Command Palette
Search for a command to run...
Agent探索的方策最適化のためのマルチモーダルエージェント推論
Agent探索的方策最適化のためのマルチモーダルエージェント推論
Minki Kang Shizhe Diao Ryo Hachiuma Sung Ju Hwang Pavlo Molchanov Yu-Chiang Frank Wang Byung-Kwan Lee
概要
拡張推論を備えたビジョン言語モデルは複雑な問題において成功を収めているが、多くの現実世界の問題は、内部推論のみでは解決できない外部ツールを必要とする。したがって、エージェント推論は構造的な非対称性を伴う2つの行動を交互に実行する。すなわち、思考(自己完結型のデフォルト行動)とツール使用(高分散の補助的行動)である。本研究では、この非対称性をThinking-Acting Gapと呼ぶ。GRPOなどの標準的な強化学習(RL)手法において、このギャップはトレーニング中に2つの診断的兆候として現れる。すなわち、ツール使用の試行はロールアウトの約30%でしか行われず、試行された場合でも、グループ内のツール使用ロールアウトは質問の約40%において全て誤答となっており、学習信号が最も必要とされるツール呼び出し箇所において学習信号が抑制されてしまう。本研究ではAXPO(Agent eXplorative Policy Optimization)を提案する。AXPOは、ツール使用において全て誤答となる部分グループごとに、思考プレフィックスを固定した状態でツール呼び出しとその後の継続生成を再サンプリングする。この手法は、不確実性に基づくプレフィックス選択と組み合わせて適用される。9つのマルチモーダルベンチマークおよびQwen3-VL-Thinkingの3つのスケール規模において、SFT+AXPOはSFT+GRPOを上回る性能を示した(8Bモデルにおいて平均でPass@1が+1.8pp、Pass@4が+1.8pp向上)。さらに、SFT+AXPOを適用した8Bモデルは、パラメータ数を4分の1に削減しながら、Pass@4において32B Baseモデルを上回る性能を達成した。
One-sentence Summary
AXPO (Agent eXplorative Policy Optimization) bridges the Thinking-Acting Gap in multimodal agentic reasoning by fixing thinking prefixes and resampling tool calls paired with uncertainty-based prefix selection, enabling an 8B Qwen3-VL-Thinking model trained with SFT + AXPO to outperform SFT + GRPO by an average of 1.8 percentage points on Pass@1 and Pass@4 across nine benchmarks and surpass a 32B base model on Pass@4 using four times fewer parameters.
Key Contributions
- AXPO (Agent eXplorative Policy Optimization) resolves the Thinking-Acting Gap in agentic vision-language models by identifying all-wrong tool-using subgroups and resampling their tool calls and continuations while freezing the preceding reasoning prefix.
- This mechanism operates directly at the tool-call boundary rather than after tool observation, which restores the suppressed learning signal that standard group-relative policy optimization typically misses during uniform sampling.
- Evaluations across nine multimodal benchmarks using Qwen3-VL-Thinking demonstrate that pairing supervised fine-tuning with AXPO increases average Pass@1 and Pass@4 scores by 1.8 percentage points at the 8B scale and enables an 8B model to surpass a 32B base model on Pass@4 using four times fewer parameters.
Introduction
Vision-language models with extended reasoning have made significant strides, yet real-world applications frequently require external tools for live data retrieval, complex computation, and fine-grained visual analysis. Multimodal agentic reasoning addresses this need by interleaving internal thought processes with tool execution, but standard post-training pipelines struggle with a structural asymmetry known as the Thinking-Acting Gap. Under conventional reinforcement learning methods like GRPO, tool calls remain rare and highly volatile, frequently causing entire rollout groups to fail and effectively erasing the learning signal exactly when the model needs to improve its acting behavior. To resolve this bottleneck, the authors leverage AXPO (Agent eXplorative Policy Optimization), a targeted framework that anchors successful thinking prefixes and resamples only the high-variance tool calls and their continuations when trajectories fail. By concentrating exploration precisely at the tool-call boundary and applying uncertainty-driven prefix selection, AXPO restores robust learning signals for acting, delivering substantial performance gains across multimodal benchmarks while outperforming significantly larger baseline models.
