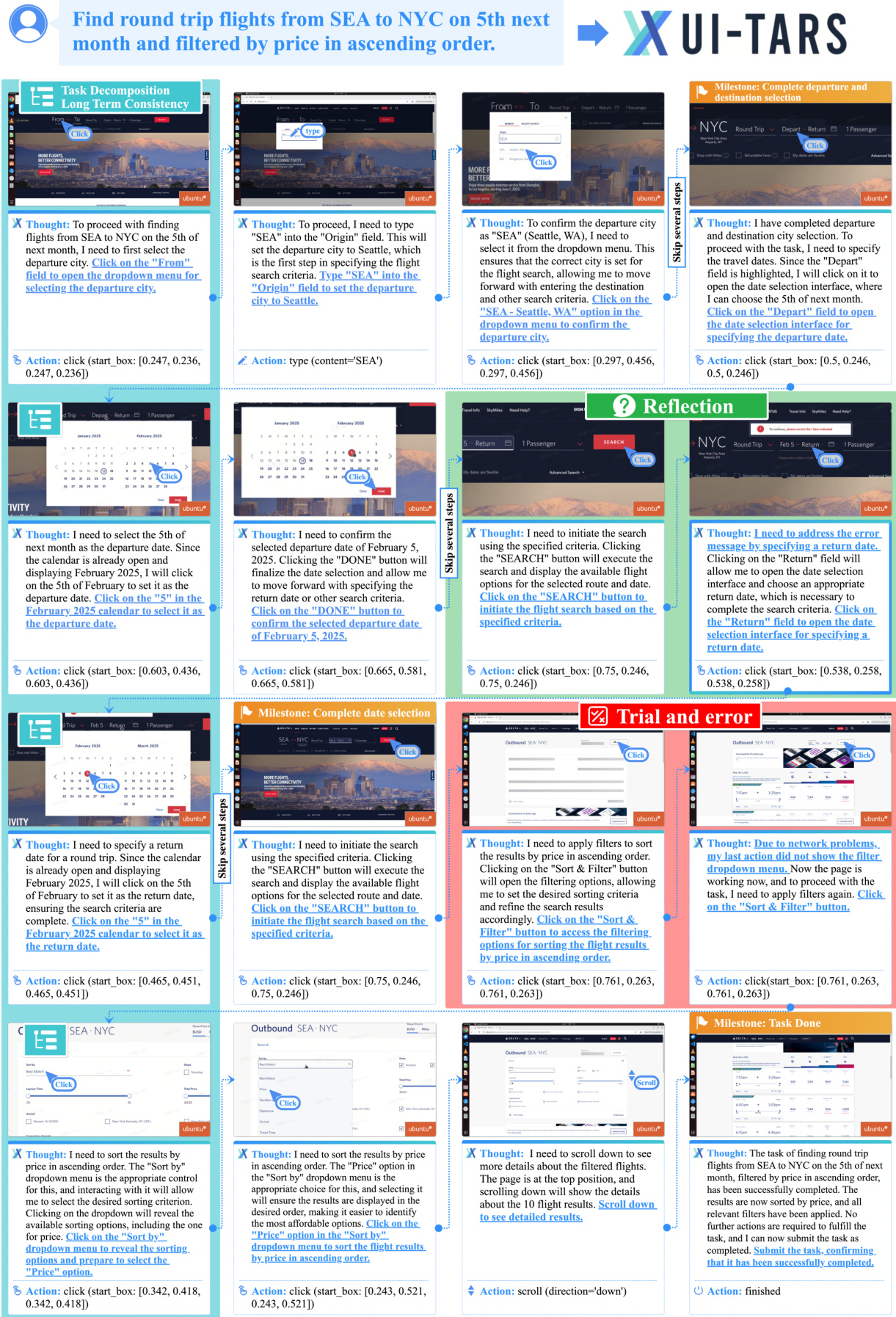
The overall architecture follows an iterative process where, given an initial task instruction, the agent receives observations from the device and performs corresponding actions. This sequential process can be formally expressed as:
(instruction,(o1,a1),(o2,a2),…,(on,an))
where oi denotes the observation (device screenshot) at time step i, and ai represents the action executed by the agent. To enhance reasoning, the authors integrate a "System 2" reasoning component in the form of thoughts ti generated before each action ai. These thoughts act as an intermediary step to guide the agent through structured, goal-oriented deliberation. The formalized process becomes:
(instruction,(o1,t1,a1),(o2,t2,a2),…,(on,tn,an))
To maintain efficiency within token limits, the model limits its input to the last N observations, while retaining the full history of actions and thoughts as short-term memory. The model predicts the thought and action iteratively as follows:
P(tn,an∣instruction,t1,a1,…,(on−i,tn−i,an−i)i=1N,on)
To improve GUI perception, the authors adopt a bottom-up data construction approach. They curate five core task types to train the model, which are illustrated in the data example below:
These tasks include Element Description, where the model learns to describe element types, visual appearance, position, and function; Dense Captioning to capture the entire interface layout; State Transition Captioning to identify subtle visual changes between screenshots; Question Answering (QA) for relational reasoning; and Set-of-Mark (SoM) to enhance the association between visual markers and elements.
