HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

TransitLM: Ein großskaliger Datensatz und Benchmark für die Generierung von Transitrouten ohne Karte

DelTA: Diskriminative Token-Credit-Zuweisung für Verstärkungslernen aus überprüfbaren Belohnungen



























TransitLM: Ein großskaliger Datensatz und Benchmark für die Generierung von Transitrouten ohne Karte
DelTA: Diskriminative Token-Credit-Zuweisung für Verstärkungslernen aus überprüfbaren Belohnungen
Interaktive Bewertung erfordert eine Designwissenschaft
ESI-BENCH: Auf dem Weg zu einer verkörperten räumlichen Intelligenz, die die Wahrnehmungs-Aktions-Schließung ermöglicht
Vergleichende Analyse der militärischen Detektion unter Verwendung von Drohnenbildern über mehrere visuelle Spektrumbereiche
Automatisierte ICD-Klassifizierung psychiatrischer Diagnosen: Von klassischem NLP zu großen Sprachmodellen
Koordiniertes optimales Power-Quality-Management in Verteilnetzen unter Nutzung der Restkapazität von Community-IBRs
EllipseLIO: Adaptive LiDAR-Inertial-Odometrie mit einer Ellipsoid-Darstellung
SMoA: Spektralmodulationsadapter für parameter-effizientes Feintuning
Erkennung von Trojaned DNNs durch spektrale Regressionsanalyse
Die Illusion des Denkens: Das Verständnis der Stärken und Grenzen von Reasoning-Modellen aus der Perspektive der Problemkomplexität
Generatives rekursives Reasoning
