Command Palette
Search for a command to run...
Selbstdistillierter Policy Gradient
Selbstdistillierter Policy Gradient
Yifeng Liu Shiyouan Zhang Yifan Zhang Quanquan Gu
Zusammenfassung
On-Policy-Selbstdistillation, bei der ein Sprachmodell sein eigenes Generieren durch konditionierte Nutzung privilegierter Kontextinformationen überwachend steuert, stellt vielversprechende dichte Supervisionssignale für Reinforcement Learning mit spärlichen Belohnungen dar. Konkret kann dies als eine auxiliary Full-Vocabulary Student-to-Teacher reverse Kullback-Leibler-Divergenz-Verlustfunktion formuliert werden. Daher schlägt SDPG vor, ein selbstdistilliertes Policy-Gradient-Framework, das Gruppenrelativ-Verifizierer-Vorteile mit normalisierter Standardabweichung, exakte Full-Vocabulary On-Policy-Selbstdistillation sowie Referenz-Policy-KL-Regularisierung kombiniert. Empirisch verbessert SDPG Stabilität und Leistung gegenüber RLVR- und Selbstdistillations-Baselines.Terminologie-Erklärungen:- On-policy: Behält den englischen Begriff bei, da er in der RL-Literatur standardisiert ist- Self-distillation: Wörtlich übersetzt als "Selbstdistillation"- KL-divergence: Bleibt als "Kullback-Leibler-Divergenz" erhalten- RLVR: Abkürzung für "Reinforcement Learning with Verifiable Rewards" - bleibt als Akronym erhalten
One-sentence Summary
The authors propose SDPG, a self-distilled policy-gradient framework that combines group-relative verifier advantages, normalized standard deviation, exact full-vocabulary on-policy self-distillation via an auxiliary student-to-teacher reverse Kullback-Leibler divergence loss, and reference-policy KL regularization to improve stability and performance over RLVR and self-distillation baselines in sparse-reward reinforcement learning.
Key Contributions
- The paper introduces SDPG, a self-distilled policy-gradient framework that utilizes on-policy self-distillation to provide dense supervision for sparse-reward reinforcement learning.
- This approach combines group-relative verifier advantages with normalized standard deviation, exact full-vocabulary on-policy self-distillation, and reference-policy KL regularization.
- Empirical evaluations demonstrate that the framework improves stability and performance relative to RLVR and existing self-distillation baselines.
Introduction
Reinforcement Learning with Verifiable Rewards enables Large Language Models to master complex reasoning tasks without relying on human preference annotation. However, standard algorithms like GRPO suffer from sparse sequence-level rewards and training instability during early stages. While on-policy distillation provides dense token-level signals, traditional methods impose memory burdens with external teachers or risk reinforcing incorrect trajectories through pure self-distillation. The authors propose Self-Distilled Policy Gradient to integrate exact full-vocabulary privileged distillation into KL-regularized policy optimization. This approach combines sparse binary outcome rewards from a verifier with dense distillation signals from a context-conditioned teacher. They further implement stabilizers such as positive-advantage gating to control noise and show that the method improves upon GRPO and self-distillation baselines.
