Command Palette
Search for a command to run...
Code2LoRA: Hypernetzwerk-generierte Adapter für Code-Sprachmodelle unter Softwareevolution
Code2LoRA: Hypernetzwerk-generierte Adapter für Code-Sprachmodelle unter Softwareevolution
Liliana Hotsko Yinxi Li Yuntian Deng Pengyu Nie
Zusammenfassung
Code-Sprachmodelle benötigen Kontext auf Repository-Ebene, um Importe, APIs und Projektkonventionen aufzulösen. Bestehende Methoden integrieren dieses Wissen als lange Eingaben (die über RAG oder Abhängigkeitsanalyse abgerufen werden) oder nutzen Repository-spezifisches Fine-Tuning sowie LoRA – beides ist im Repository-Maßstab kostspielig und bei sich weiterentwickelnden Codebasen anfällig. Wir stellen Code2LoRA vor, ein Hypernetwork-Framework, das repository-spezifische LoRA-Adapter generiert und damit Repository-Wissen effektiv mit einem Inference-Zeit token overhead von null injiziert. Code2LoRA unterstützt zwei Nutzungsszenarien: Code2LoRA-Static wandelt einen einzelnen Repository-Snapshot in einen Adapter um, was sich für das Verständnis stabiler Codebasen eignet; Code2LoRA-Evo hingegen pflegt einen Adapter, der von einem GRU hidden state gestützt wird, der pro Code-Diff aktualisiert wird, und eignet sich für die aktive Entwicklung sich weiterentwickelnder Codebasen. Um Code2LoRA gegenüber Baselines für parameter-effizientes Fine-Tuning zu evaluieren, entwickeln wir RepoPeftBench, einen Benchmark mit 604 Python-Repositories, der zwei Tracks umfasst: einen statischen Track mit 40K Trainings- und 12K Test-Aufgaben zur Assertion-Vervollständigung sowie einen Evolutions-Track mit 215K commit-abgeleiteten Trainings- und 87K commit-abgeleiteten Test-Aufgaben. Im statischen Track erzielt Code2LoRA-Static 63,8 % cross-repo und 66,2 % in-repo exact match und entspricht damit der pro Repository geltenden Obergrenze für LoRA; im Evolutions-Track erzielt Code2LoRA-Evo 60,3 % cross-repo exact match (+5,2 pp gegenüber einem einzelnen gemeinsam genutzten LoRA). Der Code von Code2LoRA ist unter https://anonymous.4open.science/r/code2lora-6857 verfügbar; die Modell-Checkpoints sowie die RepoPeftBench-Datensätze finden sich unter https://huggingface.co/code2lora.
One-sentence Summary
Code2LoRA is a hypernetwork framework that generates repository-specific LoRA adapters to inject codebase context with zero inference-time token overhead, bypassing costly fine-tuning and brittle retrieval pipelines by dynamically adapting to stable snapshots via Code2LoRA-Static or evolving diffs through a GRU-updated Code2LoRA-Evo, and achieving 66.2% in-repo exact match on the static track and 60.3% cross-repo exact match on the evolution track of the RepoPeftBench benchmark.
Key Contributions
- Code2LoRA is a hypernetwork framework that generates repository-specific LoRA adapters to inject project context into code language models with zero inference-time token overhead. It operates through a static variant that maps single repository snapshots and an evolutionary variant that maintains a GRU hidden state updated per code diff to support active development.
- RepoPeftBench is introduced as a benchmark of 604 Python repositories featuring distinct static and evolution tracks with thousands of assertion-completion and commit-derived tasks. The dataset includes a 92-repository temporal holdout split to evaluate out-of-distribution generalization on evolving codebases.
- Evaluations demonstrate that the framework outperforms existing context-injection and parameter-efficient fine-tuning baselines by 9.9 percentage points on the static track and 5.2 percentage points on the evolution track. The evolutionary variant matches the per-repository LoRA upper bound on in-repo tasks while maintaining strong accuracy on the temporal out-of-distribution holdout.
Introduction
Code language models require deep repository-level context to accurately resolve imports, APIs, and project-specific conventions, making effective knowledge injection essential for reliable coding assistance. Prior approaches typically rely on retrieval-augmented generation or dependency analysis to feed massive context windows, which strains computational resources and retrieval accuracy, while per-repository fine-tuning or LoRA adaptation proves expensive and brittle as codebases evolve. The authors leverage hypernetworks to generate repository-specific LoRA adapters that inject this knowledge directly into model parameters with zero inference-time token overhead. They introduce Code2LoRA, which operates in a static mode for stable repositories and an evolutionary mode that updates adapters via a GRU hidden state as code diffs arrive, alongside a new benchmark called RepoPeftBench to rigorously evaluate parameter-efficient adaptation under software evolution.
