Command Palette
Search for a command to run...
D^2-Monitor:Diffusion LLMs に対する動的安全性監視 ~躊躇認識型ルーティングによる~
D^2-Monitor:Diffusion LLMs に対する動的安全性監視 ~躊躇認識型ルーティングによる~
Aoxi Liu Yupeng Chen James Oldfield Guanzhe Hong Junchi Yu Baoyuan Wu Philip Torr Adel Bibi
概要
拡散大規模言語モデル(D-LLMs)が自己回帰型大規模言語モデル(AR-LLMs)の代替手段として台頭する一方で、D-LLMsの安全性モニタリングは依然としてほとんど研究されていない。AR-LLMsとは異なり、D-LLMsは多段階のノイズ除去プロセスを通じてテキストを生成するため、標準的な単一ステップのモニタリング設定では利用できない安全性に関連する情報を含む可能性のある中間の隠れ表現が露出する。軽量プローブが常時モニタリングに適しているという動機付けのもと、これらのプローブが困難に直面する可能性を最もよく示す軌道レベルのシグナルは何かを分析する。最も情報量の多いシグナルはsafety hesitationであることがわかった。これは、中間の隠れ状態がプローブの決定境界の小さなマージン内に繰り返し位置する現象を指す。D-LLMの軌道におけるこのような躊躇ステップの数はプローブの失敗を効果的に予測し、サンプルの難易度の代理指標を提供する。この分析に基づき、D-LLMs向けの二層安全性モニタリングであるD^2-Monitorを提案する。D^2-Monitorは、躊躇の推定とベース分類を同時に実行するために、軽量プローブを常時モニタリングとして採用している。躊躇レベルが閾値を超えると、より表現力はあるが計算コストの高いプローブが起動される。この動的ルーティング機構により、テスト時にモニタリングリソースが効率的に割り当てられる。4つのD-LLMsにおいて3つのデータセット(WildguardMix, ToxicChat, OpenAI-Moderation)で評価した結果、D^2-Monitorはコンパクトなパラメータ規模(leq 0.85M parameters)で最先端の性能を達成し、8つのベースラインと比較して有効性と効率性の最適なトレードオフを示している。
One-sentence Summary
D2-Monitor dynamically monitors safety in diffusion large language models by tracking intermediate trajectory states that repeatedly approach a lightweight probe’s decision boundary and routing them to a heavier probe only when hesitation exceeds a threshold, achieving state-of-the-art performance across three datasets and four models with a compact footprint of ≤ 0.85 million parameters while delivering the best effectiveness-efficiency trade-off against eight baselines.
Key Contributions
- The analysis identifies safety hesitation as a trajectory-level phenomenon where intermediate hidden states repeatedly fall near a probe's decision boundary, demonstrating that hesitation severity strongly correlates with monitoring failure and serves as a reliable proxy for sample difficulty.
- Building on this analysis, D2-Monitor is introduced as a bi-level safety framework that continuously employs a lightweight probe while dynamically routing high-hesitation samples to a computationally heavier secondary classifier. The system additionally leverages hesitation trajectories to curate targeted training data for optimizing the advanced monitoring stage.
- Evaluations on the WildguardMix, ToxicChat, and OpenAI-Moderation datasets across four diffusion language models demonstrate state-of-the-art detection accuracy in both intra-dataset and cross-dataset settings. Operating with a compact footprint of under 0.85 million parameters, the framework delivers the most favorable balance between safety effectiveness and computational efficiency against eight established baselines.
Introduction
Diffusion large language models (D-LLMs) are rapidly emerging as highly efficient alternatives to autoregressive architectures due to their parallel decoding capabilities, yet ensuring their safe deployment remains a critical application challenge. Prior safety monitoring research largely targets autoregressive models and relies on either computationally heavy external LLMs or static lightweight probes that fail to account for the multi-step denoising trajectories inherent to diffusion generation. To bridge this gap, the authors identify safety hesitation as a robust trajectory-level signal that reliably predicts when a lightweight probe will struggle with complex or adversarial inputs. They leverage this mechanistic insight to introduce D2-Monitor, a dynamic bi-level safety system that continuously tracks intermediate hidden states and routes uncertain samples to a more expressive classifier only when necessary. This design achieves state-of-the-art detection performance while maintaining a minimal parameter footprint and delivering an optimal balance between monitoring accuracy and computational efficiency.