Safety Pretraining: Auf dem Weg zur nächsten Generation sicherer KI
RubricEM: Meta-RL mit rubrikgeleiteter Policy-Dekomposition jenseits überprüfbarer Belohnungen
Wenn die Vision für den Ton spricht
AutoResearchClaw: Selbstverstärkende autonome Forschung mit Mensch-KI-Zusammenarbeit
Prozessbelohnungen mit erlernter Zuverlässigkeit
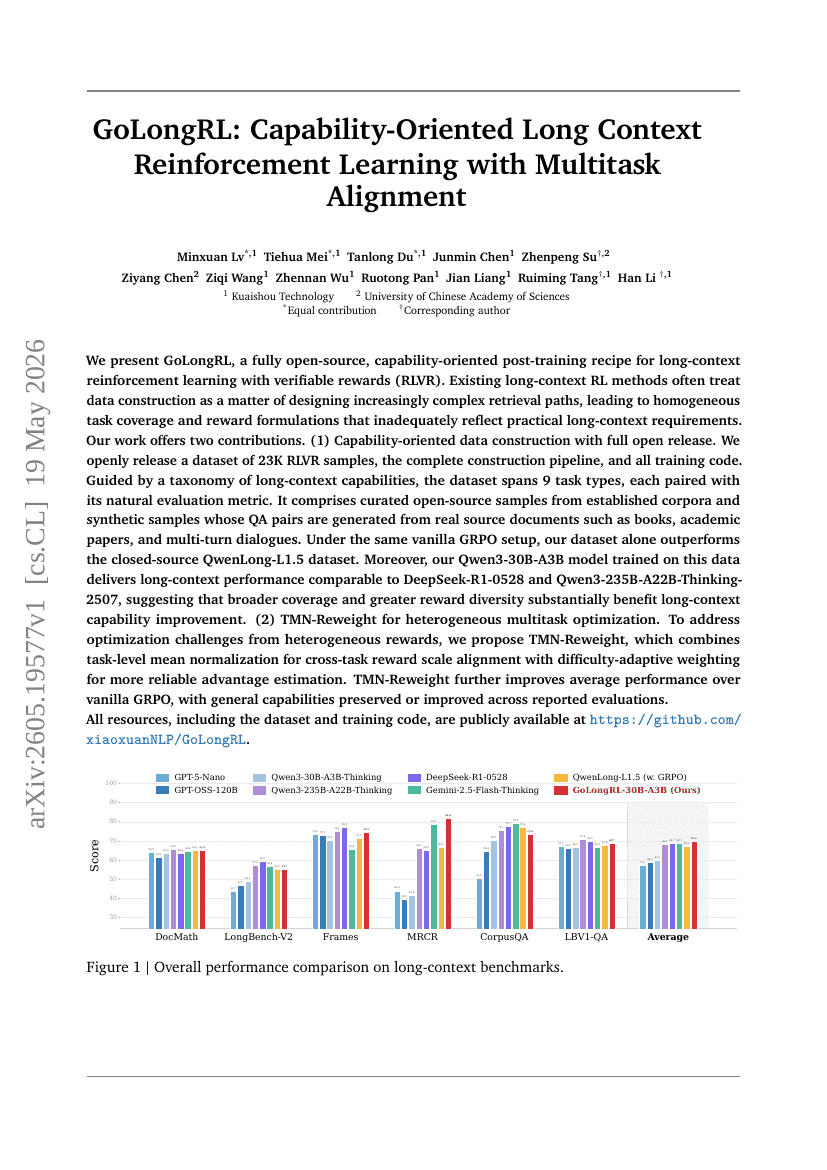
GoLongRL: Fähigkeitsorientiertes Langkontext-Verstärkungslernen mit Multitask-Ausrichtung
OpenComputer: Überprüfbare Softwarewelten für Computer-Nutzungs-Agents
Anti-Selbstdistillation für reasoning RL über punktweise gegenseitige Information
Gezielte Neuronenmodulation durch Suche nach kontrastiven Paaren
Continuous Diffusion Skaliert Wettbewerbsfähig Mit Diskreter Diffusion Für Sprache
KVPO: ODE-natives GRPO für autoregressive Videoausrichtung durch KV-semantische Exploration
Code-as-Room: Generieren von 3D-Räumen aus Draufsichtbildern durch agentic Code-Synthese
KI für die automatische Forschung: Fahrplan und Benutzerhandbuch
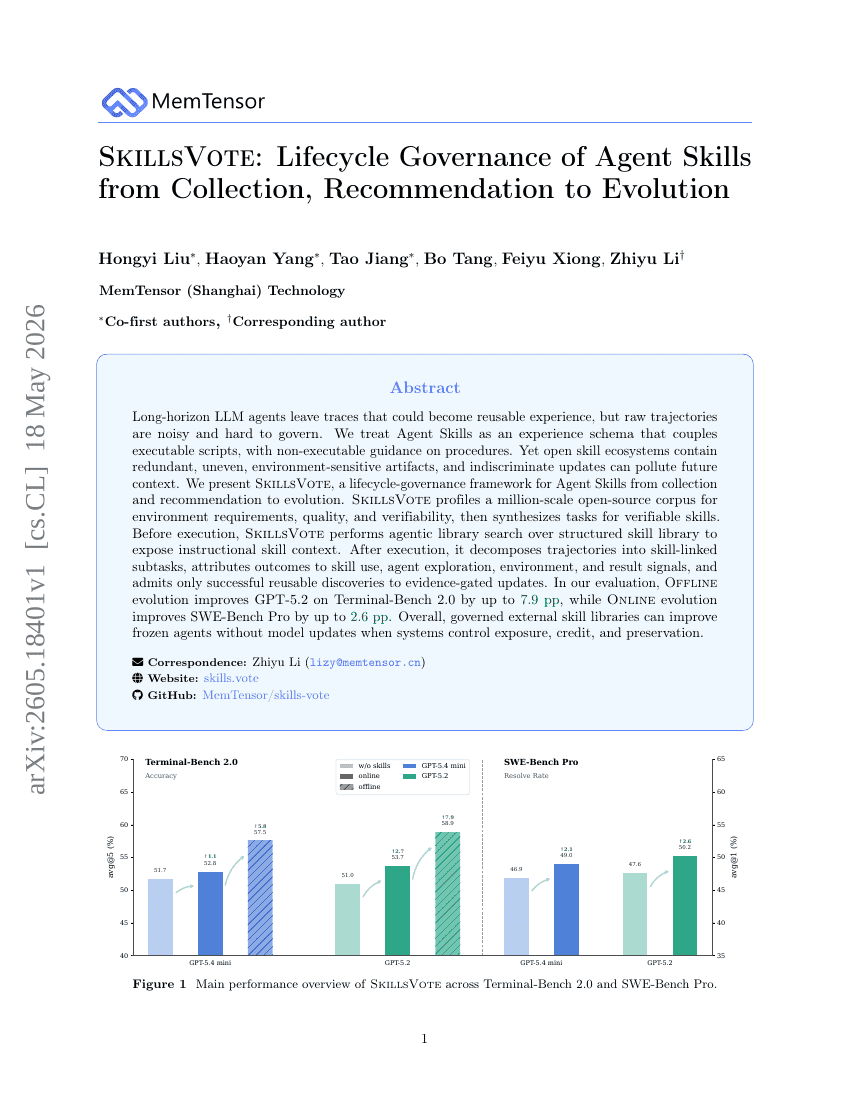
SkillsVote: Lebenszyklus-Steuerung von Agenten-Fähigkeiten von der Sammlung, Empfehlung bis zur Evolution
Lance: Einheitliches multimodales Modellieren durch Multi-Task-Synergie
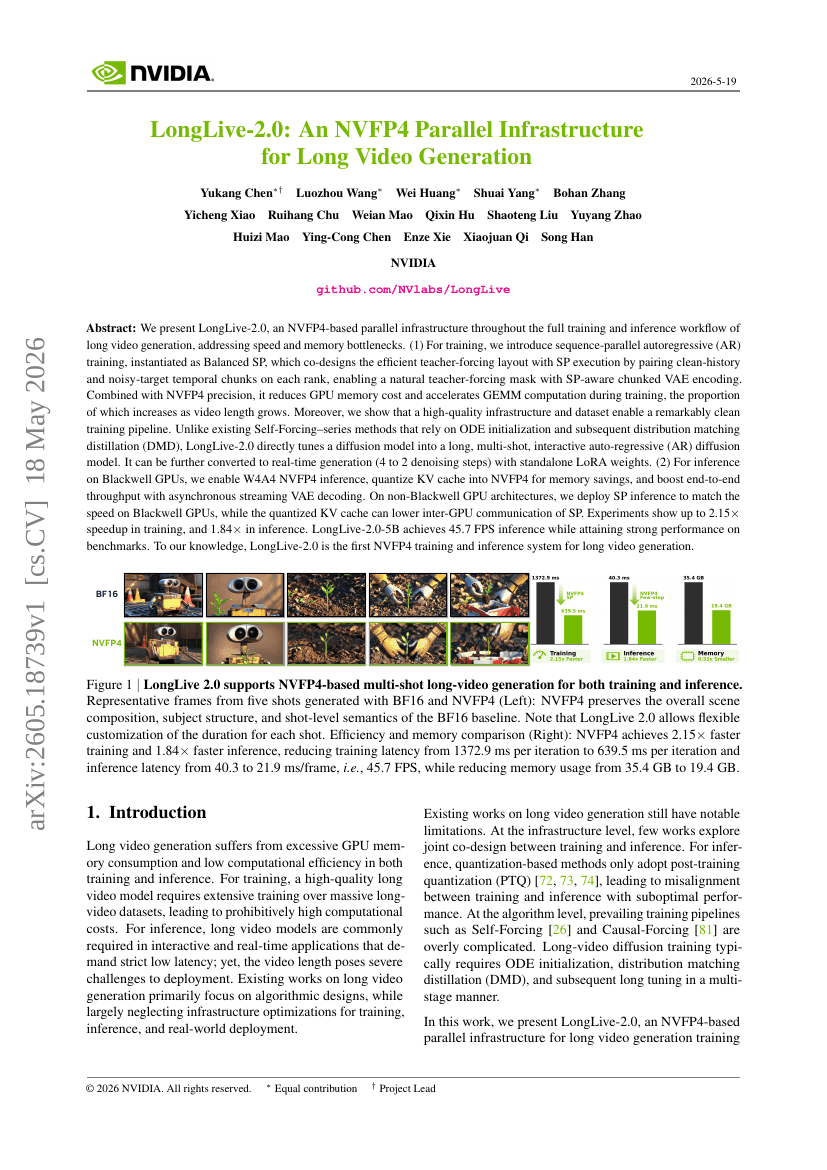
LongLive-2.0: Eine NVFP4-Parallelinfrastruktur für die Generierung langer Videos
Aufschneiden und Würfel: Konfigurieren optimaler Gemische aus Experten