The model also incorporates a mechanism for learning from prior experience through long-term memory. This is achieved via Online Trace Bootstrapping, where the agent executes instructions in virtual environments to produce raw traces. These traces undergo multi-level filtering—including rule-based rewards, VLM scoring, and human review—to produce high-quality data for self-improvement.
To address the issue of agents getting stuck in error loops, the authors introduce Reflection Tuning. This protocol exposes the model to real-world errors and their subsequent corrections. By training on error correction trace pairs, the model learns how to recognize mistakes and realign its progress. Furthermore, the authors employ Direct Preference Optimization (DPO) to explicitly guide the agent away from suboptimal actions by encoding a preference for corrected actions over erroneous ones.
The training process follows a three-phase approach using the Qwen-2-VL backbone:
- Continual Pre-training: The model learns foundational GUI interaction knowledge, including perception and action traces.
- Annealing Phase: High-quality subsets of data are used to optimize decision-making strategies, resulting in the UI-TARS-SFT model.
- DPO Phase: The model undergoes DPO training using annotated reflective pairs to reinforce optimal actions, resulting in the final UI-TARS-DPO model.
Experiment
The experiments evaluate the UI-TARS model across three critical dimensions: perception, grounding, and agent capabilities, using both offline benchmarks and dynamic online simulations. The results demonstrate that UI-TARS achieves state-of-the-art performance, particularly excelling in reasoning-intensive and multi-step tasks across web, mobile, and desktop environments. Furthermore, the study validates that scaling model size and employing System-2 reasoning significantly enhance the agent's ability to generalize to complex, out-of-domain scenarios.
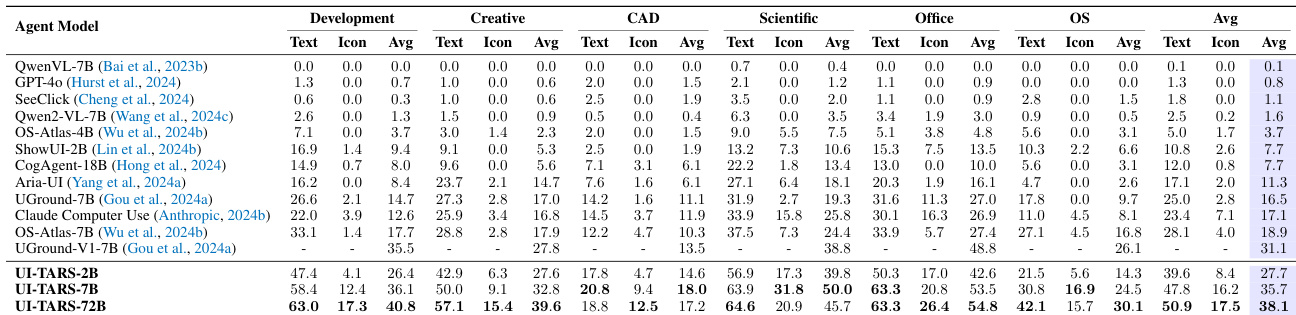
The authors evaluate the performance of the UI-TARS model variants across several specialized domains including Creative, CAD, Scientific, Office, and OS tasks. The results show that the UI-TARS models, particularly the larger 72B version, consistently achieve higher average scores compared to existing baselines across most categories. UI-TARS-72B demonstrates superior performance in the OS and Scientific domains compared to previous models. The model variants show strong capabilities in Office and CAD tasks, outperforming established baselines. Scaling the model size from 2B to 72B leads to significant improvements in average performance across all evaluated categories.