Dataset

-
Dataset Composition and Sources The authors construct RepoPeftBench, a repository-level benchmark comprising 604 Python repositories sourced from GitHub. All repositories adhere to shared quality filters requiring
pytestorunittestusage, permissive licensing, and recent activity. The corpus is divided by a temporal cutoff of April 1, 2025, into in-distribution and out-of-distribution subsets, with data collection capturing both the final repository snapshot and full commit histories. -
Subset Details
- The in-distribution subset contains 512 repositories collected before the cutoff. These repositories must have at least 300 stars and are hard-filtered for MIT licenses. This subset provides all training and validation data, with commit histories truncated at the cutoff date.
- The out-of-distribution subset comprises 92 repositories created strictly after the cutoff. These repositories lack the star count requirement, with candidates searched from six stars upward, and may carry MIT or Apache-2.0 licenses. This set is reserved exclusively for held-out test-time evaluation.
-
Data Usage and Splits
- The authors partition the 512 in-distribution repositories into Cross-Repo and In-Repo sets. The Cross-Repo set holds out 103 repositories entirely during training, split into 51 validation and 52 test repositories, to assess generalization to unseen codebases. The In-Repo set uses the remaining 409 repositories for training and supports per-repository LoRA adaptation.
- Two evaluation tracks share these repository partitions but differ in instance indexing. The Static track extracts instances from a single snapshot per repository, generating 62,294 tasks. For In-Repo splits, instances are randomly divided in an 8:1:1 ratio. The Evolution track replays commit histories and emits a task whenever a commit adds or modifies an assertion. For In-Repo splits, commits are partitioned chronologically to ensure training examples strictly precede validation and test data.
- The Evolution track applies a smart cap during training, restricting tasks to a maximum of eight per commit and four per test file to prevent dominant commits from skewing backpropagation windows.
-
Processing and Metadata
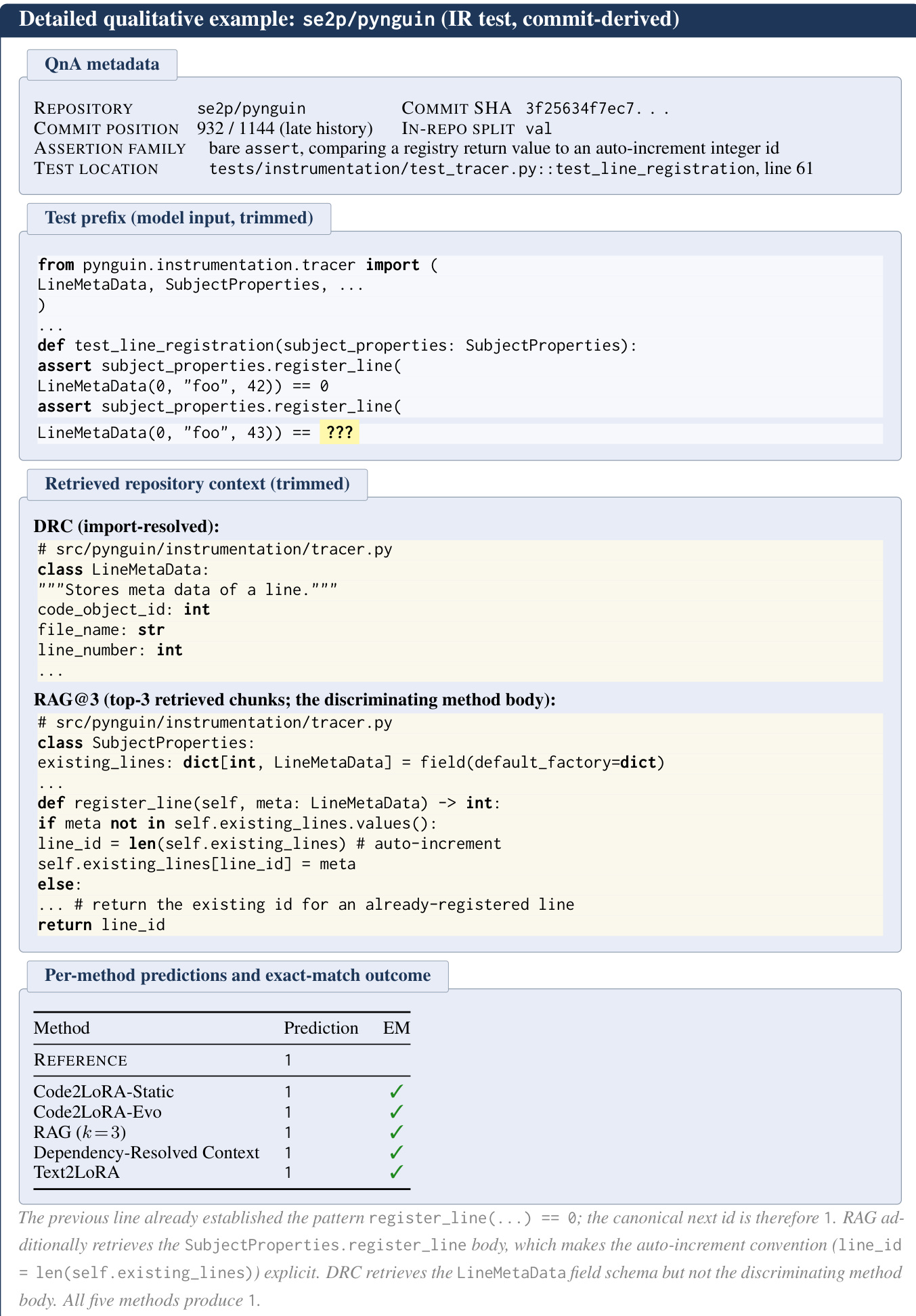
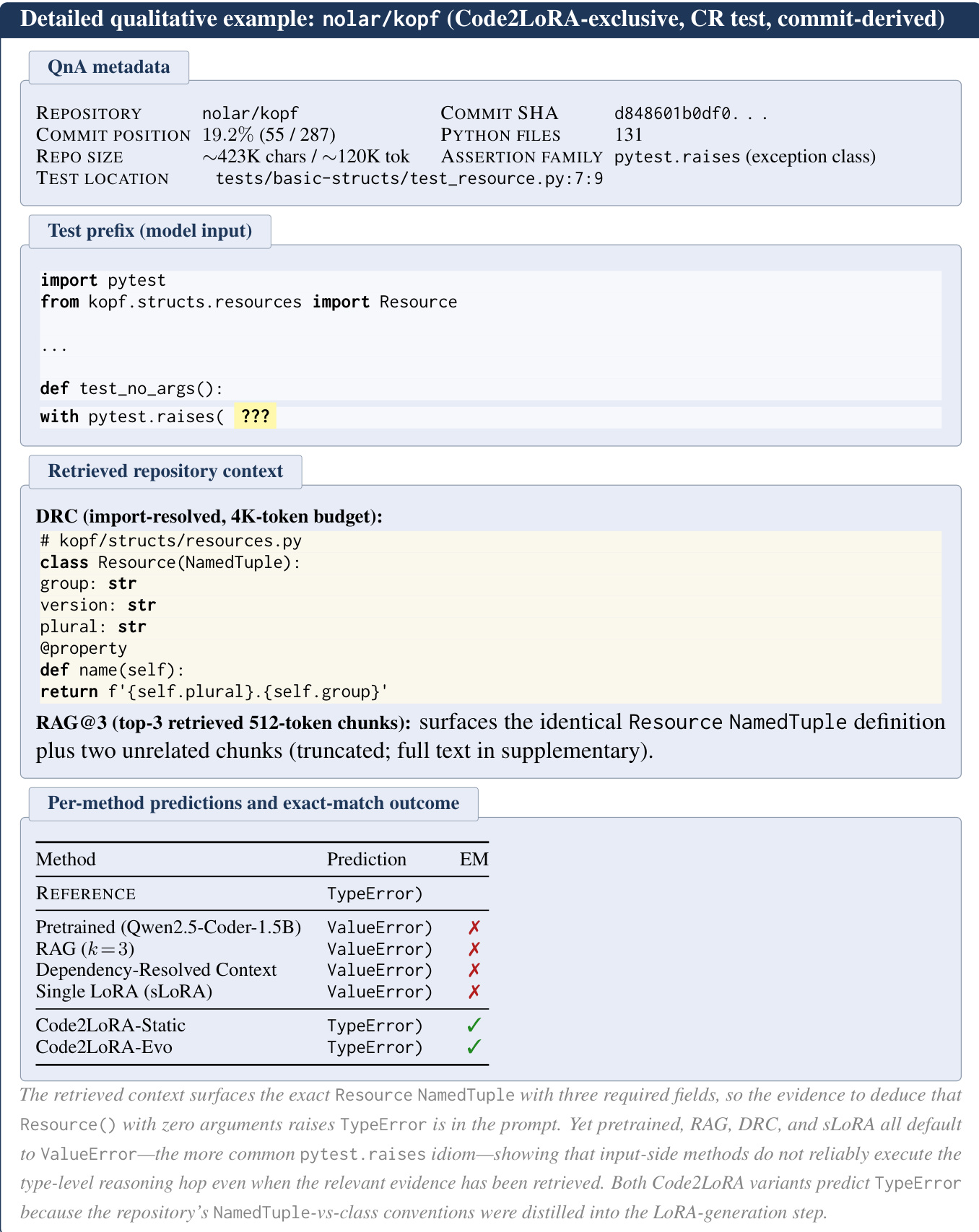
- Each instance represents an assertion-completion task where the model predicts the expected value of an assertion based on a structured prefix. The input concatenates imports, the enclosing class, helper methods, and the test function body up to the assertion cut point. The output corresponds to the right-hand side of the comparison operator or the final argument of the assertion function.