Dataset
• Dataset Composition and Sources: The authors construct their training corpus by aggregating trajectories from three established datasets: ViRL, fvqa, and PyVision-RL. Every initial trajectory is synthesized using the Qwen3-VL-32B-Thinking model as the teacher.
• Subset Details:
- Supervised Fine-Tuning collection: 64,274 trajectories in total. Roughly 25 percent incorporate at least one tool call, while the remaining 75 percent rely exclusively on internal reasoning. The authors apply a strict correctness filter, retaining only trajectories that produce the correct final answer against ground truth labels.
- Reinforcement Learning collection: Approximately 37,000 problems. This subset combines 15,591 questions filtered from the SFT pool with 22,000 additional hard questions sourced from MMFinetReason-hard. The authors remove SFT questions that the supervised checkpoint solves perfectly across four rollouts, as well as questions the teacher model fails on all four rollouts, effectively pruning trivial and unreachable tasks.
• Training Usage and Processing: The cleaned SFT trajectories form the initial training split. The authors then transition to reinforcement learning, where the policy generates up to three turns per problem with a group size of eight rollouts per question. Data is routed through the verl and rllm libraries to apply policy gradient updates, utilizing asymmetric clipping ranges and a fixed reference policy for KL regularization.
• Additional Processing Notes: The provided documentation does not outline specific image cropping methods or custom metadata schemas. Instead, the authors rely on trajectory length constraints, rollout-based sampling, and answer verification to structure and validate the training data.
Method
The authors present AXPO, a reinforcement learning algorithm designed to address the Thinking-Acting Gap in group-based agentic reasoning, where tool use is under-attempted and tool-using subgroups frequently fail entirely, leading to non-positive advantage on tool-call tokens. The framework builds upon the standard Group Relative Policy Optimization (GRPO) pipeline, which trains a vision-language model (VLM) policy πθ to generate sequences of thinking segments, tool calls, and observations, culminating in an answer. In GRPO, a batch of N rollouts is sampled per input, and rewards are normalized within the group to compute advantages, which are then used to update the policy via a PPO-clip surrogate.
The core innovation of AXPO is tool-call resampling, which targets the under-trained behavior of tool use by concentrating exploration on the continuation after a confirmed tool call. This is achieved by fixing a thinking prefix t1src that has already crossed the tool call boundary, ensuring that all subsequent continuations are tool-using by construction. From this fixed prefix, K continuations are drawn from the policy πθ(⋅∣x,t1src), executed, and rolled forward. Each resampled trajectory shares the same prefix as the source rollout, thereby concentrating stochasticity on the tool call and its immediate aftermath. This approach provably dominates standard sampling at recovering correct tool-using rollouts, as it eliminates the waste of sampling on non-tool rollouts, a key limitation of scaling N in GRPO.