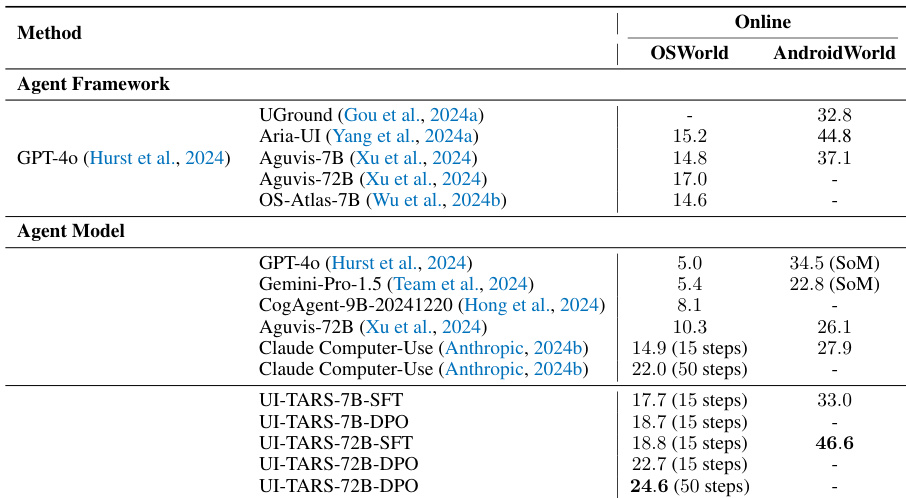
The authors compare the performance of the UI-TARS agent models against various agent frameworks and commercial models in online, dynamic environments. Results across the OSWorld and AndroidWorld benchmarks show that UI-TARS models generally achieve higher scores than existing baselines. UI-TARS models demonstrate superior performance in reasoning-intensive online tasks compared to established agent frameworks and commercial models. The 72B variant of UI-TARS achieves higher scores in both desktop and mobile environments than previous state-of-the-art methods. Applying Direct Preference Optimization (DPO) to the UI-TARS models leads to improved results in online benchmark settings.
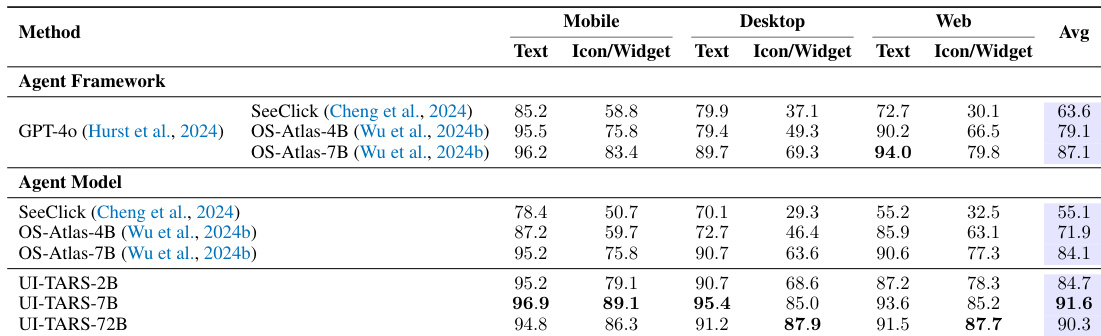
The the the table compares various agent frameworks and agent models across mobile, desktop, and web platforms using both text-based and icon/widget-based approaches. Results show that the UI-TARS agent models generally achieve higher average performance compared to the listed agent frameworks and other agent models. UI-TARS models demonstrate superior performance in icon and widget-based tasks across all three platforms compared to the baseline frameworks. The larger UI-TARS model variant achieves the highest overall average performance among all compared methods. UI-TARS models show significant improvements in icon and widget recognition and interaction capabilities over previous agent models like OS-Atlas.
