Command Palette
Search for a command to run...
ArcANE: Bleiben Language Agents im Rollenspiel zur richtigen Zeit in Charakter?
ArcANE: Bleiben Language Agents im Rollenspiel zur richtigen Zeit in Charakter?
Woojung Song Nalim Kim Sangjun Song Chaewon Heo Jongwon Lim Yohan Jo
Zusammenfassung
Role-playing language agents (RPLAs) sollten Charaktere übernehmen, deren Werte und Verhalten sich im Verlauf der Geschichte entwickeln, anstatt eine feste Persona beizubehalten. Bestehende Benchmarks erfassen das faktische Abrufen zu einem bestimmten Kapitel, nicht jedoch, ob die Antworten mit dem psychologischen Verlauf des Charakters übereinstimmen, insbesondere in Szenarien, die der Quelltext niemals behandelt. Wir stellen ArcANE (Arc-Aware Narrative Evaluation) vor, einen automatisch konstruierten Benchmark, der 17 Romane und 80 Hauptcharaktere umfasst. Ein Character Arc unterteilt die Erzählung entlang einer psychologischen Achse in Phasen, und jede Abfrage stellt über die Phasen hinweg dasselbe Szenario, das sowohl Situationen innerhalb des Quelltexts als auch solche außerhalb desselben abdeckt. Über sechs Modelle und sechs Kontextmodi hinweg übertrifft die Konditionierung auf den Character Arc auf jedem Modell jede andere Kontextstrategie, und die Lücke ist bei Szenarien außerhalb des Quelltexts am größten, bei denen das Retrieval nichts zu finden hat. Zudem feintunen wir Open-Weight-Modelle auf denselben Daten, um ArcANE-8B/32B zu erhalten, die den Vorteil des Character Arc bei Szenarien außerhalb des Quelltexts noch weiter vergrößern.
One-sentence Summary
ARcANE is an automatically constructed benchmark spanning 17 novels and 80 principal characters that evaluates role-playing language agents by segmenting narratives into psychological Character Arcs to test character alignment across evolving story phases, demonstrating that arc-conditioning outperforms all other context strategies, particularly on out-of-text scenarios, while fine-tuned ARcANE-8B and ARcANE-32B models further amplify this advantage.
Key Contributions
- This work introduces ARcANE, an automatically constructed benchmark spanning 17 novels and 80 principal characters, to evaluate whether language agents align with a character's evolving psychological trajectory rather than static factual recall.
- The study develops a Character Arc framework that segments narratives into psychological phases and probes agents with identical scenarios across these phases to capture behavioral shifts within and beyond the source text.
- Evaluations across six models and six context modes demonstrate that Arc-grounded conditioning consistently outperforms alternative strategies, with fine-tuned ARcANE-8B and ARcANE-32B models further amplifying this advantage in out-of-narrative scenarios.
Introduction
Role-playing language agents power interactive storytelling, gaming, and companion AI, where users expect immersive experiences that mirror how characters realistically evolve over time. Prior evaluation frameworks, however, treat personas as static targets, primarily measuring factual recall or surface-level stylistic consistency at fixed moments. This approach fails to capture how a character’s core values and behavioral patterns shift as narrative events accumulate. To address this limitation, the authors introduce ARCANE, a benchmark that evaluates temporal behavioral fidelity by mapping character development onto structured psychological trajectories. By testing agents against phase-specific probes, including scenarios never encountered in the source material, they demonstrate that grounding models in narrative arcs significantly improves how faithfully they portray evolving character states.