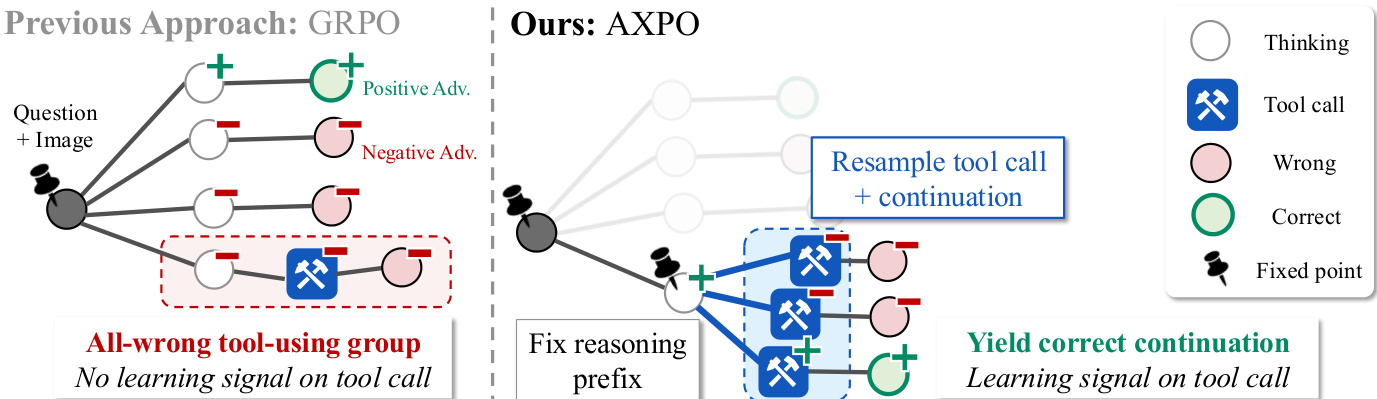
As shown in the figure below, AXPO operates only on groups where the tool-using subgroup is non-empty and entirely incorrect, identified as the primary source of non-positive advantage. This ensures that resampling is applied where it delivers the maximum gradient lift. To manage computational cost, AXPO caps the extra resampling budget at r⋅BN per step, with r=0.25 in practice, and allocates resources breadth-first across all triggered questions. Within these groups, candidate prefixes are ranked by their uncertainty, measured as the mean policy probability assigned to the tool-call tokens in the source rollout. This confidence proxy, which is a tractable alternative to predictive entropy, allows AXPO to prioritize resampling the most uncertain prefixes first, as they are more likely to contain a correct continuation.
The advantage calculation in AXPO is designed to avoid gradient conflicts arising from shared prefixes. For each selected prefix, the K resampled continuations form an independent advantage group, and their per-token advantages A^kres are computed based on their group-normalized rewards. These advantages are applied only to the continuation tokens, with the prefix tokens masked. The source trajectory's prefix tokens are updated using a separate recovery reward rprefix, which is 1 if at least one resampled continuation is correct, and 0 otherwise. This recovery reward replaces the original source rollout's reward in the group's normalization, yielding a per-prefix advantage A^prefix that is applied to the prefix tokens. This mechanism ensures that the prefix is credited positively whenever resampling succeeds, converting the coverage gain into a reinforcing gradient signal. The final AXPO loss for a selected prefix combines the clipped surrogate losses for both the source prefix and the resampled continuations.
Experiment
The evaluation employs Qwen3-VL models across nine multimodal benchmarks to assess agentic tool use in reasoning, perception, and search tasks. Main experiments validate that AXPO bridges the thinking-acting gap by dynamically resampling tool calls during reinforcement learning, which sustains tool adoption and recovers correct trajectories from initially failed reasoning prefixes. Ablations and comparative analyses confirm that these improvements stem from strategic compute allocation and precise advantage calculation rather than increased rollout budgets or reward shaping. Ultimately, the methodology enables smaller models to match or exceed larger baselines by simultaneously expanding the policy's reachable correct trajectories and enhancing conditional tool-use reliability.
