HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

ABot-M0:アクション多様体学習を用いたロボット操作向けVLA基盤モデル

視覚的推論におけるRLの改善点は何か?フランケンシュタイン風分析






















ABot-M0:アクション多様体学習を用いたロボット操作向けVLA基盤モデル
視覚的推論におけるRLの改善点は何か?フランケンシュタイン風分析
MedXIAOHE:医療分野向けMLLM構築の包括的レシピ
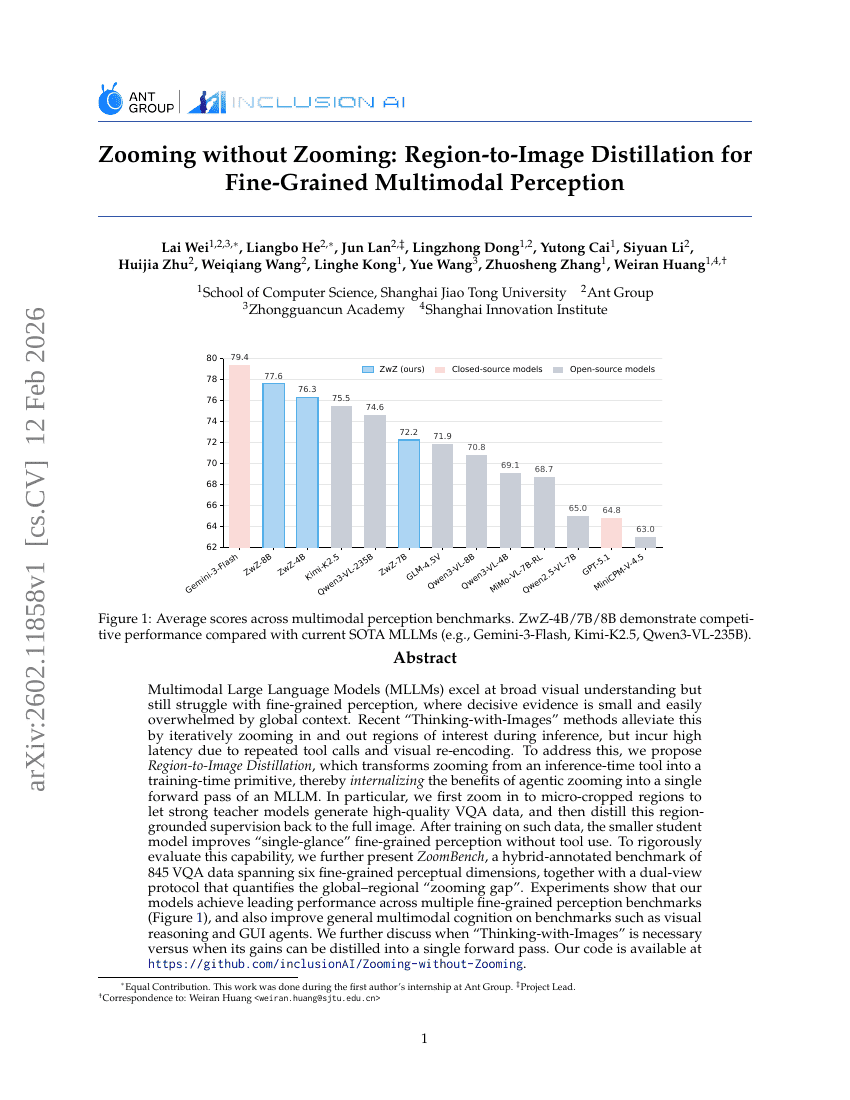
ズームしないズーム:細粒度マルチモーダル認識のための領域から画像への蒸留
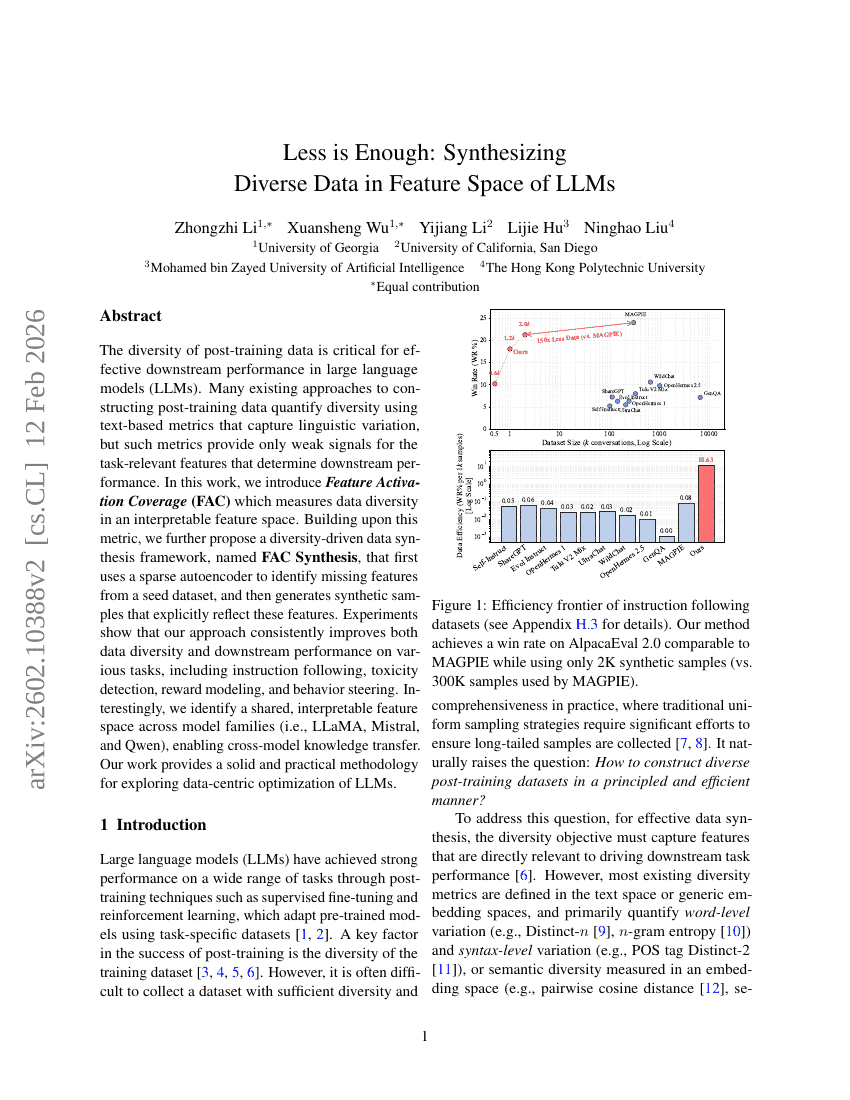
LLMの特徴空間における多様なデータの合成:十分なのは少ないこと