Dataset
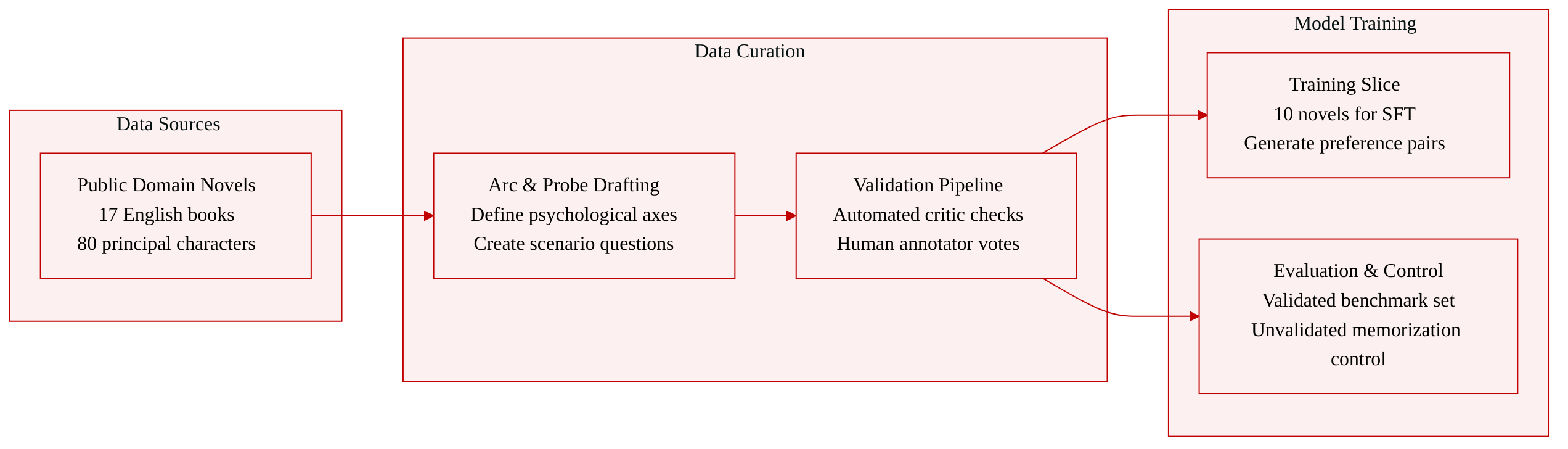
Dataset Composition and Sources
- The authors compile ARCANE from 17 English-language novels in the U.S. public domain, primarily sourced from Project Gutenberg. The corpus covers 80 principal characters across 544 psychological development axes and contains 4,601 structured probes.
- All data is serialized into JSON records tracking character arcs and probe responses, with metadata capturing literary validation, annotator votes, and quality control logs.
Key Details for Each Subset
- Training Slice: Contains 10 novels and 2,545 probes. This subset serves as the foundation for supervised fine-tuning and preference optimization data generation.
- Validated Evaluation Slice: Comprises 5 novels and 1,754 probes. The authors apply a rigorous filtering pipeline where every axis must pass an automated critic ensemble and secure a two-out-of-three majority from human annotators before inclusion.
- Unvalidated Low-Popularity Slice: Includes 2 novels and 302 probes drawn from the bottom tier of Project Gutenberg popularity metrics. This slice is held out from human review to serve as a memorization control.
Data Usage and Processing
- The training slice yields 45,690 supervised fine-tuning rows. The authors generate these by sampling three completions each from gpt-5.4-mini and claude-sonnet-4-6 with a temperature of 0.9 and an 800-token limit, pooling outputs to reduce single-model bias.
- For preference optimization, the authors construct 14,671 direct preference pairs across 12 novels and 2,838 probes. Each pair uses the anchor phase response as the chosen output and an adjacent phase response as the rejected output, isolating character development shifts as the sole variable.
- During evaluation, the authors test multiple context modes including vanilla identity prompts, five-chapter summaries, retrieval-augmented generation using top-6 text chunks, and a custom arc mode that feeds the curated character trajectory truncated at the query chapter.
Metadata Construction and Processing Details
- Character arcs are built by defining psychological dimensions with opposing poles, directional tags, and life-stage classifications. Probes are drafted across three difficulty tiers based on source distance: In-Scenario (verbatim passages), In-World (setting-consistent inventions), and Out-of-World (era-transposed scenarios).
- A multi-stage validation pipeline enforces strict quality standards. The authors run Q-Voice checks for in-character consistency and knowledge cutoff compliance, Q-PhaseFit to verify phase alignment via blind LLM judging, and Q-Anchor/World checks for setting rules. Probes failing these checks undergo automated regeneration, while adjacent phase pairs with indistinguishable responses are flagged for analysis.
