Command Palette
Search for a command to run...
ELF:埋め込み型言語フロー
ELF:埋め込み型言語フロー
Keya Hu Linlu Qiu Yiyang Lu Hanhong Zhao Tianhong Li Yoon Kim Jacob Andreas Kaiming He
概要
拡散モデルおよびフローベースモデルは、画像や動画などの領域において連続データの生成において事実上の標準的なアプローチとなっている。これらの成功は、言語モデルへの応用における関心を高めており、その傾向はますます強まっている。画像領域の対応モデルとは異なり、現在の主要な拡散言語モデル(DLMs)は主に離散のトークン上で動作する。本論文では、最小限の適応で連続DLMsを効果的に実現できることを示す。我们提案するEmbedded Language Flows(ELF)は、連続時間フローマッチング(Continuous-time Flow Matching)に基づく連続の埋め込み空間における拡散モデルの一種である。既存のDLMsとは異なり、ELFは最終的な時間ステップに至るまで主に連続の埋め込み空間内に留まり、最終ステップにおいて共有重みを持つネットワークを用いて離散のトークンへマッピングする。この定式化により、分類器なしガイダンス(CFG)など画像領域の拡散モデルで確立された技術の適応が容易になる。実験結果は、ELFが主要な離散・連続DLMsを大幅に上回り、少ないサンプリングステップ数でより高い生成品質を実現することを示している。これらの結果は、ELFが効果的な連続DLMsへの有望な道筋を提供することを示唆している。
One-sentence Summary
The authors propose Embedded Language Flows (ELF), a class of diffusion models based on continuous-time Flow Matching that operates in continuous embedding space until the final step, where it maps to discrete tokens using a shared-weight network, enabling straightforward adaptation of image-domain techniques like classifier-free guidance to substantially outperform leading discrete and continuous diffusion language models with better generation quality and fewer sampling steps.
Key Contributions
- This work presents Embedded Language Flows (ELF), a class of diffusion models in continuous embedding space based on continuous-time Flow Matching.
- Unlike existing DLMs, ELF predominantly stays within the continuous embedding space until the final time step, mapping to discrete tokens using a shared-weight network. This formulation facilitates adapting image-domain techniques like classifier-free guidance without requiring a separate decoder.
- Experiments show that ELF substantially outperforms leading discrete and continuous diffusion language models by achieving better generation quality with fewer sampling steps.
Introduction
Diffusion and flow-based models have become standard for generating continuous data like images, but adapting them to language modeling faces hurdles due to the discrete nature of text tokens. Existing continuous diffusion language models often suffer from performance gaps or require complex architectures involving separate decoders and per-step discretization losses. The authors propose Embedded Language Flows (ELF), a continuous-time Flow Matching framework that performs denoising within continuous embedding space until the final inference step. This minimalist design avoids separate decoders and enables the direct application of image-domain techniques such as classifier-free guidance. Experiments demonstrate that ELF achieves better generation quality with fewer sampling steps and significantly fewer training tokens than leading discrete and continuous baselines.
Dataset
-
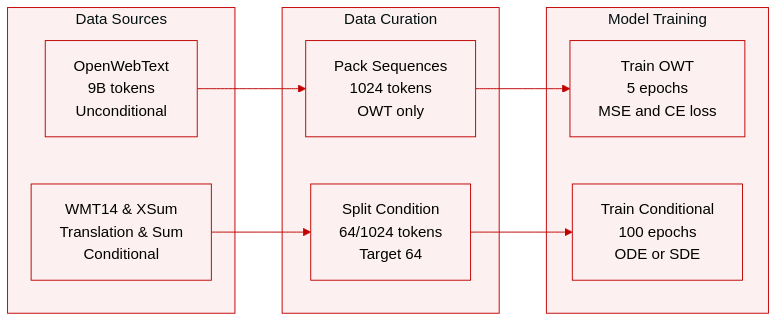
Dataset Composition and Sources
- The authors utilize OpenWebText for unconditional generation, which contains approximately 9 billion tokens.
- Conditional generation tasks rely on the WMT14 German-to-English dataset for machine translation and the XSum dataset for summarization.
-
Key Subset Specifications
- OpenWebText sequences are packed to a length of 1024 tokens.
- WMT14 uses a sequence length of 128 tokens with 64 tokens for the condition and 64 for the target.
- XSum employs a sequence length of 1088 tokens with 1024 tokens for the condition and 64 for the target.
-
Training and Processing
- Sequence packing is applied only to the unconditional dataset.
- The model trains for 5 epochs on OpenWebText and 100 epochs on the conditional datasets.
- Loss functions are mixed with 80% MSE loss and 20% CE loss depending on the model mode.
