Command Palette
Search for a command to run...
堅牢なマルチビュー3D再構成のための幾何構造を考慮した表現のノイズ除去
堅牢なマルチビュー3D再構成のための幾何構造を考慮した表現のノイズ除去
概要
多視点3D再構築は、フィードフォワード3D再構築モデルの登場に伴い、著しい進展を遂げている。しかし、これらのモデルは通常、理想的で劣化のない撮像条件下で学習・評価されるのに対し、現実世界の観測データにはそのような条件とは大きく異なる劣化が含まれることが多くある。したがって、劣化条件下における多視点3D再構築の堅牢性を向上させることは、依然として重要な課題である。本稿では、フィードフォワード3D再構築モデルの特徴空間において直接拡散ベースの多視点復元を実行する新規フレームワークであるGeometry-Aware Representation Denoising (GARD) を提案する。本設計は、3D再構築モデルが有する幾何構造を考慮した特徴表現を活用し、正確なシーン幾何構造を効果的に復元する。さらに、追加のRGB画像デコーダを採用することで、改善された特徴表現を高品質なRGB画像の復元にも利用でき、これにより3Dシーン幾何構造と高品質な画像の同時復元を可能とする。Depth Anything 3 (DA3) ベンチマーク上での包括的な実験により、本提案のGARDフレームワークの有効性が実証された。
One-sentence Summary
Geometry-Aware Representation Denoising (GARD) is a diffusion-based framework that performs multi-view restoration directly within the feature space of a feed-forward 3D reconstruction model, leveraging geometry-aware representations and an auxiliary RGB decoder to achieve robust scene reconstruction under real-world degradation.
Key Contributions
- The paper introduces Geometry-Aware Representation Denoising (GARD), a diffusion-based framework that performs multi-view restoration directly within the feature space of a feed-forward 3D reconstruction model rather than in standard pixel or VAE latent spaces.
- The method leverages the reconstructor’s geometry-aware representations to preserve cross-view consistency and fine-grained structural details during denoising, thereby circumventing the information bottlenecks associated with compressed latent formulations.
- An integrated RGB image decoder translates the refined geometric features back into clean multi-view images, enabling robust 3D geometry recovery under real-world degradations such as camera motion blur.
Introduction
Multi-view 3D reconstruction transforms 2D observations into accurate scene geometry, enabling critical applications in autonomous navigation, robotics, and augmented reality. While modern feed-forward transformer models streamline this pipeline, they degrade significantly when processing real-world images affected by motion blur, which obscures fine textures and breaks cross-view geometric consistency. Prior restoration strategies struggle to compensate for these issues because single-view image-space methods ignore multi-view relationships, while compressed VAE-based latent spaces create information bottlenecks that discard structural details. The authors leverage a diffusion-based denoising framework called GARD that operates directly within the high-dimensional geometry-aware feature space of existing reconstruction models. By refining these structured representations and routing them through an auxiliary decoder, the approach simultaneously restores high-quality imagery and preserves accurate 3D geometry across all viewpoints.