- Each probe record includes an anchor query chapter that acts as a knowledge cutoff, ensuring models cannot reference later plot developments. All validator verdicts, retry counts, and annotator validity scores are embedded directly in the dataset schema.
Method
The ArcANE framework is structured around a three-stage pipeline for constructing and evaluating character arcs, which are defined as phase-segmented trajectories of a character's evolving psychological and relational states. The overall process begins with character arc construction, proceeds to probe generation, and concludes with validation and filtering. The framework leverages two independent streams—event and state—to generate candidate axes, which are then reconciled and validated through a combination of LLM critics and human annotators.
The first stage, candidate generation, processes a novel through two parallel, chapter-level streams. The event stream extracts psychologically impactful events, such as shifts in emotion, belief, or relationship dynamics, while the state stream emits a cross-sectional psychological profile of the character, capturing emotional state, beliefs, desires, intentions, and self-awareness. Each stream independently induces two types of candidate axes: intrapersonal axes track internal changes in beliefs, motives, and coping mechanisms, and relational axes track dyadic relationships, including trust, esteem, intimacy, and antagonism. This dual-stream design ensures that failures in event omission and state misreading are separable, providing an internal reliability check. The resulting candidate axes are grounded in established literary and psychological scholarship, following the construct-grounding criterion of Values in the Wild.
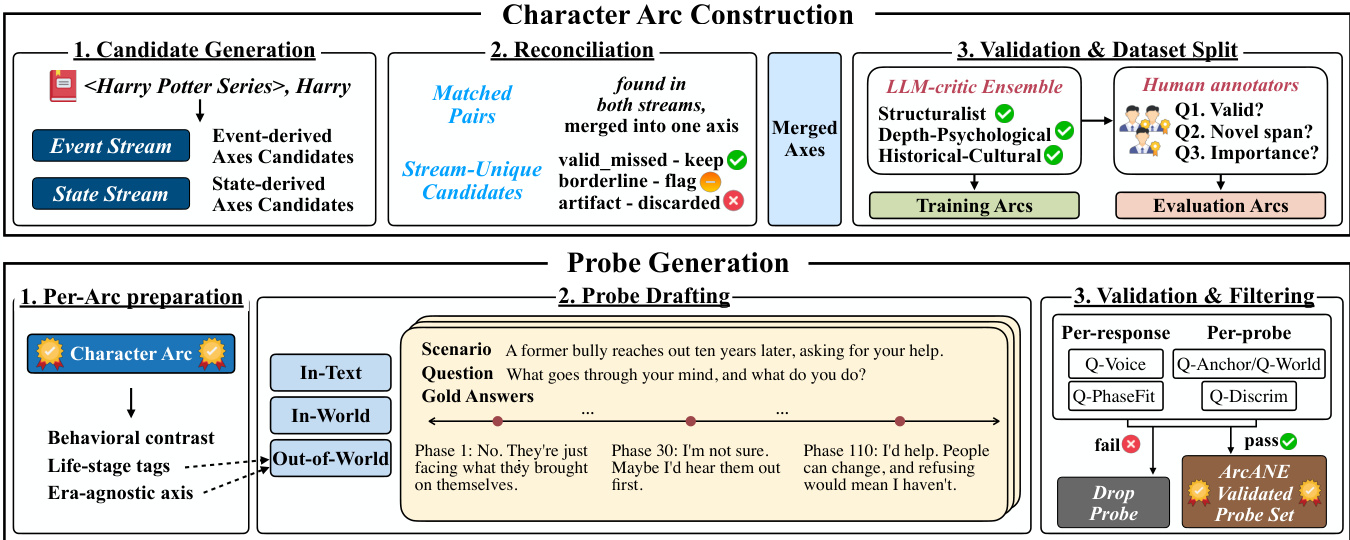
The second stage, reconciliation, involves an analyst LLM that compares the candidate axes from the two streams. Matched pairs—axes proposed by both streams—are merged into a single axis, with a direction label indicating the pole each phase is closer to. Unmatched candidates are classified as valid missed (kept), borderline (flagged), or artifact (discarded), based on their plausibility and evidence. This step ensures that only robust, cross-validated axes proceed to the final dataset.