Method
The proposed Self-Distilled Policy Gradient (SDPG) framework integrates on-policy reinforcement learning with exact full-vocabulary self-distillation to improve stability and performance in reasoning tasks. The overall architecture is depicted in the framework diagram below, illustrating how a shared policy model interacts with privileged context to generate supervision signals.
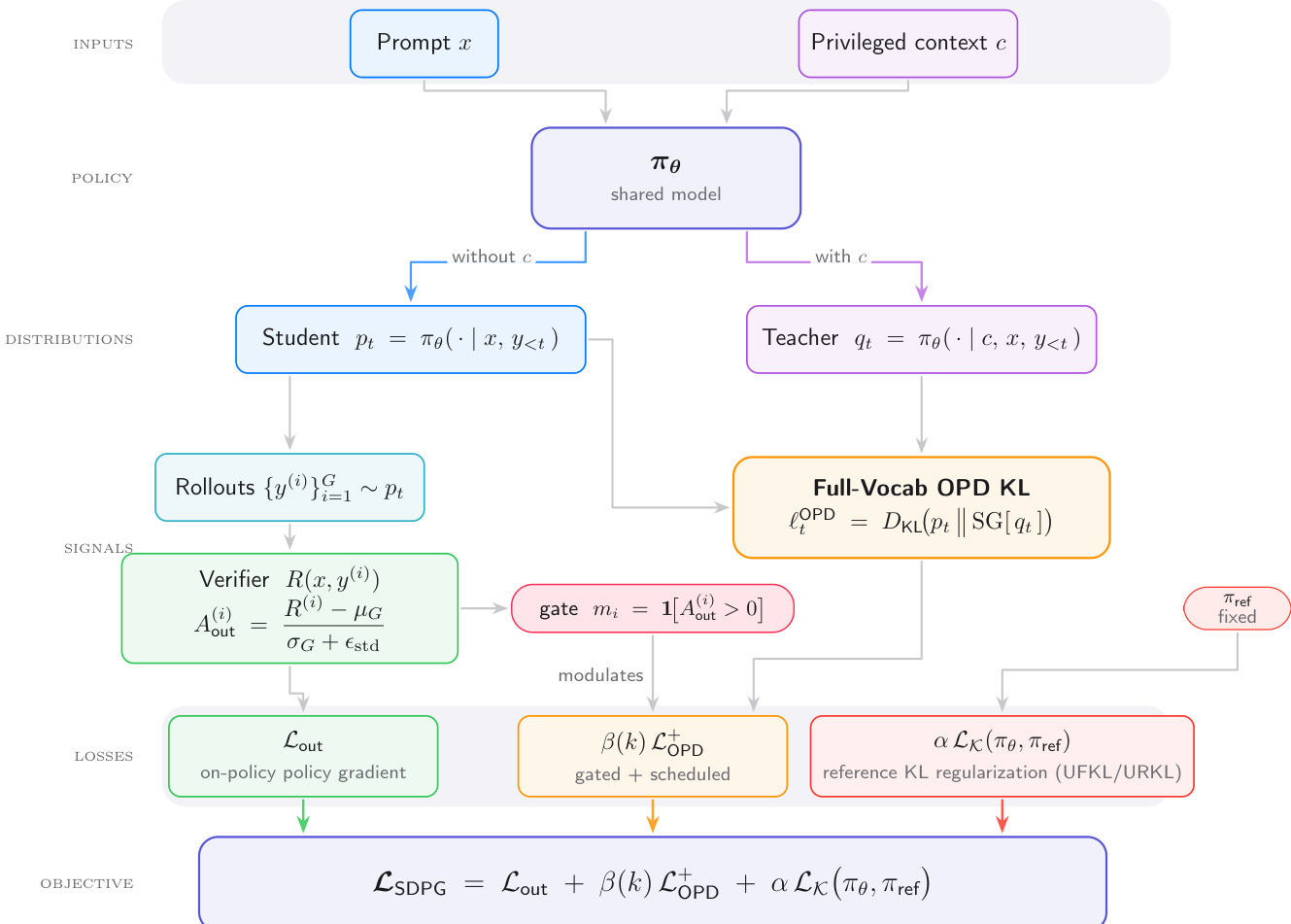
The framework operates on two inputs: the standard prompt x and a privileged context c, which may contain ground-truth reasoning traces or reference answers. A shared model πθ acts as both the student and the teacher. When conditioned only on x, it defines the student distribution pt=πθ(⋅∣x,y<t). When additionally conditioned on c, it defines the privileged teacher distribution qt=πθ(⋅∣c,x,y<t). The training objective combines three distinct loss components:
LSDPG=Lout+β(k)LOPD++αLK(πθ,πref)
The first component, Lout, is an on-policy reward-based loss derived from Group Relative Policy Optimization (GRPO). For a group of G sampled responses {y(i)}i=1G, the model computes group-relative advantages Aout(i) normalized by the mean and standard deviation of the verifier rewards R(x,y(i)). This term optimizes the policy using a REINFORCE-style surrogate loss without PPO clipping, relying on the verifier to guide exploration.
The second component, LOPD+, represents the gated full-vocabulary on-policy distillation loss. Instead of approximating the teacher signal via sampled tokens, SDPG minimizes the exact reverse Kullback-Leibler divergence between the student and teacher distributions over the full vocabulary V:
ℓi,tOPD=DKL(pi,t∥SG[qi,t])=∑a∈Vpi,t(a)logSG[qi,t(a)]pi,t(a)
To prevent the privileged signal from conflicting with the verifier on incorrect trajectories, this loss is gated by a binary mask mi=1[Aout(i)>0]. Consequently, distillation occurs only when the verifier endorses the rollout as correct.
The third component, LK, anchors the updated policy to a fixed reference policy πref to prevent collapse. The authors employ Unnormalized KL (UKL) divergence for this regularization, which handles potential mass mismatches and provides a more symmetric gradient. Two variants are supported: Unnormalized Forward KL (UFKL) and Unnormalized Reverse KL (URKL).
To manage the influence of the distillation signal, the coefficient β(k) follows a specific schedule illustrated in the figure below.
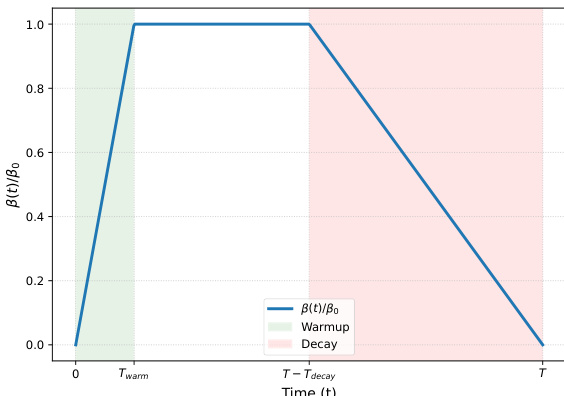
The schedule includes a warmup phase to allow the policy to stabilize before distillation begins, followed by a decay phase near the end of training to encourage exploration and avoid over-constraining the model with potentially noisy privileged signals.
