Command Palette
Search for a command to run...
PlayCoder: LLMが生成したGUIコードの実行可能性を実現する
PlayCoder: LLMが生成したGUIコードの実行可能性を実現する
Zhiyuan Peng Wei Tao Xin Yin Chenhao Ying Yuan Luo Yiwen Guo
概要
大規模言語モデル(LLM)はコード生成において優れた成果を収めているが、GUIアプリケーション、特にゲームを生成する能力については、いまだ十分に研究されていない。既存のベンチマークは主にテストケースを通じて正確性を評価しているが、GUIアプリケーションはインタラクティブかつイベント駆動型であり、一連のユーザーアクションにわたる正しい状態遷移(state transitions)を必要とするため、こうした評価手法では不十分である。したがって、その評価は単なるパス/失敗の結果だけでなく、インタラクションの流れやUIロジックを考慮すべきである。本研究では、この課題に対処するため、Python、TypeScript、JavaScriptで記述された43種類の多言語GUIアプリケーションから構築された、リポジトリを意識した(repository-aware)ベンチマーク「PlayEval」を提案する。デスクトップ環境への適応が困難であった従来のGUIベンチマークとは異なり、PlayEvalは6つの主要なGUIアプリケーションカテゴリを網羅し、コード生成の評価を直接的にサポートしている。さらに、生成されたk個の候補のうち、少なくとも1つが論理的なエラーなくエンドツーエンドでプレイ可能であるかを測定する指標「Play@k」を提案する。信頼性の高い評価を実現するため、タスク指向のGUIプレイを実行し、論理違反を自動的に検出するLLMベースのagentである「PlayTester」を開発した。最先端のコード生成LLM 10モデルを用いた実験の結果、コンパイル成功率は高いものの、Play@3はほぼゼロに近いことが示され、論理的に正しいGUIアプリケーションの生成における重大な弱点が明らかになった。この限界を克服するために、我々は、GUIアプリケーションのコードをクローズドループ内で生成、評価、および反復的に修正する、マルチagentかつリポジトリを意識したフレームワーク「PlayCoder」を提示する。PlayCoderは、オープンソースおよびクローズドソースのモデルの両方において、機能的な正確性とセマンティックな整合性(semantic alignment)を大幅に向上させ、最大で38.1%のExec@3および20.3%のPlay@3を達成した。ケーススタディでは、従来の指標では見逃されるサイレントな論理バグを特定し、的を絞った編集を通じてそれらを修正できることが示されている。
One-sentence Summary
To improve the generation of playable GUI applications, the authors propose PlayCoder, a multi-agent, repository-aware framework that utilizes closed-loop control and the PlayTester agent to perform interactive, task-oriented evaluations that detect and repair silent logic flaws missed by traditional unit tests.
Key Contributions
- The paper introduces PlayEval, a repository-aware evaluation dataset comprising 43 multilingual GUI applications across six major categories to facilitate code generation tasks on desktop platforms.
- A new evaluation metric called Play@k is proposed to measure end-to-end logical correctness by determining if at least one of k generated candidates allows for error-free application gameplay, supported by an LLM-based agent named PlayTester that automates interactive playthroughs.
- The study presents PlayCoder, a multi-agent, repository-aware framework that utilizes closed-loop control to write, evaluate, and refine GUI code, which achieves significant improvements in functional correctness and semantic alignment by reaching up to 20.3% Play@3 scores.
Introduction
Large language models have made significant strides in code generation, yet their ability to develop functional graphical user interfaces (GUIs) remains limited. While traditional benchmarks focus on compilation success and unit test passage, these metrics fail to capture the stateful, event-driven logic required for interactive applications like games. Consequently, models often produce code that runs without errors but contains critical behavioral flaws, such as broken collision detection or failed event handling, which pass standard functional tests.
The authors address these gaps by introducing PlayEval, a repository-aware benchmark designed to evaluate GUI applications through hierarchical behavioral testing. They propose a novel Play@k metric that measures whether generated code can be played end-to-end without logical errors. To automate this process, the authors develop PlayCoder, a multi-agent framework that utilizes a specialized LLM-based agent called PlayTester to drive interactive playthroughs and detect semantic violations. By feeding these behavioral diagnostics back into a refinement loop, PlayCoder enables targeted automated program repair, significantly improving the functional correctness and semantic alignment of generated GUI applications.