The third stage, validation and dataset split, ensures external validity. The merged axes are passed through an LLM-critic ensemble consisting of three perspectives: structuralist/narratologist, depth-psychological, and historical/cultural. Each critic evaluates the axis against their respective scholarly framework and provides citations. For training novels, an axis is retained only if at least two of the three critics judge it literally grounded. For evaluation novels, the critic ratings serve as a reference, and human annotators independently re-assess each axis for validity, novel span, and importance, with validity gated by a 2-of-3 majority rule.

Following arc construction, the pipeline proceeds to probe generation, which creates behavioral probes to evaluate a model's ability to distinguish subtle shifts in character behavior across narrative phases. The process begins with per-arc preparation, where the character arc is used to generate era-agnostic axes and life-stage tags. Probes are then drafted for three types: In-Text, In-World, and Out-of-World, each with specific constraints and stylistic guidelines. The draft phase produces a scenario, question, and a set of phase responses, each representing the character's behavior at a specific point in their arc.

The final stage, validation and filtering, ensures the probes are faithful to the source and properly differentiated. Per-response validation uses a Q-PhaseFit model to determine which phase a response is most diagnostic of, comparing it to the target phase. If the response is off-phase, it is regenerated. Per-probe validation checks for worldbuilding consistency and the absence of canonical scene reproduction. The trajectory rubric assesses alignment, direction, and shape of the character's change across phases, with adjacent pairs being differentiated based on the decision variable. This comprehensive validation ensures that the resulting probe set accurately reflects the character's arc and can be used to evaluate model performance.
Experiment
The evaluation assesses six language models across multiple context strategies using a benchmark of novel-based character arcs, validating whether structured narrative guidance improves agents' ability to track psychological progression. Results consistently show that conditioning on explicit character trajectories outperforms alternative context methods, particularly for scenarios beyond the source text where traditional retrieval fails. Qualitative analysis indicates this advantage reflects genuine directional tracking of character development rather than isolated scene matching, with fine-tuning experiments demonstrating that preference optimization successfully instills dynamic voice shifts aligned with narrative progression. Ablation studies further confirm that these improvements stem from structured arc content rather than pretraining memorization or structural artifacts.
{"summary": "The authors evaluate multiple language models under different context strategies, focusing on their ability to maintain character consistency across narrative arcs. The results show that conditioning on the Character Arc consistently outperforms other context methods across all models, particularly in scenarios that extend beyond the source text. The performance gap is most pronounced on trajectory-level metrics, indicating that the Arc strategy better captures the evolving psychological trajectory of characters.", "highlights": ["Arc conditioning consistently outperforms other context strategies across all models, especially in scenarios outside the source text.", "The performance gap between Arc and other methods is largest on trajectory-level metrics, highlighting better capture of character evolution.", "The advantage of Arc conditioning is most significant on models fine-tuned on the same data, suggesting enhanced alignment with character arcs."]
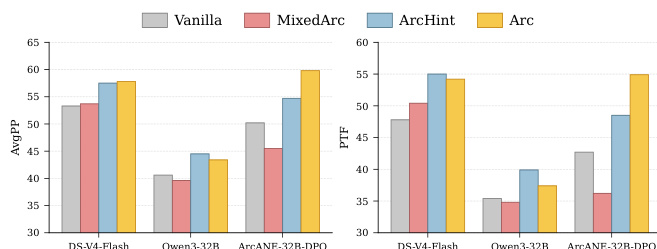
{"summary": "The authors evaluate multiple models under different context strategies, focusing on the impact of character arc grounding on role-playing performance. Results show that arc-based context consistently outperforms other strategies, with the largest gains observed in scenarios outside the source text. The advantage is particularly pronounced on trajectory-level metrics, indicating improved alignment with a character's evolving psychological state.", "highlights": ["Arc-based context consistently outperforms other strategies across all models, with the largest gains in scenarios outside the source text.", "The performance gap between arc-based and non-arc methods widens as the scenario moves from in-scenario to out-of-world.", "The trajectory-level metric shows a stronger advantage for arc-based context compared to per-phase metrics, indicating better tracking of character development over time."]
