Command Palette
Search for a command to run...
ガンマ・ワールド:2人プレイヤーを超えた生成型Multi-Agent世界モデル構築
ガンマ・ワールド:2人プレイヤーを超えた生成型Multi-Agent世界モデル構築
Fangfu Liu Kai He Tianchang Shen Tianshi Cao Sanja Fidler Yueqi Duan Jun Gao Igor Gilitschenski Zian Wang Xuanchi Ren
概要
インタラクティブな動画生成のためのワールドモデルは、単一の制御信号から将来の観測値を生成するシングルagent設定に主に焦点を当ててきた。しかし、多くの生成環境ではマルチagent間の相互作用が必要であり、複数のプレイヤー、ロボット、またはembodied agentsが共有空間内で同時に行動する。このような設定にワールドモデルをスケールさせるには、原理的なマルチagent設計が必要である。agentsは独立して制御可能であり続け、置換対称性を持ち、時間的および視点的な一貫性を維持しつつ、効率的な推論をサポートするべきである。本論文では、インタラクティブなシミュレーション用の生成型マルチagentワールドモデルを提示する。本モデルはSimplex Rotary Agent Encodingを導入する。これは3D RoPEのパラメータフリーな拡張であり、agentsを回転角空間における正単体の頂点として表現する。これにより、各agentに固有の位相が与えられつつ、すべてのagentsが置換等価となり、スロットごとの識別子を学習したり固定されたagent順序を必要としたりすることなく、スケーラブルなagent identityを実現する。agents間での密なall-to-all attentionを回避するため、さらにSparse Hub Attentionを提案する。これは、学習可能なhub tokensがagents間でのtoken相互作用を仲介し、agents数に対するcross-agent attentionのコストを二次から線形に削減するものである。リアルタイムロールアウトのため、フルコンテキストの拡散教師モデルを因果的学生モデルに蒸留し、KVキャッシングを用いて時間ブロックを逐次生成させることで、24 FPSでの行動応答型生成を可能にする。マルチプレイヤー仮想環境における実験により、本モデルがスロットベースおよび密アテンションのベースラインと比較して、動画の忠実度、行動制御性、およびinter-agent consistencyを向上させ、追加学習なしで2人から4人のプレイヤーへ汎化できることが示された。
One-sentence Summary
Gamma-World is a generative multi-agent world model that employs Simplex Rotary Agent Encoding to establish permutation-symmetric identities and Sparse Hub Attention to reduce cross-agent computational complexity from quadratic to linear, enabling real-time, action-responsive video generation that enhances fidelity, controllability, and inter-agent consistency across two to four players without additional training.
Key Contributions
- Introduces γ-World, a generative multi-agent world model featuring Simplex Rotary Agent Encoding. This parameter-free extension of 3D RoPE maps agents to the vertices of a regular simplex in rotary angle space to preserve permutation symmetry while assigning distinct phases without fixed orderings or learned per-slot identities.
- Proposes Sparse Hub Attention, a cross-agent communication mechanism that routes interactions through learnable hub tokens. This architecture reduces the computational complexity of cross-agent attention from quadratic to linear relative to the number of agents.
- Evaluates γ-World in multiplayer virtual environments to demonstrate improved video fidelity, action controllability, and inter-agent consistency over slot-based and dense-attention baselines. The framework distills a full-context diffusion teacher into a causal student with KV caching to enable real-time, action-responsive generation at 24 FPS and generalizes from two to four players without additional training.
Introduction
The authors address the growing need for controllable multi-agent world modeling, which is essential for realistic multiplayer game generation, interactive simulation, and embodied AI. Prior video world models largely remain single-agent systems, and existing multi-agent approaches struggle with scalability and structural symmetry. They rely on dense joint attention that incurs quadratic computational costs as agent count increases, and they use learned identity embeddings that break permutation symmetry and lock the model to fixed player rosters. To overcome these bottlenecks, the authors introduce γ-World, a scalable generative framework that enables interactive multi-agent simulation. They leverage Simplex Rotary Agent Encoding, a parameter-free method that positions agents at equal distances in rotary angle space to preserve permutation symmetry while maintaining distinct identities. They also implement Sparse Hub Attention, which routes cross-agent communication through learnable hub tokens to reduce computational complexity from quadratic to linear. By distilling a bidirectional teacher into a causal student with KV caching, the authors enable real-time 24-FPS autoregressive rollouts and demonstrate seamless scaling from two to four players without additional training.