-
Evaluation and Inference
- Unconditional samples are evaluated using generative perplexity and average unigram entropy.
- Translation quality is measured via BLEU scores on WMT14.
- Summarization performance is assessed using ROUGE-1, ROUGE-2, and ROUGE-L metrics on XSum.
- Inference generation utilizes either ODE or SDE samplers.
Method
The authors propose Embedded Language Flows (ELF), a framework that formulates language modeling as a continuous-time Flow Matching process within an embedding space. Unlike discrete diffusion models, ELF performs denoising primarily in continuous space, converting clean embeddings back to discrete tokens only at the final generation step. This approach allows the model to leverage the iterative nature of flow models for high-dimensional representations.
Refer to the conceptual diagram below which illustrates the continuous flow trajectory.
 The process begins with a Gaussian noise distribution at t=0 and evolves through intermediate states where data clusters form, eventually converging to distinct discrete classes at t=1.
The process begins with a Gaussian noise distribution at t=0 and evolves through intermediate states where data clusters form, eventually converging to distinct discrete classes at t=1.
The overall framework distinguishes between training and sampling phases, as shown in the schematic below.
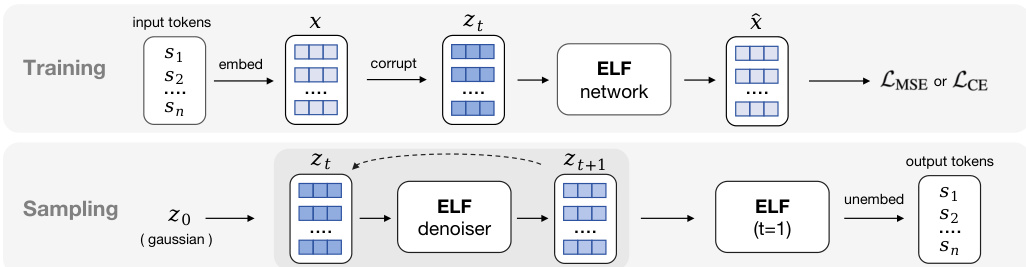 During training, discrete input tokens are embedded into a continuous space and corrupted with noise to create latent variables zt. The ELF network predicts the clean embeddings, and the model is optimized using either Mean Squared Error (MSE) for the denoising objective or Cross-Entropy (CE) for the final decoding step. In the sampling phase, the process starts from Gaussian noise z0. The ELF denoiser iteratively refines the latent variable through time steps t, and a final pass at t=1 performs the unembedding to produce discrete output tokens.
During training, discrete input tokens are embedded into a continuous space and corrupted with noise to create latent variables zt. The ELF network predicts the clean embeddings, and the model is optimized using either Mean Squared Error (MSE) for the denoising objective or Cross-Entropy (CE) for the final decoding step. In the sampling phase, the process starts from Gaussian noise z0. The ELF denoiser iteratively refines the latent variable through time steps t, and a final pass at t=1 performs the unembedding to produce discrete output tokens.
The training pipeline incorporates specific modules to handle conditioning and guidance. A detailed view of these components is provided below.
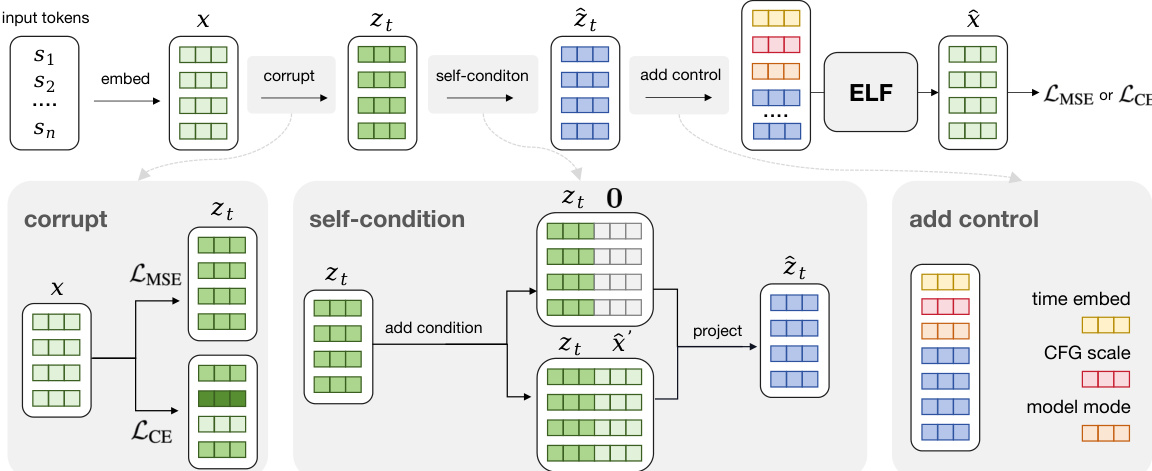 The process starts with embedding the input tokens into clean vectors x. The "corrupt" module generates noisy embeddings zt via linear interpolation between the clean data and noise. The "self-condition" module concatenates the previous prediction x^′ or a zero vector with the noisy embedding to provide intermediate context, followed by a projection layer to maintain dimensionality. Finally, the "add control" module prepends learnable tokens encoding the time step, Classifier-Free Guidance (CFG) scale, and the model mode (denoise or decode).