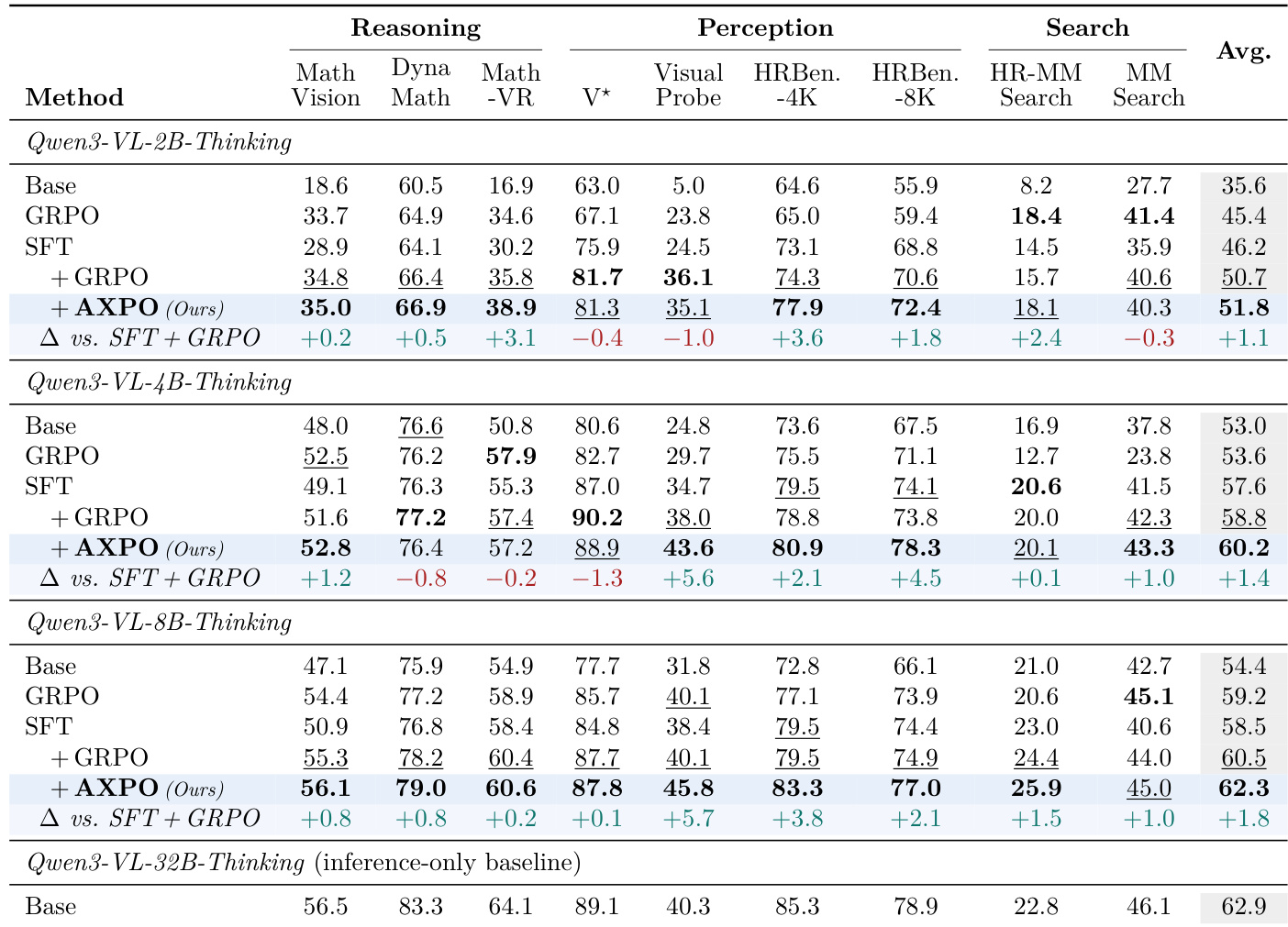
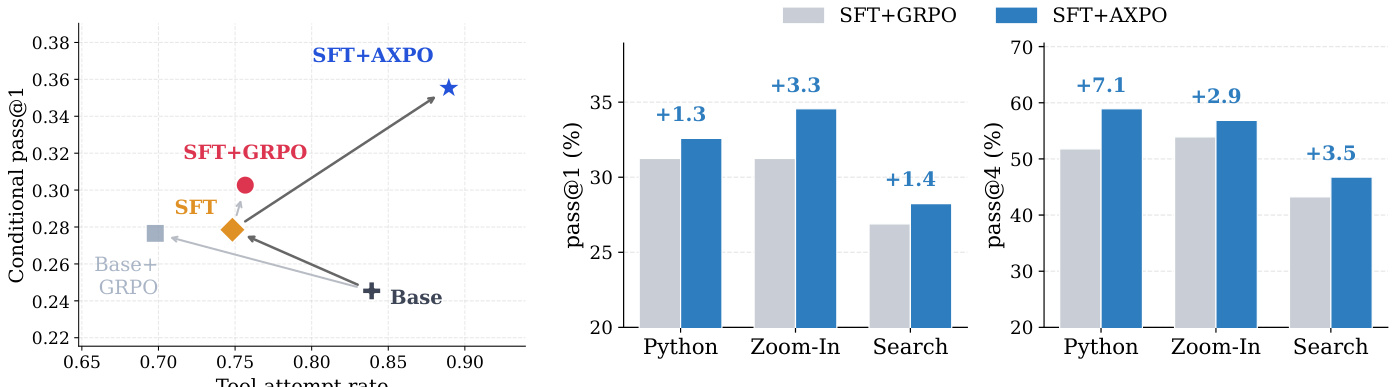
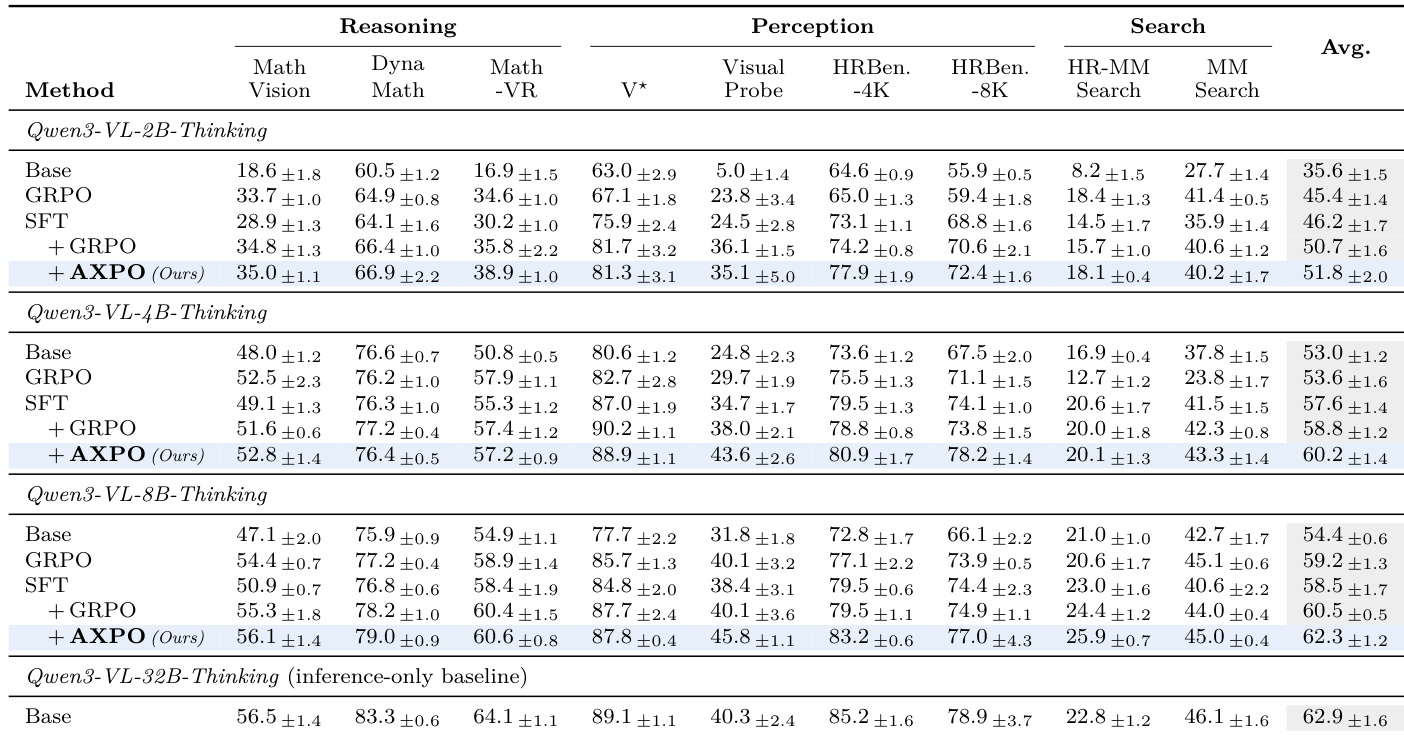
The authors evaluate the performance of their AXPO method against several baselines across multiple model sizes and benchmarks, focusing on multimodal reasoning, perception, and search tasks. Results show that AXPO consistently improves over SFT + GRPO, particularly in perception tasks, and achieves gains in both tool-use frequency and correctness. The method effectively addresses the thinking-acting gap by increasing tool utilization and reducing the frequency of all-wrong tool-using subgroups during training. AXPO improves over SFT + GRPO across all model sizes, with the largest gains in perception tasks and on Pass@4 metrics. AXPO increases tool-use frequency and reduces the all-wrong rate in tool-using subgroups, indicating better learning signal on tool calls. The method outperforms alternative RL recipes and ablation studies show that all components of AXPO are necessary for its performance gains.