GigaBrain-0.5M*:World Modelベースの強化学習から学習するVLA
MOSS-Audio-Tokenizer:将来のオーディオ基盤モデル向けに拡張されたオーディオトークナイザー
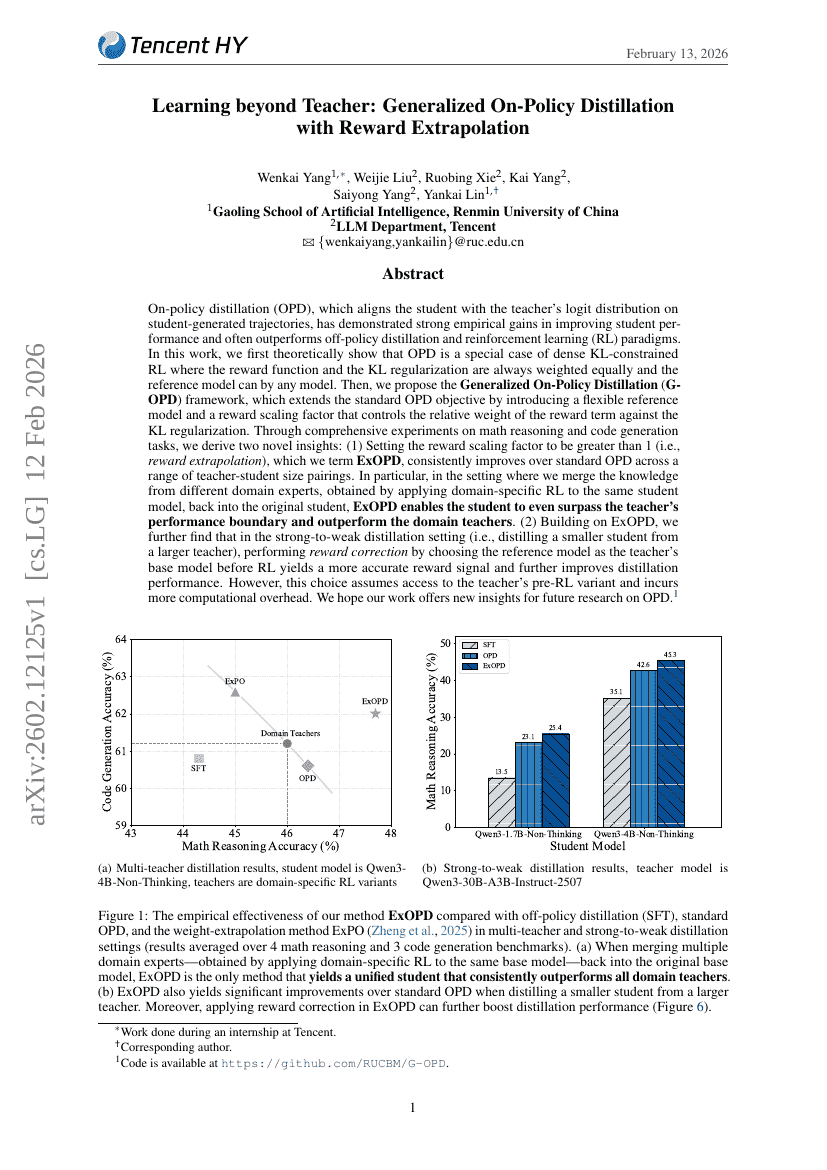
教師を超える学習:報酬外挿を用いた一般化されたオンポリシー蒸留
DeepGen 1.0:画像生成および編集の進展を促進する軽量統合型マルチモーダルモデル
Composition-RL:大規模言語モデルの強化学習のための検証可能なプロンプトの構成
自己進化型AI社会におけるアントロピック・セーフティの消滅:モルトブックの背後にある悪魔
自律的な数学研究への道 LLMやAgent、tokenなどの技術の進展により、数学研究の自動化は現実のものとなりつつある。特に、大規模な言語モデル(LLM)は、数学的証明の探索、定理の発見、問題解決の戦略設計において、人間の研究者と協働する能力を備えている。