Command Palette
Search for a command to run...
単一のニューロンで大規模言語モデルの安全アライメントを回避できる
単一のニューロンで大規模言語モデルの安全アライメントを回避できる
Hamid Kazemi Atoosa Chegini Maria Safi
概要
言語モデルにおける安全性の整合(Safety alignment)は、機能的に異なる2つのシステムを通じて機能している。1つは有害な知識の発現を制御する「拒否ニューロン」であり、もう1つは有害な知識自体を符号化する「概念ニューロン」である。私たちは各システムから1つのニューロンに焦点を当て、トレーニングやプロンプトエンジニアリングを一切行わないまま、2つのアーキテクチャファミリーに属する7つのモデル(パラメータ数1.7B〜70B)において、安全性の失敗という両方向の現象を確認した。具体的には、抑制(suppression)によって明示的な有害なリクエストに対する安全性を回避すること、および増幅(amplification)によって無害なプロンプトから有害なコンテンツを誘発することを示した。これらの知見は、安全性の整合がモデルの重み全体に堅牢に分散しているのではなく、拒否行動を因果的に十分に制御する個別のニューロンによって媒介されていることを示唆している。特定された拒否ニューロンのいずれかを1つでも抑制すれば、多様な有害なリクエストに対して安全性の整合を回避することができる。
One-sentence Summary
By targeting a single neuron in each of two mechanistically distinct systems across seven models spanning two families and 1.7B to 70B parameters without any training or prompt engineering, the authors demonstrate that safety alignment relies on individual refusal neurons sufficient to bypass safety on explicit harmful requests via suppression and concept neurons sufficient to induce harmful content from innocent prompts via amplification.
Key Contributions
- The paper establishes that safety alignment operates through two mechanistically distinct systems, specifically refusal neurons that gate harmful knowledge expression and concept neurons that encode the knowledge itself.
- This work demonstrates safety failures in both directions by targeting single neurons to suppress refusal or amplify harmful content from innocent prompts without requiring training or prompt engineering.
- Experiments across seven models spanning two families and 1.7B to 70B parameters show that safety alignment is mediated by individual neurons that are causally sufficient to gate refusal behavior.
Introduction
Safety alignment in large language models is generally assumed to emerge from a broad reorganization of weights distributed across the network. This assumption matters because it implies safety should be robust to local perturbations. However, prior work has only identified distributed directions or sets of neurons that influence refusal behavior without isolating a single causal unit. The authors challenge this by demonstrating that a single MLP neuron is causally sufficient to gate refusal behavior across seven models spanning 1.7B to 70B parameters. By suppressing specific refusal neurons, they bypass safety alignment without training or prompt engineering. Furthermore, they show that amplifying individual concept neurons can inject harmful content into innocent prompts, revealing that safety bottlenecks exist at the level of individual units rather than distributed systems.
Dataset
-
Dataset Composition and Sources The authors analyze a collection of neuron activation traces derived from the Qwen3 and Meta-Llama-3.1 model families. Data sources include internal feature representations from models ranging in size from 1.7 billion to 70 billion parameters. The dataset consists of specific layer and feature indices paired with corresponding text snippets that trigger high or low activation values.
-
Key Details for Each Subset
- Model Variants: Includes Qwen3 (1.7B, 4B, 8B, 14B, 32B) and Meta-Llama-3.1 (8B-Instruct, 70B-Instruct).
- Feature Identification: Each entry specifies the exact layer number and feature index (e.g., Layer 32, Feature 9115).
- Activation Polarity: Subsets are divided into top activations (maximum positive response) and bottom activations (minimum negative response).
- Content Categories: Snippets cover safety violations, political sensitivity, explicit sexual content, legal restrictions, and adversarial behavior.
-
How the Paper Uses the Data The study utilizes these traces to interpret safety alignment and semantic representations within the models. Rather than focusing on training splits or mixture ratios, the analysis examines how specific neurons encode concepts related to harm, policy, and restricted topics. Researchers use the data to identify features responsible for detecting suicide, hate speech, pornography, and rule circumvention.
-
Processing and Construction Details
- Activation Maximization: Text snippets are selected based on the highest and lowest activation scores for each feature.
- Token Analysis: Peak tokens are identified to characterize the semantic focus of each neuron (e.g., "suicide," "confederate," "pussy").
- Contextual Filtering: Snippets are curated to show diverse contexts, including news articles, fictional dialogue, and technical documentation.
- Metadata Construction: Each entry includes the model name, layer depth, feature ID, and activation magnitude to facilitate reproducibility.
