Command Palette
Search for a command to run...
Nemotron 3 Ultra: Open-Source, effizientes Mixture-of-Experts-Hybridmodell aus Mamba und Transformer für agentic reasoning
Nemotron 3 Ultra: Open-Source, effizientes Mixture-of-Experts-Hybridmodell aus Mamba und Transformer für agentic reasoning
Zusammenfassung
Wir stellen Nemotron 3 Ultra vor, ein hybrides Mixture-of-Experts-Modell, das Mamba-Attention kombiniert. Es verfügt über insgesamt 550 Milliarden Parameter, wovon 55 Milliarden aktiv geschaltet sind. Nemotron 3 Ultra wurde mit 20 Billionen Text-Tokens vortrainiert, anschließend auf eine Kontextlänge von 1 Million Token erweitert und im Nachtrainingsprozess mittels Supervised Fine-Tuning (SFT), Reinforcement Learning (RL) sowie Multi-Teacher On-Policy Distillation (MOPD) feinjustiert.Nemotron 3 Ultra ist unser leistungsstärkstes Modell bisher. Es setzt auf mehrere Schlüsseltechnologien: LatentMoE, Multi Token Prediction (MTP), NVFP4-Vortraining, Multi-Umgebungs-Reinforcement Learning für Validierung und Resilienz (RLVR), MOPD sowie die Steuerung des Reasoning-Budgets. Im Vergleich zu state-of-the-art-LLMs, die öffentlich verfügbar sind, erreicht Nemotron 3 Ultra eine bis zu etwa sechsmal höhere Inference-Durchsatzrate bei gleichbleibend hoher Genauigkeit. Dank dieser state-of-the-art-Genauigkeit, des hohen Inference-Durchsatzes und der 1-Million-Token-Kontextlänge eignet sich Nemotron 3 Ultra ideal für langlaufende, autonome Agentic-Tasks.Wir veröffentlichen die Basisversion sowie die Nachtrainings- und quantisierten Checkpoints zusätzlich mit den Trainingsdaten und der Trainingsanleitung (Recipe) auf HuggingFace open-source.
One-sentence Summary
The authors introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Transformer model pre-trained on 20 trillion tokens with a 1 million token context, employing LatentMoE, Supervised Fine Tuning, Reinforcement Learning, and Multi-teacher On-Policy Distillation to achieve up to six times higher inference throughput than state-of-the-art publicly available LLMs while maintaining on-par accuracy and open-sourcing base, post-trained, and quantized checkpoints along with training data and recipe for autonomous agentic reasoning tasks.
Key Contributions
- This paper introduces Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. The architecture employs key technologies including LatentMoE, Multi Token Prediction, and NVFP4 pre-training to optimize performance.
- The training pipeline pre-trains on 20 trillion text tokens and extends the context length to 1M tokens using Supervised Fine Tuning, Reinforcement Learning, and Multi-teacher On-Policy Distillation. Additional techniques such as multi-environment RLVR and reasoning budget control are incorporated to support complex reasoning and long-running autonomous agentic tasks.
- Experiments demonstrate up to ~6× higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The base, post-trained, and quantized checkpoints are open-sourced on HuggingFace along with the training data and recipe.
Introduction
As large language model applications evolve from simple chatbots to autonomous agents capable of complex reasoning and coding, the demand for fast and efficient inference grows significantly. Existing models often face challenges in balancing high accuracy with inference throughput due to the computational overhead of standard attention mechanisms and large key-value cache footprints. The authors present Nemotron 3 Ultra, which leverages a Mixture-of-Experts hybrid Mamba-Attention architecture to reduce attention costs while maintaining performance. This approach delivers up to 5.9 times higher inference throughput compared to competing models on long-context tasks while achieving on-par accuracy across agentic and reasoning benchmarks.
Dataset
Dataset Composition and Sources
- The authors organize the data into pretraining and post-training phases, releasing new datasets on HuggingFace.
- The pretraining corpus spans 19 high-level categories including web crawl data, math, code, Wikipedia, academic texts, legal data, and multilingual content across 11 languages.
- Post-training data is designed to improve agentic, reasoning, and general model capabilities through SFT and RL stages.
- Sources include public datasets, synthetic generation pipelines, and commercially cleared subsets from repositories like OpenResearcher and GitHub.
