Command Palette
Search for a command to run...
minWM: リアルタイムインタラクティブビデオワールドモデルのためのフルスタックオープンソースフレームワーク
minWM: リアルタイムインタラクティブビデオワールドモデルのためのフルスタックオープンソースフレームワーク
概要
近年、ビデオ拡散ファウンデーションモデルは高品質なビデオ生成において顕著な進歩を遂げているが、それらをリアルタイムインタラクティブビデオワールドモデルに変換することは依然として課題が残っている。インタラクティブワールドモデルには、制御可能で因果的かつ低レイテンシーなロールアウトが必要であり、実際にはデータ構築、制御可能なファインチューニング、自己回帰学習、少ステップ蒸留、ストリーミング推論にわたるフルパイプラインが要求される。本研究では、リアルタイムインタラクティブビデオワールドモデルの構築のためのフルスタックオープンソースフレームワークであるminWMを紹介する。minWMは、既存の双方向T2V/TI2Vビデオファウンデーションモデルをカメラ制御可能な少ステップ自己回帰ワールドモデルに変換するエンドツーエンドパイプラインを提供する。具体的には、minWMはまずカメラ制御付きの双方向ビデオ拡散モデルをファインチューニングし、次にAR拡散学習、因果ODEまたは因果一貫性蒸留、非対称DMDを含むCausal Forcing / Causal Forcing++パイプラインを適用し、低レイテンシーロールアウト用の少ステップ自己回帰ジェネレーターへ蒸留する。本フレームワークはモジュール化可能かつアーキテクチャ拡張可能であり、Wan2.1-T2V-1.3BおよびHY1.5-TI2V-8Bを含む代表的なオープンバックボーンで実装し、クロスアテンションベースの条件注入とMMDiTスタイルアーキテクチャの両方をカバーしている。minWMは、HY-WorldPlayなどの既存のビデオワールドモデルを、新しいデータ分布、トレーニングレシピ、レイテンシー目標に適応させることもサポートする。実行可能スクリプト、チェックポイント、ドキュメント、推論コードの公開に加え、カメラ軌跡の品質、制御性トレーニングステップ、最小バッチサイズ要件に関する実用的なアブレーション分析を提供する。minWMがリアルタイムインタラクティブビデオワールドモデルの構築および適応のための再現可能かつ拡張可能なレシピとして機能することを期待する。プロジェクトページ: https://github.com/shengshu-ai/minWM
One-sentence Summary
minWM is a modular full-stack open-source framework that converts bidirectional video diffusion models into camera-controllable, few-step autoregressive world models via a pipeline combining camera-conditioned fine-tuning, causal forcing, causal consistency distillation, and asymmetric DMD to enable low-latency interactive generation on architectures such as Wan2.1-T2V-1.3B and HY1.5-TI2V-8B.
Key Contributions
- This work introduces minWM, a full-stack open-source framework that provides a modular, end-to-end pipeline for converting existing bidirectional text-to-video and text-and-image-to-video foundation models into camera-controllable autoregressive world models. The framework unifies data construction, controllable fine-tuning, autoregressive training, few-step distillation, and streaming inference into a reproducible workflow.
- The framework executes a two-phase conversion recipe that first fine-tunes a bidirectional diffusion backbone on camera-annotated data to enable trajectory control. It subsequently applies Causal Forcing or Causal Forcing++ pipelines, combining autoregressive diffusion training, causal ODE or consistency distillation, and asymmetric DMD post-training to distill the model into a few-step autoregressive generator for low-latency rollout.
- The pipeline is instantiated on Wan2.1-T2V-1.3B and HY1.5-TI2V-8B backbones to demonstrate real-time interactive video generation across cross-attention and MMDiT architectures. By releasing intermediate checkpoints for each training stage and providing ablation studies on camera trajectory quality and training configurations, the framework offers actionable guidance for reproducible world model development.
Introduction
High-quality diffusion-based video foundation models have significantly advanced visual generation, yet they function as offline generators rather than interactive world models. Real-time interactive applications demand causal rollout, responsive camera control, and low-latency frame synthesis, but existing conversion techniques remain scattered across disconnected pipelines that require extensive manual effort across data preparation, fine-tuning, autoregressive training, and distillation. To bridge this gap, the authors introduce minWM, a full-stack open-source framework that unifies the entire workflow into a single reproducible pipeline. The authors leverage a two-phase strategy that first fine-tunes bidirectional video backbones for camera controllability and then applies causal forcing alongside asymmetric distillation to convert them into few-step autoregressive generators. This modular architecture enables researchers to seamlessly adapt existing foundation models into real-time, camera-controlled video world models while supporting mid-pipeline checkpointing and customizable training configurations.
Method
The authors present minWM, a full-stack framework for constructing real-time interactive video world models, which operates through a two-phase pipeline. The overall architecture begins with data preparation, proceeds through a training phase that includes bidirectional diffusion fine-tuning and autoregressive distillation, and culminates in low-latency inference. The process starts with inputs comprising an image, text, and an action signal, which are processed through data filtering and rebalancing, followed by structured annotation to generate a dataset suitable for training. This dataset is then used to fine-tune a bidirectional diffusion model with camera controllability, leveraging PROPE as the injection method for camera parameters. The framework supports multiple backbones, including Wan2.1-T2V-1.3B and HY1.5-TI2V-8B, enabling the conversion of existing video foundation models into camera-controllable few-step autoregressive generators.