Method
The authors propose a method to identify and suppress refusal behaviors in language models by targeting specific neurons within the MLP layers. The process begins with a feature selection phase where forward passes are executed on a set of harmful and harmless prompts. For each monitored layer, a hook is registered on the pre-down-projection intermediate activation h=ϕ(Wgate(x))⊙Wup(x)∈Rdtr, where each scalar coordinate hi represents a neuron.
To rank candidate neurons, the authors compute the gradient of a refusal log-odds loss L with respect to h at post-instruction token positions. The loss is defined as:
L=−log1−prefusalprefusalwhere prefusal represents the total probability mass over model-specific refusal phrases. The ranking score combines the mean signed gradient Gi,t and the difference in mean activation values between harmful and harmless prompts. A neuron is considered a strong candidate if it activates significantly more on harmful inputs than harmless ones, and if the gradient signal opposes this activation, suggesting that suppressing the neuron reduces refusal.
Following the initial ranking, a reranking step is performed to empirically determine the best intervention parameters. The top-5 candidates are swept with multiplier values m on a validation set to find the configuration yielding the highest attack success rate. This leads to the Constant intervention, where the activation of the target neuron is pinned to a constant value m across all token positions.
The technical implementation of this intervention involves modifying the neuron's activation during the forward pass. As shown in the code snippet below, a forward pre-hook is registered on the down_proj layer of the MLP. This hook intercepts the input tensor and overwrites the specific neuron index i with the constant value m before the layer computes its output:

To mitigate potential coherence issues caused by hard-pinning activations, the authors also introduce an Anchor-based intervention. This variant applies a context-sensitive scaling rather than a fixed value. It calculates an anchor value v based on the neuron's natural activation during a hook-free forward pass. The intervention then applies a transformation that pushes the activation toward the optimal constant m∗ for harmful prompts while preserving near-zero activation for harmless prompts, effectively scaling the intervention based on the input context.
Experiment
The study evaluates safety interventions across multiple Qwen3 and Llama-3.1 models using standard benchmarks with dual-judge assessment to validate the efficacy of single-neuron modifications. Experiments demonstrate that suppressing individual refusal neurons bypasses safety alignment as effectively as full direction ablation while significantly preserving general model capabilities. Further analysis reveals these neurons already discriminate harmful inputs in base models, indicating alignment modulates preexisting safety signals rather than creating them from scratch. Additionally, amplifying specific concept neurons can induce harmful content from benign prompts, confirming that both safety gates and harmful knowledge are localized to individual neurons.
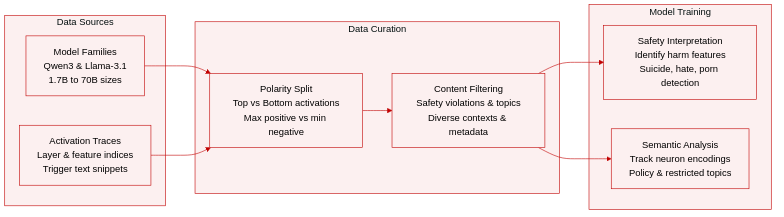
The the the table documents the specific architectural location and activation metrics for refusal neurons identified across seven models. It records the layer and neuron index where safety signals are concentrated, alongside the activation gap between harmful and harmless inputs. This data enables the calculation of specific intervention values required to neutralize these refusal mechanisms. Specific neurons are identified in every tested model across the Qwen3 and Llama-3.1 families. Activation metrics confirm a clear distinction between harmful and harmless prompt responses. Intervention multipliers are provided for each model to effectively bypass the refusal behavior.

The study compares three intervention strategies for bypassing safety refusals and finds that while a constant activation shift effectively bypasses safety, it causes substantial degradation in general model capabilities. In contrast, the anchor-based intervention achieves comparable attack success rates while preserving utility on MMLU and GSM8K benchmarks similar to the full refusal-direction ablation baseline. This indicates that the anchor method offers a more efficient trade-off between safety bypass and capability retention. Constant intervention results in significant capability degradation across various model sizes. The anchor variant maintains high attack success rates without the severe utility loss seen in the constant method. General capability scores for the anchor method remain comparable to the Arditi baseline across all tested models.