Dataset

-
Dataset composition and sources: The authors evaluate their safety monitoring approach using three public benchmarks: WildGuardMix, ToxicChat, and OpenAI-Moderation. These sources cover adversarial inputs, real-world conversational interactions, and standardized content moderation categories.
-
Key details for each subset:
- WildGuardMix: 86.8k training and 1.7k test prompts labeled as harmful or unhelpful. Released under the ODC-BY license.
- ToxicChat: 5.08k training and 5.08k test prompts collected from actual user-AI interactions, annotated with a binary toxicity label (1 for toxic, 0 otherwise). Released under CC-BY-NC-4.0 for non-commercial research only.
- OpenAI-Moderation: 1.68k prompts annotated across eight risk categories. Prompts are marked unsafe if any category is flagged and safe otherwise. Released under the MIT license.
-
Usage and training splits: The authors apply the data in two evaluation protocols. For intra-dataset testing, they train and evaluate probes separately on WildGuardMix and ToxicChat. For cross-dataset generalization, they train exclusively on WildGuardMix and test the resulting probes on both ToxicChat and OpenAI-Moderation. The datasets are used directly to train lightweight safety probes without any specified mixture ratios or sampling strategies.
-
Processing and metadata construction: The authors utilize the datasets as provided, relying on the original prompt texts and pre-assigned safety labels. No cropping, text truncation, or custom metadata generation is applied. The existing labels are mapped directly to binary or multiclass targets to train the temporal hidden-state monitors.
Method
The authors propose D2-Monitor, a dynamic safety monitoring framework for Diffusion Large Language Models (D-LLMs) that leverages the multi-step denoising trajectory to enable efficient and effective safety classification. The framework operates on the insight that the number of hesitation steps in a D-LLM's denoising process serves as a reliable indicator of sample difficulty for a linear probe. The core mechanism involves identifying trajectories with high hesitation severity, defined as the count of steps where the probe's signed margin to the decision boundary is below a threshold τ, and using this information to guide a two-stage classification process.
The overall architecture of D2-Monitor is composed of three key components: a low-complexity base probe, a router, and a high-complexity advanced probe. The base probe, implemented as a linear probe, is designed to be lightweight and operate as an always-on monitor. It processes each input prompt through the D-LLM's denoising process to generate a multi-step trajectory of hidden representations. The base probe then computes the step-wise margins, identifies hesitation steps, and calculates the overall hesitation severity nτ. This severity score is used by the router to determine whether to escalate the sample for a second-stage classification. For samples with low hesitation severity (nτ≤λ), the base probe directly provides the final prediction. For samples with high hesitation severity (nτ>λ), the router activates the advanced probe.
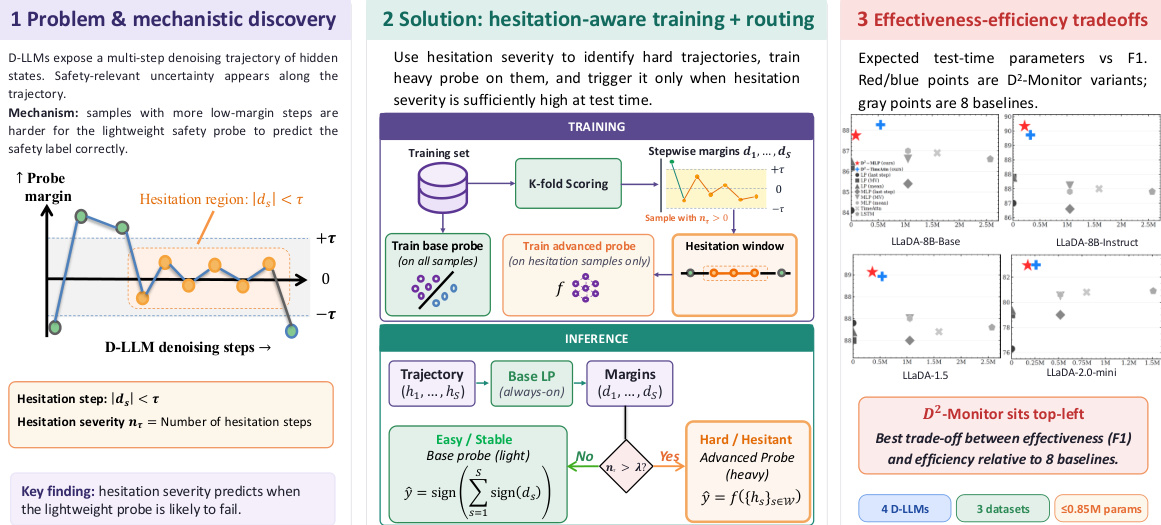
The training process for D2-Monitor is structured in three stages. First, out-of-fold scoring is employed to collect hesitation trajectories for training the advanced probe. The training set is partitioned into k folds, and a linear probe trained on k−1 folds is used to score the remaining fold, yielding unbiased margin estimates. Hesitation steps are identified using the margin threshold τ, and trajectories with nτ>0 are selected. Second, the base probe is trained on the full training set to serve as the initial classifier and to compute hesitation scores. The advanced probe is trained exclusively on the collected hesitation trajectories. This advanced probe operates on the full trajectory H without step-level pooling, using a temporal attention mechanism to aggregate information from the hesitation window—defined as the minimal contiguous span containing all hesitation steps. This window is then fed into a two-layer MLP for classification. Finally, during inference, the cascade detection strategy is applied: the base probe first computes the margins and nτ. If nτ≤λ, the base probe's majority vote prediction is returned. Otherwise, the hesitation window is extracted and passed to the advanced probe for a second-tier prediction. This design enables a dynamic allocation of computational resources, ensuring that only the most difficult samples are processed by the more expensive advanced model.