- Instances are mined from five assertion families:
bare assert,self.assert*,unittest.raises,unittest.assert*, andNumPy-style assert_*. - The pipeline applies filtering rules to exclude malformed targets, including those starting with commas, located outside function bodies, empty, duplicated within a function, or containing only punctuation.
- Metadata statistics indicate a median repository size of 165K tokens, a median prefix length of 224 tokens, and a median target length of three tokens. Dependency resolution context is available for 64.1% of pairs. The dataset release retains LICENSE files and source code verbatim without PII scrubbing to preserve identifiers essential for the prediction task.
Method
The Code2LoRA framework is a hypernetwork-based approach designed to generate repository-specific LoRA adapters for a frozen code language model, enabling the injection of repository-level knowledge with zero inference-time token overhead. The overall architecture, as illustrated in Figure 1a, comprises three main components: a shared repository encoder that processes repository-level context into dense embeddings, a hypernetwork that maps these embeddings to LoRA weights, and a frozen base LLM that receives the generated adapters to perform inference. Only the hypernetwork is trained, while the repository encoder and the base LLM remain frozen throughout the process. The framework supports two distinct usage scenarios: Code2LoRA-Static, which generates a single adapter from a static repository snapshot, and Code2LoRA-Evo, which maintains a dynamic adapter trajectory over the repository's evolution through sequential code diffs.
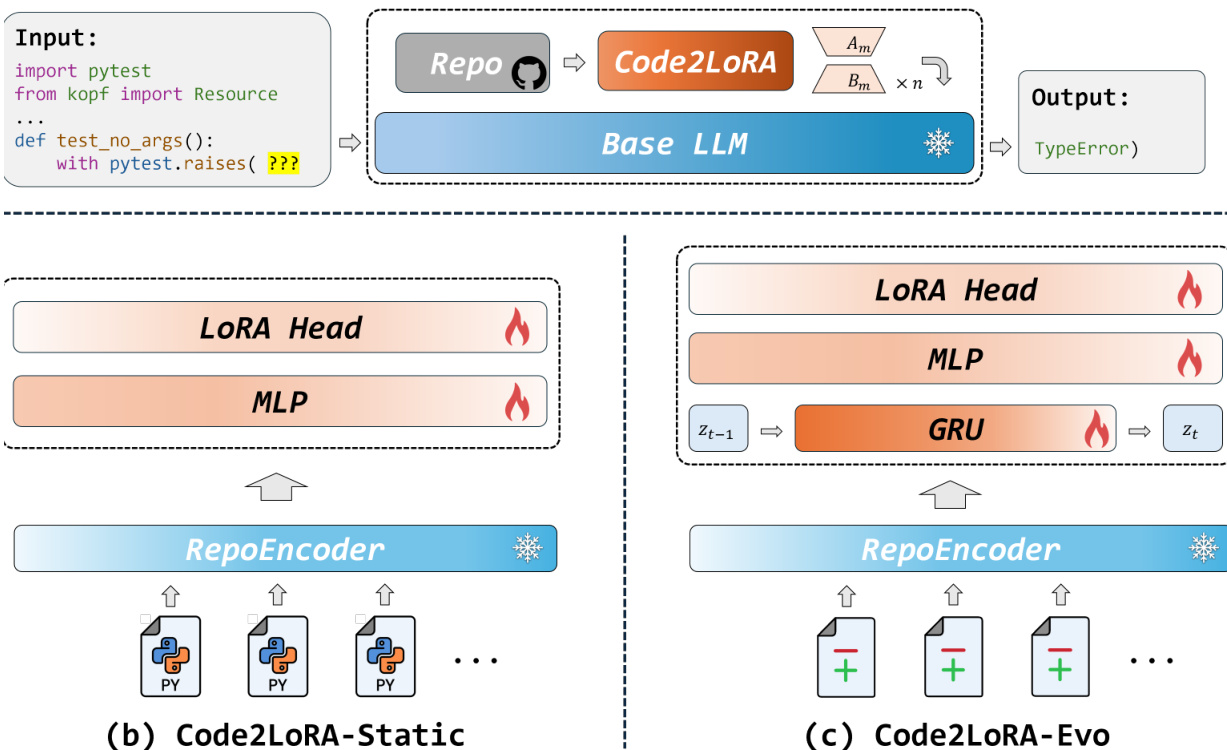
The repository encoder, detailed in Section 3.1, compresses repository-level context into a fixed-size vector through a two-step, training-free process using a frozen Qwen3-Embedding-0.6B model. First, each file in the repository is divided into 4096-token chunks with a 512-token overlap, embedded, and mean-pooled to produce a file-level vector. Second, these file vectors are aggregated into a repository-level embedding by computing a weighted mean and a max pool, capturing both the average characteristics and the most distinctive features of the codebase. The weights for this aggregation are determined based on a combination of content distinctiveness, file size, and path importance. The resulting repository embedding, e, is pre-computed offline and stored for use during training and inference.