The process starts with embedding the input tokens into clean vectors x. The "corrupt" module generates noisy embeddings zt via linear interpolation between the clean data and noise. The "self-condition" module concatenates the previous prediction x^′ or a zero vector with the noisy embedding to provide intermediate context, followed by a projection layer to maintain dimensionality. Finally, the "add control" module prepends learnable tokens encoding the time step, Classifier-Free Guidance (CFG) scale, and the model mode (denoise or decode).
Mathematically, the flow velocity v is defined as the time derivative of the latent variable zt. The authors parameterize the network to predict the clean embedding x rather than the velocity directly. The training objective minimizes the mean squared error between the predicted and target velocities:
LMSE=Et,x,ϵ(1−t)21∥xθ(zt,t)−x∥2For the final decoding step at t=1, the model minimizes a cross-entropy loss between the unembedded logits and the ground-truth tokens. This x-prediction parameterization enables effective Flow Matching on high-dimensional embeddings and aligns the denoising objective with the final token prediction task.
The underlying architecture utilizes a standard Diffusion Transformer backbone incorporating SwiGLU activation, RMSNorm, and RoPE positional embeddings. Instead of standard adaptive layer normalization, the model employs in-context conditioning by prepending control tokens, which reduces the parameter count and allows for flexible conditioning on time and guidance scales.
Experiment
The study evaluates Embedded Language Flows through ablation studies on unconditional generation and system-level comparisons on translation and summarization tasks against various baselines. Ablation results indicate that pretrained contextual embeddings and stochastic sampling strategies effectively balance generative quality and diversity, while model scaling consistently enhances performance across the quality-diversity trade-off. Overall, the experiments validate that ELF achieves superior efficiency and quality compared to prior diffusion language models, producing fluent and semantically aligned text with substantially reduced training and inference costs.
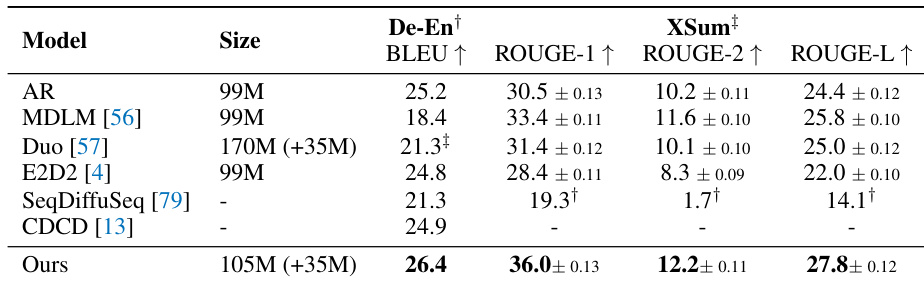
The authors evaluate their model against several autoregressive and diffusion-based baselines on machine translation and text summarization tasks. The results indicate that their approach achieves superior performance, consistently outperforming all compared methods across the reported evaluation metrics. The proposed model achieves the highest BLEU score on the De-En translation task among all listed baselines. On the XSum summarization task, the model outperforms all competitors across ROUGE-1, ROUGE-2, and ROUGE-L metrics. The method demonstrates superior performance while maintaining a parameter count similar to the compared discrete and diffusion-based models.