Experiment
The evaluation tests D2-Monitor across intra- and cross-dataset settings on diffusion LLMs to validate its hesitation-aware cascaded architecture against standard baselines. Comprehensive experiments verify the model's robustness to varying decoding configurations, remasking strategies, and distribution shifts, while ablation studies confirm that margin-based routing effectively isolates intrinsically uncertain samples. By conditionally activating a specialized probe only during genuine model hesitation, the framework substantially reduces computational overhead without compromising detection accuracy. Overall, the findings demonstrate that targeting localized hesitation dynamics yields a highly efficient and reliable safety monitoring solution.
The authors evaluate the performance of their proposed method, D2-Monitor, on different LLaDA models, comparing it against baseline methods. The results show that D2-Monitor achieves higher performance across all models compared to the baseline, with its effectiveness being consistent regardless of the specific model or dataset configuration. D2-Monitor outperforms the baseline across all evaluated models. D2-Monitor achieves higher performance on LLaDA-8B-Base and LLaDA-8B-Instruct compared to LLaDA-1.5. The method's performance is consistently superior to the baseline, indicating robust effectiveness across different model configurations.

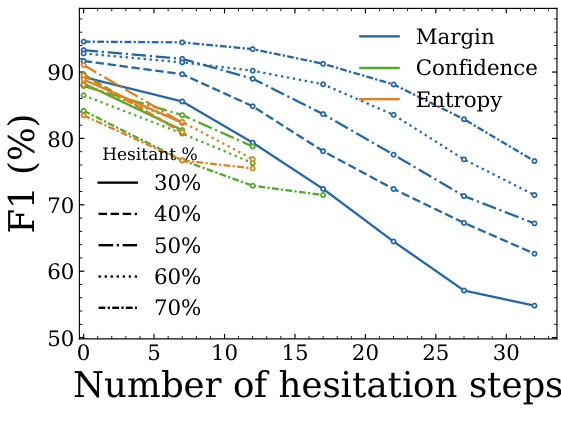
The authors analyze the performance of different routing signals in their method, focusing on how the number of hesitation steps affects F1 scores across varying thresholds for identifying hesitation. The results show that margin-based routing consistently outperforms confidence and entropy-based signals, with stable performance across different hesitation percentages. The performance degrades as the number of hesitation steps increases, but margin-based routing maintains higher F1 scores compared to the alternatives. Margin-based routing consistently achieves higher F1 scores compared to confidence and entropy-based routing across all hesitation percentages. F1 scores decrease as the number of hesitation steps increases, with margin-based routing showing more stable performance. The method demonstrates robustness to different thresholds for identifying hesitation, maintaining high performance across 30% to 70% hesitation levels.