Key Details for Each Subset
- Pretraining Code: Includes 173B tokens of fresh code data from GitHub through September 30, 2025.
- Pretraining Legal: Comprises curated HTML files (e.g., California Code of Regulations), LLM-cleaned summaries (5.4M from Caselaw), and synthetic datasets for classification and QA. An ablation study showed LegalBench accuracy improved from 64.6 to 74.7.
- Pretraining Specialized: Contains synthetic Q&A data spanning STEM, math, code, and reasoning domains in Multiple-Choice and Generative formats. Held-out test splits were not used for data generation to preserve evaluation integrity.
- Pretraining Fact-Seeking: Generated from Finewiki statements in two stages to improve factual recall.
- Post-training Safety: The final blend contains approximately 135K samples including 45K in English and 15K each for six translated languages. Examples with semantic similarity below 0.8 during back-translation were filtered, removing roughly 10 to 15% of examples per language.
- Post-training Search: Includes 21.7K trajectories from a commercially cleared subset of OpenResearcher and challenging samples requiring 50 to 100 searches.
- Post-training Terminal Use: Consists of approximately 370K multi-turn conversations covering software engineering and data processing, generated using DeepSeek-V3.2 as an agent.
- Post-training Code: Yields 1.2M Python and 1.0M C++ reasoning traces from competitive programming platforms, plus 1.3M Python tool-calling traces.
- Post-training Math: Sources 1.8M tool-calling samples and 1.9M non-tool samples, alongside proof data from the AOPS split of Nemotron-Math-Proofs-v1.
- Post-training CUDA: A synthetic dataset of approximately 100K samples for kernel generation, repair, and optimization validated in an internal evaluation environment.
- Post-training RTL: Contains around 1.2M samples from ACE-RTL covering specification-to-RTL generation, code editing, and debugging.
Data Usage and Mixture
- The pretraining data follows a two-phase curriculum where Phase 1 biases dataset diversity and Phase 2 biases dataset quality.
- The transition between phases occurs after approximately 15 trillion tokens, which corresponds to roughly 75% of pretraining.
- Quality-filtered web crawl data is the largest component, accounting for approximately 49% of Phase 1 tokens and 38% of Phase 2 tokens.
- Post-training data is used to train the model on long-context abilities, efficiency, control, and safety behaviors.
- For software issue resolution, trajectories are filtered by a heuristic analyzer to ensure submission integrity and remove disallowed git operations or edit-test loops.
- Task distributions are trained under at least two different harnesses such as Stirrup, OpenHands, or Terminus to ensure generalization.
Processing and Packing Strategies
- The authors adopt a length-aware best-fit packing strategy that reads and interleaves source files in a round-robin fashion to minimize padding overhead.
- Conversations are neither truncated nor split, preserving complete context and reducing hallucinations.
- An in-pack deduplication constraint prevents identical prompts from co-occurring within the same sequence.
- Multilingual post-training data uses an end-to-end translation pipeline that processes full JSON objects rather than line-by-line translation to improve quality.
- For chat data, responses are selected by Nemotron-GenRM, and multi-turn conversations are simulated with controlled prompting to build robustness against imperfect previous turns.
Method
The Nemotron 3 Ultra model employs a hybrid Mamba-Attention Mixture-of-Experts (MoE) architecture. It features 550 billion total parameters with 55 billion active parameters per token. The design integrates LatentMoE for efficient sparsity and native Multi-Token Prediction (MTP) for inference acceleration. The specific layer pattern and configuration are illustrated below.

The backbone consists of repeating blocks containing Mamba-2 layers, Attention layers, and Latent MoE layers. This hybrid design combines the sub-quadratic sequence-length scaling of Mamba with the global context modeling capabilities of Attention. Pretraining was conducted on 20 trillion text tokens using an NVFP4 recipe, and the model was extended to support a 1 million token context length through a dedicated long-context phase at the end of pretraining.
The post-training pipeline is substantially redesigned to enhance agentic capabilities and reasoning. It begins with a general Supervised Fine-tuning (SFT) stage, followed by a unified Reinforcement Learning with Verifiable Reward (RLVR) stage. The pipeline then transitions into Multi-teacher On-Policy Distillation (MOPD) and MTP Boosting. The overall workflow is illustrated below.