これらのモデルは、数学的な記号や論理構造を理解し、複雑な推論を実行することで、新たな数学的知見を生成する可能性を秘めている。さらに、Agentアーキテクチャを用いることで、複数のLLMが協調して数学的課題に取り組むことが可能となり、長期的な研究プロセスの自律的進行が期待される。このように、LLMとAgentの統合は、数学研究の自動化を推進し、新たな発見の速度と範囲を飛躍的に拡大する可能性を示している。
長文脈推論のためのゲート付き再帰的メモリ:いつ記憶し、いつ停止するか
ASA:ツールコール領域適応のためのアクティベーション制御
PhyCritic:物理AI向けマルチモーダル・クリティックモデル
GENIUS:生成型流動知能評価スイート
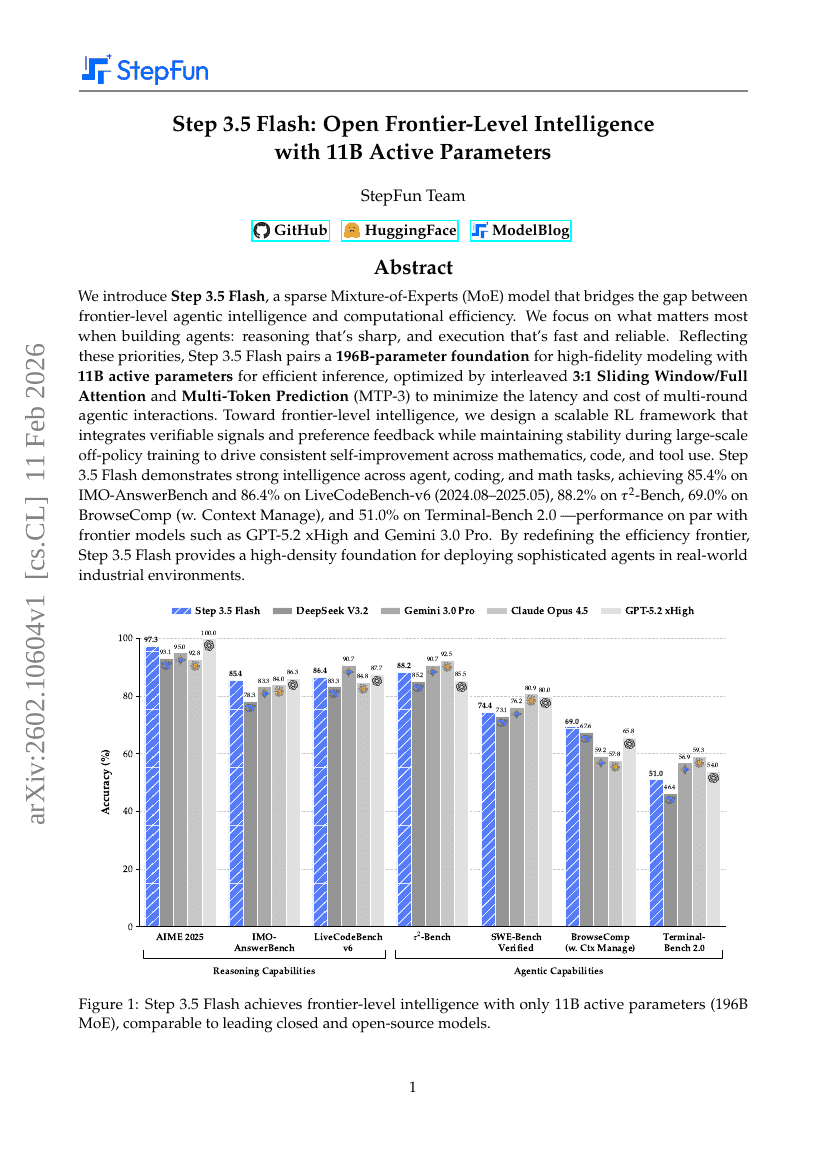
ステップ3.5 Flash:11Bのアクティブパラメータを用いたフロントエンドレベルのインテリジェンスの開放