Dataset
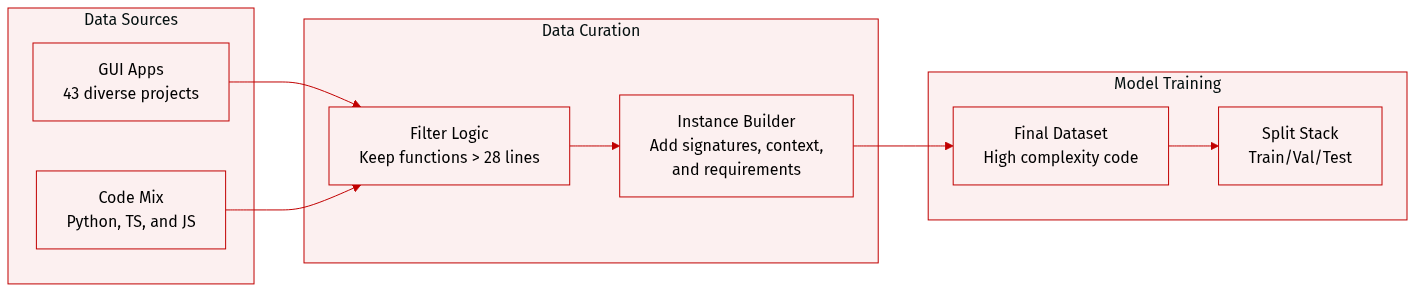
-
Dataset Composition and Sources: The authors introduce PlayEval, a repository-aware benchmark consisting of 43 diverse GUI applications. The dataset spans three programming languages: Python, TypeScript, and JavaScript. The applications are organized into six categories: Game Emulation, Classic Games, MMORPG Games, Game Engines, Standalone Applications (such as productivity tools and multimedia apps), and Desktop Widgets.
-
Selection and Filtering Criteria: Repositories were selected based on active development history (at least 6 months of maintenance), community validation (primarily projects with over 100 GitHub stars), and functional completeness. To ensure the benchmark focuses on behavior-rich code rather than simple utility helpers, the authors applied a filtering rule where functions must have a minimum of 28 lines after excluding docstrings and decorators.
-
Data Processing and Metadata Construction: Each evaluation instance is constructed using a three part structure:
- Function Signature: The exact method declaration including parameter types and return specifications.
- Requirements: Natural language descriptions of the function's purpose and behavior, generated using GPT-4o-mini and manually verified by experts to ensure high quality.
- Repository Context: Relevant imports, class definitions, and related functions extracted from the codebase. To maintain realistic development environments, the authors used git checkout to revert repositories to specific states.
-
Complexity and Evaluation: The dataset is designed to stress models with high structural complexity, featuring an average cyclomatic complexity of 10.2 per file and an average nesting depth of 11.0 levels. For ground truth, the authors utilize the original repository's unit tests, though they note that real-world projects often have limited test coverage.
Method
The authors propose PlayCoder, a multi-agent framework designed for repository-aware GUI application code generation, which operates through a structured test-and-repair cycle involving two specialized agents: PlayDeveloper and PlayRefiner. The overall workflow begins with a requirement description, repository context, and function signature, which are combined to generate candidate code. This code undergoes behavioral testing, and based on the results, PlayRefiner performs automated program repair (APR) to refine the application. The process iterates until the generated code satisfies both syntactic and behavioral criteria.
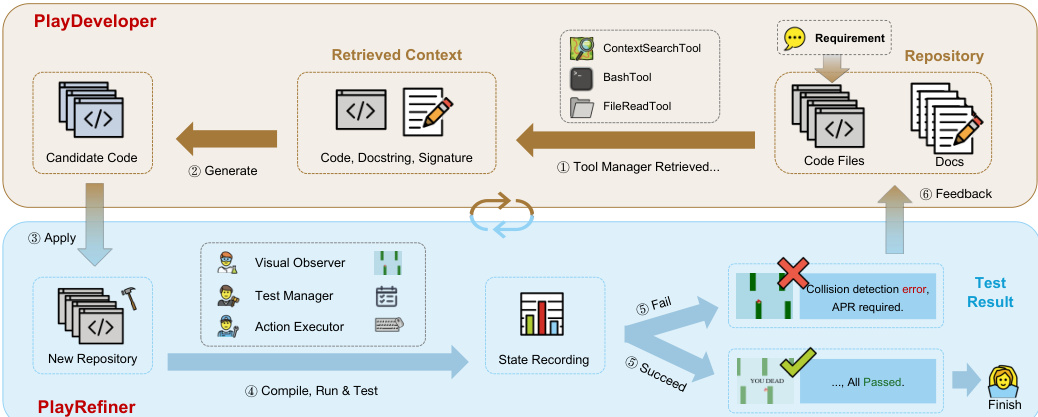
The framework's architecture is illustrated in the diagram above, showing the interaction between the two agents. PlayDeveloper, the code generation agent, operates in a context-aware manner by retrieving relevant code patterns and module structures from the repository. It leverages a modular tool ecosystem, including a ContextSearchTool for retrieving code examples and import patterns, a FileReadTool for accessing files, a BashTool for executing shell commands, and a ConversationTool to maintain dialogue sessions. This agent uses few-shot prompting with standard requirement-code examples to generate repository-aware code.