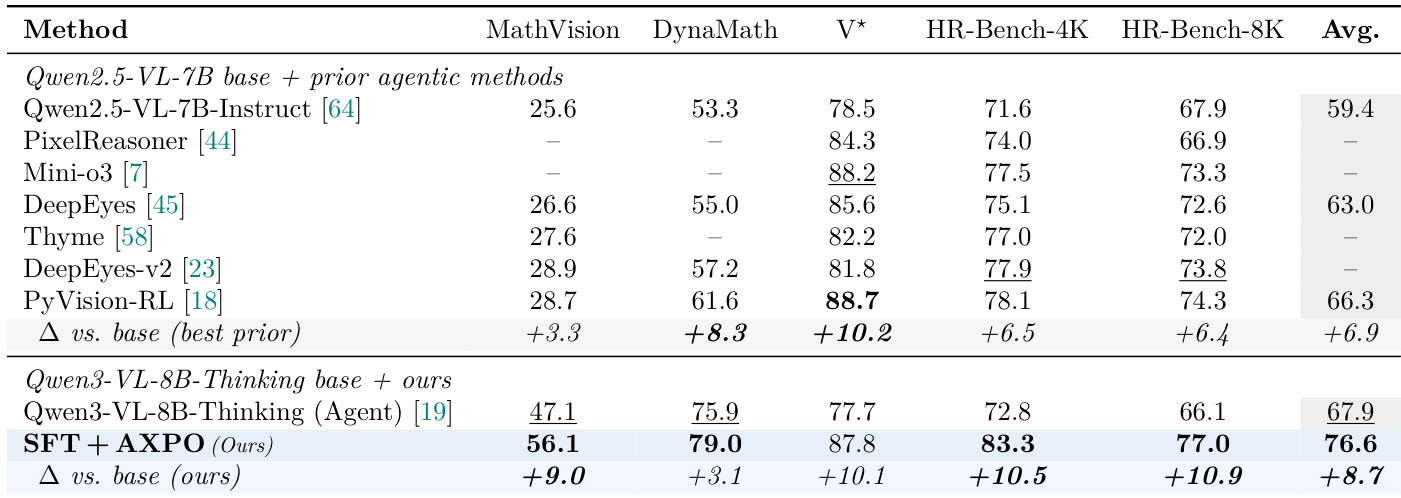
The authors compare their proposed AXPO method against prior agentic VLM systems on five benchmarks, showing that AXPO achieves higher performance on four of the five benchmarks and on the average across all five. The results indicate that AXPO outperforms previous methods, particularly on math-over-image tasks, and delivers a larger improvement over its base model compared to prior methods over their respective bases. AXPO outperforms prior agentic VLM systems on four of five benchmarks and on the average across all five. AXPO achieves a larger improvement over its base model compared to prior methods over their bases. AXPO performs particularly well on math-over-image benchmarks, where prior methods have less investment.