World-VLA-Loop:動画ワールドモデルとVLAポリシーのクローズドループ学習
自律的数学研究へ向かって
エージェント・ワールドモデル:エージェンティック強化学習のための無限合成環境
P1-VL:物理学オリンピックにおける視覚認識と科学的推論を橋渡しする
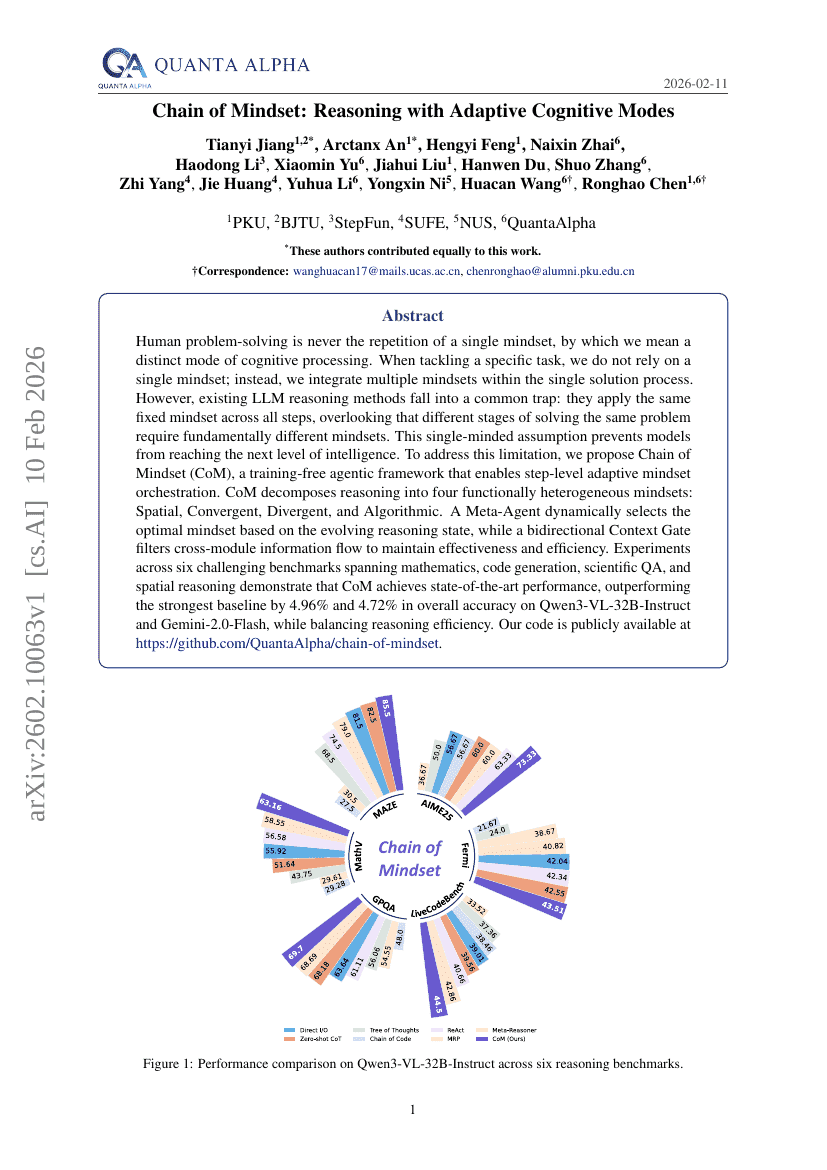
マインドセットのチェーン:適応的認知モードを用いた推論
UI-Venus-1.5 技術報告
Code2World:レンダラブルなコード生成を用いたGUIワールドモデル
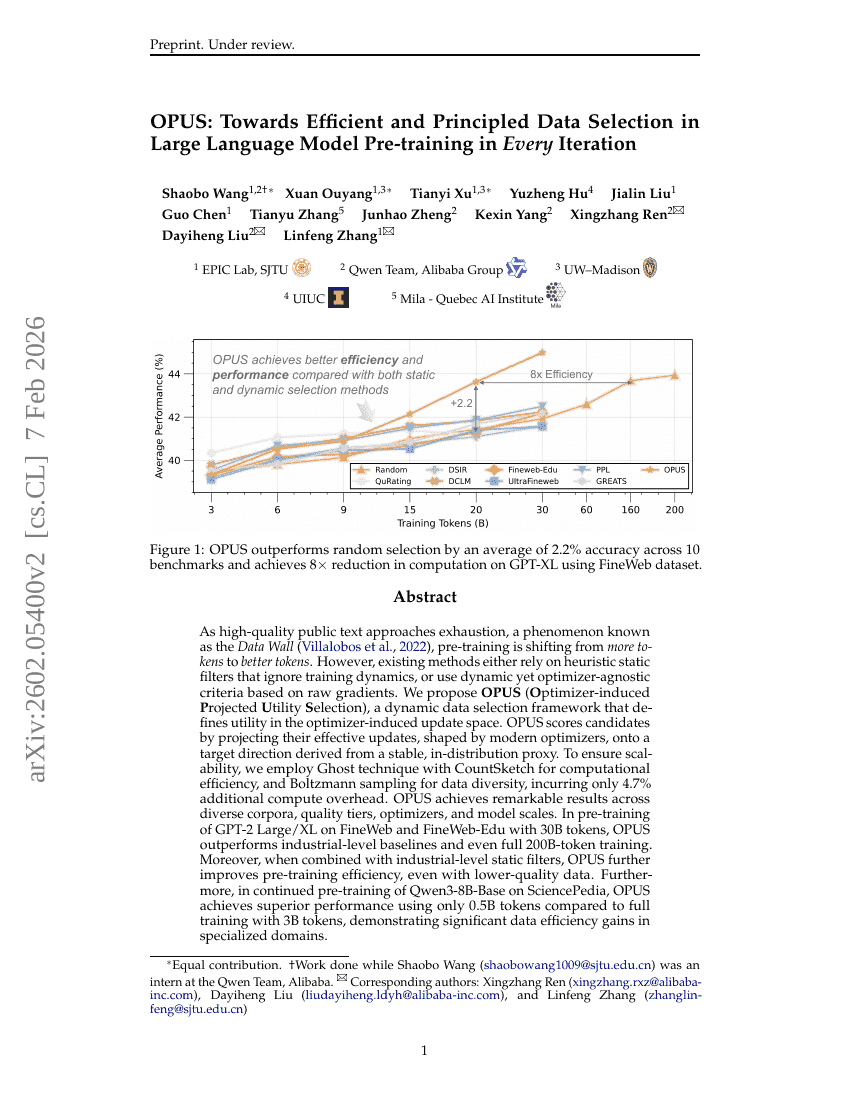
OPUS:大規模言語モデルの事前学習において、各反復毎に効率的かつ原則的なデータ選択へ向けて
BagelVLA:視覚・言語・行動の交互生成による長期予測操作の向上
THINGS-data:ヒトの脳および行動における物体表現を調査するための、大規模なマルチモーダルデータセット・コレクション