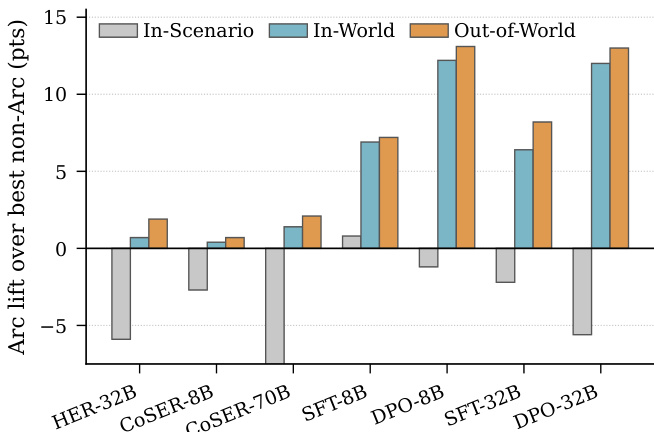
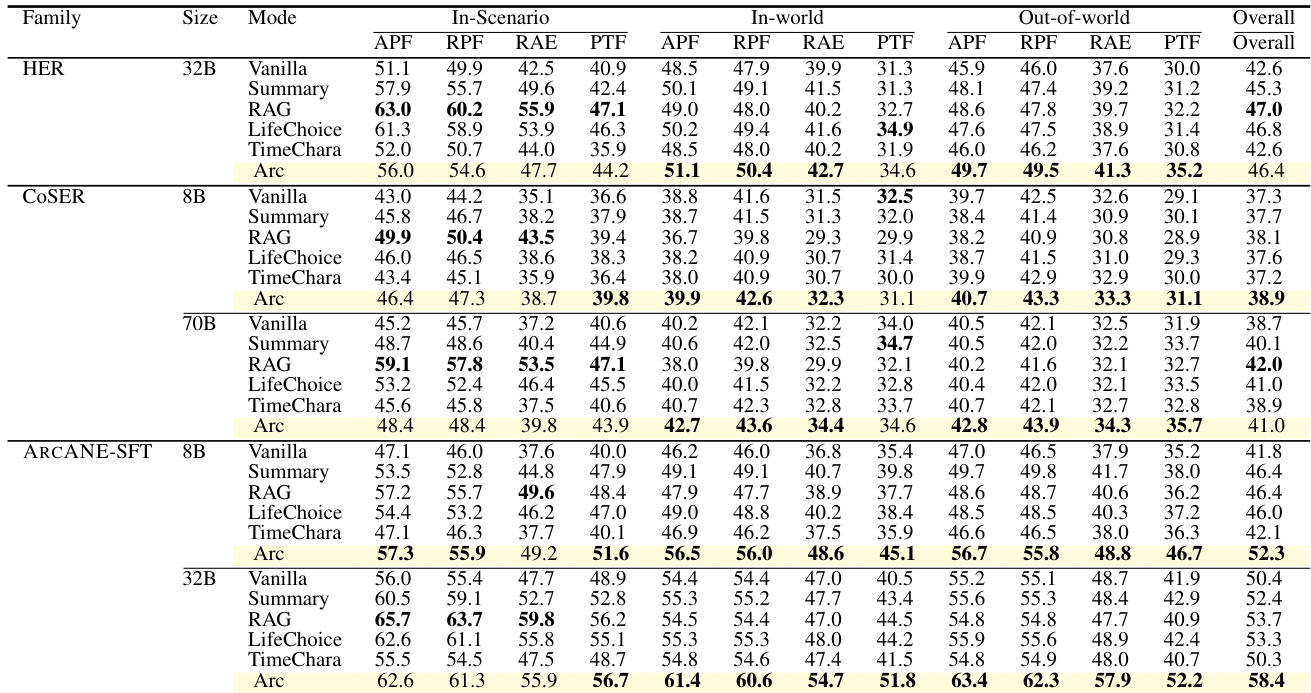
The authors evaluate multiple models under different context strategies on a benchmark that assesses character arc consistency in narrative responses. Results show that conditioning on the character arc leads to superior performance across all models, particularly on scenarios that extend beyond the source text and on trajectory-level metrics that capture narrative coherence over time. Conditioning on the character arc consistently outperforms other context strategies across all models and metrics. The performance gap between arc-based and non-arc-based methods is largest on scenarios outside the source text, where retrieval-based methods have no relevant information. The arc-based approach achieves the highest scores on trajectory-level metrics, indicating better alignment with the character's psychological progression over time.
