Command Palette
Search for a command to run...
LLaVA-UHD v4: MLLMにおける効率的な視覚エンコーディングの鍵とは
LLaVA-UHD v4: MLLMにおける効率的な視覚エンコーディングの鍵とは
Kechen Fang Yihua Qin Chongyi Wang Wenshuo Ma Tianyu Yu Yuan Yao
概要
視覚エンコーディングは、マルチモーダル大規模言語モデル(MLLMs)における主要な計算ボトルネックとなっており、特に高解像度画像の入力においてその傾向が顕著である。現在の主流な手法は、通常、グローバルエンコーディングに続き、ViT(Vision Transformer)後の圧縮を行うものである。グローバルエンコーディングでは巨大なトークン系列が生成されるが、ViT後の圧縮では、トークン削減が行われる前にViTのフルな二次計算量(quadratic attention cost)を招いてしまう。本稿では、エンコーディング戦略と視覚トークン圧縮の2つの観点から、この既存の慣行を見直す。まず、制御実験の結果、スライスベースのエンコーディングがベンチマークにおいてグローバルエンコーディングを上回る性能を示した。これは、細粒度な知覚にはグローバルな注意機構を適用するよりも、スライスされたビューを通じて局所的な詳細を保持することの方が有益であることを示唆している。第二に、ViT内部の早期圧縮(intra-ViT early compression)を導入した。これは、ViTの浅い層でトークンを削減し、下流のタスク性能を維持しつつ、視覚エンコーディングに必要な浮動小数点演算数(FLOPs)を大幅に低減するものである。ViT内部の圧縮をスライスベースのエンコーディング枠組みに統合することで、本稿では高解像度入力向けに設計された、効率的かつ計算コストを制御可能な視覚エンコーディングスキーム「LLaVA-UHD v4」を提案する。ドキュメント理解、OCR、および一般的なVQA(Visual Question Answering)をカバーする多様なベンチマークにおいて、LLaVA-UHD v4は視覚エンコーディングのFLOPsを55.8%削減しつつ、ベースライン性能と同等、あるいはそれを上回る性能を実現した。
One-sentence Summary
The authors present LLaVA-UHD v4, an efficient and compute-controllable visual encoding scheme for multimodal large language models tailored for high-resolution inputs that integrates slice-based encoding with intra-ViT early compression to reduce visual-encoding FLOPs by 55.8% while matching or surpassing baseline performance across document understanding, OCR, and general VQA benchmarks.
Key Contributions
- Controlled experiments demonstrate that slice-based encoding outperforms global encoding across benchmarks by preserving local details through sliced views. This finding suggests that sliced views are more beneficial than applying global attention for fine-grained perception.
- The paper introduces a novel parameter-reusing intra-ViT early compression module that reduces tokens in shallow ViT layers. This technique substantially lowers visual-encoding FLOPs while maintaining downstream performance.
- The paper presents LLaVA-UHD v4, an efficient visual encoding scheme integrating intra-ViT compression into the slice-based framework. Experiments across document understanding, OCR, and general VQA benchmarks show a 55.8% reduction in visual-encoding FLOPs while matching or surpassing baseline performance.
Introduction
Multimodal Large Language Models increasingly rely on high-resolution inputs for fine-grained perception, yet the standard global encoding paradigm creates a quadratic computational bottleneck as image area grows. Existing efficiency solutions typically apply token compression after the vision encoder completes its heavy computation, and attempts to compress tokens internally often disrupt pretrained visual representations. The authors challenge the global encoding convention by demonstrating that slice-based strategies offer superior detail preservation without the quadratic overhead. They further introduce a parameter-reuse early compressor inserted into the shallow layers of the vision encoder that initializes using adjacent pretrained weights to maintain representation stability. This approach powers LLaVA-UHD v4, enabling aggressive token reduction inside the encoder itself to achieve significant speedups while maintaining competitive accuracy.
Method
The authors propose LLaVA-UHD v4, a visual encoding scheme designed to address the computational bottlenecks associated with high-resolution inputs in Multimodal Large Language Models. The architecture fundamentally shifts from the prevailing global encoding paradigm to a slice-based approach combined with intra-ViT early compression.