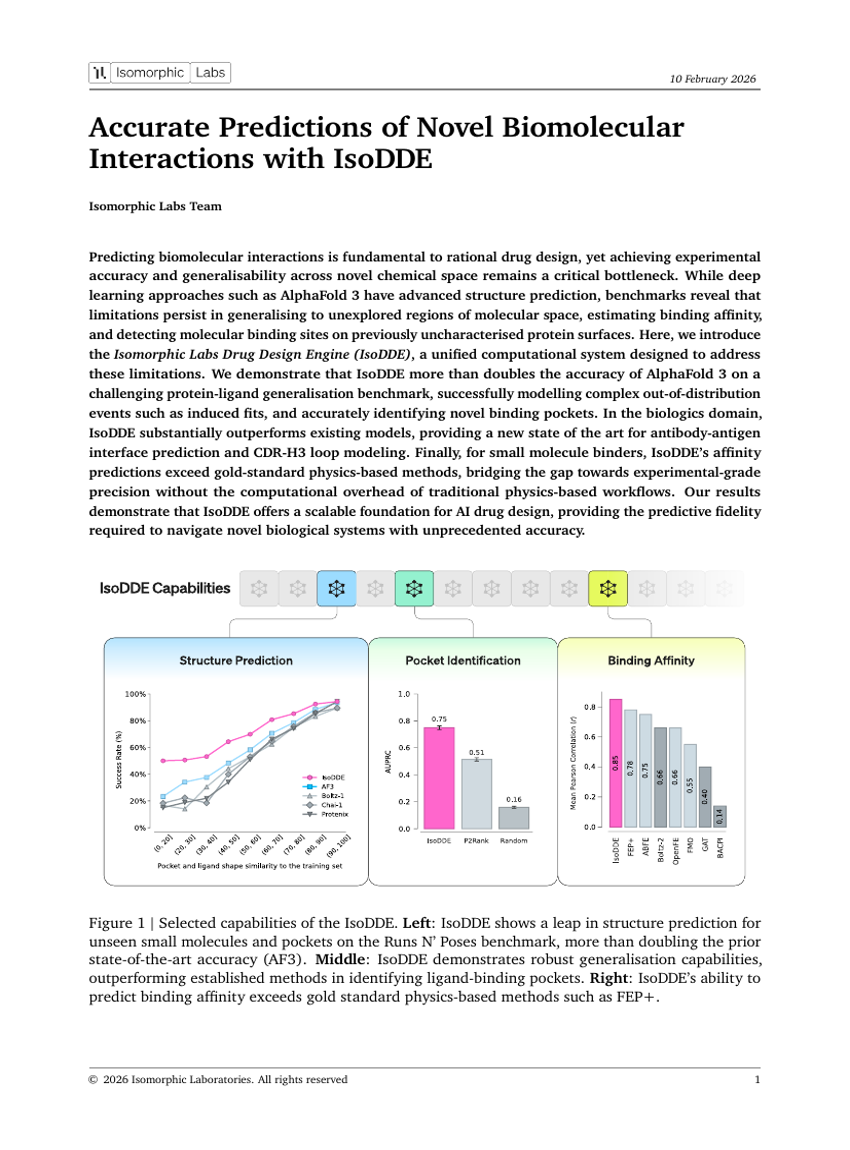
IsoDDEを用いた新規生体分子相互作用の正確な予測
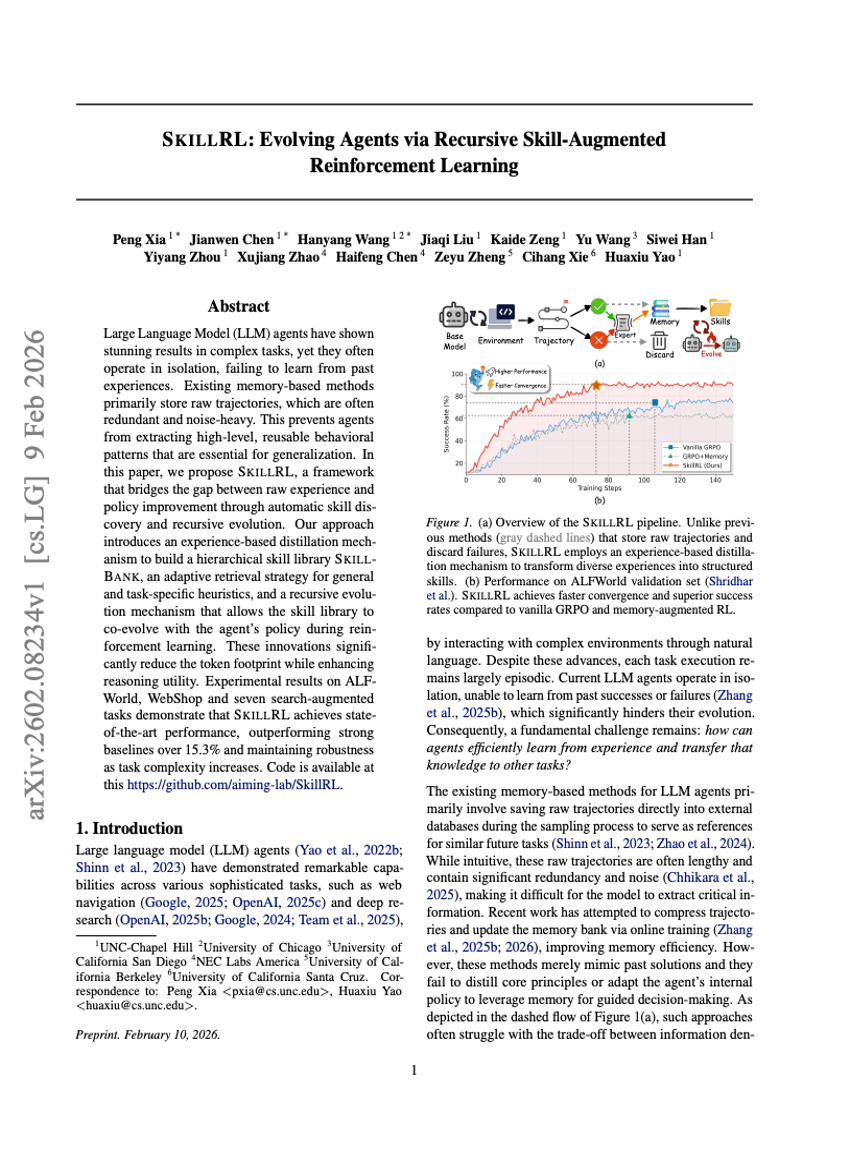
SKILLRL: 再帰的なスキル拡張型強化学習によるAgentの進化
LLaDA2.1:トークン編集によるテキスト拡散の高速化
FlowベースのGRPOにおけるステップワイズおよび長期的サンプリング効果のモデリングによるスパース報酬の軽減
再帰的深度VLA:潜在反復推論を用いた視覚言語行動モデルのテスト時計算スケーリングの陰的実現
MedXIAOHE:医療分野向けMLLM構築の包括的レシピ
ズームしないズーム:細粒度マルチモーダル認識のための領域から画像への蒸留
LLMの特徴空間における多様なデータの合成:十分なのは少ないこと
GigaBrain-0.5M*:World Modelベースの強化学習から学習するVLA
