Command Palette
Search for a command to run...
128Kを超えるコンテキストにおける汎化を活用した長期コンテキストビジョン言語モデルの効率的なトレーニング
128Kを超えるコンテキストにおける汎化を活用した長期コンテキストビジョン言語モデルの効率的なトレーニング
概要
タイトル:(タイトルなし)抄録:長文脈モデリングは、現代の大規模ビジョン・言語モデル(LVLMs)の中核的な能力となりつつあり、長文書の理解、動画分析、およびエージェントワークフローにおけるマルチターンツール利用にわたる持続的な文脈管理を可能にしている。しかし、特に長文脈データミックスの設計とバランス調整に関する実用的なトレーニングレシピは十分に探求されていない。本研究では、LVLMsに対する長文脈継続事前学習の体系的な調査を行い、7Bパラメータのモデルを32Kから128Kの文脈長へ拡張し、長文書データに関する広範なアブレーション実験を実施した。まず、長文書VQA(Visual Question Answering)がOCR文字起こしよりも大幅に効果的であることを示した。この観察に基づき、アブレーション実験からさらに3つの重要な知見が得られた。i) 系列長分布に関して、バランスの取れたデータが目標長に焦点を当てたデータ(例:128K)よりも優れた性能を示し、長文脈能力には様々な長さと位置における汎用性の高い重要情報検索が必要であることが示唆された。ii) 検索が主要なボトルネックであり、タスクの多様性のために推論データを控えめにしつつ、検索に重点を置いたデータミックスが有利である。iii) 純粋な長文書VQAは短文脈能力をほぼ維持しており、指示形式の長文データが短データミックスの必要性を低減することを示唆している。これらの知見に基づき、Qwen2.5-VL-7Bから長文脈継続事前学習を行い、わずか5Bトークンの予算で得られたMMProLongを導入する。MMProLongは、長文書VQAスコアを7.1%向上させ、128Kの学習ウィンドウを超えて256Kおよび512Kの文脈においても追加学習なしで強力なパフォーマンスを維持する。さらに、ウェブページベースのマルチモーダルニードル検索、長文脈ビジョン・テキスト圧縮、長動画理解など、タスク固有の監督なしに一般化することも示した。全体として、本研究は実用的なLongPTレシピと、長文脈ビジョン・言語モデルの進展のための実証的基盤を確立する。
One-sentence Summary
The authors introduce MMPROLONG, a 7B vision-language model derived from Qwen2.5-VL-7B through long-context continued pre-training on a 5B-token budget that extends the context window to 128K by prioritizing balanced sequence-length distributions and retrieval-heavy long-document VQA over OCR transcription, thereby preserving short-context capabilities.
Key Contributions
- Long-document visual question answering is identified as a superior training task that provides robust evidence retrieval and reasoning supervision while preserving short-context capabilities without requiring additional short-context data mixing.
- Extensive ablations demonstrate that prioritizing balanced sequence-length distributions and retrieval-heavy mixtures overcomes retrieval bottlenecks, enabling context extension from 32K to 128K within a 5B-token budget.
- The MMProLong recipe extends Qwen2.5-VL-7B via long-context continued pre-training, achieving strong performance on MMLongBench and VTCBench while generalizing to 256K and 512K context lengths across diverse multimodal tasks.
Introduction
The authors leverage long-context continued pre-training to address a critical capability gap in modern vision-language models, which increasingly require sustained context management for long-document analysis, hour-long video understanding, and multi-turn agentic workflows. Despite rapid context window scaling in recent architectures, practical training methodologies remain underexplored, leaving practitioners without clear guidance on how to construct optimal data mixtures, balance sequence length distributions, or effectively integrate short-context supervision. To resolve these challenges, the authors conduct a systematic ablation study on long-document visual question answering and training design, ultimately introducing MMProLong. This approach extends a 7B model from 32K to 128K tokens using a modest 5B-token budget, proves that balanced length distributions and retrieval-heavy data mixtures outperform target-length-focused training, and delivers robust performance at 256K and 512K contexts without additional fine-tuning.
Dataset
-
Dataset Composition and Sources
- The authors construct a foundational pool of over 1.5 million PDF documents spanning academic papers, books, and technical manuals across engineering, medicine, social sciences, and biology.