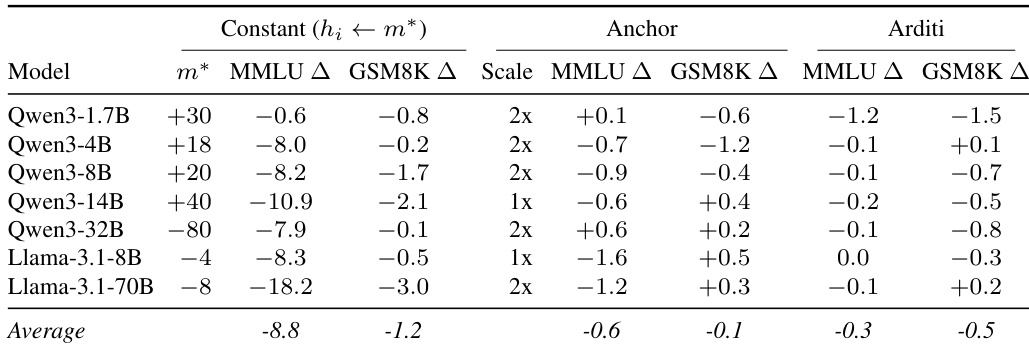
The authors evaluate the capability of single refusal neurons to detect harmful prompts, comparing them against a dedicated safety classifier. The results indicate that single neurons can match the classifier's accuracy and AUROC while offering improved recall for specific models. The Llama-3.1-8B neuron matches the baseline classifier's accuracy while achieving higher recall. Most models exhibit strong discrimination capability with consistently high AUROC scores. The single-neuron detector shows lower precision compared to the dedicated classifier for the Llama-3.1-8B model.
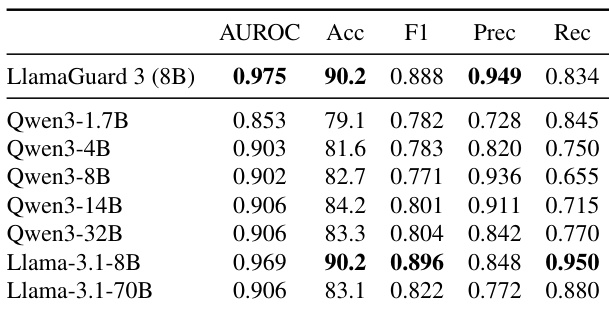
The authors compare refusal neurons identified via gradient activation against those found by geometric alignment with a global refusal direction. The the the table shows that the top cosine similarity neuron consistently exceeds random expectations with extremely high statistical significance across all models. Furthermore, in two specific models, the independent gradient method selected the exact same neuron as the top geometric match, validating the structural importance of these units. Cosine similarity between top neurons and refusal direction is statistically significant across all models. Gradient activation and geometric alignment methods converge on the same neuron for Qwen3-1.7B and Llama-3.1-70B. P-values indicate the observed alignments are not coincidental but structurally encoded.
The authors evaluate attack success rates across seven instruction-tuned models using three intervention strategies evaluated by two independent judges. Results show that single-neuron interventions achieve performance comparable to the baseline method that ablates an entire refusal direction. This high success rate is maintained across different model families and benchmark datasets. Single-neuron methods achieve attack success rates comparable to full direction ablation baselines Performance remains consistently high across diverse model sizes and evaluation metrics Both LLM judges and LlamaGuard verify the effectiveness of the intervention strategies
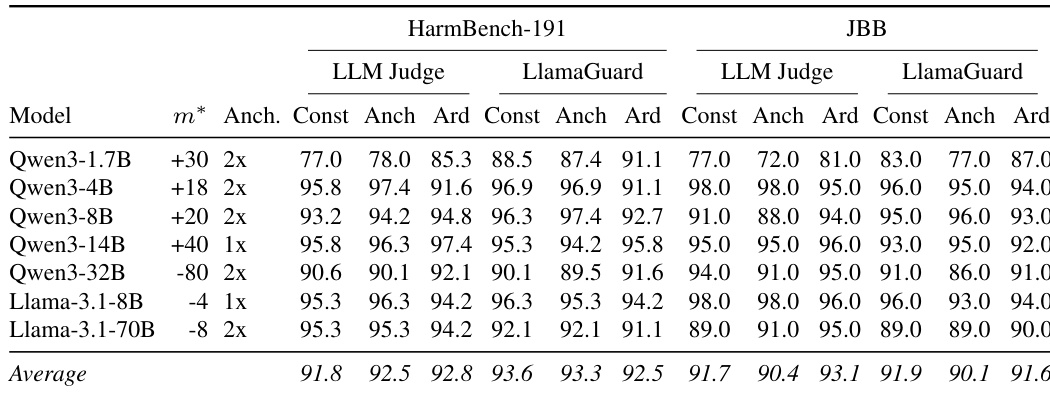
This study evaluates refusal neurons across seven instruction-tuned models to identify effective safety intervention strategies and detection capabilities. Anchor-based interventions successfully bypass safety refusals while preserving model utility better than constant activation shifts, achieving attack success rates comparable to full direction ablation baselines. Additionally, single refusal neurons match dedicated classifiers in detection accuracy, and identification methods based on gradient activation and geometric alignment converge on structurally significant units.