Command Palette
Search for a command to run...
Lernen, schnell und langsam: Auf dem Weg zu LLMs, die sich kontinuierlich anpassen
Lernen, schnell und langsam: Auf dem Weg zu LLMs, die sich kontinuierlich anpassen
Rishabh Tiwari Kusha Sareen Lakshya A Agrawal Joseph E. Gonzalez Matei Zaharia Kurt Keutzer Inderjit S Dhillon Rishabh Agarwal Devvrit Khatri
Zusammenfassung
Große Sprachmodelle (LLMs) werden für nachgelagerte Aufgaben (Downstream-Aufgaben) trainiert, indem ihre Parameter aktualisiert werden (z. B. via Reinforcement Learning, RL). Das Aktualisieren der Parameter zwingt die Modelle jedoch dazu, aufgabenpezifische Informationen zu absorbieren, was zu katastrophalem Vergessen (catastrophic forgetting) und einem Verlust an Plastizität führen kann. Im Gegensatz dazu ermöglicht In-Context Learning bei fixierten LLM-Parametern eine kostengünstige und schnelle Anpassung an aufgabenspezifische Anforderungen (z. B. durch Prompt-Optimierung), kann aber allein typischerweise nicht die Leistungsgewinne erreichen, die durch die Aktualisierung der LLM-Parameter erzielt werden können. Es gibt keinen stichhaltigen Grund, das Lernen ausschließlich auf das In-Context- oder das In-Weights-Lernen zu beschränken. Zudem lernen Menschen voraussichtlich auf unterschiedlichen Zeitskalen (z. B. System 1 vs. System 2).Zu diesem Zweck stellen wir ein Fast-Slow-Learning-Framework für LLMs vor, bei dem die Modellparameter als „langsame“ Gewichte und der optimierte Kontext als „schnelle“ Gewichte fungieren. Diese schnellen „Gewichte“ können aus textuellen Rückmeldungen lernen, um aufgaben spezifische Informationen zu absorbieren, während die langsamen Gewichte näher am Basis-Modell bleiben und allgemeine Reasoning-Verhalten aufrechterhalten. Fast-Slow Training (FST) ist bei Reasoning-Aufgaben bis zu 3-mal stichproben-effizienter als rein langsames Lernen (RL), während es konsequent eine höhere asymptotische Leistungsgrenze erreicht. Darüber hinaus bleiben mit FST trainierte Modelle dem Basis-LLM näher (bis zu 70 % geringere KL-Divergenz), was zu weniger katastrophalem Vergessen im Vergleich zu RL-Training führt. Diese reduzierte Abweichung erhält auch die Plastizität: Nach dem Training auf einer Aufgabe passen sich mit FST trainierte Modelle effektiver an eine nachfolgende Aufgabe an als Modelle, die ausschließlich durch Parameteraktualisierung trainiert wurden. In kontinuierlichen Lernszenarien (Continual Learning), in denen sich die Aufgabenbereiche dynamisch ändern, kann FST weiterhin neue Aufgaben lernen, während das rein parameterbasierte RL ins Stocken gerät.
One-sentence Summary
The authors propose Fast-Slow Training, a framework treating optimized context as fast weights and model parameters as slow weights for continual adaptation in large language models, achieving up to 3× more sample efficiency than reinforcement learning while reducing catastrophic forgetting and preserving plasticity across changing task domains by maintaining up to 70% less KL divergence from the base model.
Key Contributions
- A fast-slow learning framework is introduced for large language models, treating model parameters as slow weights and optimized context as fast weights. This structure allows fast weights to absorb task-specific information from textual feedback while maintaining slow weights closer to the base model.
- Fast-Slow Training (FST) achieves up to 3× more sample efficiency than slow learning via reinforcement learning across reasoning tasks. The method consistently reaches a higher performance asymptote compared to parameter-only updates.
- FST-trained models remain closer to the base large language model with up to 70% less KL divergence than reinforcement learning training. This reduced drift preserves plasticity, enabling more effective adaptation to subsequent tasks in continual learning scenarios where parameter-only RL stalls.