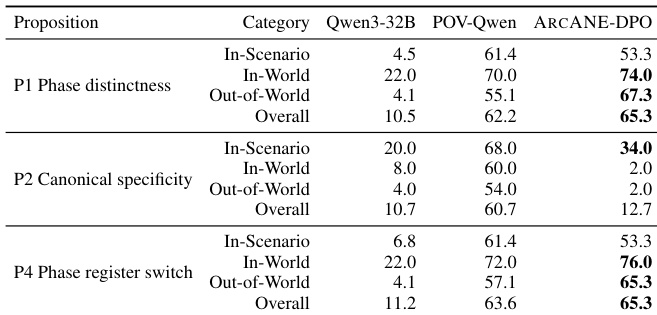
The authors evaluate multiple language models across different context strategies on a benchmark that assesses character arc fidelity in narrative role-playing. Results show that conditioning on the Character Arc consistently outperforms other strategies across all models, with the largest gains observed on scenarios outside the source text and for trajectory-level coherence. The advantage is particularly pronounced for larger models and when fine-tuned on the benchmark data. Conditioning on the Character Arc achieves the highest overall performance across all models, outperforming other context strategies. The performance gap between Arc and non-Arc methods is largest for out-of-world scenarios and trajectory-level metrics. Fine-tuned models on the benchmark data show a greater Arc advantage, especially in out-of-world and trajectory evaluation.
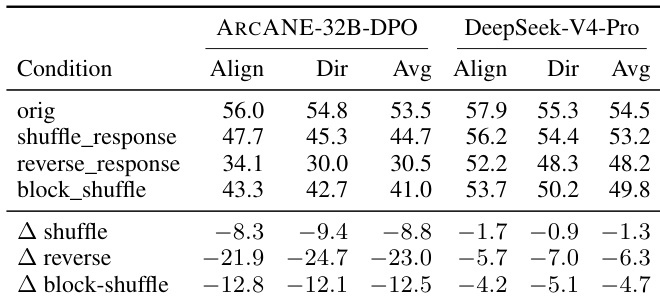
The authors evaluate the impact of different response ordering perturbations on trajectory fidelity metrics for two models, ARcANE-32B-DPO and DeepSeek-V4-Pro, using a the the table that reports scores for alignment, direction, and average metrics. The results show that shuffling and reversing the response sequence significantly degrades trajectory fidelity scores for both models, with larger drops observed for ARcANE-32B-DPO compared to DeepSeek-V4-Pro, indicating that the former is more sensitive to phase-ordering and thus better at tracking narrative trajectories. The block-shuffle perturbation also causes substantial score reductions, suggesting that the trajectory metric captures more than just per-phase content and is influenced by the sequence of responses. Shuffling and reversing response sequences causes significant drops in trajectory fidelity scores, especially for ARcANE-32B-DPO. ARcANE-32B-DPO shows greater sensitivity to response ordering perturbations than DeepSeek-V4-Pro. The block-shuffle perturbation also leads to substantial score reductions, indicating the trajectory metric captures sequence-level structure beyond per-phase content.
The experiments evaluate multiple language models across various context strategies to assess their ability to maintain character consistency and psychological progression in narrative role-playing. Conditioning on the Character Arc consistently yields superior performance compared to alternative methods, particularly in out-of-source scenarios and on trajectory-level metrics that track narrative development over time. Additionally, sensitivity analyses reveal that disrupting response sequences significantly degrades trajectory fidelity, demonstrating that these metrics effectively capture sequence-level narrative structure rather than isolated content. Collectively, the findings confirm that arc-based conditioning enhances long-form character coherence while trajectory metrics reliably measure a model’s alignment with evolving narrative dynamics.