- To prevent evaluation contamination, they filter the pool by comparing PDF content hashes against known benchmarks.
- Each PDF is rendered into images at 144 DPI using PyMuPDF, and an OCR expert model fine-tuned from Seed 2.0 parses the pages into layout-aware blocks with structural labels like titles, sections, paragraphs, and tables.
-
Key Details for Each Subset
- Long-Document VQA: Sourced from documents containing 32 to 50 pages, yielding multimodal sequences of 32K to 128K tokens. The subset covers three task types: single-page extraction, multi-page extraction, and cross-page reasoning.
- OCR Transcription: Divided into full-document transcription, which requires outputting text from every page, and needle-page transcription, which focuses on 1 to 3 target pages while treating the rest as distractors.
- Short-Context Data: Publicly available instruction tuning data from LLaVA-OneVision is used for supplementary fine-tuning and mixture experiments.
-
Data Usage and Training Mixture
- The authors synthesize long-document VQA data using a short-to-long pipeline, generating questions from 8 to 15 page segments before placing them back into the full document context.
- They compare two length distributions, ultimately selecting the pool-native distribution, which maintains a natural length spread across the sampled documents rather than concentrating on near-maximum lengths.
- For final training, the VQA tasks are grouped into information extraction and reasoning categories. The authors optimize the mixture ratio and adopt an 8:2 extraction-to-reasoning split, which yields the strongest long-context performance.
- Short-context data is mixed with long-context data in controlled ratios to evaluate its impact on preserving general instruction-following capabilities.
-
Processing, Metadata, and Cropping Strategies
- Page sampling relies on OCR-derived structural labels to ensure semantically coherent segments of 8 to 15 consecutive pages are selected for question generation.
- Metadata construction includes explicit segment anchors in every question, such as specifying the exact section or page range, to prevent ambiguous answers when evaluated in the full document context.
- The QA generation process outputs structured JSON containing the question, answer, answer format, evidence page indices, and evidence sources, ensuring strict traceability and format consistency.
- The rendering resolution and OCR parsing pipeline balance visual fidelity with computational efficiency, enabling scalable synthesis of long multimodal sequences.
Method
The authors leverage a three-stage pipeline to construct a long-context training dataset for LongPT, designed to enhance performance on document-level reasoning tasks. The process begins with segment sampling, where a full document is processed using an OCR expert to extract text, and then split into coherent segments of 8 to 15 pages. This step ensures that the input is structured into manageable units suitable for downstream generation while preserving the document's inherent layout and content flow. Refer to the framework diagram.
The second stage involves question-answer (QA) generation, where each document segment is paired with a task instruction to guide the generation process. A QA generator model then produces a QA pair based on the segment and instruction. This stage is critical for creating diverse and contextually grounded questions that require understanding of the document's content. As shown in the figure below:
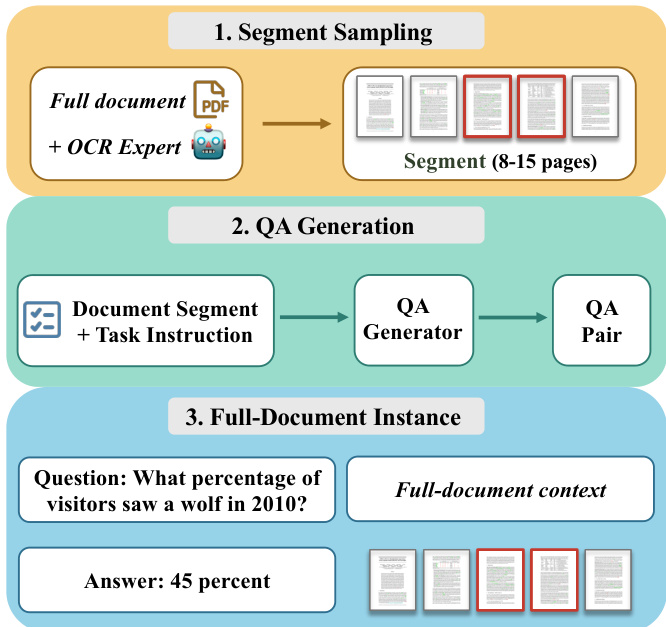
The final stage assembles the generated QA pairs into full-document instances by aggregating the context across the entire document. This step ensures that the model is trained on questions that require reasoning over the full document rather than isolated segments. Each instance includes a question, the corresponding answer, and the full-document context, which enables the model to learn long-range dependencies and perform cross-page reasoning. The framework emphasizes the integration of visual and textual elements, ensuring that both the layout and content are preserved throughout the process.