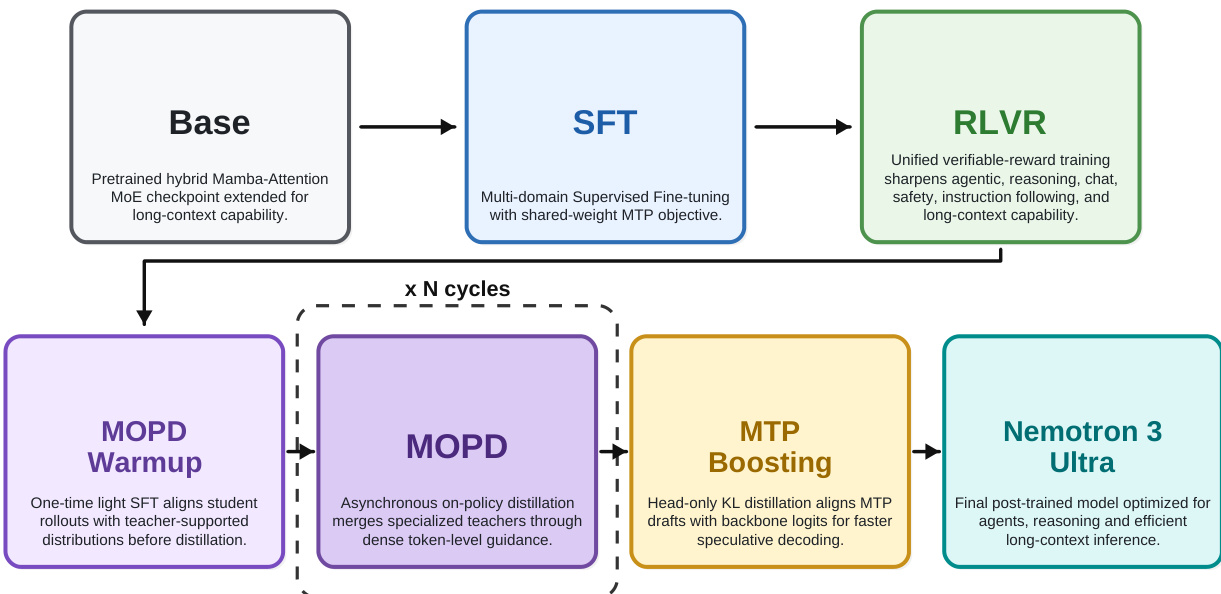
This pipeline moves from a Base model through SFT and RLVR, then into iterative MOPD cycles before final MTP Boosting to produce the Nemotron 3 Ultra model. To address the dilution of learning signals in mixed-environment RLVR, the authors employ Multi-teacher On-Policy Distillation (MOPD). This process involves training over ten specialized teacher models, each optimized for specific domains such as software engineering, office tasks, search, and STEM. The student model generates rollouts across these domains and receives dense reward signals from the corresponding teachers. MOPD is executed asynchronously to maximize efficiency, with rollout generation, teacher scoring, and student optimization fully pipelined. The process occurs over multiple iterative cycles, allowing for continuous capability improvement. The detailed interaction between the student and specialized teachers across two iterations is shown below.
