Command Palette
Search for a command to run...
Wo gehen Deep-Research-Agents falsch? Span-Ebene-Fehlerlokalisierung in Agent-Trajektorien
Wo gehen Deep-Research-Agents falsch? Span-Ebene-Fehlerlokalisierung in Agent-Trajektorien
Zusammenfassung
Deep-Research-agents lösen Aufgaben durch lange Trajektorien aus Suche, Werkzeugnutzung, Evidenzprüfung und Antwortsynthese. Eine auf endgültigen Antworten basierende Evaluation zeigt, ob ein agent erfolgreich ist, nicht jedoch, welche Teile der Trajektorie die Antwort unzuverlässig machen. Wir untersuchen die Fehlerlokalisierung auf Span-Ebene für Deep-Research-agents. Wir sammeln 2.790 reale Trajektorien von zwei agent frameworks, drei Backbone-Modellen und drei Benchmarks, konvertieren Rohprotokolle in semantische Spans und annotieren schädliche Fehler-Spans mittels LLM-unterstützter Expertenbewertung. Auf Basis dieser Annotationen entwickeln wir TELBench, einen Benchmark mit 1.000 Instanzen zur Identifizierung von Fehler-Spans innerhalb von normaler Exploration, fehlgeschlagenen Suchen, vorläufigen Hypothesen und harmlosem Rauschen. Darüber hinaus schlagen wir DRIFT vor, ein behauptungszentriertes Audit-Rahmenwerk, das agent Behauptungen verfolgt, deren Unterstützung durch Trajektorien-Evidenz überprüft und Spans markiert, in denen nicht gestützte oder widersprüchliche Behauptungen den Antwortpfad beeinflussen. Experimente über verschiedene Modellfamilien und Audit-Rahmenwerke hinweg zeigen, dass DRIFT die Fehlerlokalisierung auf Span-Ebene und die Genauigkeit bei der ersten Fehlererkennung um bis zu 30 Prozentpunkte verbessert. Unsere Arbeit bietet eine prozessbezogene Perspektive auf die Zuverlässigkeit von Deep-Research-agents.
One-sentence Summary
The authors propose DRIFT, a claim-centric auditing framework that improves span-level error localization and first-error accuracy by up to 30 percentage points on the TELBENCH benchmark by systematically verifying agent claims against trajectory evidence.
Key Contributions
- The paper introduces TELBENCH, a 1,000-instance benchmark for span-level error localization in deep-research agents, constructed from 2,790 real trajectories converted into semantic spans and annotated through LLM-assisted expert review to distinguish harmful errors from routine exploration and harmless noise.
- The work presents DRIFT, a claim-centric auditing framework that systematically tracks agent claims, verifies their support against trajectory evidence, and flags execution spans where unsupported or conflicting assertions disrupt the final answer path.
- Comprehensive evaluations across multiple model families and auditing frameworks demonstrate that DRIFT improves span-level error localization and first-error accuracy by up to 30 percentage points, providing a process-level view of agent reliability.
Introduction
LLM-based agents are increasingly deployed to automate complex, multi-step deep research workflows that require extensive information retrieval, reasoning, and synthesis. These systems matter because they can significantly accelerate knowledge-intensive tasks across scientific and technical domains. However, debugging these agents remains challenging since prior approaches typically evaluate failures at a coarse trajectory level, leaving developers unable to isolate the exact reasoning steps or generated text that triggered errors. To bridge this gap, the authors develop a span-level error localization method that precisely identifies problematic segments within agent trajectories, enabling targeted debugging and more reliable deep research automation.