As shown in the figure below:
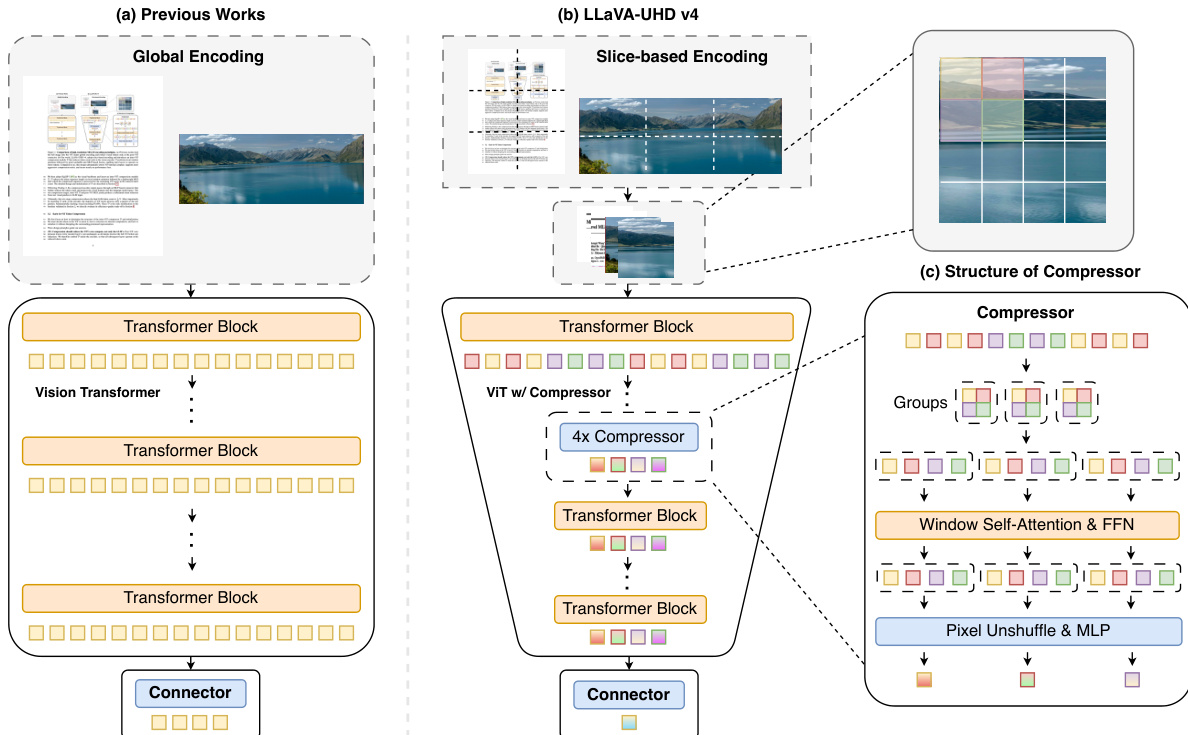
The framework begins by decomposing the input image into a low-resolution thumbnail and a set of high-resolution slices selected by an aspect-ratio-aware policy. Unlike previous works that process the entire image globally before token reduction, LLaVA-UHD v4 rescales and concatenates these views along the sequence dimension. This allows the Vision Transformer (ViT) to process them in a single forward pass while preserving per-view attention locality.
A key innovation is the integration of an intra-ViT early compressor module, denoted as D. This module is inserted directly into the ViT backbone, specifically after layer k=6, to reduce the token sequence length before the deeper layers process the data. This design choice adheres to the principle that compression should reduce the ViT's own compute, not just the downstream LLM's load. By reducing the token count early, the majority of the ViT layers operate on a significantly smaller sequence, slashing visual-encoding FLOPs.