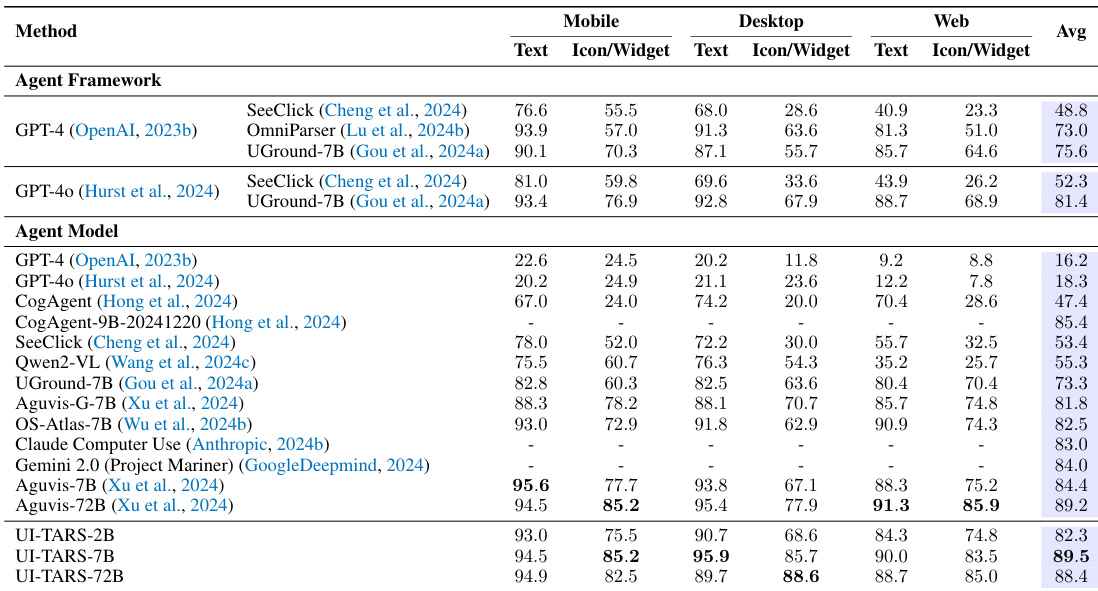
The the the table compares various agent frameworks and agent models across mobile, desktop, and web platforms. Results show that the UI-TARS models, particularly the larger variant, achieve superior performance across most categories compared to existing frameworks and models. The UI-TARS-72B model achieves the highest average performance among all evaluated methods. UI-TARS models demonstrate strong capabilities across mobile, desktop, and web environments, often outperforming commercial and academic baselines. In many categories, the UI-TARS-72B model shows significant improvements over both modular agent frameworks and end-to-end agent models.
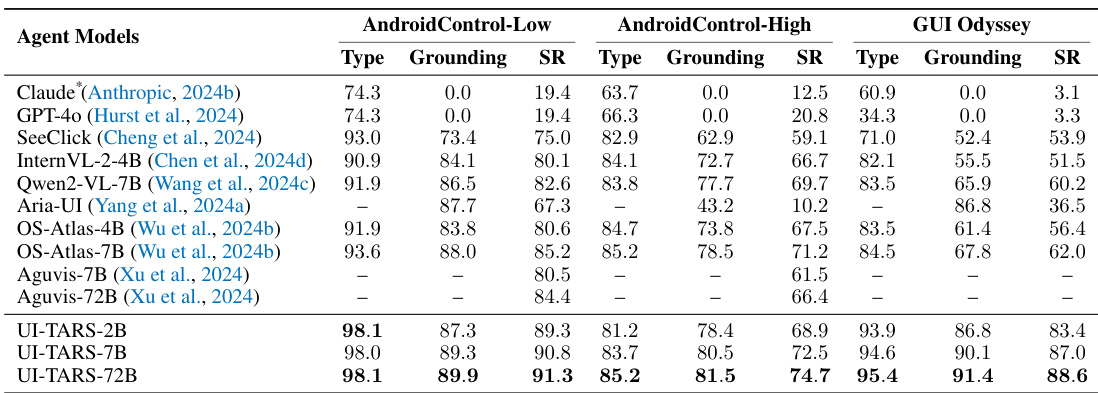
The authors evaluate several agent models across mobile-based benchmarks including AndroidControl and GUI Odyssey. Results show that the UI-TARS models consistently achieve higher performance in both grounding and success rates compared to existing baselines. UI-TARS-72B achieves superior performance in both low and high complexity AndroidControl tasks. The UI-TARS models demonstrate improved grounding and success rates in GUI Odyssey compared to previous state-of-the-art methods. Scaling from the 2B to the 72B variant leads to measurable improvements in task execution and grounding precision.
The authors evaluate the UI-TARS model variants across diverse specialized domains, dynamic online environments, and multiple platforms including mobile, desktop, and web. The experiments validate the model's ability to perform complex reasoning and icon-based interactions, demonstrating that scaling from 2B to 72B significantly enhances task execution and grounding precision. Ultimately, the UI-TARS models, particularly the 72B version, consistently outperform existing agent frameworks and commercial models across various benchmarks.