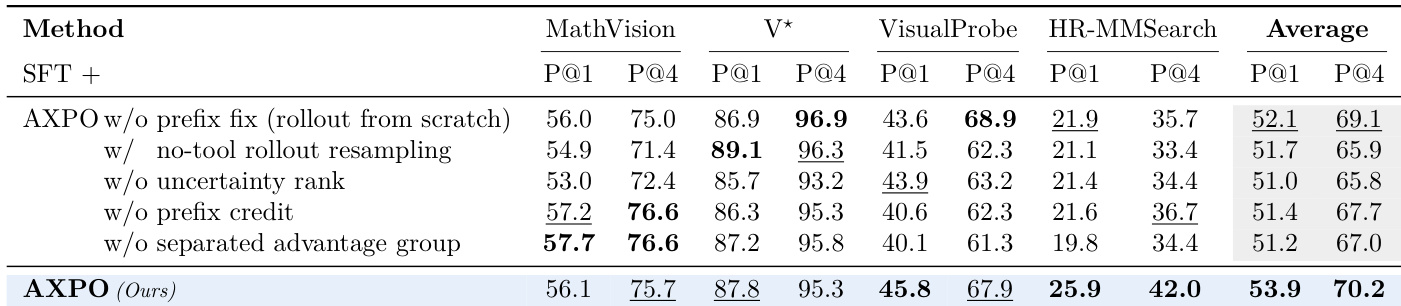
The authors conduct an ablation study to evaluate the impact of individual components in the AXPO method on model performance across multiple benchmarks. Results show that removing any of the key design elements—prefix fixing, uncertainty-based prefix selection, prefix credit, or separate advantage grouping—leads to a consistent drop in performance, indicating that each component contributes to the overall effectiveness of the method. The full AXPO method achieves the highest scores across all evaluated metrics, demonstrating that the integration of these components is essential for optimal performance. Removing any component of AXPO leads to a measurable decrease in performance across all benchmarks. The full AXPO method outperforms all ablated versions, highlighting the importance of its integrated design. Each ablated version shows lower scores compared to the complete method, indicating that all components are necessary for optimal results.
The authors compare SFT+AXPO against SFT+GRPO and other baselines across multiple benchmarks, showing that AXPO improves both tool-use frequency and the quality of tool-using trajectories. Results show that AXPO consistently outperforms SFT+GRPO in Pass@1 and Pass@4 across all model sizes, with gains concentrated in perception tasks where tool use is critical. The method narrows the thinking-acting gap by increasing tool use and reducing the frequency of all-wrong tool-using subgroups during training. AXPO improves both tool-use frequency and the quality of tool-using trajectories compared to SFT+GRPO. AXPO achieves higher Pass@1 and Pass@4 scores across all model sizes, with gains most pronounced in perception tasks. AXPO reduces the all-wrong rate among tool-using subgroups and increases tool-use rate during training, reversing the symptoms of the thinking-acting gap.
{"summary": "The authors evaluate a method called AXPO, which enhances reinforcement learning in agentic reasoning by resampling tool calls to address the Thinking-Acting Gap. Results show that AXPO improves performance across multiple benchmarks, particularly in Perception tasks, by increasing tool-use frequency and correcting failures in tool-using subgroups. The method outperforms baselines and alternative training recipes, with gains driven by better coverage of under-explored tool-call trajectories.", "highlights": ["AXPO increases tool-use frequency and corrects failures in tool-using subgroups during training, leading to improved performance across benchmarks.", "AXPO outperforms SFT + GRPO and alternative RL recipes, with gains concentrated in Perception tasks where tool use is critical.", "Ablation studies confirm that all components of AXPO contribute to performance, particularly resampling at tool-call boundaries and advantage grouping."]
The authors evaluate AXPO against supervised fine-tuning with reinforcement learning and prior agentic vision-language models across multiple model sizes and benchmarks spanning multimodal reasoning, perception, and search tasks. The experiments validate that AXPO effectively bridges the thinking-acting gap by increasing meaningful tool utilization and correcting failure patterns in agent trajectories. Comparative results consistently demonstrate superior performance over existing methods, with particularly strong qualitative gains in perception and math-over-image domains. Ablation studies further confirm that every design component is essential, as removing any element leads to consistent performance degradation across all evaluated tasks.