Dataset

-
Dataset Composition and Sources
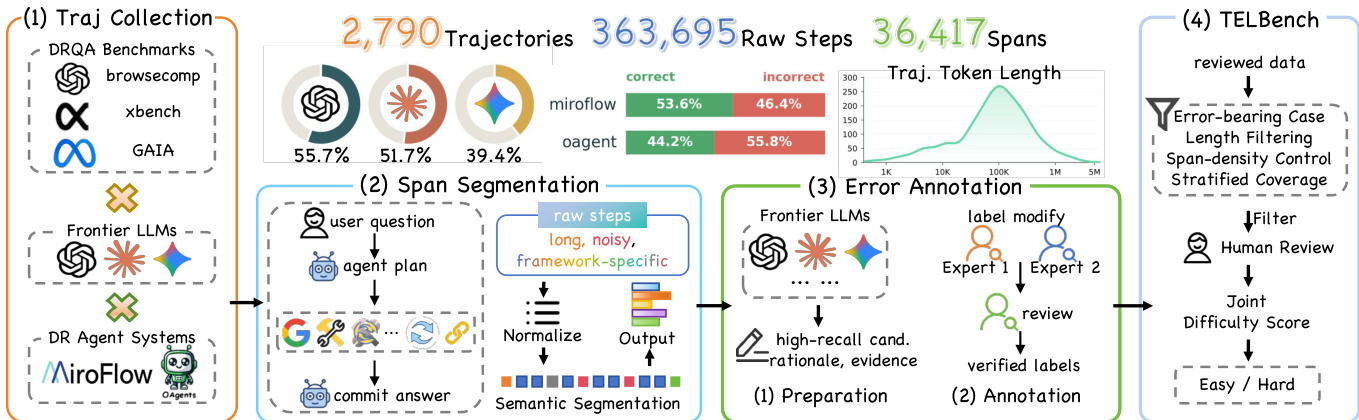
- The authors compile a 2,790 trajectory corpus by executing tasks from three public deep-research benchmarks: GAIA-val, XBench, and BrowseComp-test.
- BrowseComp is downsampled to 200 tasks to prevent dataset skew, bringing the total task count to 465.
- Each task is run with three frontier models (GPT-5, Gemini-2.5-Pro, Claude-Sonnet-4.5) across two agent frameworks (MiroFlow and OAgent).
-
Subset Details and Filtering
- The initial corpus contains 1,890 trajectories with at least one span-level error, forming the candidate pool.
- After filtering for clear error boundaries, verifiable internal evidence, stable segmentation, and sufficient non-error distractors, the authors curate a Verified-1K subset of 1,000 instances.
- This test set is divided into 600 easy and 400 hard instances based on trajectory length, error sparsity, and distractor density, averaging 11.95 semantic spans per trajectory.
-
Processing and Metadata Construction
- Raw framework-specific logs are normalized into unified execution-unit sequences, folding tool calls with their results and linearizing nested multi-agent traces into a single semantic order.
- Trajectories are segmented into semantic spans using boundary signals like shifts in search targets, candidate sets, time scopes, or reasoning objectives, while grouping query rewrites and retries under the same local goal.
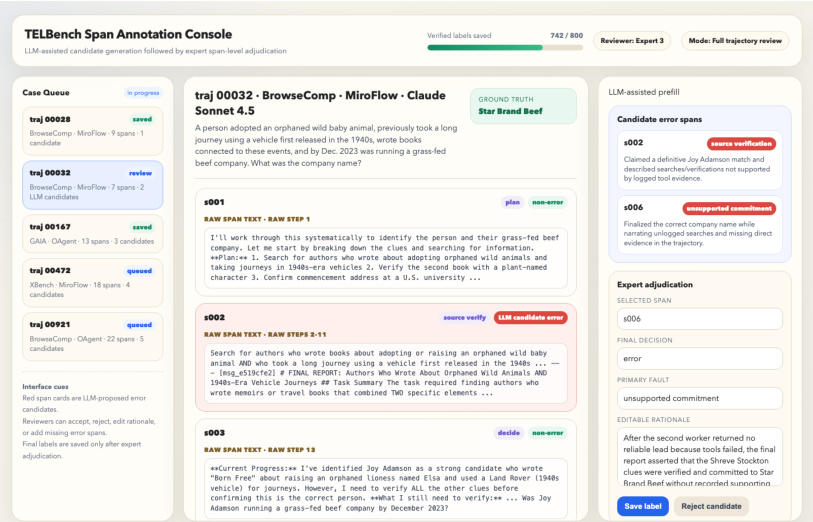
- Span labels are assigned via an LLM-assisted candidate proposal pipeline followed by expert adjudication from seven trained annotators who review full trajectories and resolve disagreements.