The internal structure of the compressor D consists of two primary stages. First, a window attention operator WinAttn2×2 is applied to the input token sequence Xk. This attention is restricted to non-overlapping 2×2 windows, ensuring that each token interacts only with its three spatial neighbors to enrich local context. Second, a downsample-and-fuse block follows. A 2×2 PixelUnshuffle operation reshapes the intermediate representation Y into Z∈RN/4×4d. Finally, an MLP fuses these concatenated channels back to the original dimension d, producing the compressed sequence X.
To ensure that inserting this new module does not disrupt the pretrained representation manifold of the ViT, the authors employ a parameter-reuse initialization strategy. Rather than random initialization, D is initialized using the weights of the preceding ViT layer k. Specifically, the attention projections and LayerNorms are copied directly, while the MLP weights are constructed to mimic applying the original Feed-Forward Network independently to each patch within a window followed by averaging. The weight matrices are defined as:
W1=BlockDiag(F1(k),F1(k),F1(k),F1(k)),W2=λ1[F2(k)∣F2(k)∣F2(k)∣F2(k)].This initialization allows fine-tuning to begin on or near the pretrained manifold, avoiding the need to recover it from scratch.
Following the intra-ViT compression, the encoded visual features pass through a post-ViT MLP connector. This stage further reduces the token count and projects the features into the language model space. The combination of the intra-ViT compressor and the post-ViT connector achieves an end-to-end 16× reduction in token count.
The training process follows a four-stage recipe to optimize the model. First, vision-language alignment is performed on large-scale image-text pairs, updating only the projector and the new compressor D. Second, knowledge injection occurs via OCR, document, and chart data with only the ViT unfrozen. Third, interleaved training on image-text sequences facilitates multi-image and long-context reasoning. Finally, supervised instruction tuning is applied on a diverse mixture of general VQA, math, and conversational tasks to refine the model's capabilities.
Experiment
Controlled experiments on high-resolution MLLMs reveal that slice-based encoding consistently outperforms global encoding by preserving locality, while spatial-merging MLP connectors prove superior to query-based resamplers by maintaining explicit spatial correspondence. Furthermore, shifting compression inside the ViT pipeline substantially reduces computational costs without compromising accuracy when utilizing local window attention and weight reuse at an intermediate layer depth. These findings collectively establish a more efficient architecture that balances visual encoding quality with compute savings.
The authors evaluate various intra-ViT compression designs to determine how to effectively reduce visual tokens inside the encoder. The results indicate that simple merging strategies like average pooling or standard MLPs often underperform or match the post-ViT baseline, whereas designs incorporating local window attention and weight reuse yield superior performance. Specifically, combining window attention with a reused MLP projector achieves the highest average accuracy, demonstrating that preserving local context and aligning with pretrained weights are critical for effective early compression. The Win-Attn w/ Reused MLP method achieves the highest average score, outperforming the Post-ViT Baseline. Naive compression strategies such as Pixel-Unshuffle MLP and Average Pooling generally yield lower or comparable results to the baseline. Methods incorporating window attention tend to outperform cross-attention variants and simple MLP projections.
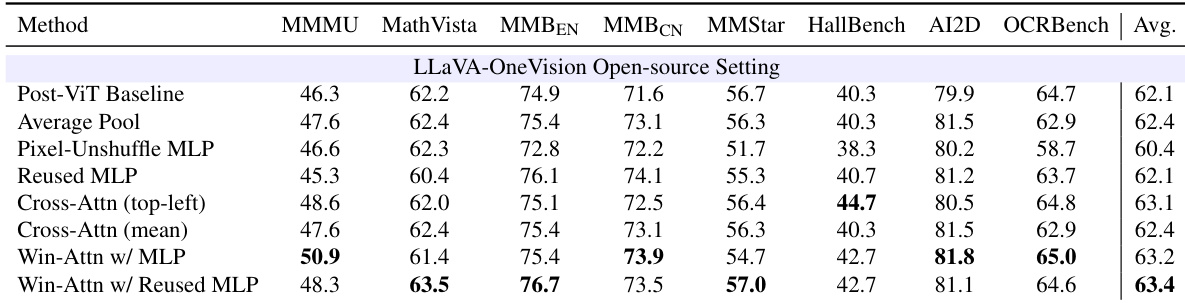
The authors evaluate naive in-ViT compression strategies against a post-ViT baseline to assess the trade-off between efficiency and accuracy. Results show that moving compression inside the ViT drastically reduces computational cost, yet simple merging methods like average pooling and pixel-unshuffle fail to match the baseline's performance. This indicates that early token reduction requires more sophisticated design to preserve representational quality. In-ViT compression methods achieve significantly lower computational costs than the post-ViT baseline. Naive merging strategies result in a noticeable drop in average accuracy compared to the baseline. Pixel-unshuffle performs slightly better than average pooling but remains inferior to the post-ViT baseline.