PlayRefiner, the automated program repair agent, is responsible for diagnosing and fixing behavioral issues identified during testing. It coordinates a set of core tools: a ContextSearcher for retrieving repository-aware APIs and import patterns during repair, a Validator for syntax and AST checks, and an Executor for running the program in a sandbox to capture runtime and behavioral signals. The repair process follows a five-phase loop: Diagnosis aggregates compiler output, runtime logs, and testing reports into actionable failure summaries; Patch Generation proposes minimal edits guided by retrieved context; Patch Application writes changes atomically; Build & Runtime Validation compiles and executes the application; and Iterative Refinement repeats this cycle up to a fixed budget or until the behavioral criteria are met.
The behavioral testing phase is conducted using the PlayTester framework, which integrates three specialized components. The Visual Observer captures application state via screenshots using platform-specific APIs and caches recent frames to detect state changes. The Action Executor translates test strategies into specific GUI operations, such as clicks, typing, and scrolling, and includes safety mechanisms. The Test Manager, which uses vision-language models, plans tests by processing screenshots and textual context to generate strategies, with distinct prompt templates for goal-driven (e.g., games) and coverage-driven (e.g., non-game applications) testing regimes. The entire process is supported by comprehensive logging through the AgentTrajectory tool, which records LLM interactions, tool usage, and execution traces, enabling diagnosis and reproducibility. Applications execute in sandboxed environments with deterministic seeding to ensure fair and reproducible evaluations.
Experiment
The researchers evaluate the effectiveness of PlayCoder, a multi-agent framework designed for GUI-based code generation, against various state-of-the-art LLMs and agentic baselines using the PlayEval benchmark. The experiments validate the necessity of combining automated program repair with visual-based behavioral testing to detect silent logical failures that traditional unit tests cannot capture. Results demonstrate that PlayCoder significantly outperforms existing methods across multiple programming languages and provides superior cost-effectiveness by achieving higher behavioral correctness per token consumed.
The the the table presents a breakdown of the PlayEval benchmark, which consists of 43 projects across six categories including game emulation, classic games, and MMORPG games. The projects vary significantly in size and complexity, with metrics such as lines of code, number of functions, and classes showing substantial differences between categories, while the benchmark includes a total of 2,104 test cases. The benchmark spans six categories with varying project complexity, including game emulation, classic games, and MMORPG games. There is significant variation in project size across categories, with some having over 120,000 lines of code and others under 3,000. The benchmark includes a total of 2,104 test cases across all projects, with test case counts per project ranging from 24 to 1,539.

The authors evaluate various language models and enhanced methods on a benchmark for GUI application code generation, focusing on execution, pass, and behavioral validation metrics. Results show that even top-performing models achieve low behavioral correctness rates, and existing enhancement strategies provide limited improvements, highlighting the challenges in generating semantically correct GUI applications. The proposed PlayCoder framework, which integrates automated program repair with dynamic GUI testing, outperforms all baselines across different models and languages, demonstrating superior effectiveness and cost-effectiveness. Top-performing models achieve low behavioral correctness rates, with significant performance drops from execution to behavioral validation across all languages. Existing enhancement methods provide limited and inconsistent improvements over base models, failing to bridge the performance gap for GUI applications. PlayCoder outperforms all baselines across models and languages, achieving the highest effectiveness and cost-effectiveness in behavioral validation.
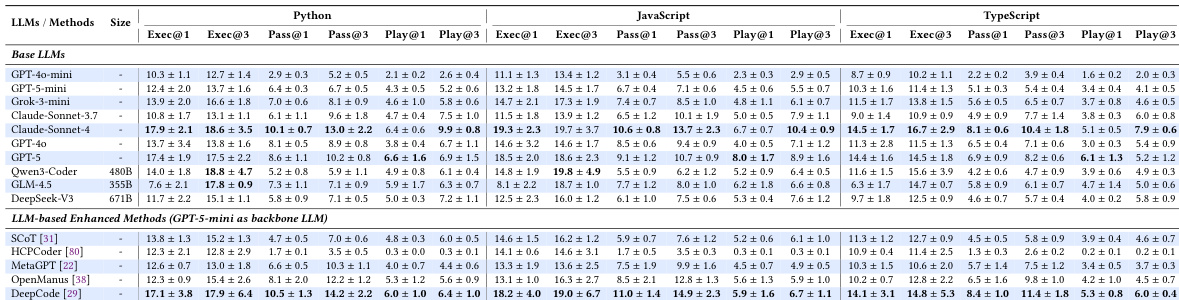
{"summary": "The authors evaluate the performance of various LLMs and code generation methods on a benchmark for GUI application development, focusing on behavioral correctness through interactive testing. Results show that existing methods struggle with behavioral validation, particularly in TypeScript, and that the proposed PlayCoder framework significantly outperforms baselines by combining automated program repair with visual feedback and dynamic interaction. The framework demonstrates consistent effectiveness across different LLMs and achieves higher efficiency compared to other agentic approaches.", "highlights": ["PlayCoder outperforms all baseline methods across different LLMs and programming languages, achieving superior behavioral validation through iterative repair and visual feedback.", "Existing methods show limited improvements over base models, with significant performance gaps in behavioral validation, especially in statically-typed languages like TypeScript.", "PlayCoder demonstrates strong cost-effectiveness and consistent performance across diverse LLM architectures, highlighting the importance of both automated repair and GUI feedback components."]