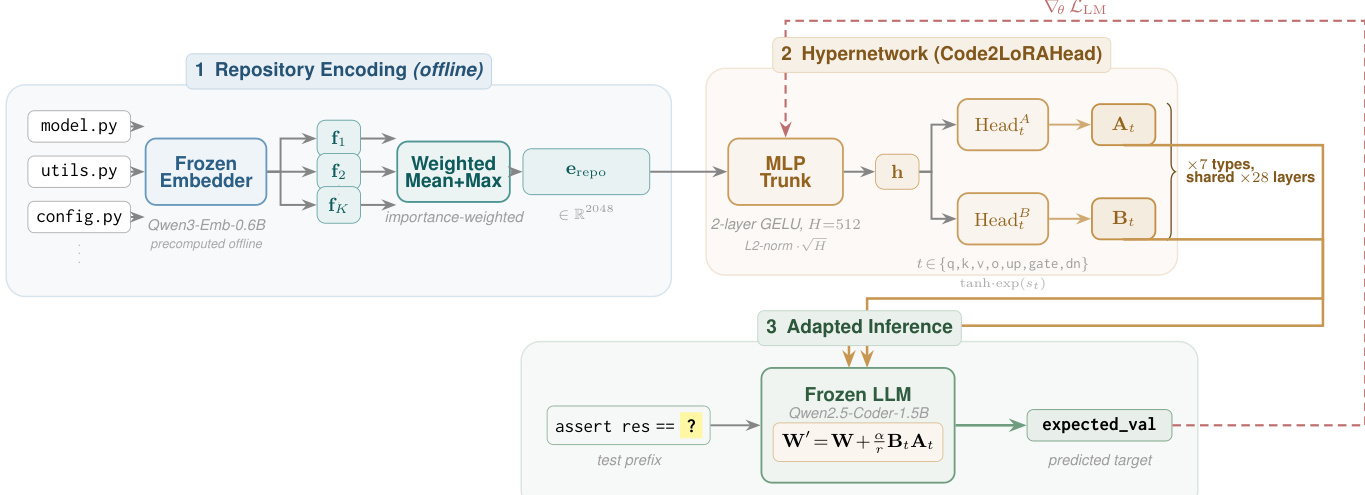
For the Code2LoRA-Static variant, the hypernetwork, depicted in Figure 1b, takes the single repository embedding e as input and generates a LoRA adapter in a single forward pass. This is achieved through a shared 2-layer MLP with GELU activation, followed by dedicated output heads for each of the seven module types (query, key, value, output, gate, up, down). The hidden representation h from the MLP trunk is L2-normalized and rescaled by dh. The LoRA matrices Am and Bm for each module type m are then generated using tanh(HeadmA(h))⋅exp(smA) and tanh(HeadmB(h))⋅exp(smB), where smA/B are learnable log-scale parameters that control the adapter magnitudes. The generated LoRA weights are injected into the base LLM via the standard LoRA update rule W′=W+rαBmAm.