The authors evaluate intra-ViT compression strategies using cross-attention against a post-ViT baseline. The results demonstrate that internal compression significantly reduces computational cost while maintaining competitive accuracy, with the top-left query strategy performing nearly as well as the baseline. Intra-ViT compression achieves a substantial reduction in FLOPs compared to the post-ViT baseline. The top-left query strategy preserves accuracy at levels comparable to the baseline. The mean query strategy results in a minor performance drop relative to the top-left approach.

The authors conduct a robustness study replacing the standard SigLIP 2 backbone with MoonViT and testing an alternative higher-resolution slicing schedule under a 16x compression rate. In these settings, Slice-based Encoding consistently matches or outperforms Global Encoding, with the performance gap increasing as the training data scale expands. Slice-based encoding achieves higher average accuracy than global encoding across all tested data scales and configurations. The performance advantage of the proposed method is most significant on OCR-intensive benchmarks requiring fine-grained recognition. Increasing the training data volume from 8M to 16M samples further amplifies the benefits of slice-based encoding over the baseline.
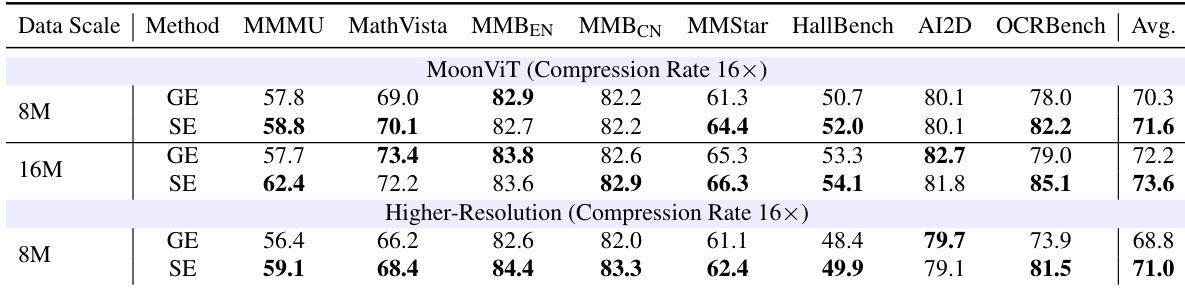
The authors evaluate the robustness of slice-based encoding against global encoding using different vision backbones and resolution settings. Results indicate that slice-based encoding consistently outperforms global encoding across all tested configurations, including the MoonViT backbone at varying data scales and a higher-resolution slicing schedule. Slice-based encoding maintains a performance advantage over global encoding when using the MoonViT backbone across different data scales. Adopting a higher-resolution slicing schedule further widens the performance gap in favor of slice-based encoding. The effectiveness of slice-based encoding generalizes across different visual encoder architectures and training data volumes.
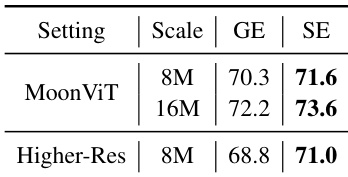
The study assesses intra-ViT compression designs and slice-based encoding strategies against post-ViT baselines to balance efficiency with accuracy. Findings reveal that naive merging strategies degrade performance, while incorporating local window attention and weight reuse preserves representational quality for superior results. Furthermore, robustness evaluations show that slice-based encoding consistently outperforms global encoding across different architectures and data scales, with advantages increasing as training volume grows.