Introduction
Large language models are typically adapted for downstream tasks by updating their parameters via methods like reinforcement learning. However, forcing all task-specific information into persistent weights often results in catastrophic forgetting and a loss of plasticity for future learning. While in-context learning with fixed parameters offers flexibility, it typically cannot match the performance gains achieved through weight updates. To address these limitations, the authors introduce Fast-Slow Training (FST), a framework that treats model parameters as slow weights and optimized context as fast weights. This approach allows the system to co-evolve both components so that task-specific signals are absorbed into the prompt while the base model remains stable. Consequently, FST achieves higher sample efficiency and performance while significantly reducing drift from the base policy and preserving the capacity to adapt to new tasks.
Dataset
-
Dataset Composition and Sources
- The authors adopt the star-graph search planning task introduced by Prakash and Buvanesh.
- They procedurally generate both training and test splits rather than using static collections.
-
Subset Details and Construction
- Each graph instance is defined by a triple (d,p,n) representing source degree, path length, and node-pool size.
- A unique gold path connects the source to the goal node using intermediate nodes sampled from the pool.
- To increase difficulty, decoy branches are attached to the source using unused nodes so they do not intersect the gold path.
- The full edge set is shuffled uniformly at random and serialized as a flat space-separated list of comma-separated pairs.
-
Training and Evaluation Splits
- Headline experiments use parameters set to (d,p,n)=(25,20,500).
- The training set consists of 10,000 examples while the test set contains 200 held-out examples.
- Inputs follow a verbatim prompt template requiring step-by-step reasoning and a final answer within boxed braces.
-
Processing and Scoring
- The system prompt instructs the model to inspect source node neighbors before committing to a branch.
- The reward function extracts the content from the last boxed section for exact-match comparison against the gold path string.
- Scoring is binary with a reward of 1.0 for exact matches and 0.0 for any deviation.
Method
The authors propose a dual-loop optimization framework termed Fast-Slow Training (FST), which simultaneously optimizes the model parameters and the textual context used to condition the model. The system distinguishes between slow weights, denoted as θ, which represent the trainable neural network parameters, and fast weights, denoted as ϕ, which represent textual scaffolds or prompts drawn from a discrete text space Σ∗. The overall architecture and the interaction between these components are illustrated below:
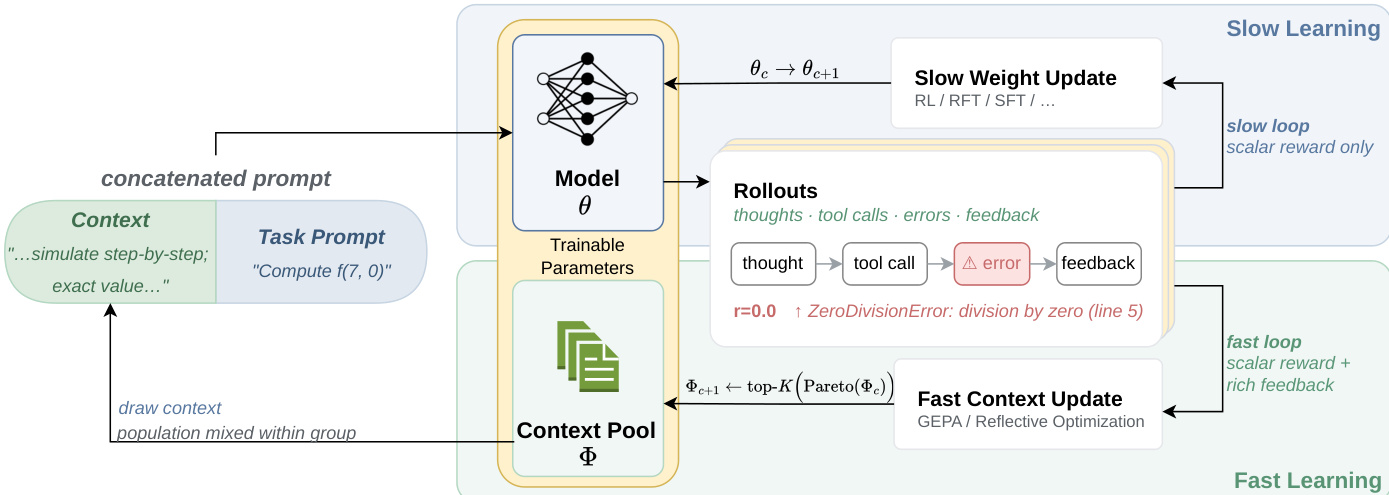
The training process begins by constructing a concatenated prompt that combines a dynamic context ϕ selected from a Context Pool Φ with a static Task Prompt. This combined input is fed into the Model θ, which generates a response y conditioned on both the query x and the context ϕ. During the generation phase, the model produces rollouts that may include intermediate thoughts, tool calls, and error signals, ultimately yielding a response and associated feedback.