Agentengesteuerte Entdeckung neuronaler Architekturen: AIRA-Compose und AIRA-Design
Lernen, vorauszusehen: Enthüllung der Entschlüsselungseffizienz der On-Policy-Distillation
DexJoCo: Ein Benchmark und ein Toolkit für aufgabenorientierte geschickte Manipulation auf MuJoCo
Interaktive Bewertung erfordert eine Designwissenschaft
ESI-BENCH: Auf dem Weg zu einer verkörperten räumlichen Intelligenz, die die Wahrnehmungs-Aktions-Schließung ermöglicht
Vergleichende Analyse der militärischen Detektion unter Verwendung von Drohnenbildern über mehrere visuelle Spektrumbereiche
Automatisierte ICD-Klassifizierung psychiatrischer Diagnosen: Von klassischem NLP zu großen Sprachmodellen
Koordiniertes optimales Power-Quality-Management in Verteilnetzen unter Nutzung der Restkapazität von Community-IBRs
EllipseLIO: Adaptive LiDAR-Inertial-Odometrie mit einer Ellipsoid-Darstellung
SMoA: Spektralmodulationsadapter für parameter-effizientes Feintuning
Erkennung von Trojaned DNNs durch spektrale Regressionsanalyse
Die Illusion des Denkens: Das Verständnis der Stärken und Grenzen von Reasoning-Modellen aus der Perspektive der Problemkomplexität
Generatives rekursives Reasoning
Safety Pretraining: Auf dem Weg zur nächsten Generation sicherer KI
RubricEM: Meta-RL mit rubrikgeleiteter Policy-Dekomposition jenseits überprüfbarer Belohnungen
Wenn die Vision für den Ton spricht