The injection of privileged context c is handled via specific prompt engineering, as shown in the teacher prompt example below.

This prompt structure includes placeholders for the question, the correct answer, and solution steps, along with specific instructions to derive the answer using rigorous mathematical approaches without explicitly stating the source of the information. This ensures the teacher model generates high-quality reasoning traces that the student can learn to mimic during the distillation phase.
Experiment
This study empirically evaluates the proposed SDPG framework against baselines such as GRPO and RLSD on mathematical reasoning benchmarks using Qwen3 models. Experimental results demonstrate that SDPG variants achieve superior accuracy and faster convergence while avoiding the entropy collapse and training instability observed in pure self-distillation methods. Ablation studies further validate that combining full-vocabulary privileged distillation with policy KL regularization is essential for maintaining coherent reasoning patterns and stability across different model scales.
The authors empirically evaluate their proposed SDPG algorithm against baselines on mathematical reasoning tasks using a pretrained LLM. The results show that both SDPG variants consistently achieve higher performance than baseline methods like GRPO and RLSD across all benchmarks. SDPG-UFKL generally secures the highest scores, while SDPG-URKL demonstrates the best performance on the AIME25 benchmark. Both SDPG variants consistently outperform baseline methods like GRPO and RLSD across all benchmarks. SDPG-UFKL achieves the highest scores on the majority of metrics, particularly on AIME24 and AMC23. SDPG-URKL secures the top performance specifically on the AIME25 benchmark.
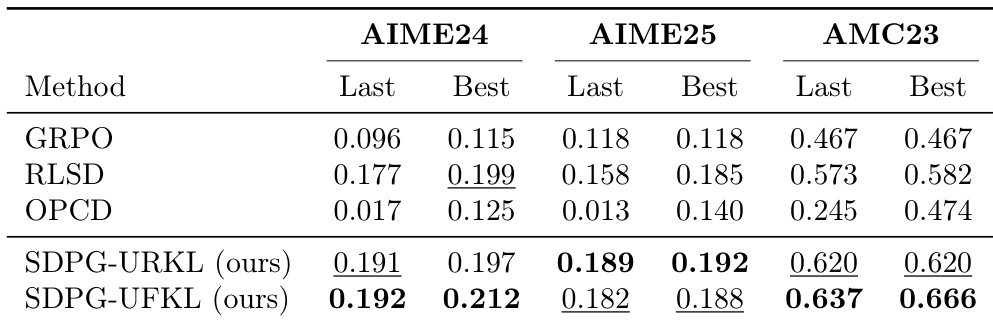
The authors evaluate their proposed SDPG framework against baselines like GRPO and RLSD on mathematical reasoning benchmarks including AIME24, AIME25, and AMC23. The results demonstrate that both SDPG variants consistently outperform the baseline methods across all tested datasets. Specifically, the SDPG-UFKL variant achieves the highest performance in the majority of the reported metrics. Both SDPG variants consistently outperform baseline methods across all mathematical reasoning benchmarks. The SDPG-UFKL variant secures the highest performance scores in the majority of the evaluation categories. Significant performance improvements are observed on the AMC23 benchmark where the proposed methods lead substantially over baselines.
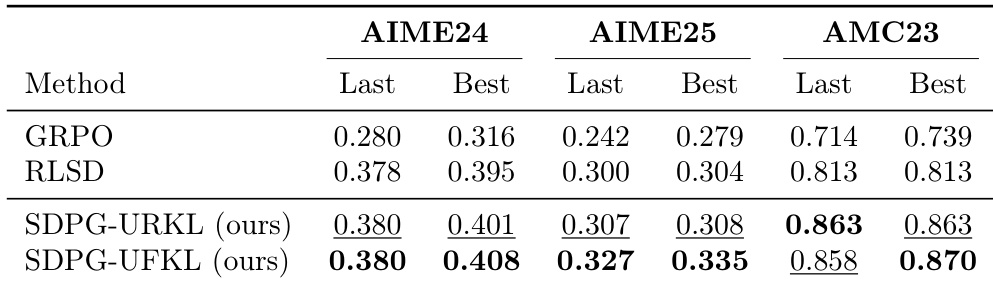
The authors evaluate the proposed SDPG framework using a pretrained LLM against baselines like GRPO and RLSD on mathematical reasoning benchmarks including AIME24, AIME25, and AMC23. Both SDPG variants consistently outperform the baseline methods across all tested datasets, with significant improvements observed particularly on AMC23. Specifically, the SDPG-UFKL variant secures the highest performance scores in the majority of evaluation categories while SDPG-URKL leads on the AIME25 benchmark.