Dataset
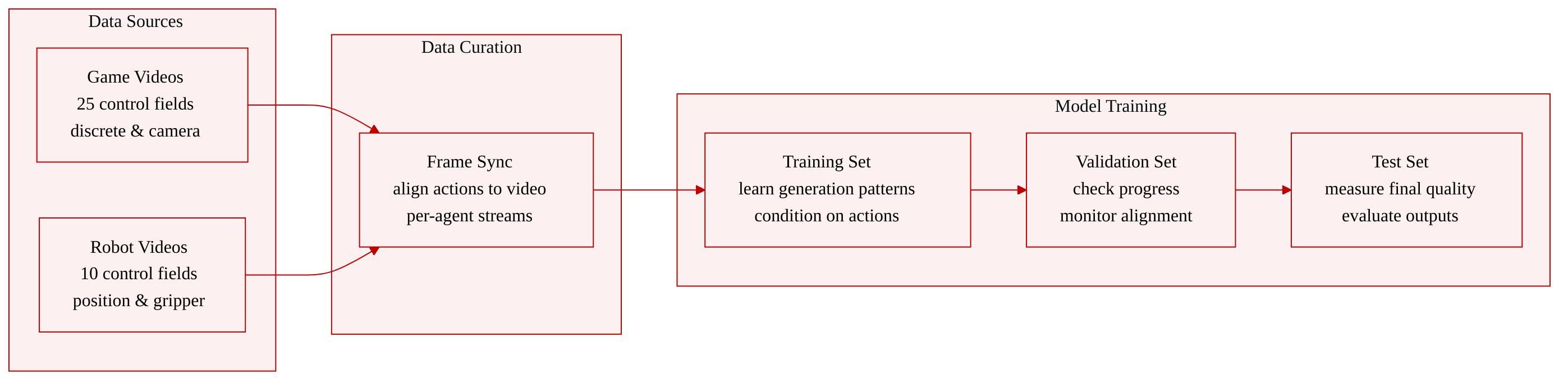
- Dataset Composition and Sources: The authors build a paired video and action dataset spanning two domains: Minecraft-style game environments and robotic manipulation tasks. Each sample aligns video footage with explicit per-agent action traces.
- Subset Details and Action Formats: The game subset stores 25-field action vectors per frame, containing 23 discrete player controls for inventory, hotbar selection, movement, item manipulation, and mouse interactions, plus 2 continuous fields for horizontal and vertical camera motion. The robot subset uses 10-field continuous vectors per frame, recording 3D end-effector position, 6D orientation, and gripper opening values. Both left and right robotic agents share this format, producing one temporally aligned sequence per robot.
- Model Usage and Training Integration: The authors treat these action traces as explicit conditioning signals during model training. Actions are synchronized frame-by-frame with the video data and supplied as independent per-agent streams to guide generation.
- Additional Processing Details: The provided excerpt does not specify dataset size, filtering rules, training splits, mixture ratios, cropping strategies, or metadata construction. The documentation focuses exclusively on action vector formatting and temporal alignment with video frames.
Method
The authors leverage a transformer-based latent video diffusion framework adapted for autoregressive generation, building on the DiT architecture. The model processes synchronized multi-agent inputs, where observations and actions from P agents are tokenized and encoded into a shared latent space. The input representation is structured as Z0∈RP×T×H×W×Cz, extending the single-agent latent with an explicit agent axis. During training, the model is conditioned on initial observations and per-agent action sequences to predict future latent observations for all agents jointly, ensuring consistency across time and agent perspectives. At inference, the first observations are encoded as context, while future latent tokens are initialized from noise and denoised block by block under the per-agent action sequences.
Action conditioning is implemented using a shared action encoder fa that maps each agent's action sequence a1:Tp to a hidden action feature utp∈RD. This feature is projected to a layer-specific action bias βItp and broadcast to all spatial tokens of the corresponding agent and frame, allowing the model to incorporate action information without breaking permutation symmetry. The model further enhances this by modifying the 3D rotary position embedding (RoPE) to account for agent identities, introducing a 4D rotary operator R4D(t,p,h,w) that includes an agent axis p.