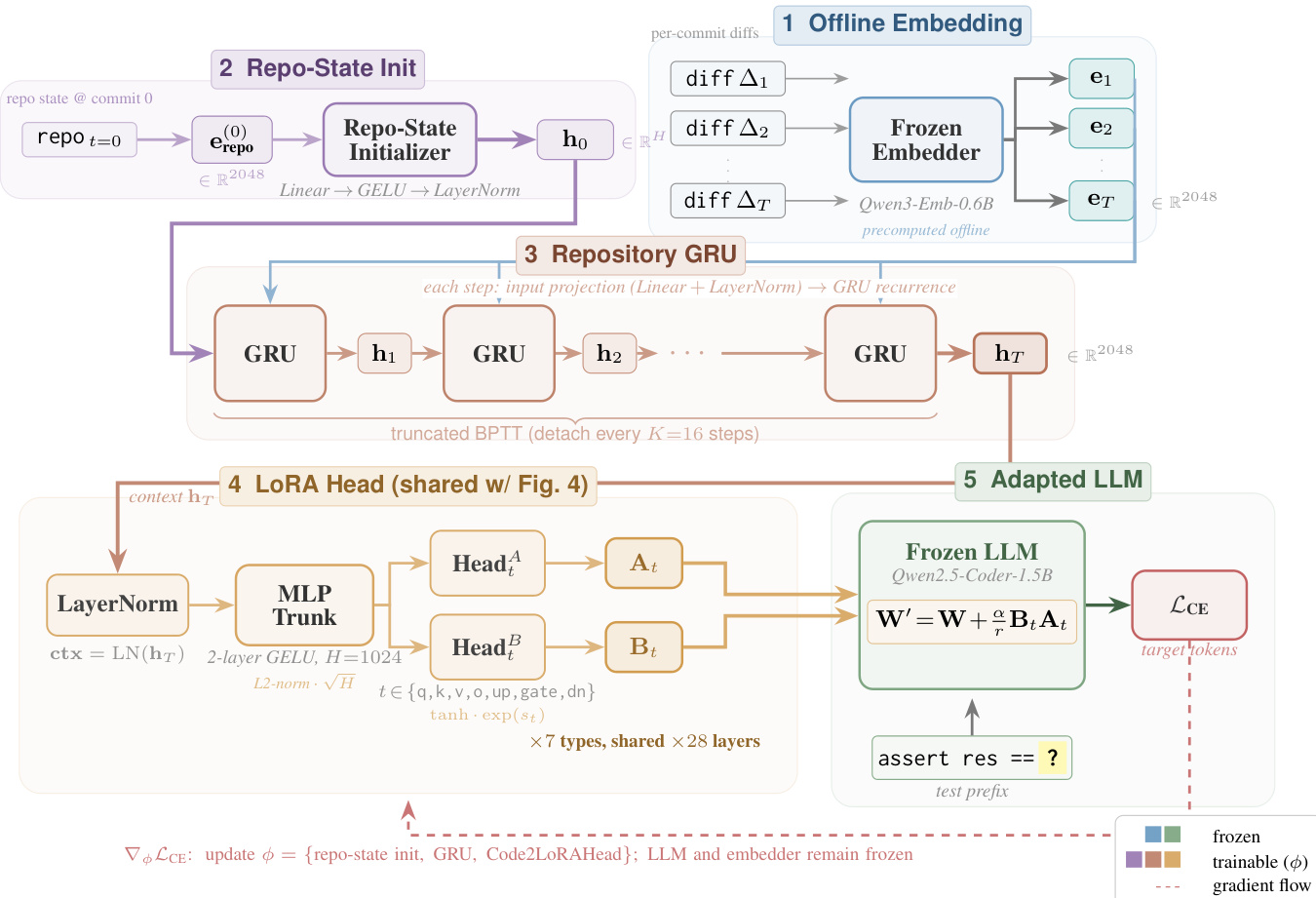
The Code2LoRA-Evo variant, shown in Figure 1c, extends the static approach to model software evolution. It maintains a repository-specific adapter over a chronological stream of diff embeddings {et}. This is accomplished by inserting a GRU recurrent neural network between the repository encoder and the LoRA generation head. At each step t, the GRU receives a linearly projected diff embedding et and combines it with the previous hidden state zt−1 to produce the current state zt. The initial GRU state z0 is initialized by a small linear projector that maps the initial repository embedding. At each step, the LoRA adapter is generated by the same shared head as in Code2LoRA-Static, but using the current GRU state zt as input. This process yields an adapter trajectory over the repository's lifetime, allowing the model to adapt to code changes commit by commit.
The training process, as detailed in Section 3.4, is conducted end-to-end by minimizing the cross-entropy loss on assertion-completion pairs from the frozen base LLM. The loss function is defined as L(θ)=−∑(x,y)∈Dlogp(y∣x;Hypernetworkθ(u)), where u is the input to the hypernetwork. For Code2LoRA-Static, u is the repository embedding e, while for Code2LoRA-Evo, u is the current GRU hidden state zt. To manage the sequential nature of the data, Code2LoRA-Evo employs truncated backpropagation through time, detaching the hidden state every K=16 steps. Batches are formed by sampling a repository and a pair of input-output from it to ensure diverse exposure and prevent overfitting to data-rich repositories. The hypernetwork is trained using AdamW with a cosine learning rate schedule and a weight decay of 0.01, with the base LLM and repository encoder remaining frozen.
Experiment
The evaluation leverages the RepoPeftBench benchmark across static, evolving commit, and out-of-distribution temporal tracks to validate repository-level code adaptation strategies. Results demonstrate that parametric adaptation through a LoRA-generating hypernetwork consistently outperforms context-injection and full fine-tuning baselines by effectively transferring cross-repository knowledge while circumventing the severe overfitting observed in per-repository training. Additionally, the evolutionary variant successfully aggregates sequential code diffs to mitigate model staleness, preserving robust performance across repository lifecycles and unseen codebases. Structural and deployment analyses further confirm that the generated adapters remain semantically diverse and highly efficient, requiring negligible inference overhead compared to traditional fine-tuning approaches.