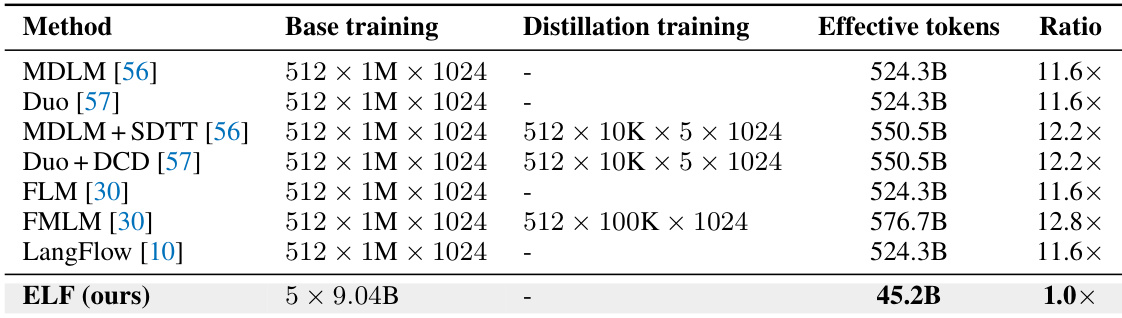
The authors compare the training efficiency of their proposed ELF model against several baseline diffusion language models. The results indicate that ELF is substantially more data-efficient, utilizing a significantly smaller fraction of the effective training tokens required by prior methods, including those that employ distillation strategies. The proposed ELF method requires substantially fewer effective training tokens than all compared baseline models. Baseline models typically consume more than ten times the token budget of the proposed method to achieve similar settings. Unlike several baselines that rely on additional distillation training stages, the proposed method achieves its results without extra distillation phases.
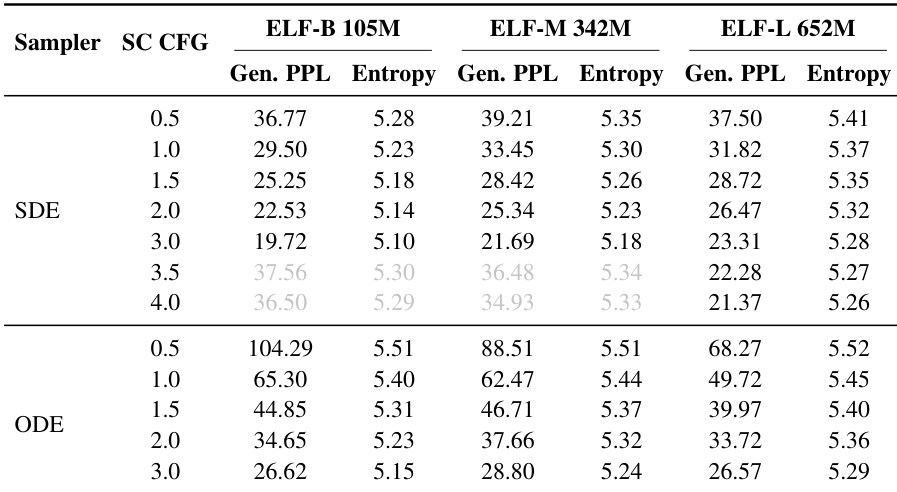
The authors evaluate the impact of sampling methods and guidance scales on ELF models of varying sizes. Results indicate that SDE sampling achieves lower generative perplexity than ODE sampling, while increasing the CFG scale improves quality at the cost of diversity. SDE sampling consistently yields lower generative perplexity than ODE sampling for equivalent CFG settings. Higher CFG scales reduce generative perplexity but also decrease entropy, highlighting a trade-off between sample quality and diversity. Larger model configurations generally maintain higher entropy values, indicating better diversity retention compared to smaller models.
The authors define three model scales with increasing parameter counts and architectural complexity. As model size increases, depth and hidden dimensions grow while training epochs decrease. This scaling consistently improves the generative perplexity-entropy frontier. Model depth and hidden size increase from the smallest to the largest variant. Training epochs decrease as the parameter count grows. Larger models achieve better quality-diversity trade-offs according to the scaling study.

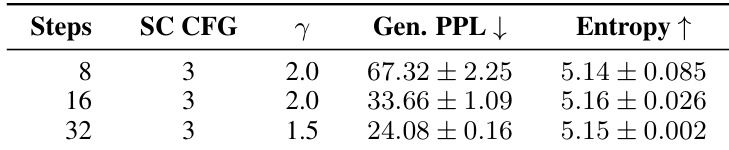
The authors evaluate the impact of sampling steps on unconditional generation using SDE sampling. Increasing the number of steps leads to a significant reduction in generative perplexity while maintaining stable entropy levels. Generative perplexity improves markedly as the sampling steps increase. Entropy remains consistent across different sampling budgets. The setup employs a self-conditioning CFG scale of 3 with varying noise injection scales.
The authors evaluate their proposed ELF model against autoregressive and diffusion-based baselines on translation and summarization tasks, demonstrating superior performance with comparable parameter counts and significantly higher training efficiency. Additional experiments investigate sampling strategies and model scaling, revealing that SDE sampling outperforms ODE while larger model configurations achieve better trade-offs between quality and diversity. Furthermore, increasing guidance scales enhances quality at the cost of diversity, whereas adding more sampling steps improves generation quality while maintaining diversity.