To address the challenge of agent identity representation without imposing a fixed ordering, the authors propose Simplex Rotary Agent Encoding. This method represents agents as vertices of a regular simplex in the rotary angle space, ensuring that all agents are equidistant and exchangeable. For a batch with P≤V active agents, an injective assignment π maps agents to vertices from a fixed simplex pool of size V. The agent-band rotation angles are defined as θp=αsπ(p), where sπ(p) is the selected simplex vertex. This encoding is parameter-free, permutation-symmetric, and supports scaling to more agents by selecting additional unused vertices from the same pool. 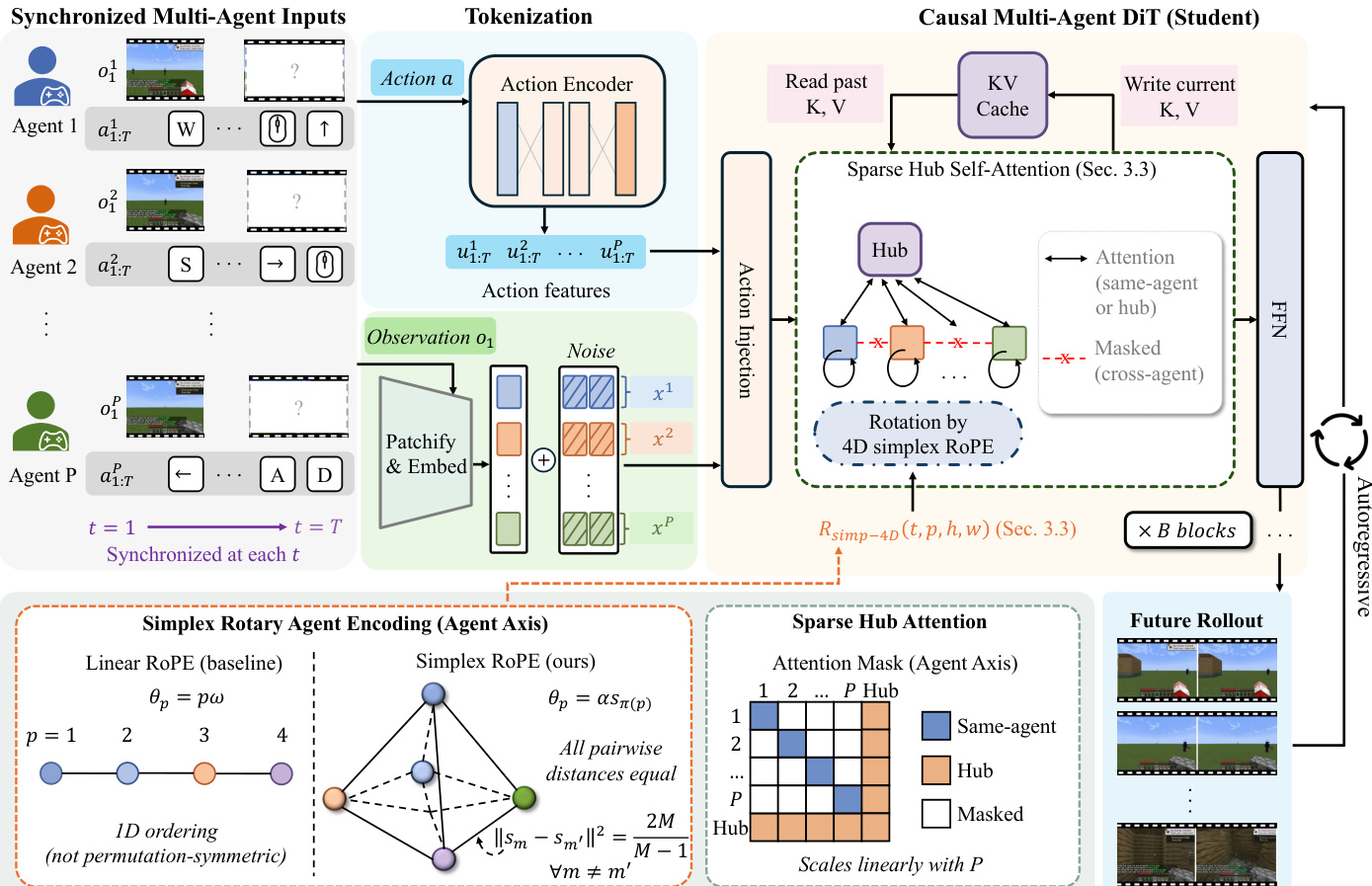
To reduce computational cost associated with dense cross-agent attention, the authors introduce Sparse Hub Attention (SHA). This mechanism uses a small set of learnable hub tokens to mediate information flow between agents. Agent tokens attend only to tokens from the same agent stream and to the hub tokens, while hub tokens attend to all agents and to other hub tokens. Direct attention between distinct agent streams is masked, enforcing a two-hop communication path: agent → hub → agent. The sequence is organized as PTL agent tokens followed by TK hub tokens, with K hub tokens per latent frame. The hub-and-spoke topology is defined by the mask Mhub(i,j)=1[ρ(i)=ρ(j)∨ρ(i)=hub∨ρ(j)=hub], where ρ(i) denotes the identity of token i. For causal autoregressive generation, this topology is composed with a block-causal mask M(i,j)=1[b(j)≤b(i)]⋅Mhub(i,j), where b(i) is the temporal block index of token i. This reduces the per-block attention cost from O(P2n2L2) to O(PnL(nL+nK))+O(nK(PnL+nK)), which is linear in P for fixed block size n, spatial length L, and number of hub tokens K.
The training process is conducted in three stages to support real-time rollout. First, a bidirectional teacher model is trained for high-quality conditional denoising, exploiting full temporal and cross-agent visibility. Second, a causal student model is trained using the Diffusion Forcing formulation, combining block-causal attention with the Sparse Hub Attention mask. This causal student is trained as a full multi-step diffusion model, providing a stable starting point for distillation. Finally, a conditional Self-Forcing distillation process is applied, where the multi-step causal student is distilled into a few-step generator. The distillation uses distribution matching distillation (DMD) with rollout-aware