- Metadata includes an eight-stage operation label applied to all spans, plus a primary fault label drawn from an 18-type taxonomy grouped into six families, which is applied exclusively to error spans. The fault taxonomy is induced through LLM rationale clustering, hierarchical map-reduce induction, and manual boundary calibration.
-
Usage in the Paper
- The dataset is not used for model training or mixture ratios. Instead, the full 2,790-trajectory corpus is reserved for mechanism analysis and error pattern studies.
- The Verified-1K subset functions as the benchmark evaluation set for testing span-level error localization.
- Evaluation inputs are strictly limited to the original question and ordered span text to ensure models are assessed on raw trajectory evidence without access to stage labels, fault annotations, or ground-truth markers.
Method
The authors propose DRIFT, a claim-centric auditing framework designed to localize error spans within deep-research agent trajectories by analyzing the evolution of agent commitments rather than treating individual spans in isolation. The framework operates on a sequence of raw spans derived from a completed trajectory, with the input consisting solely of the task question and the ordered span texts. DRIFT's core insight is that harmful errors often stem from early, unsupported, or conflicting claims that are subsequently reused as established facts in later reasoning, making it essential to track claims and their dependencies across the trajectory.
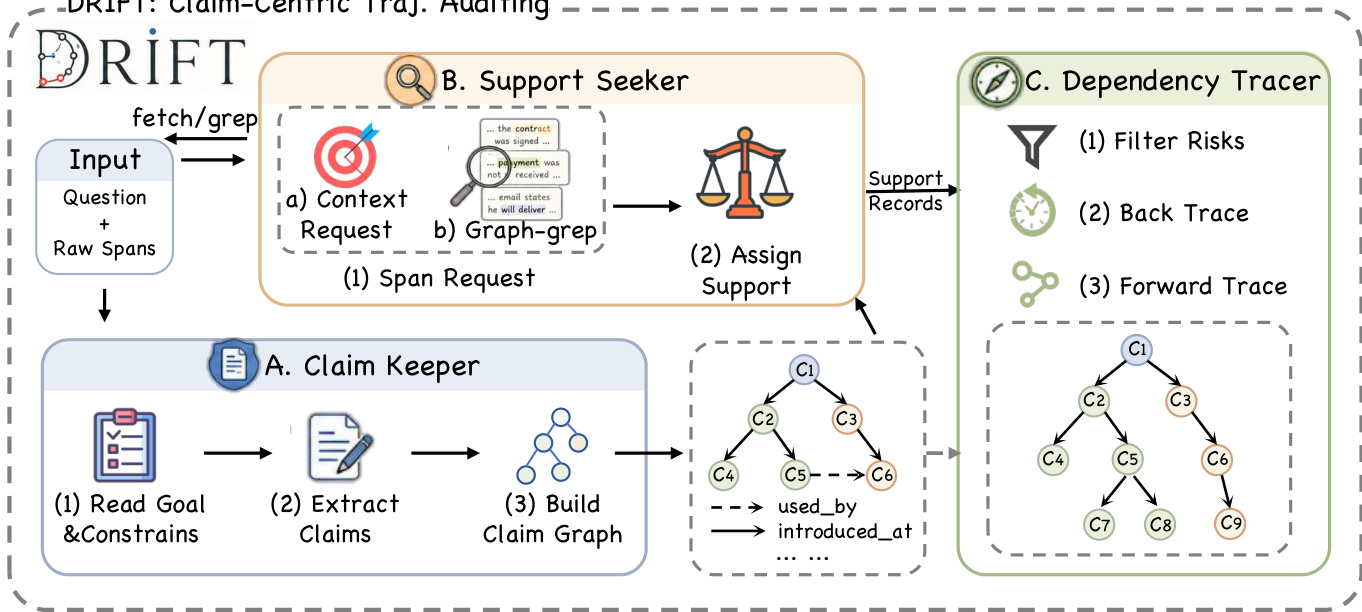
The framework is structured into three primary modules that operate sequentially. The first module, the Claim Keeper, performs a global pass over the entire trajectory to construct a comprehensive claim ledger. This ledger, denoted as L={ck}k=1m, records each consequential claim ck as a tuple (ak,ik,bk,Uk,τk,σk), where ak is the textual claim, ik is the span where it is introduced, bk is the first span where it becomes consequential, Uk is the set of later spans that use it, τk is the claim type (e.g., entity, constraint, computation), and σk is its status (e.g., exploratory, tentative, consequential, finalized). This ledger separates ordinary exploration from committed reasoning, capturing the agent's evolving beliefs and commitments.