Experiment
Under a fixed computational budget, experiments compare long-document VQA against OCR transcription and test various short-context data mixing ratios to validate the optimal supervision source and context preservation strategy for extended training. The results indicate that long-document VQA offers superior instruction-aligned supervision, successfully preserving short-context capabilities while substantially enhancing long-document performance. Additionally, the optimized recipe extrapolates robustly to contexts up to 512K and transfers effectively to diverse downstream tasks, including needle-in-a-haystack retrieval, video understanding, and vision-text compression. These findings demonstrate that the proposed methodology cultivates a generalized long-context capability that remains highly effective across different model architectures.
The authors compare the performance of MMProLong against Qwen2.5-VL-7B on long-video understanding benchmarks, including Video-MME, MLVU, and LongVideoBench. Results show that MMProLong achieves higher scores than the base model across all three benchmarks, indicating improved long-video understanding capabilities. MMProLong outperforms Qwen2.5-VL-7B on Video-MME, MLVU, and LongVideoBench The model achieves consistent improvements on long-video understanding benchmarks without video-specific training Results indicate that the training recipe enhances general long-context multimodal capabilities beyond document VQA

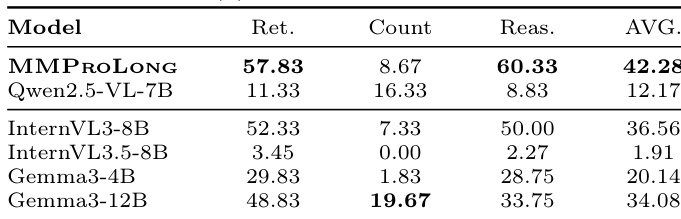
The authors compare the performance of MMProLong against several open-source and closed-source LVLMs on long-document VQA tasks. Results show that MMProLong achieves the highest overall average score, significantly outperforming Qwen2.5-VL-7B and other models across retrieval, counting, and reasoning tasks. The performance gap is particularly pronounced in the reasoning and counting categories, where MMProLong demonstrates superior capability. MMProLong achieves the highest overall average score on long-document VQA tasks compared to other models. MMProLong shows significant improvements in reasoning and counting tasks over Qwen2.5-VL-7B. The model maintains strong performance across retrieval, counting, and reasoning categories, indicating balanced capability.
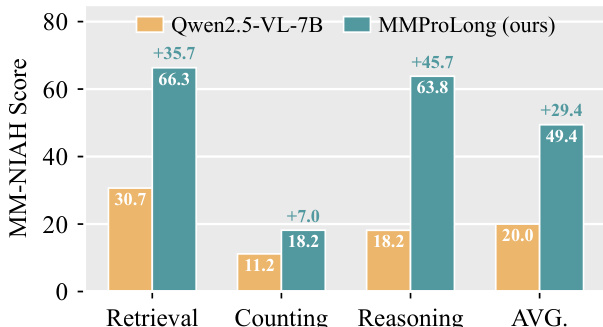
The authors compare the performance of MMProLong against Qwen2.5-VL-7B on the MM-NIAH benchmark, which evaluates retrieval, counting, and reasoning tasks. Results show that MMProLong significantly outperforms the baseline across all three capabilities, with the largest improvement observed in retrieval. The overall average score also shows a substantial gain, indicating that the training recipe enhances performance on multiple aspects of long-context multimodal understanding. MMProLong achieves substantial improvements over Qwen2.5-VL-7B on retrieval, counting, and reasoning tasks in the MM-NIAH benchmark. The largest performance gain is observed in the retrieval task, with a significant increase in score. The overall average score shows a notable improvement, highlighting the effectiveness of the training recipe across different capabilities.