MOSS-Audio-Tokenizer:将来のオーディオ基盤モデル向けに拡張されたオーディオトークナイザー
教師を超える学習:報酬外挿を用いた一般化されたオンポリシー蒸留
DeepGen 1.0:画像生成および編集の進展を促進する軽量統合型マルチモーダルモデル
Composition-RL:大規模言語モデルの強化学習のための検証可能なプロンプトの構成
自己進化型AI社会におけるアントロピック・セーフティの消滅:モルトブックの背後にある悪魔
自律的な数学研究への道 LLMやAgent、tokenなどの技術の進展により、数学研究の自動化は現実のものとなりつつある。特に、大規模な言語モデル(LLM)は、数学的証明の探索、定理の発見、問題解決の戦略設計において、人間の研究者と協働する能力を備えている。これらのモデルは、数学的な記号や論理構造を理解し、複雑な推論を実行することで、新たな数学的知見を生成する可能性を秘めている。さらに、Agentアーキテクチャを用いることで、複数のLLMが協調して数学的課題に取り組むことが可能となり、長期的な研究プロセスの自律的進行が期待される。このように、LLMとAgentの統合は、数学研究の自動化を推進し、新たな発見の速度と範囲を飛躍的に拡大する可能性を示している。
長文脈推論のためのゲート付き再帰的メモリ:いつ記憶し、いつ停止するか
ASA:ツールコール領域適応のためのアクティベーション制御
PhyCritic:物理AI向けマルチモーダル・クリティックモデル
GENIUS:生成型流動知能評価スイート
ステップ3.5 Flash:11Bのアクティブパラメータを用いたフロントエンドレベルのインテリジェンスの開放
World-VLA-Loop:動画ワールドモデルとVLAポリシーのクローズドループ学習
自律的数学研究へ向かって
エージェント・ワールドモデル:エージェンティック強化学習のための無限合成環境
P1-VL:物理学オリンピックにおける視覚認識と科学的推論を橋渡しする
マインドセットのチェーン:適応的認知モードを用いた推論
UI-Venus-1.5 技術報告
Code2World:レンダラブルなコード生成を用いたGUIワールドモデル
OPUS:大規模言語モデルの事前学習において、各反復毎に効率的かつ原則的なデータ選択へ向けて
BagelVLA:視覚・言語・行動の交互生成による長期予測操作の向上
THINGS-data:ヒトの脳および行動における物体表現を調査するための、大規模なマルチモーダルデータセット・コレクション
IsoDDEを用いた新規生体分子相互作用の正確な予測
SKILLRL: 再帰的なスキル拡張型強化学習によるAgentの進化
LLaDA2.1:トークン編集によるテキスト拡散の高速化
FlowベースのGRPOにおけるステップワイズおよび長期的サンプリング効果のモデリングによるスパース報酬の軽減
再帰的深度VLA:潜在反復推論を用いた視覚言語行動モデルのテスト時計算スケーリングの陰的実現