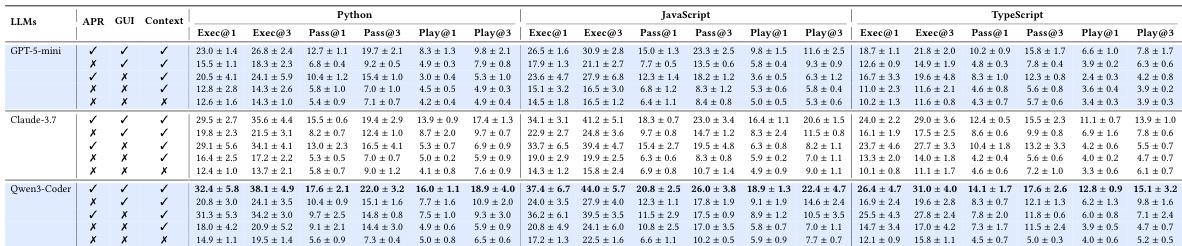
The authors evaluate various large language models and code generation methods on a benchmark for interactive GUI applications, focusing on behavioral correctness through automated testing. Results show that even top-performing models achieve low behavioral validation rates, with significant performance drops from basic execution to interactive testing, and that existing enhancement strategies provide limited improvements. The proposed PlayCoder framework, which integrates iterative repair with visual feedback, outperforms all baselines across multiple languages and models, demonstrating superior effectiveness and cost-efficiency. PlayCoder significantly outperforms all baseline methods in both execution and behavioral validation across multiple programming languages and models. Existing enhancement strategies provide limited improvements in behavioral correctness, with performance degrading substantially from execution to interactive testing. PlayCoder achieves better performance per token consumed, demonstrating high cost-effectiveness compared to other methods.

The authors evaluate the performance of various code generation methods on a benchmark for interactive GUI applications, focusing on execution, pass, and behavioral validation metrics. Results show that existing methods, including advanced LLM-based approaches, struggle with behavioral correctness, particularly in TypeScript, while the proposed PlayCoder framework demonstrates significant improvements across all metrics and maintains consistent effectiveness across different models. Existing code generation methods show limited behavioral validation performance, especially in TypeScript, with most failing to achieve high Play@k scores. PlayCoder outperforms all baseline methods across different models and programming languages, achieving superior execution and behavioral validation metrics. The framework's effectiveness is consistent across diverse LLM architectures, with ablation studies confirming the critical role of automated program repair and visual feedback components.
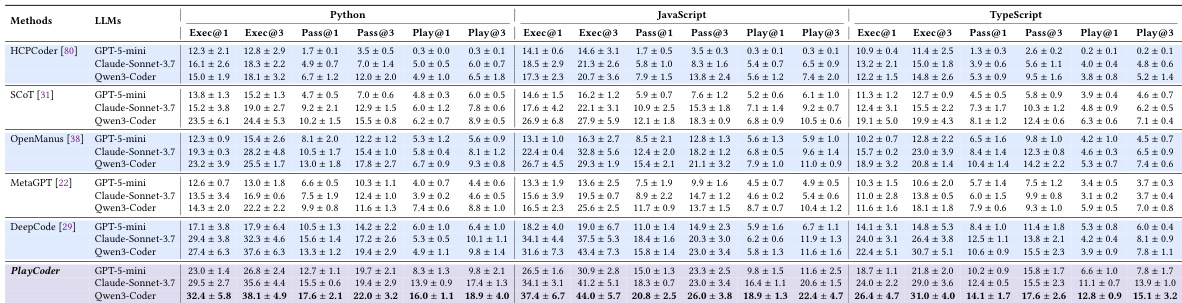
The authors evaluate various large language models and enhancement strategies on the PlayEval benchmark, which consists of diverse GUI application projects ranging from game emulation to MMORPGs. The experiments reveal that existing methods struggle to achieve behavioral correctness, showing significant performance declines when moving from basic execution to interactive testing. In contrast, the proposed PlayCoder framework outperforms all baselines by integrating automated program repair with visual feedback, demonstrating superior effectiveness and cost-efficiency across multiple programming languages and model architectures.