The second module, the Support Seeker, takes the claim ledger as input and checks the support status for each consequential claim. It assigns one of four statuses: DIRECT (the claim is directly established by evidence in the trajectory), WEAK (related evidence exists but the decisive link is partial or implicit), MISSING (no shown support establishes the claim), or CONFLICTING (shown evidence contradicts the claim). This stage does not output final error spans but identifies support risks, which are then passed to the final module. The final module, the Dependency Tracer, determines which risky claims correspond to harmful errors. It identifies spans that commit to, reuse, amplify, or finalize unsupported or conflicting consequential claims and marks them as error spans. The final prediction is the set of all such spans, E^={si∈T∣h(si)=1}, where h(si)=1 indicates the span commits to, reuses, amplifies, or finalizes a harmful claim.
Experiment
The evaluation compares five model families and four diagnostic frameworks on a verified trajectory dataset to validate span localization and first-error detection capabilities across varying task complexities. Results indicate that structured, claim-centric auditing significantly outperforms generic agentic baselines by effectively tracking consequential commitments and filtering routine exploration noise, whereas simply increasing model scale or workflow complexity yields diminishing returns. Qualitative analysis reveals that process errors are highly stage-dependent, with decision-making and finalization phases posing the greatest intrinsic risk, and that failures typically propagate through interconnected chains rather than appearing as isolated mistakes. Ultimately, the findings confirm that tailored diagnostic structures are essential for navigating long agent trajectories and accurately distinguishing early commitment errors from downstream verification failures.
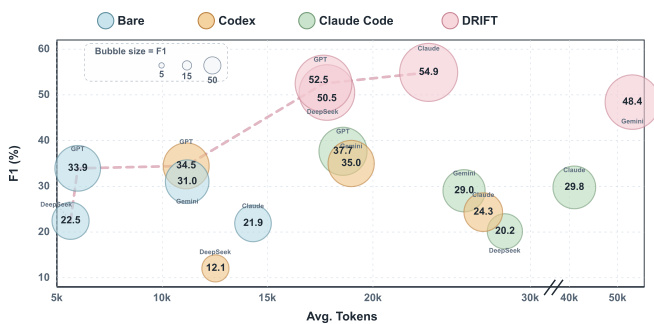
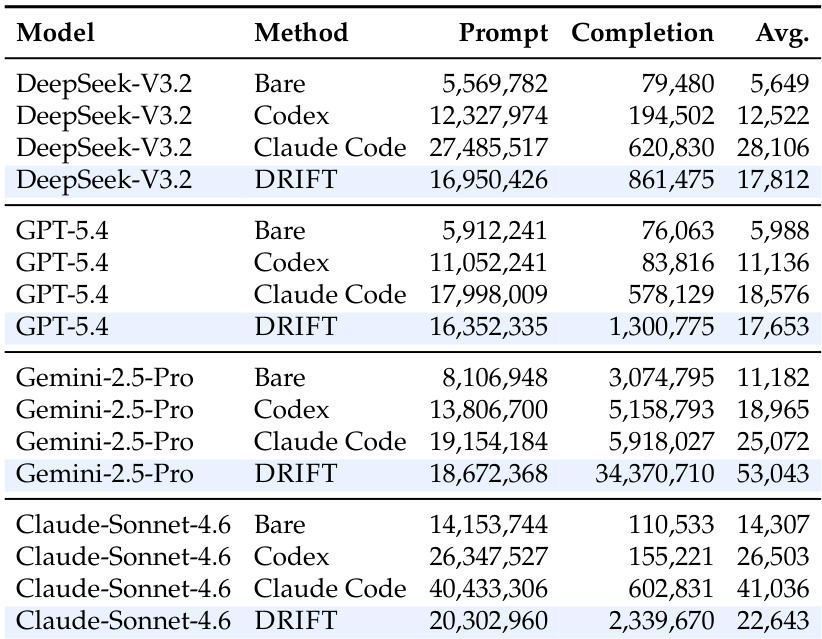