Method
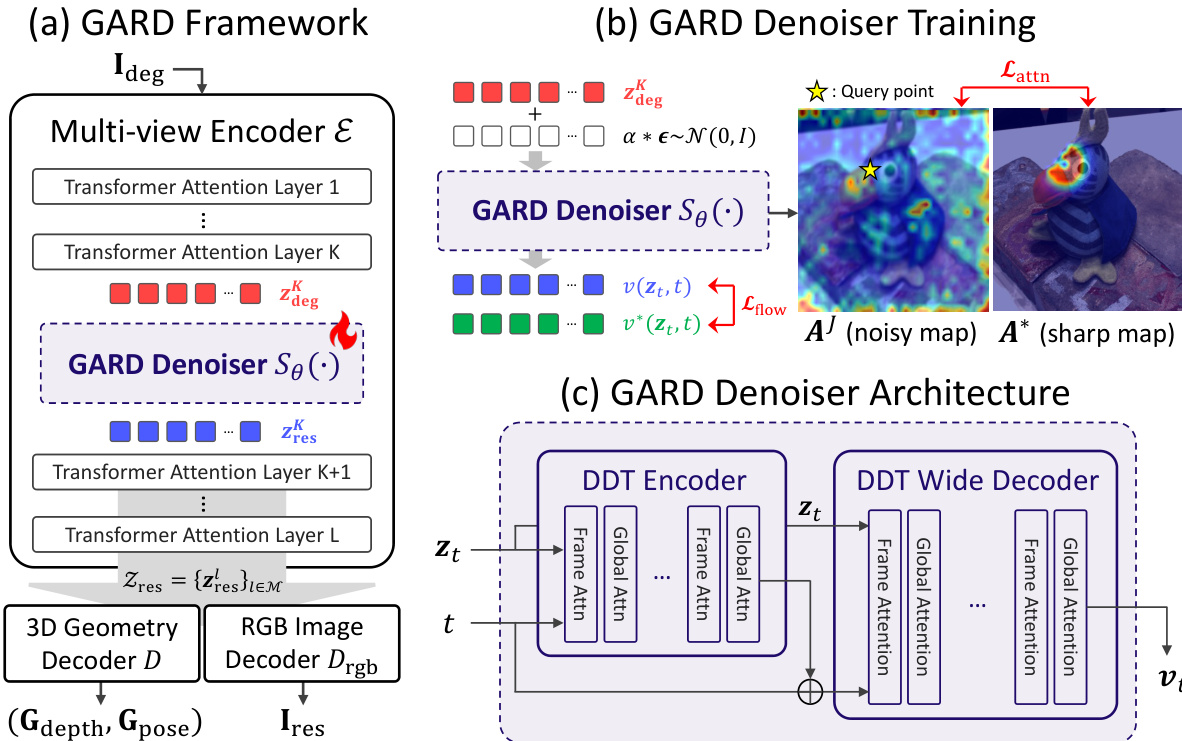
The authors propose Geometry-Aware Representation Denoising (GARD), a framework designed to perform multi-view image restoration directly within the geometry-aware feature space of a pre-trained feed-forward 3D reconstruction model. This approach contrasts with conventional pixel-space restoration methods that first denoise images and then feed them into a reconstructor, thereby failing to leverage multi-view consistency and potentially introducing view-dependent artifacts. The core of the GARD framework is a denoiser, Sθ(⋅), which operates on intermediate feature representations generated by the multi-view encoder of the reconstructor, F(⋅), rather than on the raw images. As shown in the figure below, the framework takes degraded multi-view images as input and processes them through the encoder to produce a degraded feature representation at a specific layer, zdegK. The GARD denoiser is inserted at this layer to refine the representation into zresK, which is then propagated through the remaining encoder layers. The restored features, Zres, are subsequently decoded by a geometry decoder and an RGB image decoder to produce the final outputs: the restored images and the estimated 3D scene geometry. This design enables simultaneous recovery of both visual and geometric information in a single forward pass without retraining the underlying backbone.

The GARD denoiser Sθ(⋅) is implemented as a multi-view latent diffusion model, specifically built upon the DiTDH architecture from Representation Autoencoders (RAEs). Its architecture, as detailed in the figure below, consists of a DDT encoder and a DDT wide decoder. The model is enhanced with interleaved global attention layers that enable multi-view modeling. Frame-level attention captures local spatial structures within each view, while global attention facilitates the aggregation of contextual information across views, allowing the model to exploit cross-view correspondences and enforce geometric consistency. The denoiser is trained using a combination of an interpolated flow matching loss and an attention alignment loss. The flow matching loss, which is optimized over a noise-perturbed source distribution, encourages the model to learn the mapping from degraded features to clean features by predicting a velocity field. This is complemented by the attention alignment loss, which regularizes the global attention maps of the denoiser to align with target correspondence maps derived from the clean input data, promoting sharper and more coherent attention patterns.