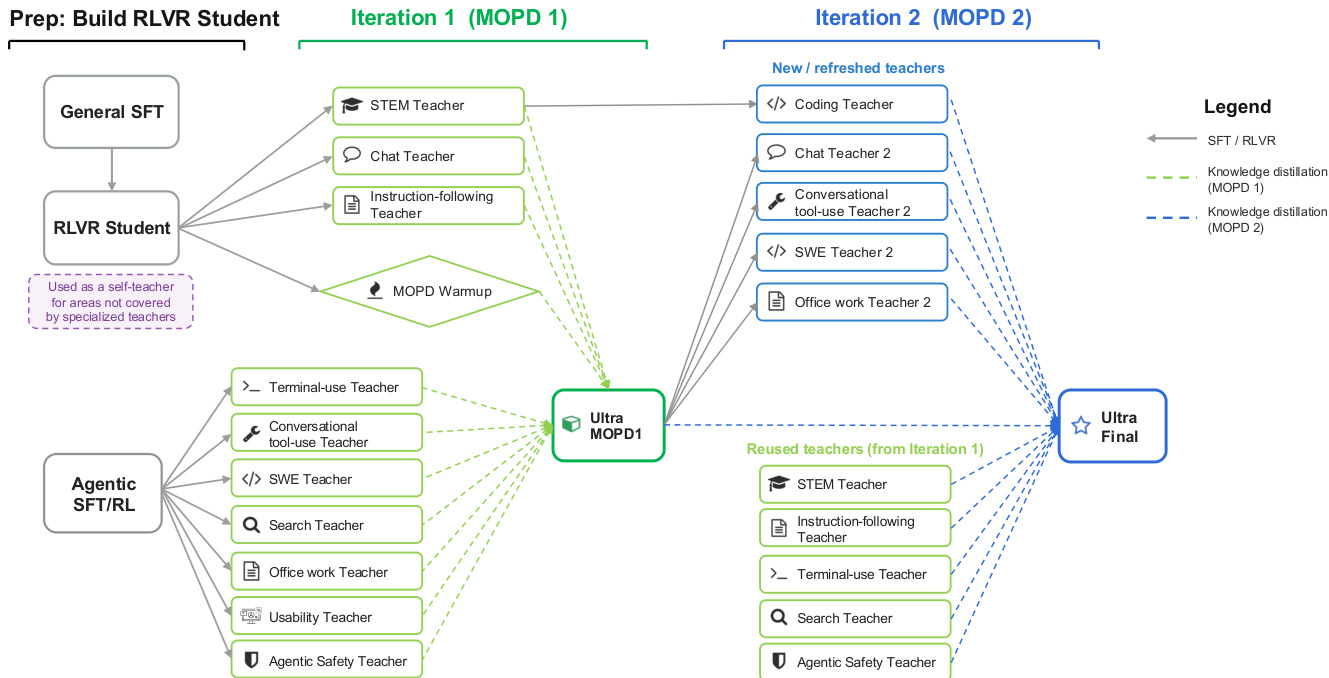
In the first iteration, signals from general and agentic teachers are distilled into an intermediate model. In the second iteration, new teachers are initialized from this intermediate model, and improvements are merged back to create the final Ultra model. The objective function for MOPD trains the student to match the teacher distribution on states induced by the student itself, formulated as maximizing the negative reverse-KL objective:
IMOPD(θ)=∑i=1NλiEq∼Di, y∼πθ(⋅∣q)[∑t=1HlogπTi(yt∣st)−logπθ(yt∣st)],
where λi controls the sampling weight of domain i.
Finally, the model undergoes MTP Boosting to align the Multi-Token Prediction head with the backbone's distribution under inference conditions. This stage addresses the train-inference mismatch where the MTP head conditions on noisy hidden states generated by previous MTP steps. The boosting objective uses a temperature-scaled forward-KL loss against the backbone's logits to ensure the drafting head handles longer draft lengths gracefully. The loss function is defined as:
LMTP(θ)=Nmtp∣A∣T2∑k=1Nmtp∑t∈ADKL(σ(zt+k/T)σ(zt+kmtpk/T)).
This results in a model capable of native speculative decoding with significantly improved acceptance lengths.
Experiment
The evaluation setup utilized a comprehensive benchmark suite covering agentic tasks, reasoning, and long-context understanding, including held-out gates to validate generalization beyond development metrics. Training stability experiments addressed divergence issues through precision adjustments and learning rate annealing, while post-training distillation demonstrated that MOPD effectively improves agentic performance when teacher-student distribution mismatches are mitigated. Quantization and infrastructure studies confirmed that NVFP4 precision with mixed-precision layers maintains long-context capabilities and that Multi-Token Prediction accelerates rollout generation, resulting in competitive agentic and reasoning performance with optimized inference efficiency.