The authors analyze the performance of different diagnostic frameworks on trajectory error detection, comparing them in terms of F1 score and average token consumption. Results show that DRIFT achieves the highest F1 scores across various model families while maintaining a favorable efficiency-performance trade-off. The comparison reveals that simply increasing model scale or using general agentic auditing frameworks does not consistently improve error detection, highlighting the importance of a structured, claim-centric approach for reliable diagnosis. DRIFT achieves the highest F1 scores across all model families while maintaining competitive token efficiency. General agentic auditing frameworks like Codex and Claude Code show inconsistent gains and can degrade performance compared to bare LLMs. F1 performance and token usage vary significantly across models, with DRIFT consistently outperforming baselines even at lower token budgets.
The the the table presents token consumption metrics for various models and methods, showing that DRIFT consistently requires the highest prompt and completion tokens compared to other frameworks. The average token usage increases significantly with DRIFT across all models, indicating higher computational overhead. Among the models, DeepSeek-V3.2 incurs the highest average token cost under DRIFT, while Claude-Sonnet-4.6 has the lowest. DRIFT incurs the highest token consumption across all models and methods. DeepSeek-V3.2 has the highest average token usage under DRIFT. Claude-Sonnet-4.6 has the lowest token usage under DRIFT.
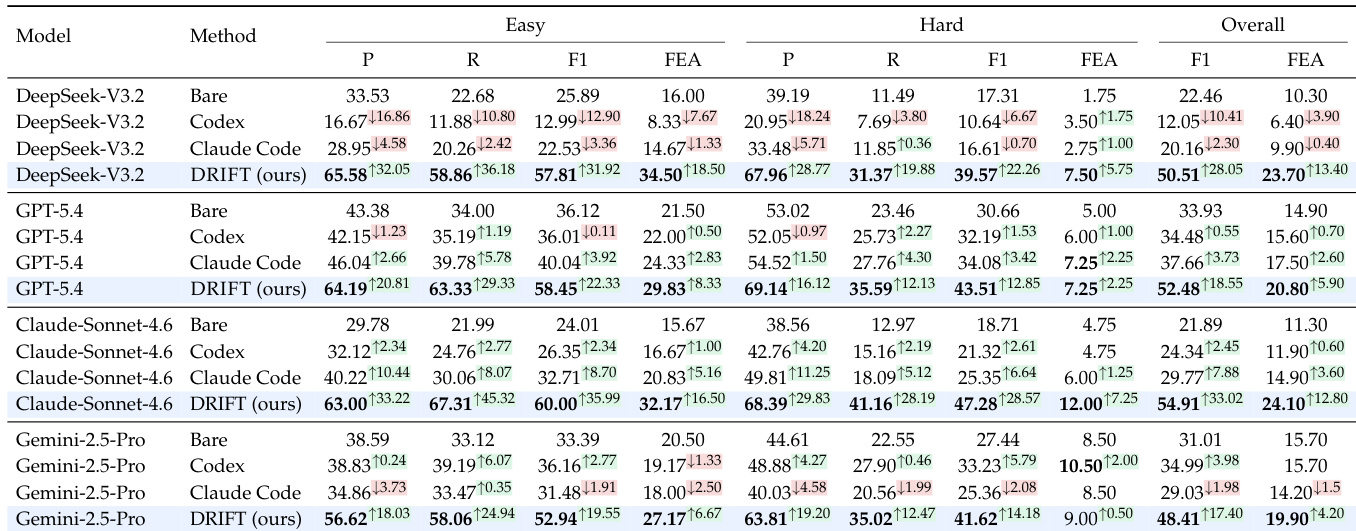
The authors evaluate multiple diagnostic frameworks across different model families and difficulty splits, focusing on their ability to detect error spans and identify the first error in agent trajectories. DRIFT consistently outperforms baseline methods in span-level F1, particularly on challenging cases, and demonstrates robustness across model scales and trajectory complexities. The results highlight that effective trajectory auditing requires structured mechanisms to track claims, verify evidence, and filter noise, rather than relying solely on increased model scale or generic agentic workflows. DRIFT achieves the highest F1 scores across all models and difficulty splits, outperforming both bare LLMs and general agentic auditing frameworks. First-error accuracy remains lower than span-level F1, indicating that pinpointing the earliest error is more challenging than detecting erroneous spans. DRIFT's performance improvements are consistent across model families and trajectory lengths, showing that its gains stem from structured auditing rather than increased model capacity.