Experiment
The experiments evaluate the proposed GARD method against various single-view, multi-view, and video restoration baselines under severe motion blur degradation, validating its effectiveness across camera pose estimation, three-dimensional scene reconstruction, and image restoration. By operating directly within a geometry-aware feature space rather than relying on compressed latent representations or isolated single-view processing, the method successfully preserves cross-view consistency, structural fidelity, and fine geometric details that baseline approaches fail to maintain. Ablation studies further confirm that combining interpolated flow matching with attention alignment significantly enhances correspondence learning, while utilizing additional input views consistently improves geometric recovery. Overall, the results demonstrate that integrating feature-space denoising with a feed-forward reconstructor yields a robust and accurate solution for recovering degraded multi-view environments.
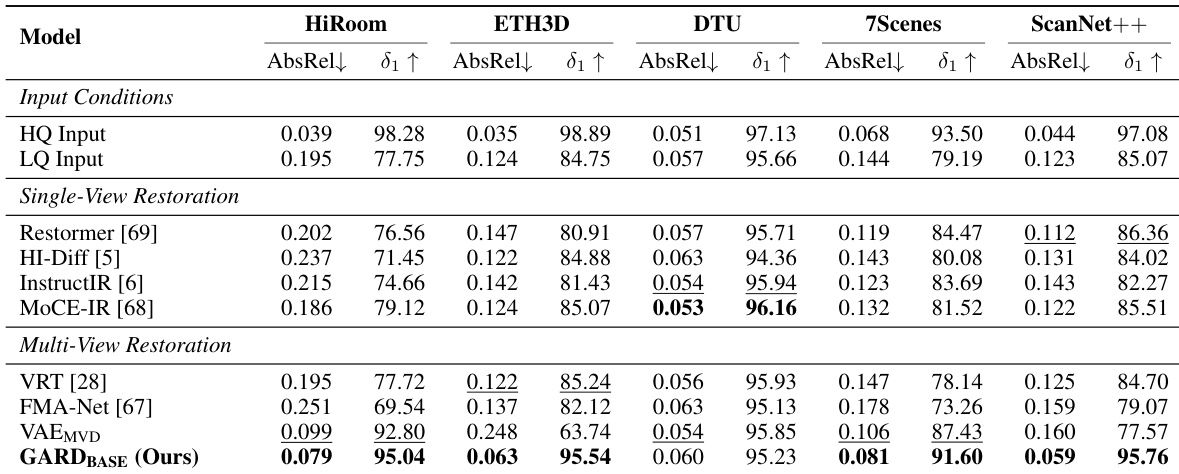
The authors evaluate their method against various restoration and reconstruction baselines under severe degradation conditions, focusing on camera pose estimation and 3D reconstruction performance. Results show that their approach outperforms both single-view and multi-view restoration methods, achieving higher accuracy in pose estimation and more consistent 3D reconstructions by operating within a geometry-aware feature space. The proposed method achieves superior camera pose estimation accuracy compared to single-view and multi-view restoration baselines under severe degradation. The approach outperforms existing methods in 3D reconstruction quality, producing more geometrically consistent and complete reconstructions. Increasing the number of input views consistently improves both pose estimation and reconstruction performance, indicating the benefit of richer multi-view information.