AutoResearchClaw: Selbstverstärkende autonome Forschung mit Mensch-KI-Zusammenarbeit
Prozessbelohnungen mit erlernter Zuverlässigkeit
GoLongRL: Fähigkeitsorientiertes Langkontext-Verstärkungslernen mit Multitask-Ausrichtung
OpenComputer: Überprüfbare Softwarewelten für Computer-Nutzungs-Agents
Anti-Selbstdistillation für reasoning RL über punktweise gegenseitige Information
Gezielte Neuronenmodulation durch Suche nach kontrastiven Paaren
Continuous Diffusion Skaliert Wettbewerbsfähig Mit Diskreter Diffusion Für Sprache
KVPO: ODE-natives GRPO für autoregressive Videoausrichtung durch KV-semantische Exploration
Code-as-Room: Generieren von 3D-Räumen aus Draufsichtbildern durch agentic Code-Synthese
KI für die automatische Forschung: Fahrplan und Benutzerhandbuch
SkillsVote: Lebenszyklus-Steuerung von Agenten-Fähigkeiten von der Sammlung, Empfehlung bis zur Evolution
Lance: Einheitliches multimodales Modellieren durch Multi-Task-Synergie
LongLive-2.0: Eine NVFP4-Parallelinfrastruktur für die Generierung langer Videos
Aufschneiden und Würfel: Konfigurieren optimaler Gemische aus Experten
Agentengesteuerte Entdeckung neuronaler Architekturen: AIRA-Compose und AIRA-Design
Lernen, vorauszusehen: Enthüllung der Entschlüsselungseffizienz der On-Policy-Distillation
DexJoCo: Ein Benchmark und ein Toolkit für aufgabenorientierte geschickte Manipulation auf MuJoCo