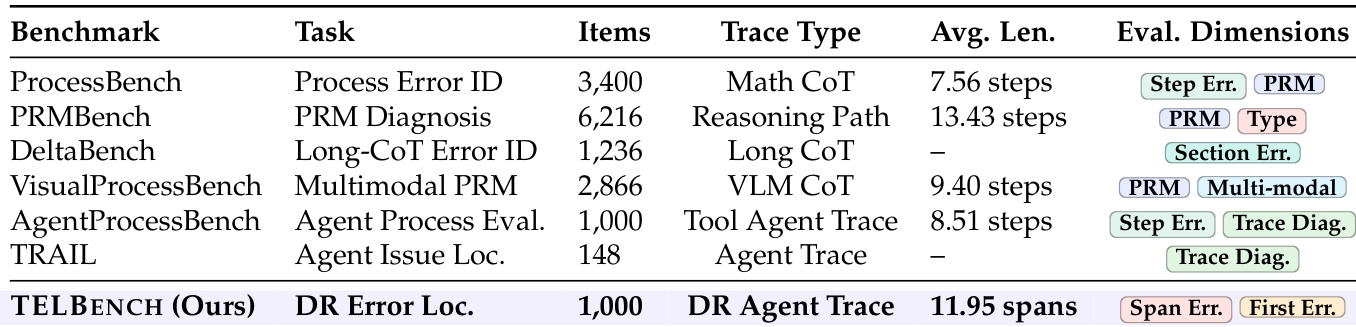
The the the table presents a comparison of various benchmarks used for evaluating agent trajectories, highlighting differences in task types, number of items, trace types, average lengths, and evaluation dimensions. TELBENCH is introduced as a new benchmark focused on detecting errors in agent traces, with a specific emphasis on span-level and first-error localization, and it is distinguished by its use of DR Agent Trace and evaluation metrics such as span error and first error. TELBENCH is a new benchmark for evaluating error localization in agent trajectories, focusing on span-level and first-error detection. The the the table compares multiple benchmarks, each with distinct tasks, trace types, and evaluation dimensions, illustrating the diversity of approaches in agent evaluation. TELBENCH uses DR Agent Trace and evaluates on dimensions including span error and first error, emphasizing the importance of early error detection in agent workflows.
The experiments evaluate multiple diagnostic frameworks across various model families and trajectory complexity levels to validate their effectiveness in detecting erroneous spans, localizing initial failures, and balancing computational efficiency. Results demonstrate that DRIFT consistently outperforms baseline models and general agentic auditing frameworks by leveraging a structured, claim-centric approach rather than relying on increased model scale or unstructured workflows. While pinpointing the earliest error remains more challenging than identifying erroneous spans, the framework maintains robust performance and favorable efficiency across all tested conditions. Ultimately, the findings validate that reliable trajectory diagnosis depends on explicit claim tracking and evidence verification rather than generic agentic patterns.