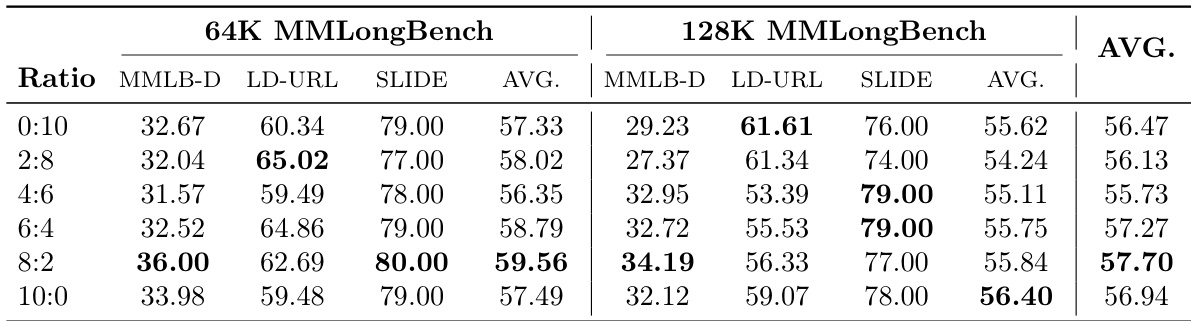
The authors examine the impact of mixing short-context data during long-context training on model performance across various benchmarks. Results show that adding short-context data leads to a trade-off, where short-context performance improves but long-document VQA performance decreases. Pure long-context training preserves short-context capabilities with minimal degradation while achieving the best long-document VQA performance. Mixing short-context data improves short-context performance but reduces long-document VQA performance. Pure long-context training maintains high short-context performance with minimal degradation. Long-document VQA performance is maximized when no short-context data is mixed during training.
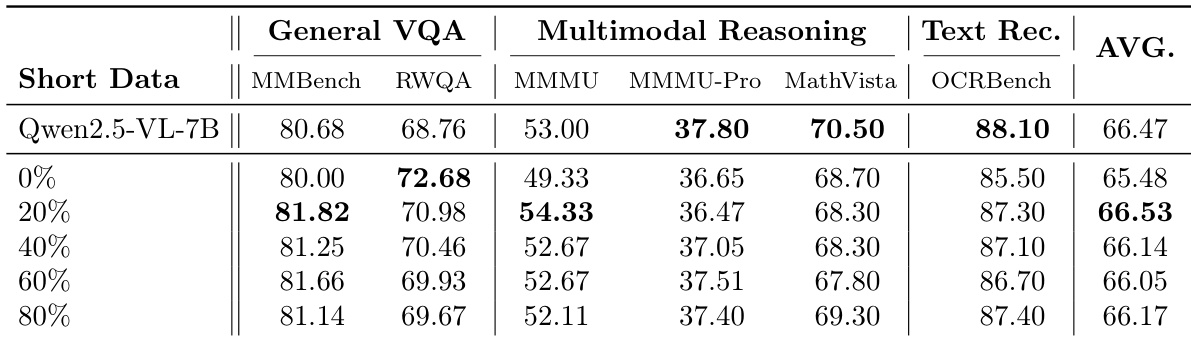
The authors investigate the impact of different data mixing ratios on long-document VQA performance, particularly focusing on the trade-off between short-context and long-context capabilities. Results show that varying the proportion of short-context data during training affects both short-context and long-document VQA performance, with pure long-context training yielding the best long-document results while maintaining strong short-context performance. The optimal balance is found when using a 4:6 ratio of short to long-context data, which achieves high performance on both metrics. Pure long-context training achieves the highest long-document VQA performance while only mildly degrading short-context capabilities. A 4:6 mixing ratio of short to long-context data provides a balanced trade-off, maintaining strong performance on both long- and short-context tasks. The 8:2 ratio yields the best short-context performance but significantly reduces long-document VQA scores, indicating a clear trade-off between the two.
The evaluation compares MMProLong against baseline vision-language models across long-video comprehension and long-document question-answering benchmarks, while also examining the impact of short- versus long-context data mixing during training. Results demonstrate that the proposed method consistently surpasses baselines in video understanding and document-based retrieval, counting, and reasoning without requiring video-specific fine-tuning. Further analysis of training data composition reveals that pure long-context training maximizes long-document capabilities with minimal short-context degradation, whereas strategic data mixing provides a tunable trade-off for balanced performance across both short and long contexts.