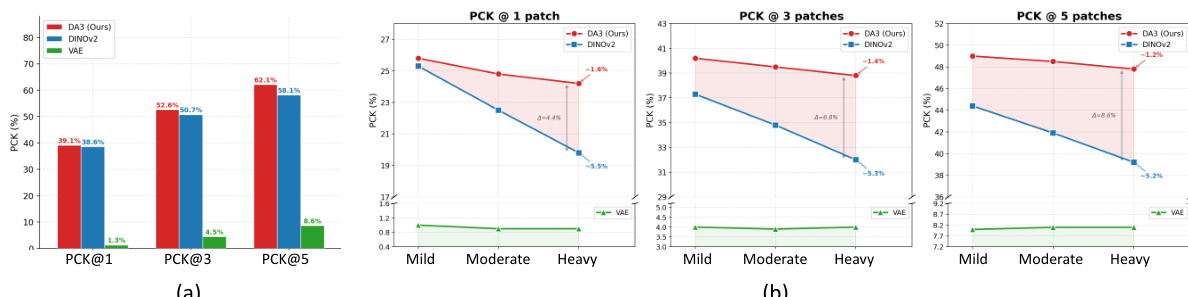
The authors compare their method against various single-view and multi-view restoration approaches for camera pose estimation under severe motion blur degradation. Results show that the proposed method outperforms all baselines across multiple benchmarks, achieving the highest accuracy in pose estimation and reconstruction by leveraging geometry-aware feature space denoising. The method demonstrates consistent improvements over single-view and multi-view restoration approaches, particularly in preserving structural fidelity and cross-view consistency. The proposed method achieves the best performance in camera pose estimation across all benchmarks compared to single-view and multi-view restoration baselines. The method outperforms existing multi-view restoration approaches by operating directly in a geometry-aware feature space, enhancing structural fidelity and cross-view consistency. Results indicate that increasing the number of input views improves both pose estimation and 3D reconstruction quality, highlighting the benefit of richer cross-view information.
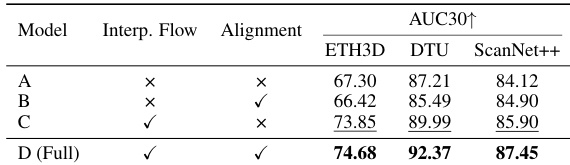
The authors conduct an ablation study on the GARD denoiser, evaluating the impact of its training components and the number of input views. Results show that combining interpolated flow matching with attention alignment leads to improved performance across different benchmarks, and increasing the number of input views consistently enhances both pose estimation and 3D reconstruction accuracy. Combining interpolated flow matching with attention alignment improves performance compared to using either component alone. Using more input views leads to better camera pose estimation and 3D reconstruction quality. The full GARD model configuration achieves the best results across all evaluated benchmarks.
The authors compare their proposed GARD method against single-view and multi-view restoration baselines in the context of camera pose estimation and 3D reconstruction under severe motion blur. Results show that GARD outperforms all baselines across multiple benchmarks, demonstrating superior performance in preserving geometric consistency and structural fidelity. The ablation studies further confirm the effectiveness of key components in the GARD framework and the benefit of using more input views. GARD achieves the best performance in camera pose estimation and 3D reconstruction across all benchmarks compared to single-view and multi-view restoration baselines. The proposed method outperforms existing multi-view restoration approaches, particularly in preserving geometric consistency and structural fidelity under severe degradation. Ablation studies indicate that using more input views improves both pose estimation and reconstruction quality, highlighting the benefit of richer cross-view information.