The authors evaluate Code2LoRA variants on repository adaptation tasks, comparing static and evolving code scenarios. Results show that parametric adaptation outperforms context injection and that recurrent aggregation over commit diffs improves performance on evolving repositories. Code2LoRA-Evo achieves the best results on both tracks, with consistent gains across repository types and a minimal drift over time. Parametric adaptation methods outperform context-injection techniques on both static and evolution tracks. Code2LoRA-Evo demonstrates a consistent advantage on evolving repositories by aggregating commit history. Code2LoRA variants maintain high performance across repository types with minimal per-repository variance.
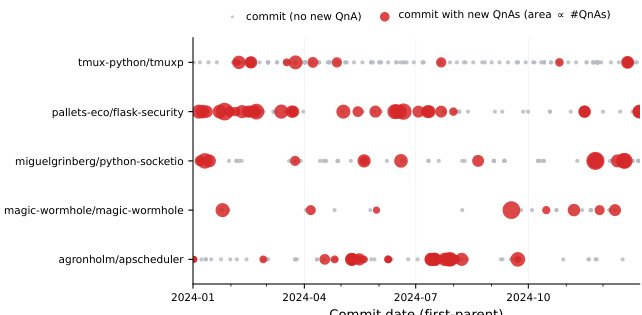
The authors evaluate Code2LoRA variants on repository-level code completion tasks, comparing their performance against various baselines across static and evolving repository scenarios. Results show that parametric adaptation methods outperform context-injection approaches, with Code2LoRA-Evo demonstrating superior performance in evolution settings due to its ability to aggregate commit history, while Code2LoRA-Static achieves strong cross-repository generalization on static snapshots. Parametric adaptation methods outperform context-injection methods on both static and evolution tracks. Code2LoRA-Evo achieves the highest performance on evolution tasks by leveraging recurrent aggregation of commit diffs. Code2LoRA-Static matches the performance of per-repository LoRA on in-repo evaluation without requiring per-repository training.
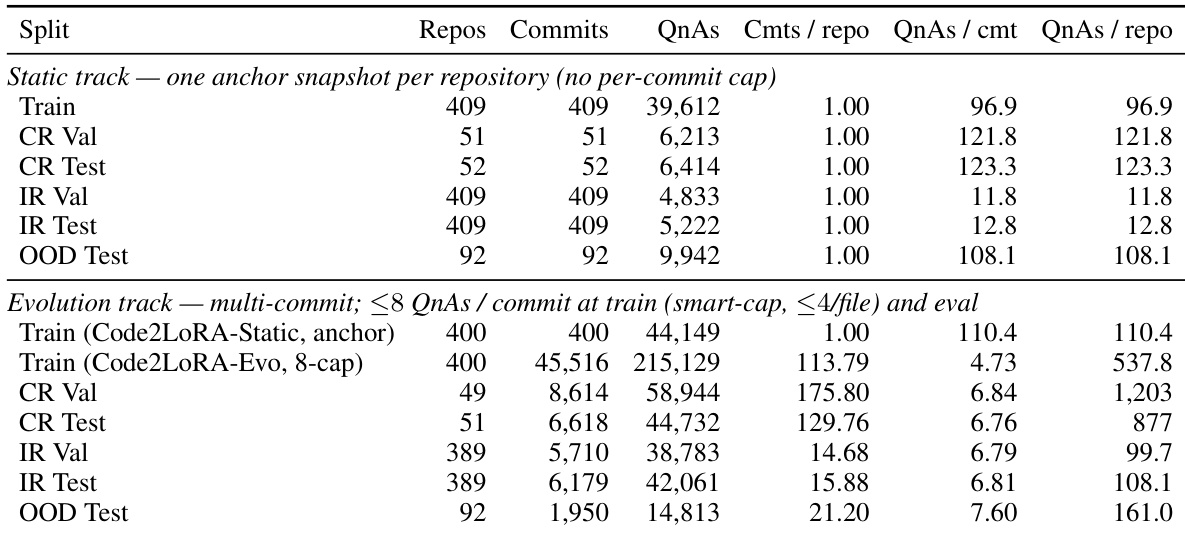
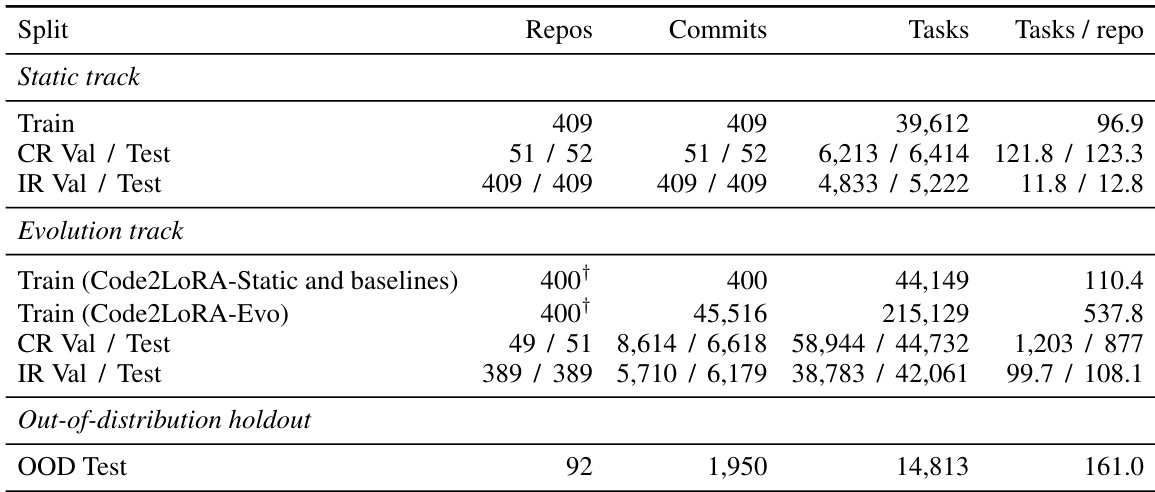
The the the table presents dataset statistics for RepoPeftBench, divided into static and evolution tracks. The static track uses a single snapshot per repository with one anchor commit, while the evolution track involves multiple commits and a smart-cap on the number of QnAs per commit, with a higher number of QnAs per repository in the training and test splits. Both tracks share the same set of in-distribution repositories but differ in the number of commits and QnAs per commit, with the evolution track showing a higher number of commits and QnAs per commit. The static track uses one anchor snapshot per repository with a consistent number of QnAs per commit, while the evolution track involves multiple commits and a higher number of QnAs per commit. The number of QnAs per repository is significantly higher in the evolution track compared to the static track. Both tracks share the same set of in-distribution repositories but differ in the number of commits and QnAs per commit, with the evolution track showing a higher number of commits and QnAs per commit.