training, encouraging the few-step student to preserve quality over its own generated histories. The model is trained with conditional distillation, ensuring that the initial observation and action controls are preserved. At inference time, the distilled student generates one temporal block at a time, conditioned on the initial observations and the latest per-agent action block, streaming the rollout at 24 FPS. KV caches are maintained for each agent stream and a shared cache for hub tokens to preserve the Sparse Hub Attention topology during streaming.
Experiment
Evaluated across synchronized multi-agent Minecraft scenarios and real-world bimanual robotics tasks, the experiments validate that representing agents as distinct yet exchangeable entities coupled through a shared communication hub significantly improves cross-view consistency and generation fidelity over existing baselines. Qualitative demonstrations confirm the model maintains synchronized interactions, robust object grounding, and coordinated dynamics when scaling from two to four agents without architectural modifications. Efficiency analyses further verify that the sparse hub attention mechanism drastically reduces computational overhead as agent counts grow, enabling practical real-time inference. Ultimately, the framework successfully generalizes coupled multi-agent dynamics from virtual simulations to physical environments, establishing a scalable foundation for interactive world modeling.
The authors conduct an ablation study to evaluate the impact of different architectural choices in their multi-agent world model, focusing on input organization, agent identity encoding, and cross-agent interaction. Results show that combining sequence-based input organization, simplex agent encoding, and sparse hub attention leads to the best performance across multiple quality metrics. The full model achieves the lowest values for FVD, FID, and LPIPS, indicating improved visual quality and consistency, while also achieving higher PSNR and SSIM, suggesting better perceptual and pixel-level fidelity. The full model with sequence concatenation, simplex agent encoding, and sparse hub attention outperforms all other architectural variants in visual quality and consistency. Simplex rotary agent encoding improves over learned view embeddings by enabling distinct yet exchangeable agent identities. Sparse hub attention reduces computation and latency as the number of agents increases, enabling efficient multi-agent interaction.