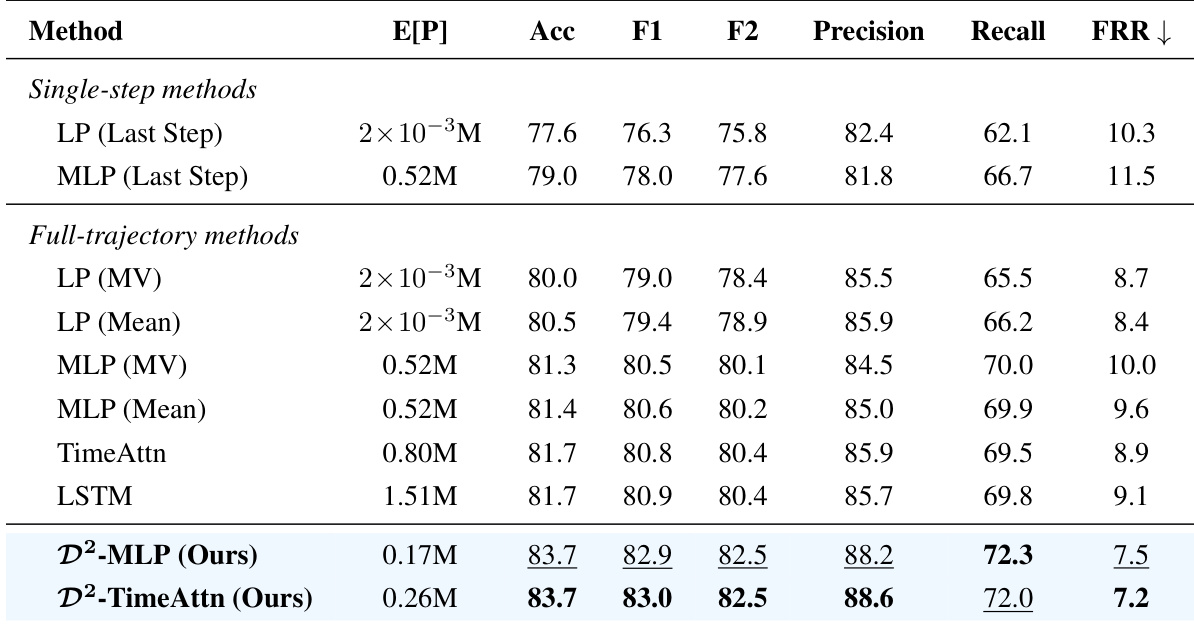
The authors compare their proposed method, D2-Monitor, against various single-step and full-trajectory baselines, demonstrating that their approach achieves superior performance on multiple metrics while maintaining a significantly lower computational cost. The results show that D2-Monitor outperforms all baselines in accuracy, F1, F2, and precision, with competitive recall and lower false rejection rates, particularly when compared to full-trajectory methods. The method's efficiency is attributed to its conditional computation, which reduces the expected FLOPs per sample by only processing a fraction of inputs and focusing on localized hesitation windows. D2-Monitor achieves the highest accuracy and F1 scores among all methods while using substantially fewer computational resources than full-trajectory baselines. The method maintains strong performance across multiple metrics, including precision and F2 score, with lower false rejection rates compared to other approaches. By selectively activating the advanced probe only on hesitation examples, D2-Monitor achieves a better efficiency-effectiveness trade-off, with computational costs comparable to single-step methods.
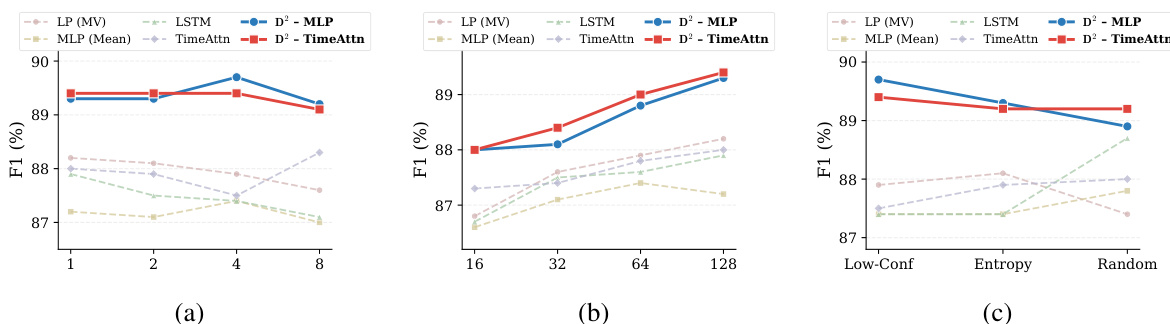
The authors evaluate the performance of their proposed D2-Monitor method against various baselines across different experimental settings. Results show that D2-Monitor consistently achieves higher F1 scores than all other methods, demonstrating superior effectiveness. The method also maintains a favorable efficiency-effectiveness trade-off, as it reduces computational cost by selectively activating advanced probes only on samples exhibiting hesitation, while still matching the performance of full-trajectory models. D2-Monitor achieves the highest F1 scores across all experimental settings compared to all baseline methods. The method demonstrates a strong efficiency-effectiveness trade-off by reducing computational cost through hesitation-aware routing, achieving performance comparable to full-trajectory models with lower resource usage. The performance of D2-Monitor is robust across different generation lengths, step lengths, and remasking strategies, indicating its generalizability to varied deployment conditions.