The framework operates through two distinct learning loops. The slow learning loop focuses on updating the model parameters θ. This process utilizes Reinforcement Learning with Verifiable Rewards (RLVR). For each query, the policy generates a group of rollouts, and group-relative advantages are computed based on scalar rewards provided by an automatic verifier (e.g., checking for code execution success or mathematical correctness). The model parameters are then updated using a truncated importance-sampling REINFORCE objective, specifically the CISPO loss, to maximize the expected reward while maintaining stability. This loop updates the weights θc→θc+1 and relies primarily on scalar reward signals.
Concurrently, the fast learning loop optimizes the Context Pool Φ using Reflective Evolutionary Prompt Optimization, specifically the GEPA algorithm. This loop treats the textual prompts as fast weights that can be rapidly adapted. Instead of updating parameters, GEPA evolves the population of prompts Φ by maintaining a Pareto frontier of complementary candidates. It uses the rollouts generated by the current policy to elicit natural-language critiques from a frozen reflection language model. These critiques guide the proposal of textual mutations that improve performance on an anchor set of tasks. This process allows the system to capture task-specific improvements and rapidly evolving behaviors without the computational cost of retraining the neural network weights.
The Fast-Slow Training method interleaves these two processes in cycles. At the start of each cycle, the system pre-fetches a lookahead batch of data and runs GEPA to update the prompt population Φ based on the current policy πθ. For the subsequent steps in the cycle, the model parameters θ are updated via RL using the newly optimized prompt population, while the prompts remain fixed. This division of labor allows the fast weights to handle rapid adaptation and task-specific conditioning, while the slow weights consolidate persistent behavioral patterns, leading to improved data efficiency and performance.
Experiment
The experiments evaluate Fast-Slow Training against standard reinforcement learning across code, math, and fact verification tasks using a Qwen3-8B base model. Results demonstrate that FST achieves higher performance ceilings and greater data efficiency by leveraging textual fast weights to capture task signals faster than parameter updates alone. Furthermore, the method maintains closer proximity to the base model to preserve plasticity for subsequent tasks, while ablation studies confirm that jointly optimizing both fast textual channels and slow parameters is necessary to maximize performance.
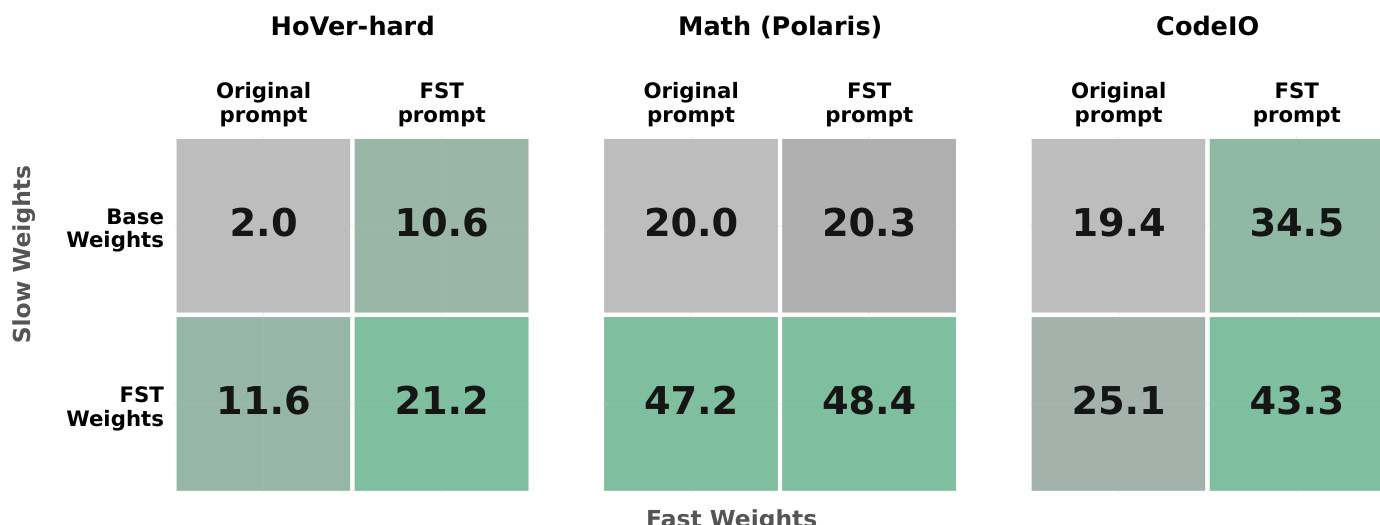