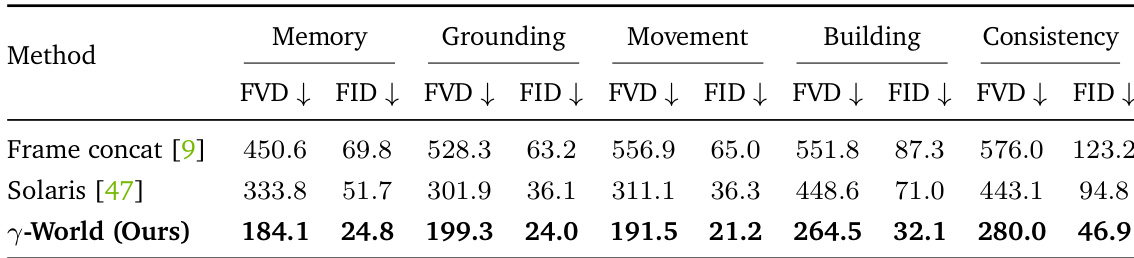
The authors compare their method, γ-World, against two baselines in multi-agent world modeling, evaluating performance across several tasks including memory, grounding, movement, building, and consistency. Results show that γ-World outperforms the baselines in all categories, demonstrating improved visual quality and inter-agent consistency. The framework's design, which treats agents as distinct yet exchangeable entities and uses an efficient shared interaction pathway, contributes to its superior performance and scalability. γ-World achieves better performance than baselines across multiple evaluation tasks, including memory, grounding, movement, building, and consistency. The method outperforms frame concatenation and Solaris, indicating the effectiveness of its approach to agent identity encoding and sparse cross-agent interaction. Results show that γ-World maintains strong visual quality and consistency, particularly in scenarios requiring memory and cross-view coherence.
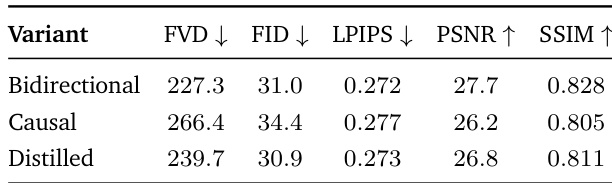
The authors present an ablation study comparing different training stages of their model, including a bidirectional teacher, a causal student, and a distilled variant. The results show that the bidirectional teacher achieves the best performance across multiple metrics, while the distilled model recovers much of the teacher's quality while maintaining a causal structure suitable for streaming inference. The causal variant exhibits degraded performance due to limited temporal context. The bidirectional teacher achieves the best performance across all evaluation metrics. The distilled model recovers most of the bidirectional teacher's quality while supporting streaming inference. The causal variant shows degraded performance due to limited access to future context.
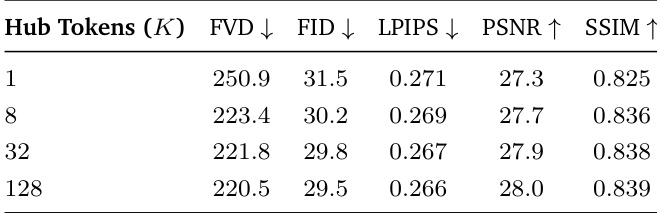
{"summary": "The authors conduct an ablation study to evaluate the impact of the number of hub tokens in Sparse Hub Attention on generation quality. Results show that increasing the number of hub tokens leads to improvements in most metrics, indicating that a larger hub capacity enhances the model's ability to summarize and communicate multi-agent interactions. However, the gains diminish at higher hub token counts, suggesting a trade-off between communication capacity and efficiency.", "highlights": ["Increasing the number of hub tokens improves generation quality across multiple metrics, with diminishing returns at higher counts.", "A larger hub capacity enables better summarization of multi-agent interactions, leading to higher perceptual and pixel-level quality.", "The study demonstrates that hub token count is a critical design parameter for balancing communication capacity and model efficiency."]
The authors evaluate their multi-agent world model through a series of ablation studies and comparative benchmarks to assess architectural design, training strategies, and hyperparameter configurations. Results demonstrate that combining sequence-based input organization, simplex agent encoding, and sparse hub attention optimizes visual quality and cross-agent consistency, significantly outperforming established baselines across diverse simulation tasks. Training stage comparisons further reveal that while a bidirectional teacher achieves peak performance, a distilled variant successfully preserves this quality while enabling efficient streaming inference. Finally, analysis of the attention mechanism highlights a clear trade-off between communication capacity and computational efficiency, collectively validating the framework's robust and scalable design.