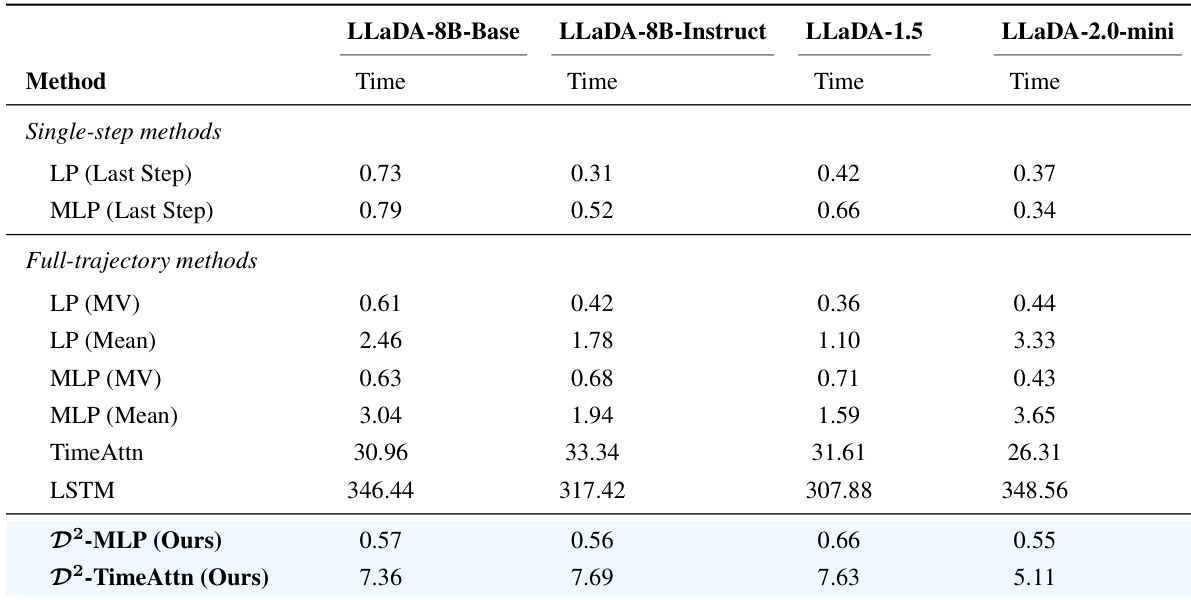
The the the table compares inference times across different methods for various LLaDA models, showing that the proposed D2-Monitor methods achieve significantly lower inference times compared to full-trajectory baselines while maintaining competitive performance. The results indicate that D2-MLP and D2-TimeAttn are among the fastest methods, with inference times comparable to single-step approaches and substantially lower than those of sequence-based models. The authors attribute these efficiency gains to a hesitation-aware routing mechanism that selectively activates more complex probes only on a subset of samples, reducing computational overhead without sacrificing effectiveness. The proposed D2-Monitor methods achieve inference times comparable to single-step methods while outperforming full-trajectory baselines in effectiveness. D2-MLP and D2-TimeAttn significantly reduce inference time compared to traditional full-trajectory models like TimeAttn and LSTM. The efficiency gains are attributed to conditional computation, where advanced probes are activated only on a fraction of samples identified as hesitant, minimizing unnecessary processing.
The proposed method is evaluated across multiple LLaDA models and experimental configurations, benchmarked against both single-step and full-trajectory baselines. Experiments validate that the approach consistently achieves superior detection accuracy, with margin-based routing signals proving more stable and effective than confidence or entropy alternatives. Efficiency evaluations confirm that selectively activating advanced probes only on hesitant inputs yields a highly favorable trade-off, matching full-trajectory performance while significantly reducing computational overhead and inference latency. Overall, the findings demonstrate robust generalizability across varying generation lengths, hesitation thresholds, and remasking strategies.