The authors decompose performance gains into contributions from slow weights (parameters) and fast weights (prompts) to analyze the division of labor in Fast-Slow Training. Results indicate that while slow weights drive the majority of gains on the Math task, both channels contribute significantly to performance on HoVer-hard and CodeIO. The combination of optimized weights and optimized prompts consistently reaches the highest performance asymptote across all domains. Combining FST-trained weights with FST-evolved prompts consistently yields the highest performance across all tasks. HoVer-hard and CodeIO benefit significantly from both the slow weight and fast prompt channels, which compound when combined. On the Math task, performance improvements are primarily driven by updates to the slow weights, with the fast prompt channel offering minimal additional benefit.
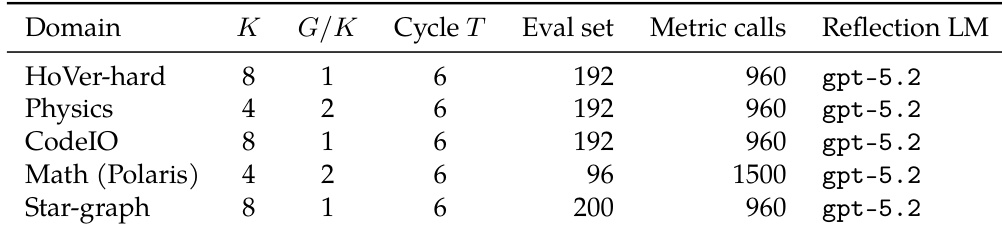
The the the table details the hyperparameter configurations for the Fast-Slow Training experiments across five distinct reasoning domains. While the cycle length and reflection language model remain uniform across settings, the population size and evaluation budgets are tailored to the specific requirements of each task. This standardized yet adaptable setup enables the authors to demonstrate that their method achieves higher performance ceilings and better data efficiency than standard reinforcement learning baselines. Uniform cycle lengths and reflection models are used across all domains to maintain consistent training dynamics. Evaluation budgets and population sizes vary by domain, with math tasks utilizing higher metric call limits. The configuration supports diverse reasoning tasks, ranging from code generation to multi-hop fact verification.
The the the table details the hyperparameter configurations for five reasoning domains, indicating a standard setup across most tasks with specific deviations for the Math and Star-graph experiments. While the majority of domains utilize the Qwen3-8B model in thinking mode with uniform batch settings, the Math task employs a specialized base model with increased batch capacity. Conversely, the Star-graph task utilizes a smaller model variant without thinking capabilities, yet all configurations maintain stable GPU utilization. Three domains share an identical base model and batch configuration to ensure consistent comparison. The Math task requires a specialized SFT base model and larger batch size to handle task saturation. The Star-graph experiment uses a smaller model size and disables thinking mode, distinguishing it from the primary 8B setups.

The evaluation spans five reasoning domains with tailored hyperparameters and model configurations, primarily utilizing Qwen3-8B with specific adjustments for Math and Star-graph tasks to ensure consistent comparison. Experiments decompose performance gains to analyze the division of labor between slow weights and fast prompts, revealing that combining optimized weights and prompts consistently reaches the highest performance asymptote across all tasks. While slow weights primarily drive improvements on the Math task, both channels contribute significantly to HoVer-hard and CodeIO, demonstrating that the method achieves higher performance ceilings and better data efficiency than standard reinforcement learning baselines.