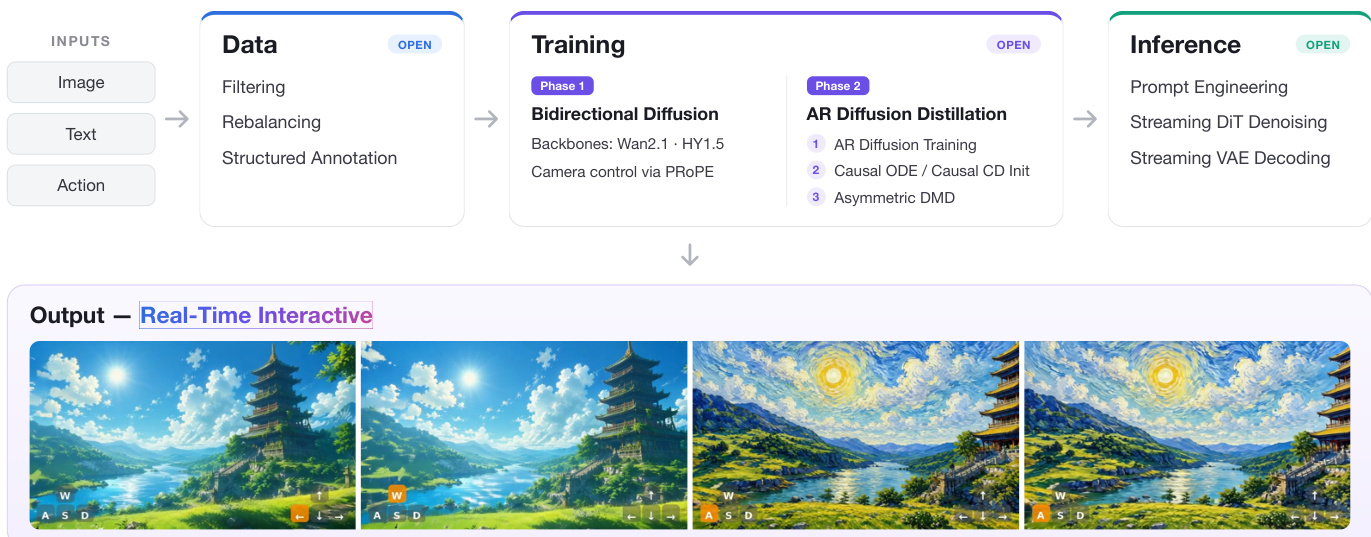
As shown in the figure below, the training phase is divided into two stages. Phase 1 involves bidirectional diffusion training on the fine-tuned model, where camera control is integrated via PROPE. This phase equips the model with the ability to condition on camera trajectories while maintaining the original self-attention structure. Phase 2, AR Diffusion Distillation, applies the Causal Forcing or Causal Forcing++ pipeline to transform the bidirectional model into a real-time interactive autoregressive model. This includes AR diffusion training, causal ODE or causal consistency distillation initialization, and asymmetric DMD post-training. The final stage, inference, enables streaming VAE decoding and prompt engineering, resulting in real-time interactive video outputs. The framework is modular and extensible, supporting the adaptation of existing models to new data distributions and latency targets.
Experiment
The evaluation trains two base video generation models using an autoregressive framework with few-step distillation to assess inference efficiency and camera control. Qualitative results demonstrate that the approach significantly reduces first-frame latency, enabling seamless playback during generation, while successfully preserving camera-controllable capabilities. Ablation studies further reveal that robust camera control depends on high-quality ground-truth trajectory data, sufficient training iterations, and a minimum batch size to ensure stable optimization.
The authors compare the first-frame latency and speedup of multi-step bidirectional and few-step autoregressive models based on two different base models. Results show that the few-step AR model significantly reduces first-frame latency and achieves substantial speedup over the multi-step bidirectional baseline, while maintaining camera-controllable generation capabilities. Few-step AR models achieve substantial reductions in first-frame latency compared to multi-step bidirectional models. The few-step AR model provides significant speedup over the multi-step bidirectional baseline for both base models. Camera-controllable generation is preserved in the few-step AR models despite the latency improvements.
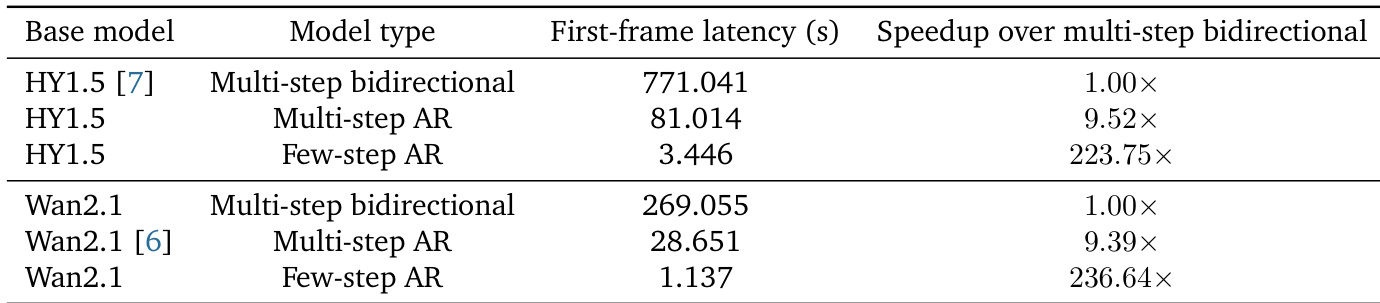
The evaluation compares the initial generation latency and processing speed of multi-step bidirectional models against few-step autoregressive architectures across two distinct base models. Results demonstrate that the few-step autoregressive approach substantially accelerates first-frame generation and overall inference efficiency. Importantly, these performance improvements are achieved while successfully preserving the models' camera-controllable generation capabilities.