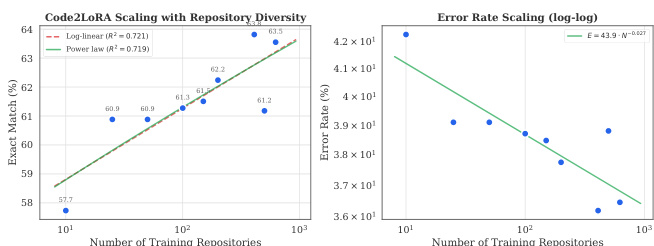
The experiments examine the impact of training repository diversity on model performance, showing that performance improves with more repositories and that the error rate decreases as the number of training repositories increases. The results indicate that the model benefits from a diverse set of repositories, with performance saturating at a few hundred repositories. Performance improves with increasing repository diversity, showing a log-linear trend up to around 200 repositories. The error rate decreases as the number of training repositories increases, indicating better generalization with more diverse data. Performance saturates at a few hundred repositories, suggesting diminishing returns beyond that point.
The experiment evaluates Code2LoRA variants on repository-level code completion tasks across static, evolution, and out-of-distribution settings, comparing them to various baselines including full fine-tuning, context injection, and per-repository adaptation. Results show that parametric adaptation methods, particularly Code2LoRA, outperform context-based approaches, with Code2LoRA-Evo achieving the best performance on evolving repositories due to its ability to incorporate commit history. The framework demonstrates strong generalization and efficiency, generating repository-specific adapters without requiring per-repository training or extra inference tokens. Code2LoRA variants outperform context-injection and full fine-tuning methods on both static and evolution tracks, with Code2LoRA-Evo achieving the highest performance on evolving repositories. The static variant of Code2LoRA matches the performance of per-repo LoRA on in-repo tasks without requiring per-repository training, demonstrating effective cross-repository knowledge transfer. Code2LoRA-Evo maintains a consistent advantage across the commit timeline, showing minimal staleness compared to static adaptation methods, and achieves the best results on out-of-distribution repositories.
The evaluation assesses Code2LoRA variants on repository-level code completion across static snapshots and evolving commit histories, benchmarking them against context injection, full fine-tuning, and per-repository adaptation baselines. Results demonstrate that parametric adaptation consistently outperforms context-based methods, with the evolving variant leveraging commit history to maintain sustained accuracy over time while the static variant effectively generalizes across repositories without per-repository training. Additionally, experiments validate that model performance scales with training data diversity before plateauing, ultimately confirming the framework's efficiency and strong generalization capabilities across diverse and out-of-distribution codebases.