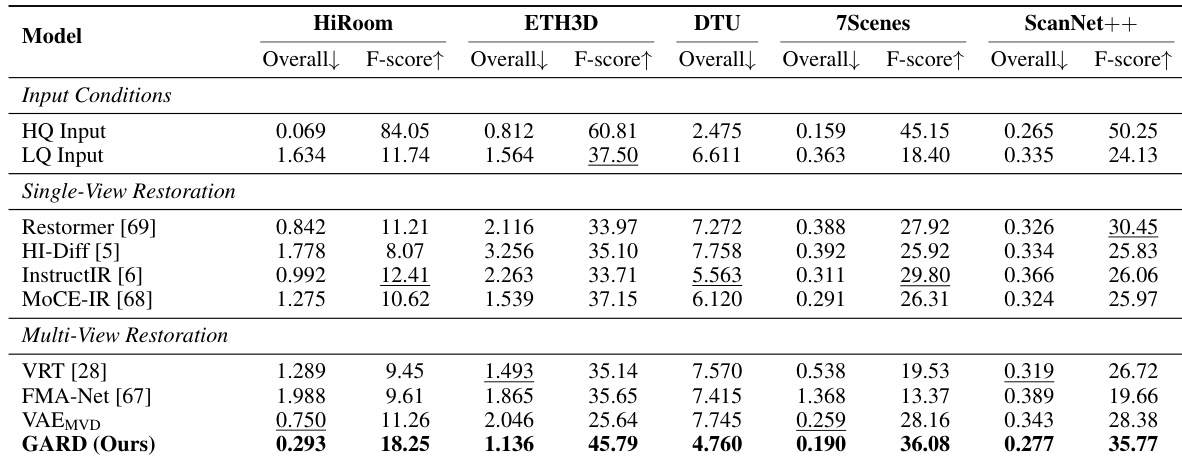
The authors evaluate their method against various single-view and multi-view restoration baselines on camera pose estimation tasks under severe degradation. Results show that the proposed approach outperforms all baselines across multiple benchmarks, with significant improvements in pose accuracy and reconstruction quality compared to single-view and VAE-based multi-view methods. The method achieves superior performance by operating within a geometry-aware feature space that preserves structural fidelity and cross-view consistency. The proposed method outperforms all single-view and multi-view restoration baselines in camera pose estimation across multiple benchmarks. The approach achieves better results than VAE-based multi-view restoration methods, which suffer from information loss in compressed latent spaces. Single-view restoration models show limited improvement due to their inability to leverage complementary information across multi-view inputs.
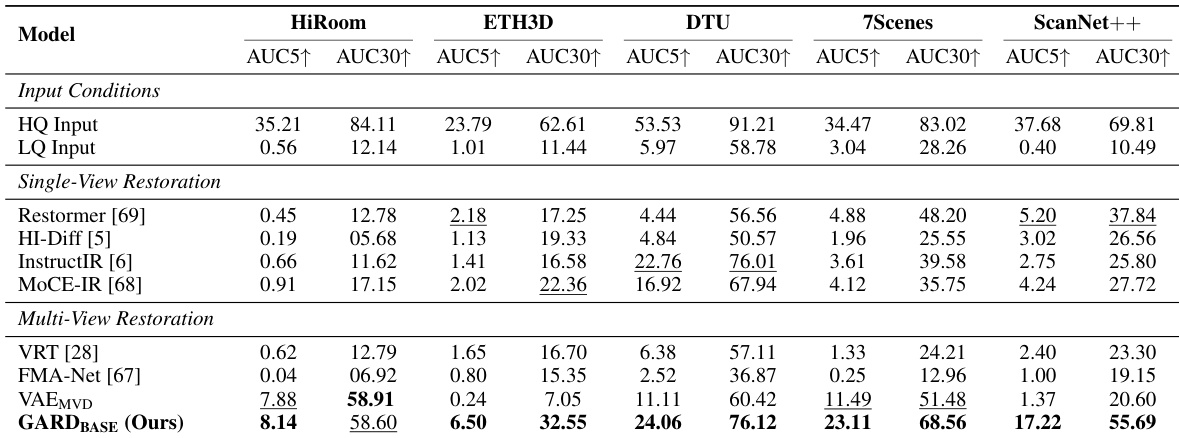
The authors evaluate their proposed method against single-view and multi-view restoration baselines for camera pose estimation and 3D reconstruction under severe motion blur degradation. The approach consistently outperforms existing techniques by operating within a geometry-aware feature space that preserves structural fidelity and cross-view consistency, while ablation studies confirm that combining interpolated flow matching with attention alignment yields optimal results. Furthermore, leveraging additional input views reliably enhances reconstruction quality, demonstrating that the method successfully overcomes the information loss limitations of VAE-based approaches and the inherent constraints of single-view models.