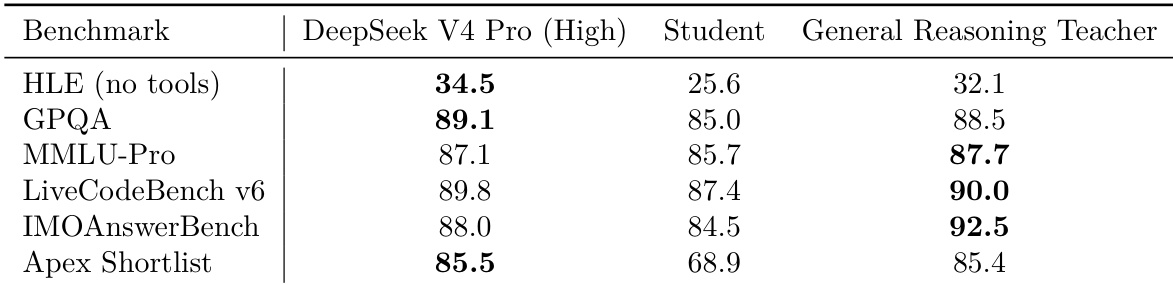
The the the table compares the performance of a Student model, a General Reasoning Teacher, and the DeepSeek V4 Pro (High) model across various reasoning and knowledge benchmarks. The Student model consistently underperforms compared to the other two models, particularly in complex reasoning tasks. The General Reasoning Teacher demonstrates competitive or superior performance in specific domains like mathematical reasoning and coding compared to the DeepSeek V4 Pro baseline. The General Reasoning Teacher achieves the highest scores on mathematical reasoning and coding benchmarks, including IMOAnswerBench and LiveCodeBench v6. DeepSeek V4 Pro (High) leads in general knowledge and complex reasoning evaluations such as HLE and GPQA. The Student model consistently records the lowest performance across all benchmarks, showing a substantial gap in the Apex Shortlist and HLE categories.
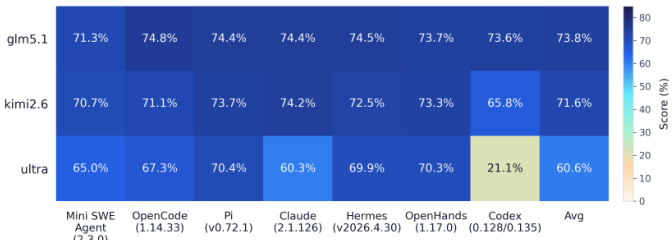
The the the table presents a comparison of code evaluation results for glm5.1, kimi2.6, and ultra across various benchmarks. glm5.1 demonstrates the strongest overall performance with the highest average score, while kimi2.6 follows closely with competitive results. The ultra model records the lowest average performance and exhibits a substantial decline on the Codex benchmark relative to the other models. glm5.1 achieves the highest average score across the evaluated code tasks kimi2.6 shows strong performance on most benchmarks but dips on Codex ultra trails in overall effectiveness and displays a significant performance gap on the Codex benchmark
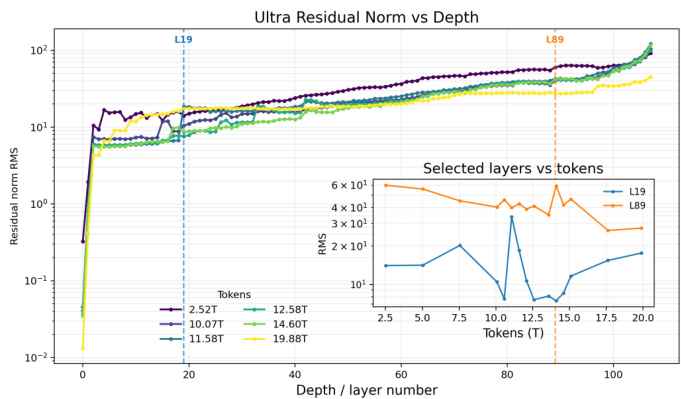
The authors analyze residual activation norms to diagnose training instability in the Ultra model. The data shows that while norms generally increase with layer depth, early layers exhibit significant spikes in activation magnitude during the middle of pretraining, indicating poor signal propagation. Residual norms grow consistently across the model depth, spanning multiple orders of magnitude. Early layers experience drastic norm spikes around the 11 trillion token mark, aligning with observed training divergence. Later layers maintain higher residual norms but show distinct stability patterns compared to the volatile early layers.
The authors compare the efficiency of HuggingFace transformers and Megatron-LM for model preparation workflows. Results demonstrate that Megatron-LM achieves a significantly faster total turnaround time despite utilizing a larger compute cluster. The most substantial performance gains are observed in the model loading and calibration phases. Megatron-LM reduces the total workflow time to a fraction of that required by HuggingFace transformers. Model loading is drastically faster with Megatron-LM compared to the baseline framework. Calibration time sees the largest relative improvement, dropping to a minimal duration with Megatron-LM.

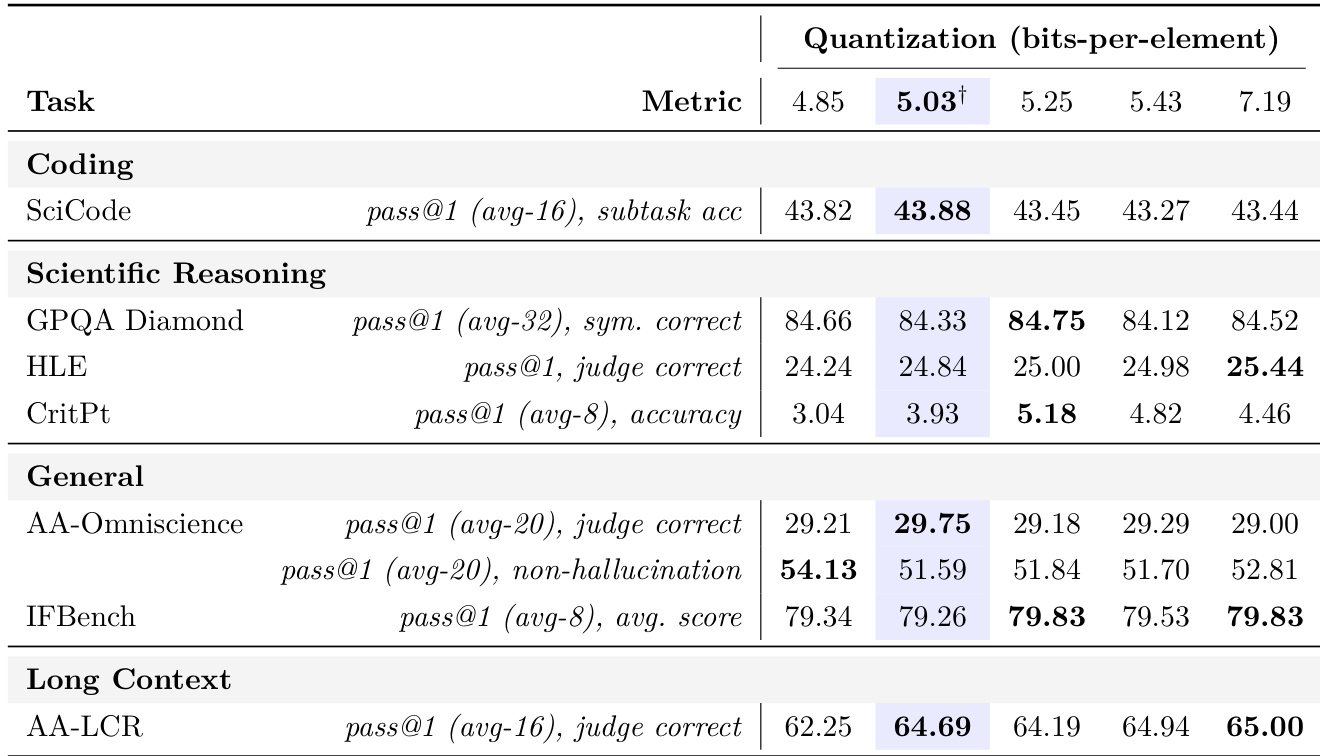
The authors evaluate the impact of varying quantization precision on model performance across coding, reasoning, and long-context tasks. Results indicate that while most capabilities remain stable across the tested range, long-context reasoning improves significantly at a specific intermediate precision setting before plateauing. This analysis supports the selection of a balanced operating point that recovers long-context performance without the overhead of higher precision configurations. Most benchmark scores remain consistent across the tested quantization precision range. Long-context reasoning shows a distinct performance improvement at a specific precision threshold. Increasing precision beyond the selected point yields no measurable gains on the evaluated tasks.
Benchmark comparisons reveal that the General Reasoning Teacher achieves superior performance in mathematical reasoning and coding relative to DeepSeek V4 Pro, while the Student and Ultra models consistently record the lowest scores across evaluated tasks. Diagnostic analysis of residual activation norms reveals early layer instability during pretraining as a primary cause of training divergence, while infrastructure comparisons demonstrate that Megatron-LM drastically reduces workflow time relative to HuggingFace transformers. Finally, quantization studies identify a specific precision threshold that improves long-context reasoning without increasing overhead, supporting the selection of a balanced operating point for deployment.